多级缓存、OpenResty缓存、Redis分布式缓存、进程缓存
一、预期表现
希望达到的效果
四台节点:node01、node02、node03、node04,系统都是ubuntu20.04 server
| 节点 | ip | 用途 | Value |
|---|---|---|---|
| node01 | 192.168.1.101 | Openresty服务器、redis节点 | |
| node02 | 192.168.1.102 | nginx反向代理服务器、redis节点 | |
| node03 | 192.168.1.103 | web前端服务器、redis节点 | |
| node04 | 192.168.1.104 | web后端服务器 |
请求流程
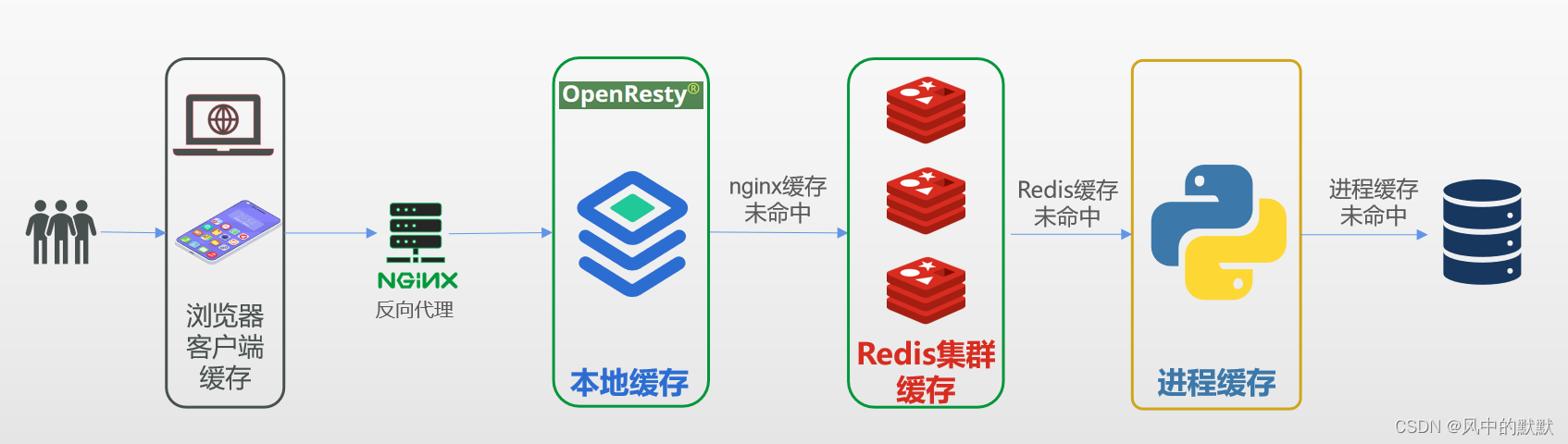
1、通过node03上的前端服务器发出查询请求(post带请求体)http://192.168.1.102:8070/cache/xxxx
2、node02上的nginx服务器8070端口监听到/cache/,转发给node01节点上8081端口
3、node01上的8081端口监听到请求,交由本机的Openresty服务器上我们编写的业务代码(lua语言)来处理:先查询Openresty本地缓存,命中失败查询redis集群缓存,命中失败查询web后端服务器,有结果后更新本地缓存与redis缓存。
4、在node01、node02、node0节点上设置redis的主从集群+哨兵,并在Openresty上的lua文件里编码主从读写分离+自动故障转移。
5、node04上的web后端服务器接收到请求(如有),先查询进程缓存,进程缓存命中失败后查询数据库,有结果后会自动添加缓存,缓存淘汰使用LRU策略。
简而言之,从请求发出到数据返回一共经历四层循环:1 浏览器缓存(我们不涉及)、2 openresty缓存、3 redis集群缓存、4 进程缓存。
二、环境配置
1、nginx环境
我们在node02节点上配置nginx代理服务器,监听8070端口,请求从node04发过来之后直接到达nginx的8070端口上,只要请求是以/cache/开头的都会被捕获,然后转发到server 192.168.1.101:8081openresty服务器进行处理。
#user nobody;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
upstream nginx-cluster{
server 192.168.1.101:8081;
}
server {
listen 8070;
server_name localhost;
location /cache/ {
proxy_pass http://nginx-cluster;
}
}
}
2、OpenResty环境
因为有的人系统不一样,所以直接去它的官网上看安装教程就好。
https://openresty.org/cn/linux-packages.html
请求通过nginx转发到了这里,我们接收到后在这里进行缓存代码的实现 & 缓存的查询。
3、redis环境
我们在node01、node02、node03三台节点上都安装redis,并搭建好主从集群 + 哨兵,设置node03是主节点,哨兵quorum设置为2,超过半数就行了。
3.1 安装redis
sudo apt update # 更新软件包列表(可选)
sudo apt install gcc tcl # 安装 gcc 和 tcl
tar -xzf redis-6.2.6.tar.gz # 安装包放在/usr/local/src下
cd redis-6.2.6
sudo make && make install # 默认的安装路径是在 /usr/local/bin 目录下
# 任意目录 redis-server 都会启动,但这属于`前台启动`,会阻塞整个会话窗口,窗口关闭redis就会停止
# 指定后台启动方式,在之前解压的redis安装包路径下,/usr/local/src/redis-6.2.6
cp redis.conf redis.conf.bck
vim redis.conf
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码。(这个随意,我没有设置)
requirepass 123321
