Redis第3讲——跳跃表详解
一、什么是跳跃表
跳跃表(skiplist)是一种随机化的数据结构,由William Pugh在论文《Skip lists: a probabilistic alternative to balanced trees》中提出。它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
跳跃表支持O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点,在大部分情况下,跳跃表的效率可以和红黑树、AVL树不相上下,但跳表原理更加简单、实现起来也更简单直观。
在Redis中,跳跃表是有序集合(zSet)数据类型的实现之一,也在集群节点中用作内部数据结构,除此之外,跳跃表在Redis里面没有其它用途。
二、举个例子
是不是有点抽象?那么下面我们举个有序链表的例子对比一下,就更容易理解了。
我们先来看下有序链表:

在这个链表中,如果我们想要查找一个数,需要从头结点开始向后依次遍历和比对,直到查到为止,那么它的时间复杂度就是O(N)。
当我们想要在这个链表插入一个数,过程和查找了类似,也是从头到尾遍历,然后在合适为止再插入,时间复杂度也是O(N)。
那有什么好办法呢?如果我们将链表中每两个节点建立第一级索引,是否可以提升效率呢,如下图:

有了索引后,如果我们查询10元素,我们先从一级索引5、8、17、29中查找:
- 先和5比较,发现10比5大,继续向后找。
- 8比10小,继续向后找。
- 发现8的next指针指向17,比10大,然后下降到0层。
- 此时第0层的next指针指向10,也就是我们要找的元素。
可以看到,同样是查找10,有序链表需要比较(2,5,7,8,10)五个元素,而建了一层索引后,仅需比较(5,8,17,10)四个元素。
有了上面经验,我们在此基础上继续建立二级...

- 首先和8进行比较,发现比10小,向后查找。
- 此时next指向NULL,下降一层。
- 此时next指针指向17,比10大,下降一层。
- 此时next指针指向10,正是我们要找的元素。
此时只需比较(5、8、10)。
综上所述,通过将有序集合的部分节点分层,从最上层节点依次开始向后查找,如果本层的next节点大于查找值或指向NULL,则从本节开始下降一层继续向后查找,如果找到则返回,反之返回NULL。
因为我们的链表不够大,查找的元素也比较靠前,所以速度上的感知可能没那么大,但是如果是在成千上万个节点、甚至数十万、百万个节点中遍历,那么这样的数据结构就能大大提高效率,这就是跳跃表的思想。
三、跳跃表的实现
Redis的跳跃表由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息,比如节点的数量、指向表头结点和表尾系欸但的指针等,下面来分别介绍一下。
3.1 zskiplit结构
保存跳跃表节点的相关信息,比如节点的数量、指向表头结点和表尾系欸但的指针等,定义如下:
/*
* 跳跃表链表结构
*/
typedef struct zskiplist {
? ?// 表头节点和表尾节点
