MySQL数据类型
目录
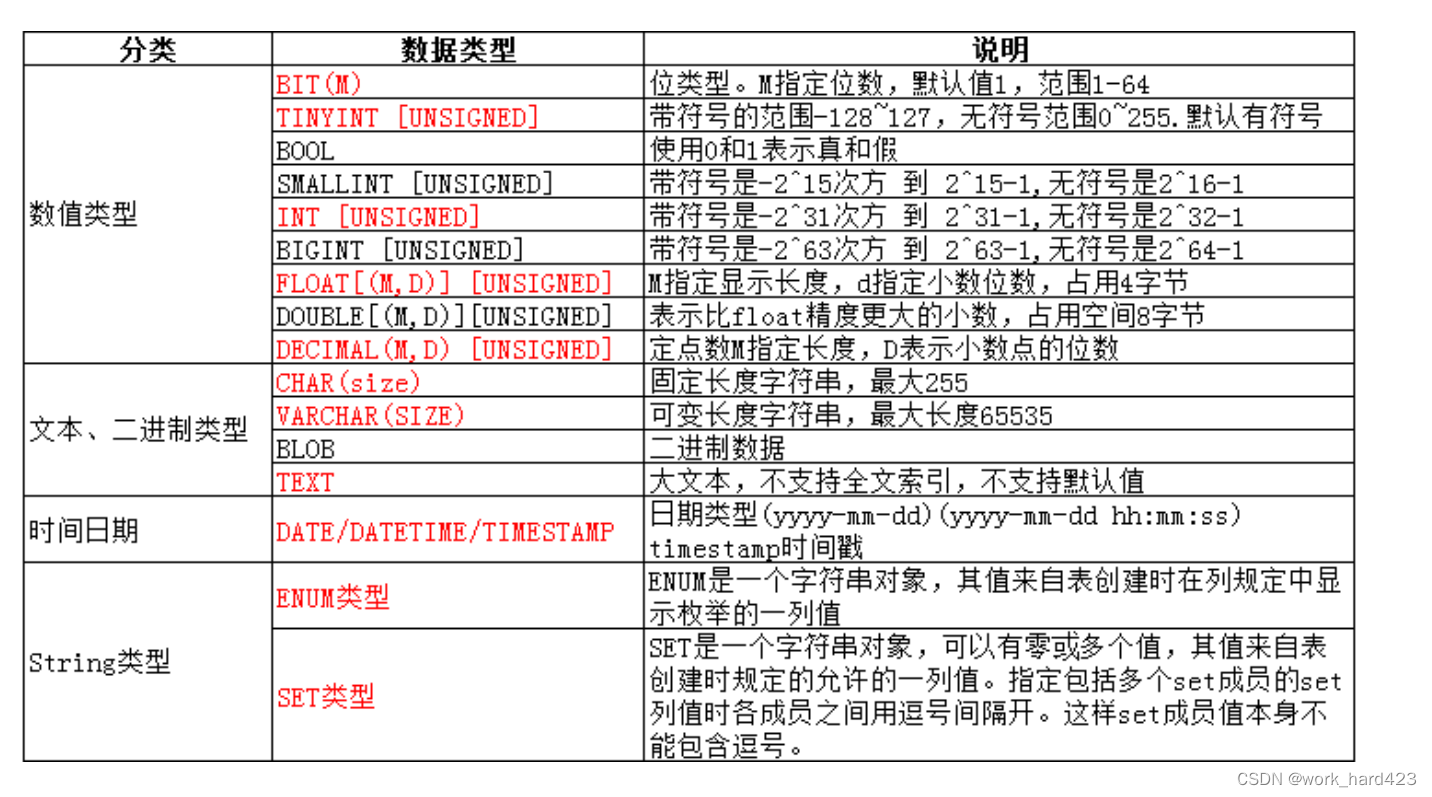
MySQL的数据类型分类
可以看到,共分为四大类,如下:
- 数值类型。
- 文本、二进制类型。
- 时间日期类型。
- String类型。
数值类型?