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
3.2 配置启动命令
# 配置redis命令
sudo vi /etc/systemd/system/redis.service
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
# 然后重载系统服务
systemctl daemon-reload
# 现在我们可以用下面这组命令来操作redis了:
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
# 让redis开机自启
systemctl enable redis
3.3 配置主从
我们设置192.168.1.103为主节点,在其他两个节点的配置文件中添加:replicaof <192.168.1.103> <6379>
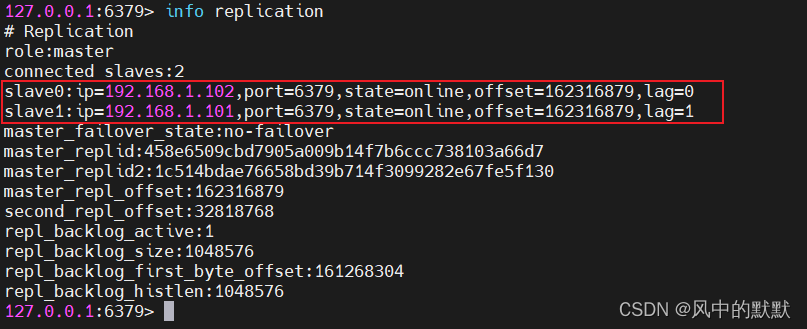
这个时候只有103能写数据,101和102节点只能读操作,所以后面写代码的时候就需要读写分离,要是随便找台节点进行写操作就会失败。
3.4 哨兵
我们在/usr/local/src/sentinel/目录下新建sentinel.conf文件,设置3个节点哨兵端口都是26379,因为只有三台redis节点,所以我们的选举值就设为2,大于一半就好。
port 26379
sentinel announce-ip "192.168.1.103"
sentinel monitor mymaster 192.168.1.103 6379 2 # 选举master时的quorum值
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/usr/local/src/sentinel"
可以使用sudo redis-sentinel sentinel/sentinel.conf --daemonize yes命令启动哨兵
4、进程缓存环境
这部分常用的实现是使用基于java语言的Caffeine,但因为本项目为python+django,为了方便起见使用了python中自带的lru_cache装饰器实现进程内缓存功能,也就不用配置什么了,有python环境就行。
启动后端的时候,在内存中维护一份缓存,有请求过来时先查一下这个内存中有没有key命中,没有命中再去请求数据库并更新缓存。应用重启/宕机,缓存丢失。
三 、主要编码工作
3.1、缓存主要问题解决
3.1.1 缓存穿透
一般处理缓存穿透有缓存null值 和 布隆过滤器两种方式,我们的业务是读多写少,基本存进去的数据不会再发生更改,不太可能出现数据短期不一致的情况,所以这里简单使用缓存null值来解决缓存穿透问题。
3.1.2 缓存雪崩
这就没什么好说的了,雪崩本来就是redis宕机或者大量缓存同时失效的情况才会发生,我们是redis集群+多级缓存来保证服务的可用性,所以雪崩的可能性很小。
3.1.3 缓存击穿
缓存击穿是有重建过程复杂的热点key失效导致的大量请求访问数据库的情况,一般处理方案是1互斥锁2逻辑过期,我这里选择了互斥锁,因为我们的业务请求量不大,而且业务的key本身就很长了,再加时间就挺不合适了。
因为我们这里是redis集群,所以可能会出现分布式并发的安全问题,我们用分布式锁来解决并发安全问题。刚好redis自己就有一个SET NX EX的命令来充当分布式锁,同时设置过期时间避免死锁。我们在拿锁的时候放入我们的线程标识,放锁的时候比对当前线程是否持有锁,有锁的才能释放,以此解决并发情况下其他线程释放锁错误的情况。
还有就是释放锁的时候有个 拿标识–比对–释放锁的过程,极端情况下可能会出现这三个过程还没走完服务就宕机的情况,所以我们使用lua脚本解决多条命令执行的原子性问题。
3.2、OpenResty编码
这里是openresty中nginx的目录,也是我们进行编码的主要地方
lua文件夹是我们自己新建的,主要是放缓存处理的业务代码
lualib是本来就有的文件夹,我们把一些通用的代码抽取出来放里面
3.2.1 openresty/nginx/conf/nginx.conf
下面是OpenResty中nginx的配置文件,/usr/local/openresty/nginx/conf/nginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
server {
