公式识别任务各个链条全部打通
引言
随着LaTeX-OCR模型转换问题的解决,公式识别任务中各个链条已经全部打通。小伙伴们可以放开膀子干了。
解决业界问题的方案,并不是单独训练一个模型就完事了,而是有着上下游的依赖。这就像工厂中流水线作业一样,一个小东西的生产是依赖无数个中间阶段才完成的。
一个模型应用到产品中,也是有着类似的流水线的。相比于工厂中流水线,这里的链条只是更加隐蔽一些而已。
公式识别任务是什么?
公式识别任务:指的是将图像中公式识别为对应的LaTeX写法,便于后续加工处理。

公式识别任务距离我们最近的应用场景便是论文写作。在我上大学写毕业论文时,由于当时并不知道LaTeX这种东西可以用来写公式,整个毕业论文公式都是在Word上用鼠标点出来的,好不痛苦。
比较推荐大家学一学LaTeX排版,绝对是提效利器,用过的人都说好。
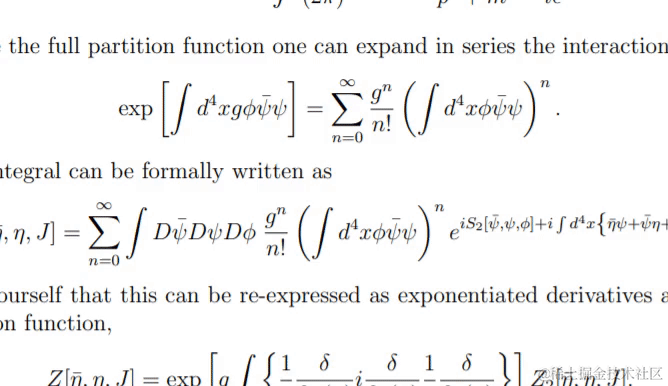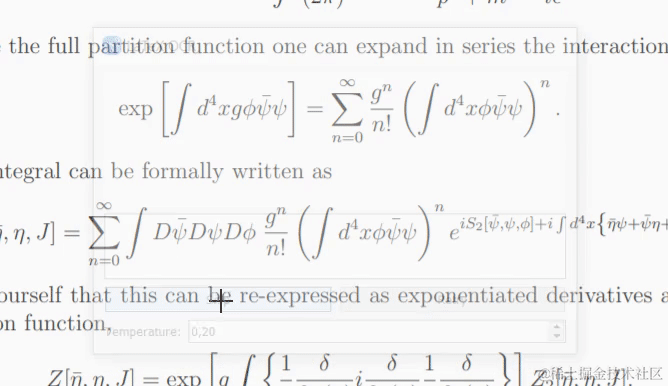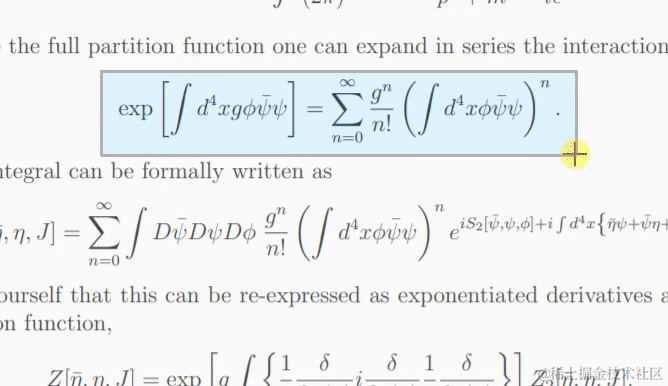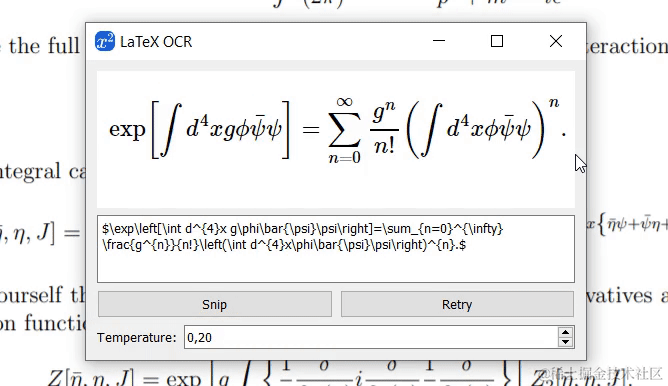
动图来自LaTeX-OCR
公式识别任务解决方案初探
解决公式识别任务,我这里姑且粗略地分为四个部分:公式识别数据集处理、训练识别模型、转换识别模型和部署使用。

取之开源,回馈开源,一直是我们的准则。以上四部分具体地址如下,除训练识别模型为lukas-blecher外,其余均经由我整理。欢迎大家多多使用和提建议。
预处理公式库ProcessLaTeXFormulaTools: https://github.com/SWHL/ProcessLaTeXFormulaTools
训练识别模型库LaTeX-OCR: https://github.com/lukas-blecher/LaTeX-OCR
转换模型为ONNX格式库ConvertLaTeXOCRToONNX: https://github.com/SWHL/ConvertLaTeXOCRToONNX
部署使用库RapidLaTeXOCR: https://github.com/RapidAI/RapidLaTeXOCR
使用建议
先尝试RapidLaTeXOCR中识别模型识别效果,是否满足场景需求。
如果不满足,再考虑结合自身场景,将上述四部分走一遍,定制化自己的公式识别模型。
写在最后
本篇文章只是简单介绍,具体请移步文中各个部分的仓库下查看。
如有具体微调,部署等需求,欢迎后台详细咨询。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!