tinyint类型
有符号tinyint的范围测试
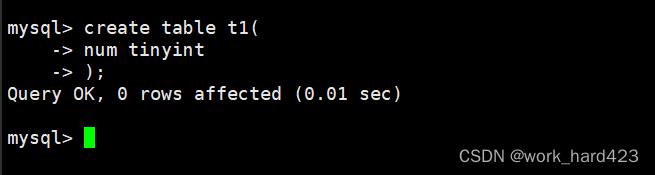
创建一个表,表当中包含一个tinyint类型的列,默认其为有符号类型。如下:
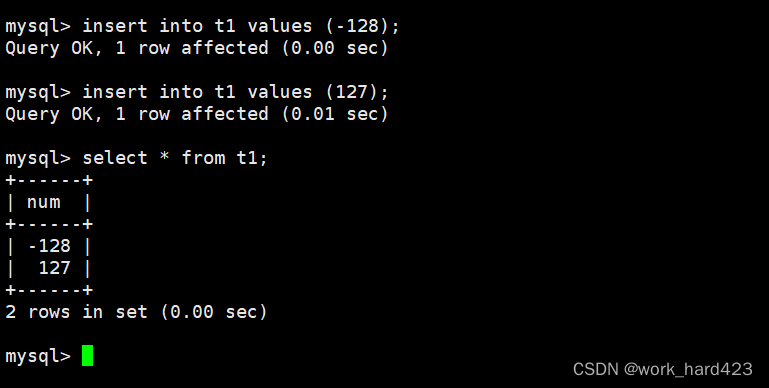
因为tinyint类型占用1字节、即8个比特位,所以有符号tinyint的取值范围为-128~127,插入该范围内的数据时都能成功插入。如下:
如果插入的数据不在-128~127范围内,那么插入数据时就会产生报错。如下:

无符号tinyint范围测试
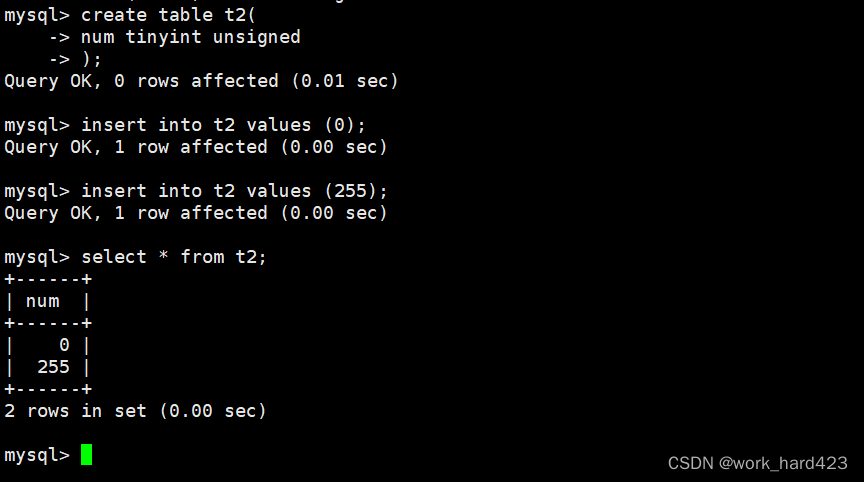
如下图所示,创建一个表,在创建表时设置一个无符号tinyint类型的属性。因为tinyint类型占用1字节、即8个二进制比特位,所以无符号tinyint的取值范围为0~255(8个二进制比特位全1即对应十进制的255),插入该范围的数据时都能成功插入。
如果插入的数据不在0~255范围内,那么插入数据时就会产生报错。如下:

bit类型
bit类型的显示方式
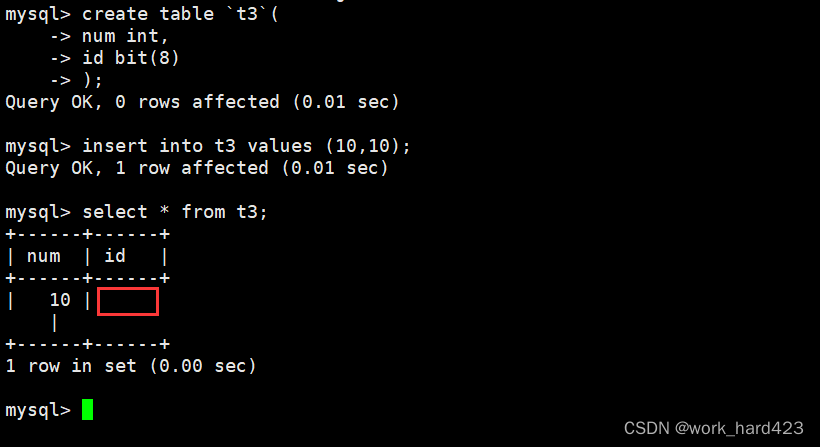
创建一个表,在创建表时设置一个int类型的num属性和一个8位bit类型的id属性。向表中插入一条记录,记录中指定num和id的值均为10,插入记录后查看表会发现如下图红框处所示,id的值显示的并不是整形10,而是一片空白,这是为什么呢?这是因为bit类型在显示时,是按照ASCII码对应的字符值进行显示的,而在ASCII码表中10对应的是控制字符LF,该字符是不可显的,所以就呈现成一片空白了。
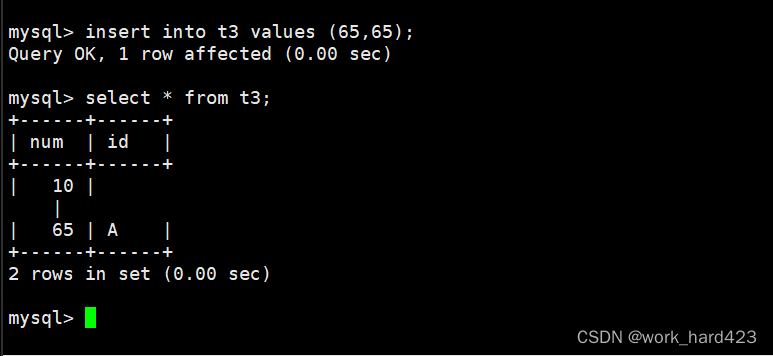
而如果向表中插入记录时指定num和id的值均为65,因为ASCII码表中65对应的是字符A,所以插入记录后查看表就会发现id的值显示的是A,如下。
bit类型的范围测试
如下图所示,创建一个表,在创建表时设置一个表示姓名的name属性和一个表示性别的gender属性,其中把gender属性的属性类型设置为1位bit类型(这是因为性别只有男和女两种取值,使用1个二进制比特位即可表示用户的性别,这样一来就可以节省空间),我们可以规定gender属性为0表示男,为1表示女,这样在插入用户信息时就可以通过插入0和1来指定用户的性别。