listen 8081;
server_name localhost;
# nginx转发过来的请求在这儿接收,返回的结果交由item.lua文件来处理返回
location /cache/ {
default_type application/json;
content_by_lua_file lua/item.lua;
}
# 当openresty缓存和redis缓存都没有命中,需要去访问后端服务器时,就从这儿走
location /xxxx/ {
proxy_pass http://192.168.1.104:8002;
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
3.2.2 lualib/redis_common.lua
重头戏来了
redis的相关操作都在lualib/redis_common.lua这个文件里,我们在里面实现了主从故障的动态切换、读写分离、redis连接池等。
local redis = require "resty.redis"
-- 定义 Redis 节点和哨兵配置
local sentinel_hosts = {
{ host = "192.168.1.101", port = 26379 },
{ host = "192.168.1.102", port = 26379 },
{ host = "192.168.1.103", port = 26379 }
}
local sentinel_group = "mymaster"
-- 以秒为单位定义缓存超时时间(例如 60 秒)
local CACHE_EXPIRATION = 60
local cached_master_address = nil
local cached_slave_address = nil
local last_master_cache_time = nil
local last_slave_cache_time = nil
-- 定义缓存节点信息的全局变量
local cached_master_address
local cached_slave_address
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 连接到哨兵节点
local function connect_to_sentinel()
local red = redis:new()
for _, sentinel_host in ipairs(sentinel_hosts) do
local ok, err = red:connect(sentinel_host.host, sentinel_host.port)
if ok then
return red
end
end
ngx.log(ngx.ERR, "【连接到哨兵节点失败: 】", err)
return nil, "Failed to connect to any sentinel"
end
-- 获取 Redis 主节点地址
local function get_master_address()
local current_time = ngx.now()
if cached_master_address and last_master_cache_time and (current_time - last_master_cache_time <= CACHE_EXPIRATION) then
return cached_master_address
end
local red_sentinel, err = connect_to_sentinel()
if not red_sentinel then
return nil, "Failed to connect to Redis Sentinel: " .. err
end
local master_ip, master_port
local master, err = red_sentinel:sentinel("get-master-addr-by-name", sentinel_group)
close_redis(red_sentinel)
for key, value in pairs(master) do
if key == 1 then
master_ip = value
elseif key == 2 then
master_port = value