? ?struct zskiplistNode *header, *tail;
? ?// 表中节点的数量
? ?unsigned long length;
? ?// 表中层数最大的节点的层数
? ?int level;
} zskiplist;
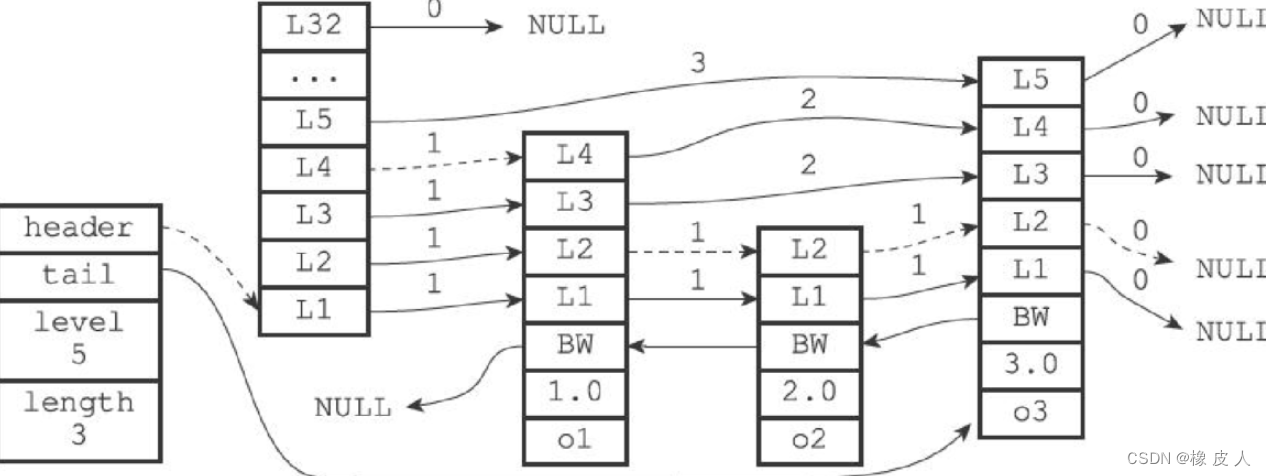
- header:指向跳跃表的表头结点。
- tail:指向跳跃表的表尾结点。
- length:跳跃表长度,表示第0层除头节点以外的所有结点总数。
- level:跳跃表高度,除头节点外,其它节点层数最高的即为跳跃表高度。
ps:表头节点和其它节点的构造是一样的:表头节点也有后退指针、分值和成员对象,不过表头节点的这些属性都不会被用到。
3.2 zskiplistNode结构
表示跳跃表节点,定义如下:
typedef struct zskiplistNode {
? ?// 成员对象
? ?robj *obj;
? ?// 分值
? ?double score;
? ?// 后退指针
? ?struct zskiplistNode *backward;
? ?// 层
? ?struct zskiplistLevel {
? ? ? ?// 前进指针
? ? ? ?struct zskiplistNode *forward;
? ? ? ?// 跨度
? ? ? ?unsigned int span;
? } level[];
} zskiplistNode;
成员对象(obj):节点的成员对象,指向一个字符串对象,而字符串对象则保存着一个SDS值。
分值(score):double类型浮点数,用户存储有序链表节点的分值,跳跃表中所有节点都按分值从小到达排序。
后退(backward)指针:后退指针,用于从表尾向表头访问,与可以一次跳过多个前进指针不同,因为每个节点只有一个后退指针,因此一次只能后退一步。
层(level):每次创建一个新跳跃节点时,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个1~32的值作为level数组的大小,这个大小就是层的“高度”,一般来说,层的数量越多,访问其它节点的速度就越快。这个level数组中的每项元素包含以下两个元素:
forward:每个层都有一个指向表尾方向的前进指针(level[i].forward属性),用于从表头向表尾方向访问节点,尾节点的forward指向NULL。
span:层的跨度(level[i].span属性),用于记录两个节点之间的距离,两个节点之间的跨度越大,说明它们距离的越远,指向NULL的所有前进指针的跨度都为0,因为他没有连向任何节点。
如果能仔细看到这的话,看一眼图,会让你茅塞顿开:最左边是zskiplist结构,右边四个是zskiplistNode结构,其中第一个为头节点(header)。
3.3 随机高度的实现
每一个新插入的节点,都会调用一个随机算法给它分配一个随机层数,定义如下:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */
#define ZSKIPLIST_P 0.25 ? ? ?/* Skiplist P = 1/4 */
/* Returns a random level for the new skiplist node we are going to create.
* 返回一个随机值,用作新跳跃表节点的层数。
* 返回值介乎 1 和 ZSKIPLIST_MAXLEVEL 之间(包含 ZSKIPLIST_MAXLEVEL),
* 根据随机算法所使用的幂次定律,越大的值生成的几率越小。
* T = O(N)
*/
int zslRandomLevel(void) {
? ?int level = 1;
? ?//0xFFFF十六进制对应65535十进制
? ?while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
? ? ? ?level += 1;
? ?return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}redis通过zslRandomLevel函数随机生成一个1~32的值作为新建节点的高度,值越大出现的概率越低,节点高度确定后就不会再修改。解释一下上述代码:
- level初始值为1,进入循环。
- 如果一个0~65535(含)之间的随机数小于ZSKIPLIST_P(0.25)?* 65535,则level加一,反之跳出循环。
- 最后一个三元运算,取level和ZSKIPLIST_MAXLEVEL(32)的最小值返回。
所以,我们可以看到,redis跳跃表默认允许最大的层数就是32,也就是ZSKIPLIST_MAXLEVEL。
四、相关API
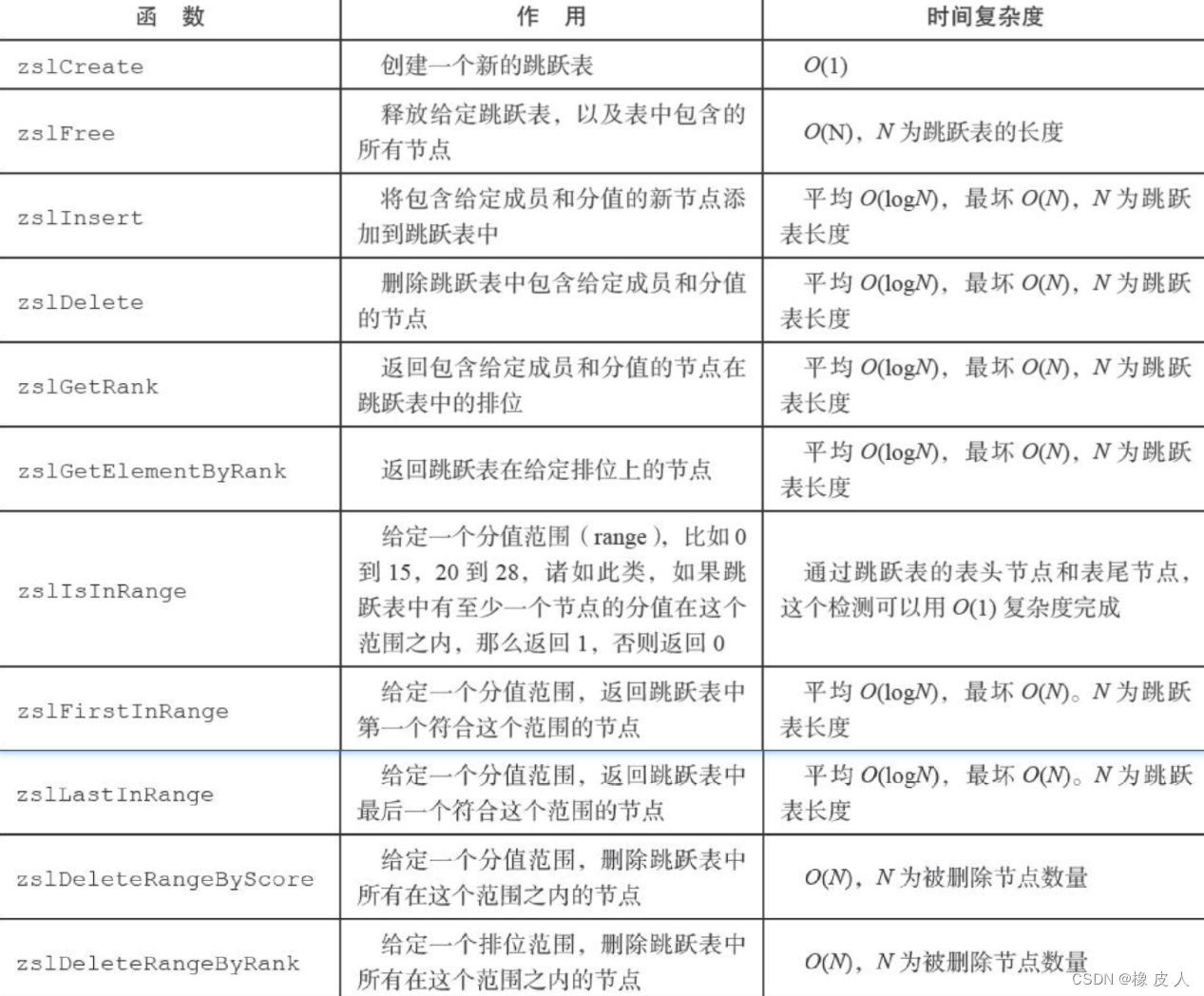
源码就不介绍了,这里给大家提供一个API,感兴趣的可以根据下图去学习相关的源码:
五、为什么zset数据类型既支持高效的范围查询且能以O(1)的时间复杂度获取元素权重值?
高效的范围查询是因为它的核心数据结构是跳跃表,而能以O(1)的时间复杂度获取元素权重值是因为同时采用了哈希表进行索引。
ps:我们直到zset数据类型的编码是skiplist和ziplist(redis 7.0 istpack),而skiplist的底层采用了zset结构,千万别搞混了!
typedef struct zset
{
dict *dict;
? ?zskiplist *zsl;
}zset;以上是zset结构,包含了两个成员,哈希表dict和调表zsl。
- dict存储member->score之间的映射关系,所以ZSCORE的时间复杂度为O(1)。
- 从上述跳跃表的介绍中也不难理解,skiplist是一个【有序链表+多层索引】的结构,每一层级的索引包含了指向其它链表中其它节点的指针,通过这些指针可以跳过一些不需要的节点,从而快速定位到目标元素,查询效率的时间复杂度为O(log N),所以它的查询效率也很高。
??End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!