说一下,如下图红框处所示是一片空白的原因在上文讲解bit类型的显示方式时已经详细说过了,即因为bit类型在显示时,是按照ASCII码对应的字符值进行显示的,而在阿斯克码表中,整形的1和整形的0对应的是不可显字符,所以就是一片空白了。

而如下图所示,如果插入gender列的数据不是0或1,那么插入数据时就会产生报错(因为一个二进制比特位只能表示十进制的0和1,无法表示大于等于2的值)。

float类型
float类型全称为:float(m,d)?[unsigned],m指定显示长度,d指定小数位数,占用空间4个字节。
- 更通俗的说就是,m表示数值的总位数,即表示数值共有多少个数字,比如当float为5.6789时,共有5个数字,则m就是5;
- d表示小数点后面能保留几位,即表示小数点后面有多少数字,比如当float为5.6789时,小数点后有4个数字,所以d就是4。
- 说一下,是m、d在控制数值,而不是根据数值来确定m、d。
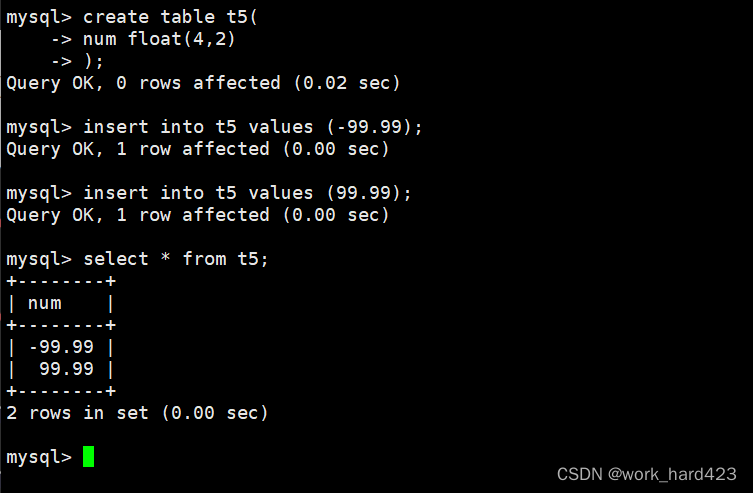
然后要知道的是,float(4,2)表示的范围是-99.99 ~ 99.99,然后因为MySQL在保存值时会进行四舍五入,所以实际可插入float(4,2)的范围为-99.994~99.994。同理,float(5,2)则表示的范围是-999.99 ~ 999.99,然后因为MySQL在保存值时会进行四舍五入,所以实际可插入float(5,2)的范围为-999.994~999.994。
有符号float范围测试
如下图所示,创建一个表,在创建表时设置一个有符号float(4,2)类型的num属性。因为float(4,2)的取值范围为-99.99~99.99,所以可以看到在下图中插入该范围内的数据都能成功插入。
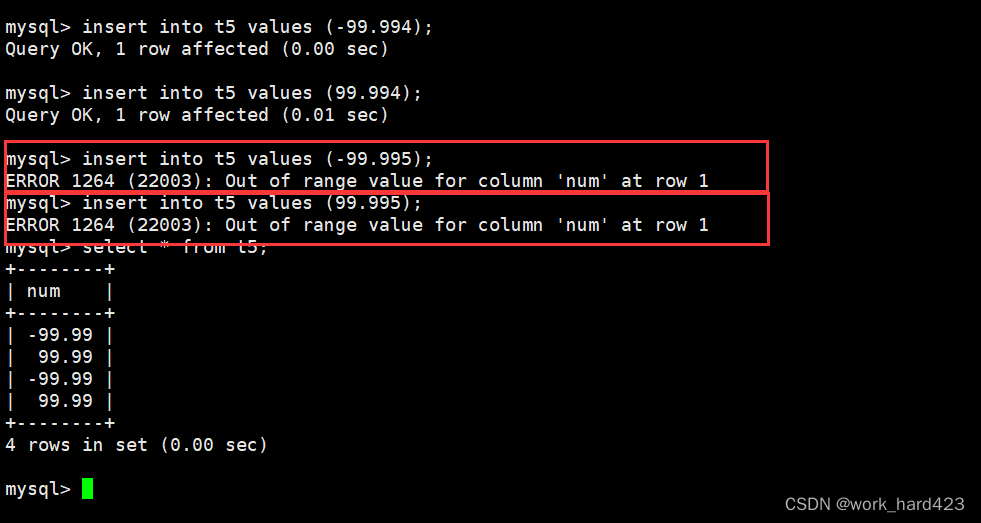
然后因为在上面说过,MySQL在保存值时会进行四舍五入,所以实际可插入float(4,2)的范围为-99.994~99.994,所以可以看到在下图中插入该范围内的数据都能成功插入;反之如果插入的数据不在该范围内,那么如下图红框处所示,插入数据时就会报错。
无符号float范围测试
如下图所示,创建一个表,在创建表时设置一个无符号float(4,2)类型的num属性。说一下,无符号float类型的取值范围,实际就是把有符号float类型中的负数部分拿走了,所以无符号float(4,2)的取值范围为0~99.99,又因为MySQL在保存值时会进行四舍五入,所以实际可插入的范围是0~99.994,可以看到在下图中插入这个范围内的值都能插入成功。