break;
end
end
cached_master_address = { master_ip, master_port }
last_master_cache_time = current_time
return cached_master_address
end
-- 获取 Redis 从节点地址
local function get_slave_address()
local current_time = ngx.now()
if cached_slave_address and last_slave_cache_time and (current_time - last_slave_cache_time <= CACHE_EXPIRATION) then
return cached_slave_address
end
local red_sentinel, err = connect_to_sentinel()
if not red_sentinel then
return nil, "Failed to connect to Redis Sentinel: " .. err
end
local slaves, err = red_sentinel:sentinel("slaves", sentinel_group)
if not slaves then
red_sentinel:set_keepalive(10000, 100)
return nil, "Failed to retrieve slave addresses: " .. err
end
close_redis(red_sentinel)
local slave_ip, slave_port
for i, slave_info in ipairs(slaves) do
if slave_info[10] and not (string.find(slave_info[10], "s_down") and string.find(slave_info[10], "disconnected")) then
slave_ip = slave_info[4]
slave_port = slave_info[6]
end
end
cached_slave_address = { slave_ip, slave_port }
last_slave_cache_time = current_time
return cached_slave_address
end
-- 获取 Redis 读连接
local function read_redis(key)
local ip, port
local address = get_slave_address()
if address then
ip, port = unpack(address)
else
ngx.log(ngx.ERR, "【无法获取从节点地址】",address)
end
if not ip then
return nil, "Failed to get Redis address"
end
local red = redis:new()
red:set_timeout(1000) -- 设置超时时间
local ok, err = red:connect(ip, tonumber(port))
if not ok then
return nil, "Failed to connect to Redis: " .. err
end
ngx.log(ngx.INFO,"【当前连接redis从节点: 】", ip," 【当前redis从节点端口: 】", port)
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "【查询Redis失败: 】", err, ", 【key = 】" , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
end
close_redis(red)
return resp
end
-- 获取 Redis 写连接
local function write_redis(cacheKey, val, expirationKey)
local ip, port
local address = get_master_address()
if address then
ip, port = unpack(address)
else