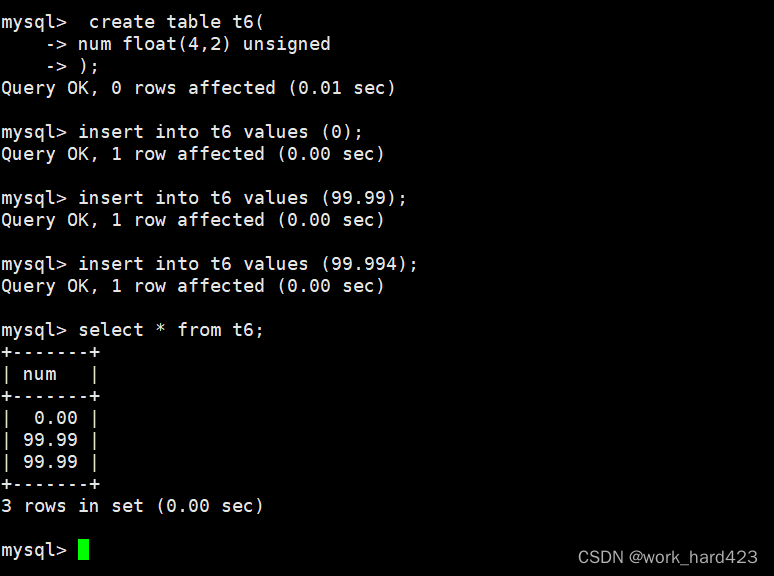
如果插入的数据不在0~99.994范围内,那么插入数据时就会产生报错。如下:

decimal类型
decimal类型和float类型的使用方式以及性质完全一样,唯一的区别在于decimal的精度比float更高,咱们来证明一下这一点。
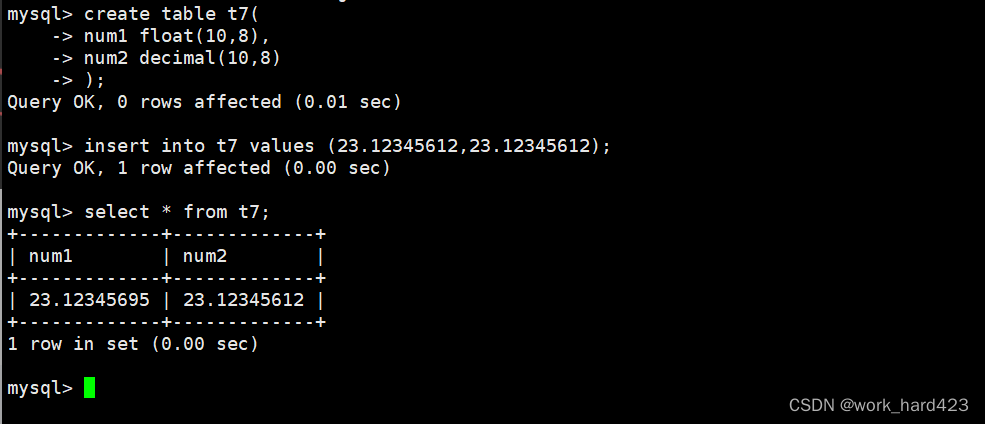
如下图所示,创建一个表,在创建表时分别设置一个float(10,8)类型的属性num1和一个decimal(10,8)类型的属性num2。然后向表中插入一条记录,指定float和decimal的值均为23.12345612,但最终查表时会发现decimal保持了数据的原貌,而float则会存在一定的精度损失,这就证明了decimal的精度比float更高。
字符串类型
char类型
char类型的测试
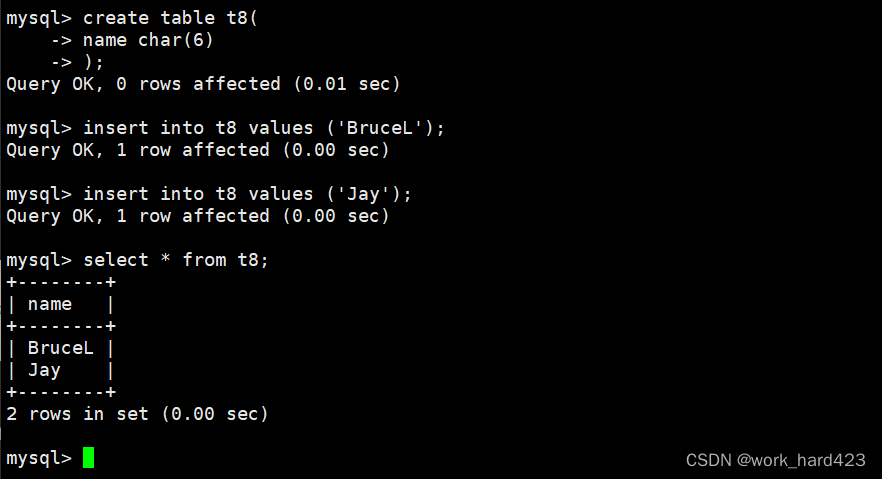
如下图所示,创建一个表,在创建表时设置一个类型为char(6)的属性content。因为char(6)中最多可存储6个字符,所以只要插入的字符个数不超过6个都是能够成功插入的,可以看到下图中的情况的确如此。
但如果插入的字符个数超过了6个,那么在插入数据时就会产生报错。如下:

需要注意的是,这里所说的字符并不只是指一个英文字母,一个汉字也是一个字符,因此只要插入的汉字个数不超过6个也是可以插入的。如下:
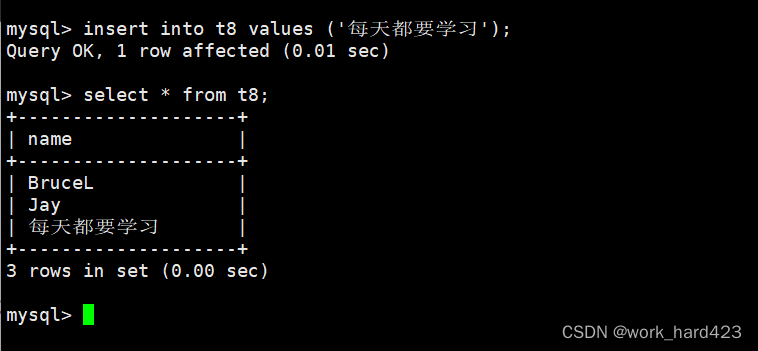
走到这里我们再来完整的介绍char类型,如下。
- char类型全称为:char(L),表示固定长度字符串,L表示最大可存储多长的字符,L最大可以为255。因为上文中char(6)竟然能存6个汉字,所以从上面的测试我们就能知道,L的单位是字符,而不是字节。
- 说char(L)是固定长度字符串是因为MySQL为char(L)开空间时只根据L的大小决定,比如L是100时,则就开100个字符所占的空间大小,即使只存储5个字符,也开100个字符所占的空间大小。问题来了,那char(100),即100个字符所占多少字节的空间呢?
- 答案是,在不同编码中,一个字符所占的字节个数是不同的,比如utf8中一个字符占3个字节,所以如果该表采用的字符集是utf8,则100个字符就是300字节的空间,而gbk中一个字符占2个字节,所以如果该表采用的字符集是gbk,则100个字符就是200字节的空间。问题来了,为什么char(L)类型不让L的单位是字节,而要让L的单位是字符呢?
- 答案是,因为每张表采用的字符集都可能是不一样的,如果让L的单位是字节,那么用户使用char(L)类型时还需要先查看当前表的字符集是什么,然后再根据要存多少个字符手动计算要开多少的空间,这样对用户来说就太不方便了;而如果让L的单位是字符,用户在使用char(L)类型时就不用关心复杂的编码细节了,大概要存多少字符就直接让L等于多少即可。
varchar类型
varchar类型全称为:varchar(L),表示变长字符串。varchar类型和char类型的使用方式完全一样,他俩的区别只有两个,如下。
其一是可指定的字符个数上限,也就是L的上限不一样。
varchar类型最多占用65535字节,其中有1~2字节用来表示实际数据长度,还有1字节来存储其他控制信息,因此varchar类型的有效字节数最多是65532字节。
而因为在不同编码中,一个字符所占的字节个数是不同的,所以varchar类型可指定的字符个数上限与表采用的字符集有关:
- 对于utf8编码来说,因为一个字符占用三个字节,所以varchar(L)中的L最大可指定为 65532 ÷ 3 = 21844。
- 对于gbk编码来说,因为一个字符占用两个字节,所以varchar(L)中的L最大可指定为 65532 ÷ 2 = 32766。
- 而char(L)类型的可存储字符上限是255,这就是char(L)和varchar(L)的第一个区别。
其二就是相比于char这种固定长度的字符串,varchar是变长的字符串。
在上文中说过,char(L)定义后,比如定义为char(100),则即使存储的字符串长度没有到达100,比如只存储了abcd共4个字符,则也会开辟用于存储100个字符的定长字节的空间(比如如果表采用的字符集是utf-8,则开辟100*3字节的空间;如果该表采用的字符集是gbk,则开辟100*2字节的空间),如果存储的字符串长度超过L则会报错。
而varchar(L)定义后,比如定义为varchar(100)后,如果只存储了abcd共4个字符,则只会开辟用于存储4个字符的空间(比如如果表采用的字符集是utf-8,则开辟4*3字节的空间;如果该表采用的字符集是gbk,则开辟4*2字节的空间)和开辟1~3字节的用于表示存储字符串的长度以及其他控制信息的空间,如果存储的字符串长度超过L则会报错。
这就是为什么要叫varchar为变长字符串的原因了,同时这也是char和varchar的第二个区别。
如何选取char和varchar类型?