ngx.log(ngx.ERR, "【无法获取主节点地址:】",address)
end
if not ip then
return nil, "Failed to get Redis master address"
end
local red = redis:new()
red:set_timeout(1000) -- 设置超时时间
local ok, err = red:connect(ip, tonumber(port))
if not ok then
return nil, "Failed to connect to master Redis: " .. err
end
ngx.log(ngx.INFO,"【redis主节点连接成功,开始执行操作。主节点IP:】", ip, " 【端口:】", port)
-- 获取互斥锁
local uuid = require("resty.uuid")
local mutex = "mutex:" .. cacheKey
local uniqueID = uuid.generate()
local expiration = 30 -- 锁的过期时间(秒)
local retryAttempts = 3 -- 尝试获取锁的次数
local retryDelay = 0.5 -- 每次重试的间隔时间(秒)
local scriptLock = [[
local lockKey = KEYS[1]
local lockValue = ARGV[1]
local expiration = tonumber(ARGV[2]) -- 锁的过期时间(秒)
local lockSet = redis.call("SET", lockKey, lockValue, "NX", "EX", expiration)
if lockSet then
return 1
else
-- 锁已经被其他客户端持有
return 0
end
]]
local scriptReleaseLock = [[
local lockKey = KEYS[1]
local lockValue = ARGV[1]
local currentLockOwner = redis.call("GET", lockKey)
if currentLockOwner == lockValue then
redis.call("DEL", lockKey)
return 1
else
return 0
end
]]
local attempts = 0
local mutexSet = 0
while attempts < retryAttempts and mutexSet ~= 1 do
local result, evalErr = red:eval(scriptLock, 1, mutex, uniqueID, expiration)
if result == 1 then
local scriptSet = [[
redis.call("SET", KEYS[1], ARGV[1])
redis.call("EXPIRE", KEYS[1], ARGV[2])
]]
mutexSet = 1
-- 获取到锁,执行操作
local setResult, setResultErr = red:eval(scriptSet, 1, cacheKey, val, expirationKey)
if not setResult then
ngx.log(ngx.ERR,"【Error setting key: 】", setResultErr)
return
end
-- 释放锁
local releaseResult, releaseErr = red:eval(scriptReleaseLock, 1, mutex, uniqueID)
if not releaseResult then
ngx.log(ngx.ERR, "【互斥锁释放失败:】", mutex, ", ", uniqueID)
end
-- 返回新值
return setResult
else
attempts = attempts + 1
if attempts < retryAttempts then
-- 未获取到锁,等待一段时间后重试
ngx.sleep(retryDelay)
end
end
end
close_redis(red)
end
-- 将方法导出
local _M = {
read_redis = read_redis,