char和varchar的优缺点如下:
- char类型的数据是定长的,因此磁盘空间比较浪费,但是效率高(直接访问定长的空间)。
- varchar类型的数据是变长的,因此磁盘空间比较节省,但是效率低(需要先读取存储字符串的长度,再访问指定长度的空间)。
如果要存储的数据是定长的,那就使用char类型进行存储,比如身份证号码、手机号、md5等。如果要存储的数据是变长的,那就使用varchar类型进行存储,比如名字、地址等。
时间日期类型
date、datetime和timestamp类型
常用的三种时间日期类型如下:
- date:日期格式为YYYY-MM-DD,占用三字节。
- datetime:时间日期格式为YYYY-MM-DD HH:MM:SS,占用八字节。
- timestamp:时间戳,格式为YYYY-MM-DD HH:MM:SS,占用四字节。
如下图所示,创建一个表,在创建表时设置date类型的属性、设置datetime类型的属性、设置timestamp类型的属性。

如下图所示,desc查看表结构时可以看到timestamp类型的属性t3是不允许为空的(下图红框处的NO就是依据),它的Default默认值为CURRENT_TIMESTAMP。
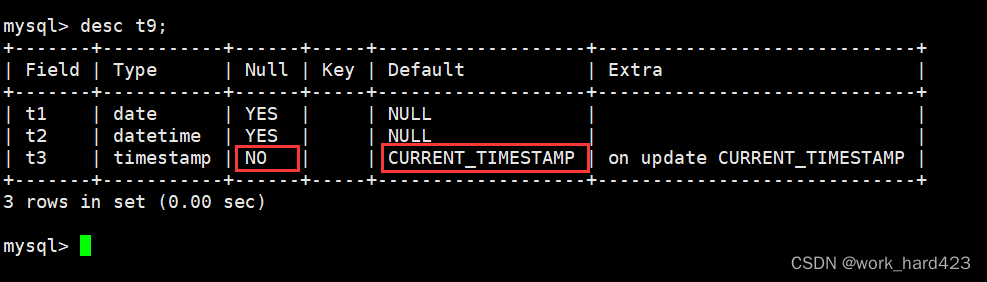
所以如果插入数据时不设置属性t3的值,MySQL就会自动插入当前的时间戳,也就是你此时此刻的精确到秒的日期(下图红框处的自动被插入的日期就是依据)。

String类型
enum和set类型
enum可以认为就是C语言中的枚举,而set则非常像C语言中的枚举,比如说:
- 在创建表设置enum类型的属性A时,需要给该属性A提供若干个选项,往后用户往该表中插入数据时,对于enum类型的属性A的值,则只能在之前提供的若干个选项中选择一个作为属性A值。
- 在创建表设置set类型的属性A时,需要给该属性A提供若干个选项,往后用户往该表中插入数据时,对于set类型的属性A的值,则可以在之前提供的若干个选项中选择任意个作为属性A值。
比如人的性别只能从男和女中进行二选一,因此可以将属性gender设置成enum类型,而人的爱好hobby在提供的选项中可能存在多个,因此可以将其定义成set类型。
enum和set类型的测试
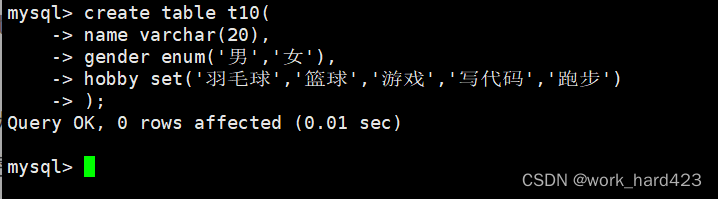
如下图所示,创建一个表,在创建表时设置一个类型为enum的属性gender和一个类型为set的属性hobby。
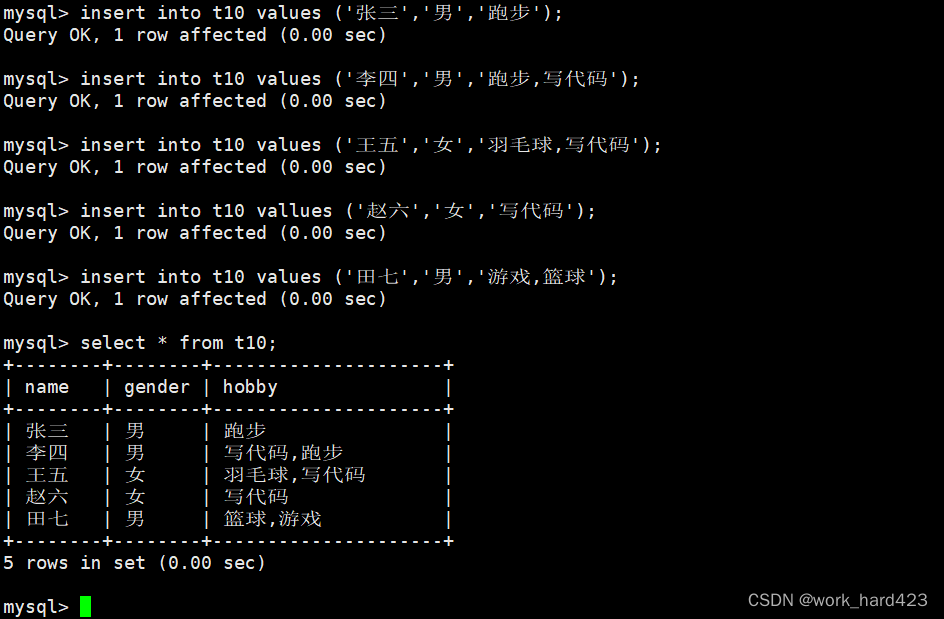
如下图所示,向表中插入记录时,因为性别gender这个属性的属性类型是enum,所以只能从男和女中进行二选一,如果选择多个或者选择不属于选项中值,则会报错;而因为爱好hobby这个属性的属性类型是set,所以选择时可以从选项中选择任意个,如果选择不属于选项中的值,则会报错。
通过数字设置enum
如下图所示,在插入数据时,除了通过指明男女来设置性别,还可以通过插入数字1和2来设置性别,这是因为MySQL出于效率考虑,在存储enum类型的属性的值时实际存储的都是数字,enum中提供的选项值依次对应数字1、2、3、…,最多65535个,因此在设置enum类型的属性gender的值时可以通过数字的方式进行设置。

通过数字设置set
在插入数据时,除了通过指明选项来设置爱好,还可以通过插入数字来设置爱好,这是因为MySQL出于效率考虑,在存储set类型的属性的值时实际存储的也都是数字。
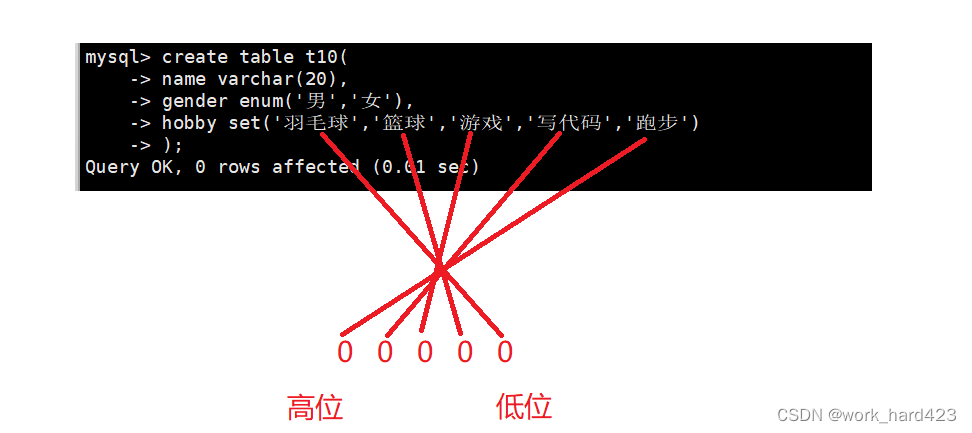
并且注意,在设置set类型的属性hobby的值时,类似于位图bitset,是按照比特位的方式进行设置的,举个例子,如下图所示,一个二进制序列的最低位对应第一个选项,高一位对应第二个选项....,所以如果设置set类型的属性hobby的值时设置为1,则十进制1的二进制为00001,所以就相当于把属性hobby的值设置为'羽毛球';如果设置set类型的属性hobby的值时设置为3,则十进制3的二进制为00011,所以就相当于把属性hobby的值设置为'羽毛球,篮球';如果设置set类型的属性hobby的值时设置为31,则十进制31的二进制为11111,所以就相当于把属性hobby的值设置为'羽毛球,篮球,游戏,写代码,跑步'。
如下图的测试结果即可证明上面的理论的确是正确的。
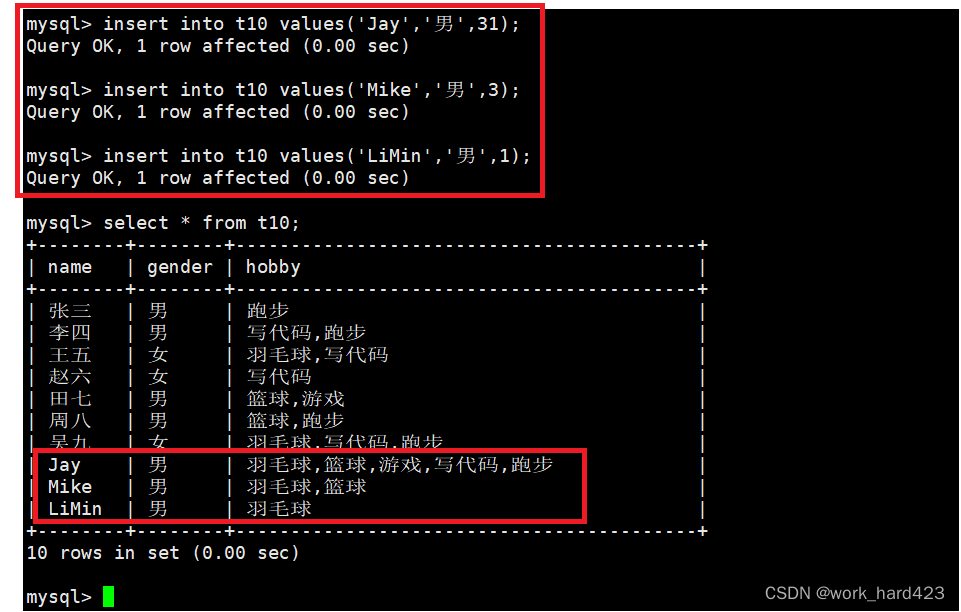
建议:
- 虽然enum和set类型的属性的值可以通过数字的方式进行设置,但严重不推荐这种做法,因为这样的SQL可读性太差,会导致后期维护成本变高。
enum和set的查找
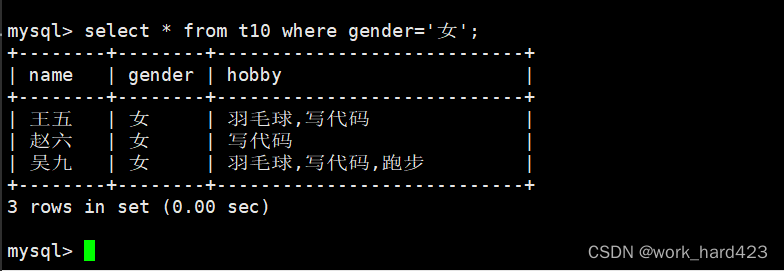
如果想要筛选出表中所有女同志的信息,那么直接在筛选时指明gender='女'即可,如下:
但如果要筛选出表中爱好包含写代码的人的信息(即除了写代码,还有其他爱好的人的信息)就比较麻烦了,因为上面的查找方式是严格匹配的,比如如果继续使用上述方式,那么最终筛选出来的是爱好只有写代码的人的信息(即除了写代码,没有其他爱好的人的信息)。如下: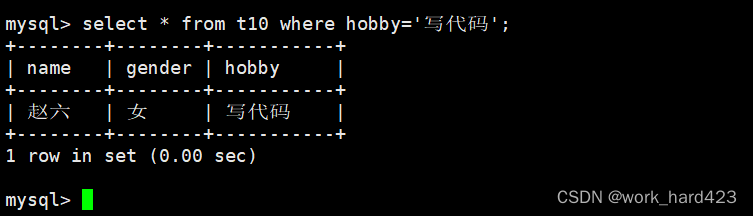
有同学可能会说采用模糊匹配查询,注意这是不行的,因为enum和set类型的属性的值底层都是整形数字,而只有字符类型才可以模糊匹配。那到底该怎么办呢?