write_redis = write_redis
}
return _M
3.2.3 lualib/common.lua
lualib/common.lua这个文件里主要是封装了发送http请求的代码,在我的流程里主要是openresty和redis缓存都命中失败时,通过这个方法去访问后端服务器。
-- 封装函数,发送 HTTP 请求,并解析响应
local function read_http(path, body)
local resp = ngx.location.capture(path, {
method = ngx.HTTP_POST, -- 修改为 POST 方法
body = body -- 设置请求体数据
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "HTTP请求查询失败, path: ", path)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
3.2.4 nginx/lua/item.lua
下面是我们的业务代码nginx/lua/item.lua,这也是重头戏。我们在里面调用上面common文件夹里封装的redis_common和http文件,然后实现查询openresty失败->查询redis失败->查询后端->更新缓存->返回结果的操作。
ngx.req.read_body()
local jsonBody = ngx.req.get_body_data()
local cjson = require "cjson"
local bodyData = cjson.decode(jsonBody)
bodyData = cjson.decode(bodyData)
local requestURI = ngx.var.uri
ngx.log(ngx.ERR,"=======================一次请求开始=======================")
local coords_str = cjson.encode(bodyData["coords"])
local key = bodyData["database"] .. ":" .. bodyData["dataset"] .. ":" .. bodyData["time"] .. ":" .. bodyData["function"] .. ":" .. coords_str
-- 引入自定义common工具模块,返回值是common中返回的 _M
local common = require("common")
local redis_common = require("redis_common")
local read_redis = redis_common.read_redis
local write_redis = redis_common.write_redis
--local read_redis = common.read_redis
local read_http = common.read_http
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "【本地缓存查询失败,尝试查询Redis】 key: ", key)
-- 查询redis
val = read_redis(key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "【redis查询失败,尝试查询后端进程】 key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
else
ngx.log(ngx.ERR, "【Redis缓存命中!】 key: ", key)
end
else
ngx.log(ngx.ERR, "【本地缓存命中!】 key: ", key)
end
-- 只在查询到非null值时,才把数据写入本地缓存, 并缓存续期
if val then
item_cache:set(key, val, 30)
end
-- 写入redis缓存,即使值为null,防止缓存穿透,也将null值添加进redis
local flag = write_redis(key, val, expire)
-- 返回数据
return val
end
-- 使用 read_http 函数发送 POST 请求并传递解析后的 JSON 数据
local itemJSON = read_data(key, 60, "/api/data_node/file_path/", cjson.encode(bodyData))
-- itemJSON是string,decode后是table,encode后是string
--local aa = cjson.encode(itemJSON)
--local bb = cjson.decode(itemJSON)
ngx.say(itemJSON)
ngx.log(ngx.ERR,"最终获得的值:", itemJSON)
ngx.log(ngx.ERR,"=======================一次请求结束=======================")
3.3、进程缓存编码
我们这里使用python里的lru_cache装饰器(Least Recently Used Cache,最近最少使用缓存),来装饰后端服务器进程查询数据库的函数,存储函数的输入参数和对应的输出结果,函数输入参数会被哈希之后作为缓存的键,所以要求输入参数必须能被哈希。后续调用中,如果相同的输入参数再次出现,直接返回缓存的输出结果,而不需要重新执行函数体,也就不需要再去数据库里查询。
from functools import lru_cache
@lru_cache(maxsize=10) # 注解在需要执行的函数上面
print(f"【进程内缓存信息:{query.cache_info()}】")
#【进程内缓存信息:CacheInfo(hits=6, misses=7, maxsize=10, currsize=7)】
# 命中6次,有请求来但未命中7次,缓存最大存储容量10,当前容量7
query.cache_clear() # 清除缓存
四、测试结果分析
我们在这一部分把整个流程跑一下,把各种可能会出现的情况都模拟一下,来验证实现的多级缓存架构的可用性。
我们在上面的编码部分设置的各缓存情况为:openresty本地缓存时间为30s,redis缓存时间为60s,进程内缓存无时间限制,不过缓存的最大数量限制为10。
4.1 初始无缓存
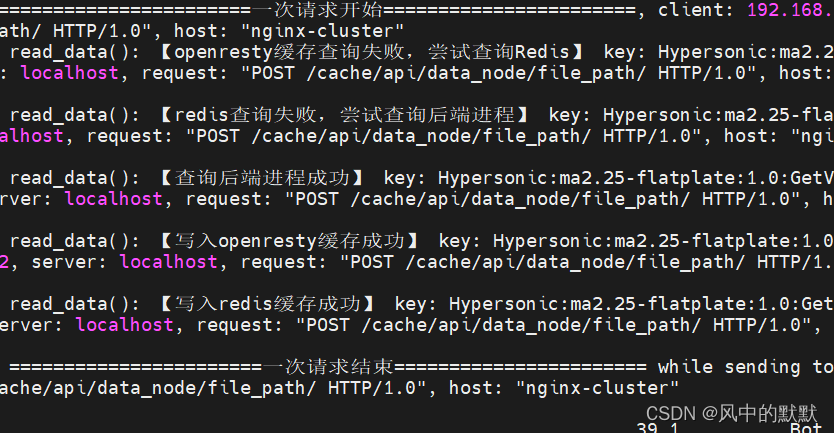
初始条件下,所有缓存里都是null,我们在前端服务器发起请求,请求后打开日志。
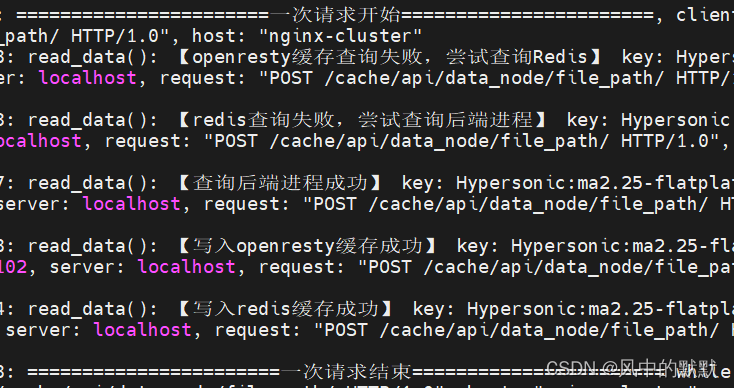
这里可以看到在初次查询时,【openresty缓存查询失败,redis查询失败,查询后端进程成功
,写入openresty缓存成功,写入redis缓存成功】。
这里我们还需要看一下后端缓存部分:

可以看到【缓存命中0,错过1,最大缓存数10,已缓存数1】,这个错过1就是我们刚发的这个请求,请求来了但是进程缓存里没有这个key,只能往下去数据库查询。已缓存数1是我们现在已经缓存了这个key。
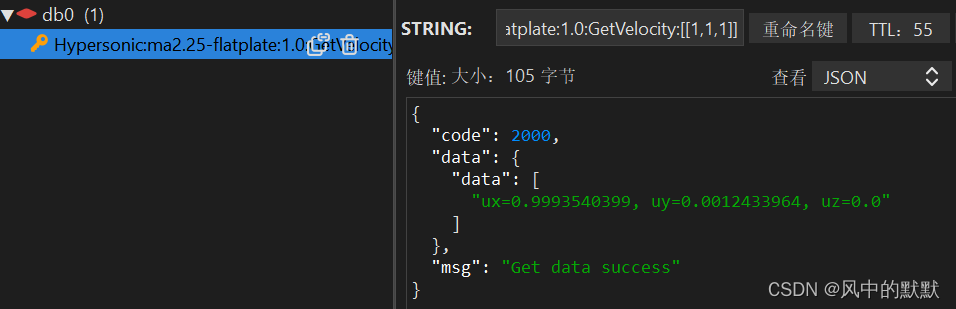
redis也写入成功,TTL从60开始计时
4.2 第二次访问(30s内)
我们在第一次访问过的基础上,在30s时间内(因为openresty本地缓存时间设置的是30s)再次访问同一个数据,返回结果如下。我们在缓存命中后依旧刷新openresty和redis缓存,进行缓存续期。
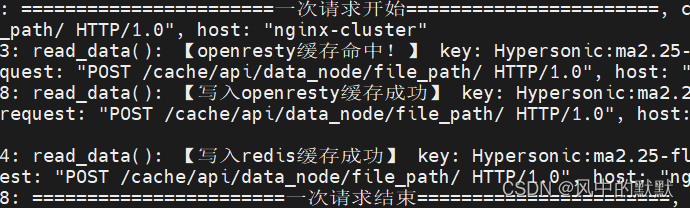
4.3 第二次访问(30s后60s内)
我们在第一次访问过的基础上,在30s外但60s内(因为openresty本地缓存时30s,redis60s)再次访问同一个数据,返回结果如下。
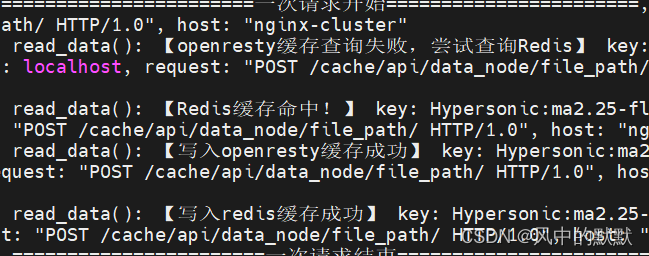
4.4 第二次访问(60s外)
我们在第一次访问过的基础上,在60s外再次访问同一个数据,此时openresty和redis缓存应该都已经过期。
可以看到的确是走了后端服务器,但是走了后端进程缓存吗?
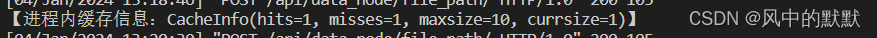
确实是走了进程缓存,因为错过数没有增加,并且多了一次命中。
4.5 自由访问
我们这里重启服务,连续自由访问6条新数据。
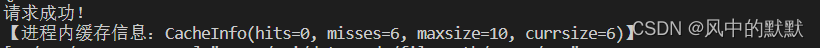
60s后再次连续访问这6条数据
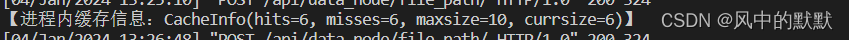
全部命中!