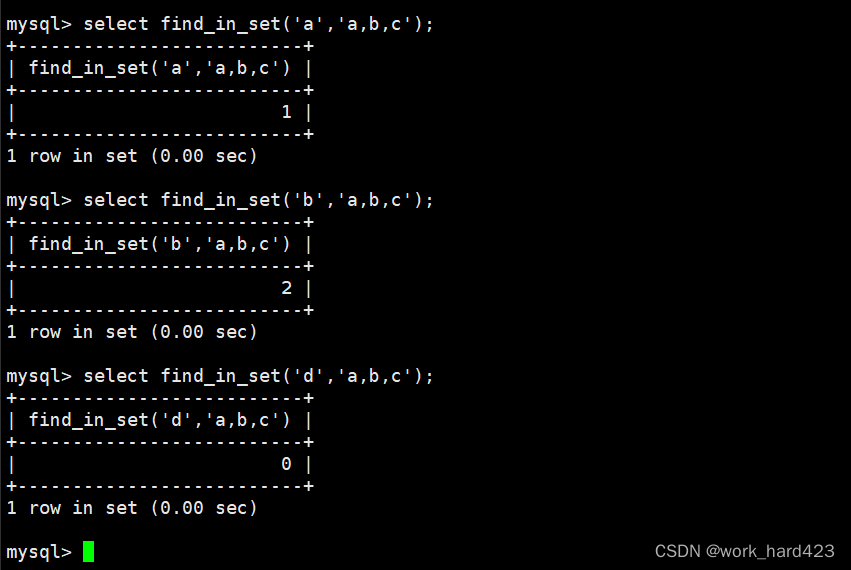
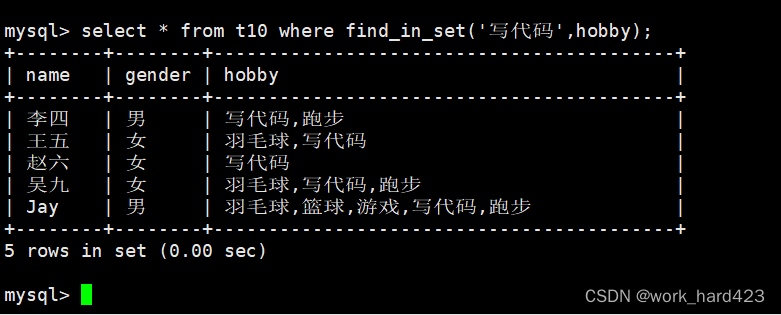
这时就需要借助一个函数,即find_in_set(str,str_list)了,该函数的作用是查询str_list中是否包含str,如果包含则返回str在str_list中的位置(从1开始),否则返回0。举个例子,如下图所示,通过select可以对find_in_set函数进行验证,比如我们依次在集合【a、b、c】中查找是否包含字符a、是否包含字符b、死否包含字符d,这时在查找字符a和b时就会得到其在集合中的下标,而在查找字符d时就会得到0值。
同理,我们就可以通过select搭配find_in_set函数筛选出爱好包含敲代码的人的信息了(即除了写代码,还有其他爱好的人的信息)。如下:
最后的感悟
学完所有的数据类型后,我们就能深刻地体会为什么要有不同的数据类型,就是因为数据类型:
- 决定了存储数据时应该开辟的空间大小。
- 决定了如何MySQL识别一个特定的二进制序列。
- 决定了数据的取值范围。
- 还能反过来约束用户,比如如果插入的数据不符合数据类型的规定,则不让用户插入(原因在下面),这本质上也是我们以后要讲解的约束的一种。
说一下,在C或者C++中,按照我们的经验,如果定义一个unsigned int x = -1是不会报错的,只是会有警告,不报错的原因是因为编译器觉得用户可能是故意利用-1让x等于整形最大值INT_MAX,所以编译器只会有一个警告提示用户,而不会强制报错。但MySQL就不一样了,如果在MySQL中让一个unsigned int类型的属性x的值等于-1,则MySQL会直接报错,不让你插入这条非法的数据。为什么呢?
对于数据库来说,如果允许让unsigned int x等于-1,则它会想,用户到底是想插入一个-1,还是想插入INT_MAX呢?如果用户只是想插入-1,但误操作把属性的类型设置成了无符号类型,这时我存储INT_MAX,未来会不会给用户造成麻烦呢?如果真的造成了麻烦,则往后用户在查表时查出来一个数据后,他是否会不信任这个数据的真实性呢?所以为了避免这些情况发生,数据库就干脆不允许让unsigned int x等于-1。以小见大,这也是为什么如果用户插入的值不符合MySQL的数据类型的规定(比如超出范围),则不让用户插入的本质原因了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!