后面还有其他的测试情况,就不一一列举了
五、涉及到的redis知识点
内存淘汰机制

缓存穿透问题
*现象:用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力

缓存空对象:如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是即使这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据。
布隆过滤:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回。
这种方式优点在于节约内存空间。但存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突。
缓存雪崩问题

缓存击穿问题
 举例:线程1在查询缓存不存在后需要去查询数据库,然后把这个数据加到到缓存里。但是在线执行的过程中,后面的n个线程同时访问当前方法,同时来查询缓存,又要同时去访问数据库,对数据库访问压力过大。
举例:线程1在查询缓存不存在后需要去查询数据库,然后把这个数据加到到缓存里。但是在线执行的过程中,后面的n个线程同时访问当前方法,同时来查询缓存,又要同时去访问数据库,对数据库访问压力过大。
解决方案1、使用互斥锁:
假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行
首先线程1来访问,没有命中缓存,去拿互斥锁然后去执行逻辑。线程2再来,并没有获得互斥锁,那么线程2就进行休眠。直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能直接从缓存中拿到数据了。

解决方案2、逻辑过期方案
在key的value里加一个逻辑过期时间,第一个线程发现当前数据已经过期,就去获取互斥锁,然后新开一个线程去重构逻辑,而它不等了直接返回当前的过期数据。在新线程执行的期间有其他线程来访问时,它们发现获取互斥锁失败那就也直接返回过期数据。
互斥锁方案:实现简单且保证了互斥性,因为仅仅只需要加一把锁而已。缺点在于有锁就有死锁问题的发生,而且只能串行执行,性能肯定受到影响。
逻辑过期方案: 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回脏数据,且实现麻烦。
多线程安全问题
分布式锁的核心思想在于所有线程或进程共享同一把锁。只要它们使用相同的锁,就能够阻止多个线程同时访问关键资源,确保程序串行执行。这种设计方式有效地控制了并发访问,保障了共享资源的正确性和一致性。

锁超时问题: 如果获取锁后,持有锁的客户端执行时间超过了锁的过期时间,那么 Redis 将会自动删除这个已过期的锁。这可能导致其他客户端误以为锁被释放了,进而导致并发问题。
原子性问题:在执行业务逻辑过程中,线程的拿锁,比锁,删锁,并不能保证原子性。
解决方法:
1、在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
2、Lua脚本解决多条命令原子性问题
基于Redis的分布式锁实现思路:
- 使用 SET NX EX 命令获取锁,确保互斥性,只有一个线程能够成功获取锁。
- 设置锁的过期时间,即使发生故障也能保证锁在一定时间后自动释放,避免死锁情况的发生,提高系统安全性。
- 存储线程标识,在释放锁时,使用 Lua 脚本先验证线程标识是否与当前线程一致,确保只有持有锁的线程才能释放锁。
- 利用 Redis 集群特性保证高可用性和高并发性,确保在集群环境下锁依然可靠且有效地工作。
基于setnx实现的分布式锁存在下面的问题:
1、重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
2、主从一致性问题: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。
分布式缓存

持久化,为了解决数据丢失问题
RDB
RDB全称Redis Database Backup file Redis数据备份文件,也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
save # save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞
bgsave # 异步执行RDB
# Redis停机时会执行一次save命令,实现RDB持久化
# 触发RDB条件,比如redis.conf里的save 900 1 ,在 900 秒内,如果至少有 1 个键被修改,则执行快照保存
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术
当主进程执行读操作时,访问共享内存;
-当主进程执行写操作时,则会拷贝一份数据,执行写操作。

RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?save 60 1000代表什么含义?
默认是服务停止时。代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- 如果两次 RDB 之间发生故障或意外,如系统崩溃、断电或其他原因,可能会导致在最近一次 RDB 快照之后产生的数据丢失
- fork子进程、压缩、写出RDB文件都比较耗时
AOF
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync n

因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
比如set num 123 和 set num 666,第二次会覆盖第一次的值,因此第一个命令记录下来没有意义。
所以重写命令后,AOF文件内容就是:mset name jack num 666
# Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb

redis主从

我们前面已经记录了怎么装redis,在上面的基础上,192.168.1.101、192.168.1.102和192.168.1.103都装一下,每个节点的端口都是默认的6379,
数据同步原理

简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。什么是增量同步?就是只更新slave与master存在差异的部分数据
简述全量同步和增量同步区别?
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
slave节点第一次连接master节点时
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
slave节点断开又恢复,并且在repl_baklog中能找到offset时
master如何知道slave与自己的数据差异?
这就要说到全量同步时的repl_baklog文件了
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset。
slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset,直到数组被填满。
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:
棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。
优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
哨兵

Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
最后是判断slave节点的运行id大小,越小优先级越高。
Sentinel的三个作用是什么?
监控
故障转移
通知
Sentinel如何判断一个redis实例是否健康?
每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
首先选定一个slave作为新的master,执行slaveof no one
然后让所有节点都执行slaveof 新master
修改故障节点,执行slaveof 新master
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!