消息中间件
文章目录
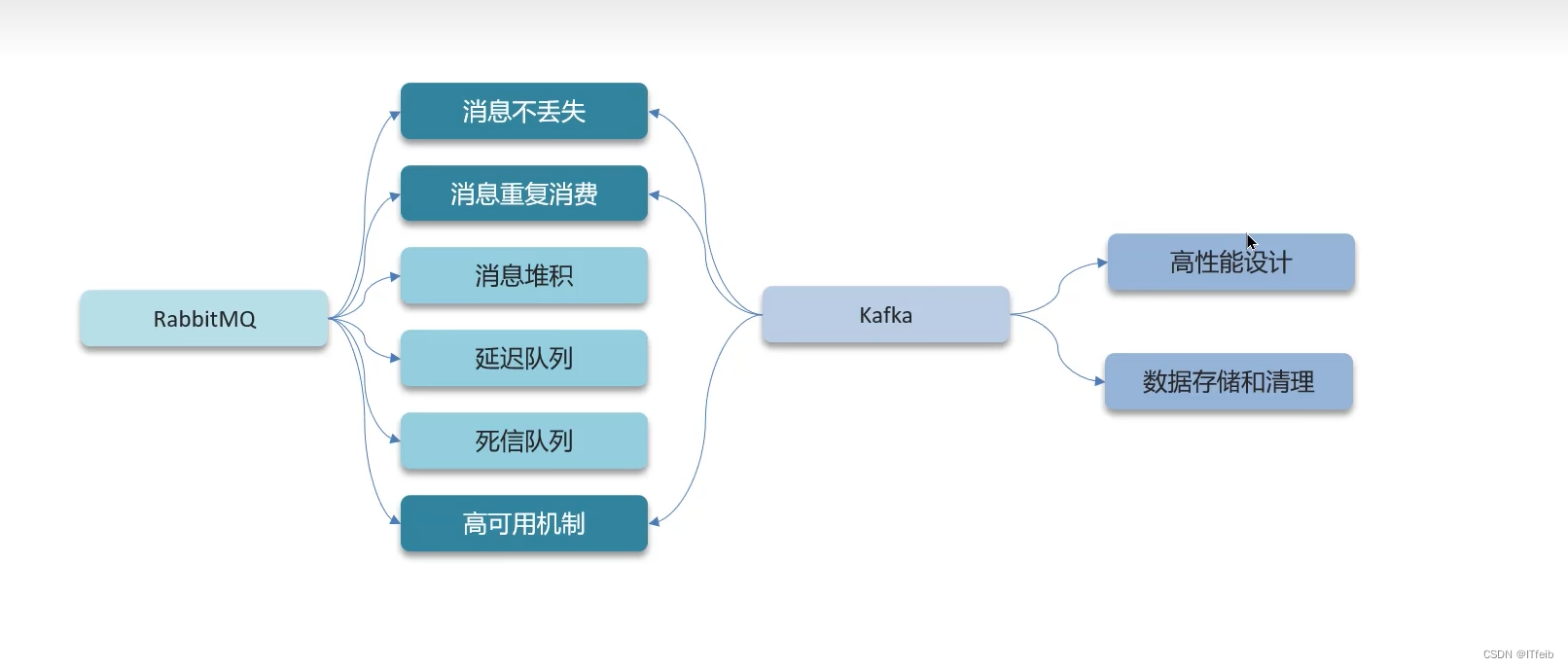

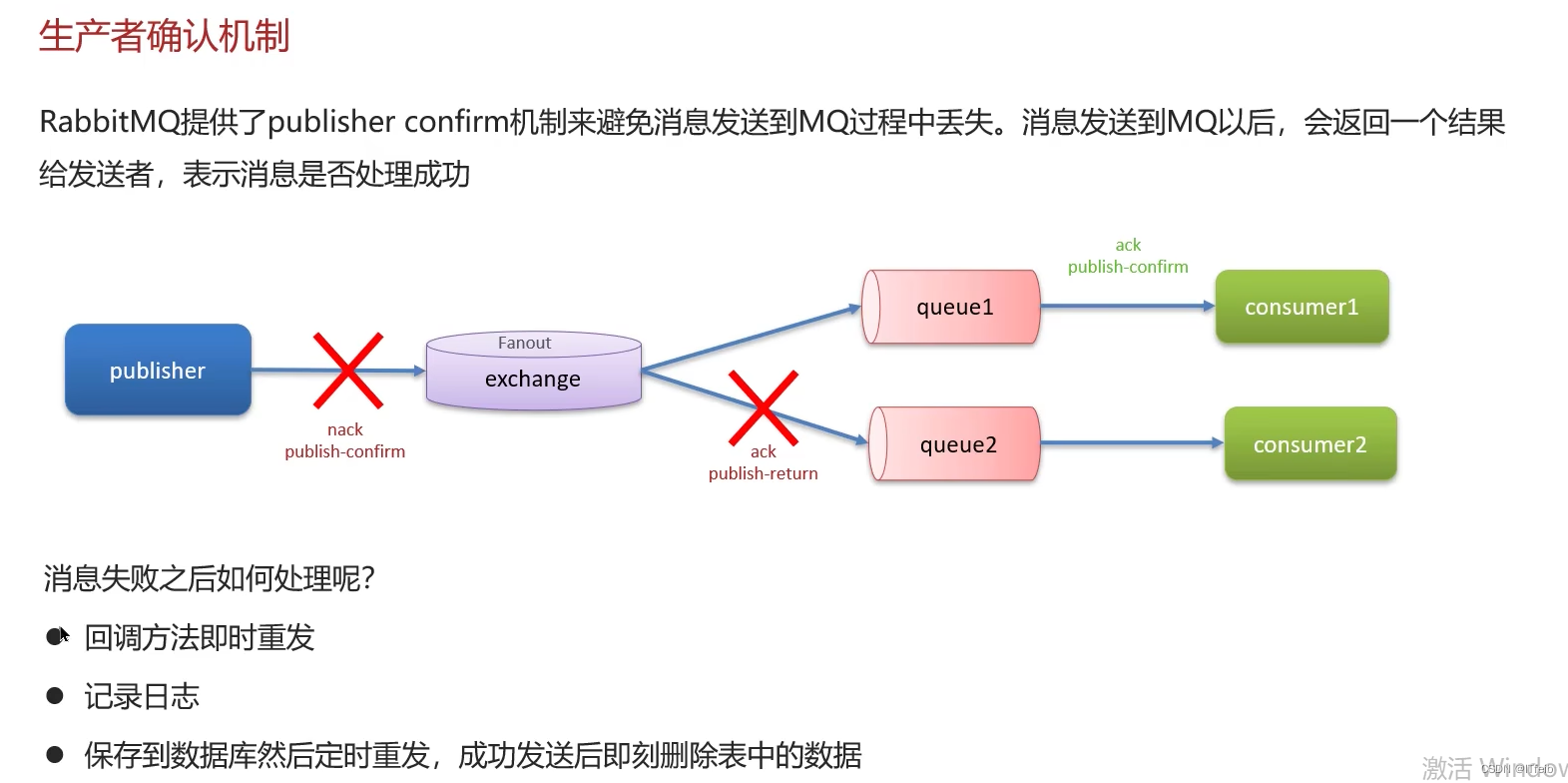
1. 消息不丢失

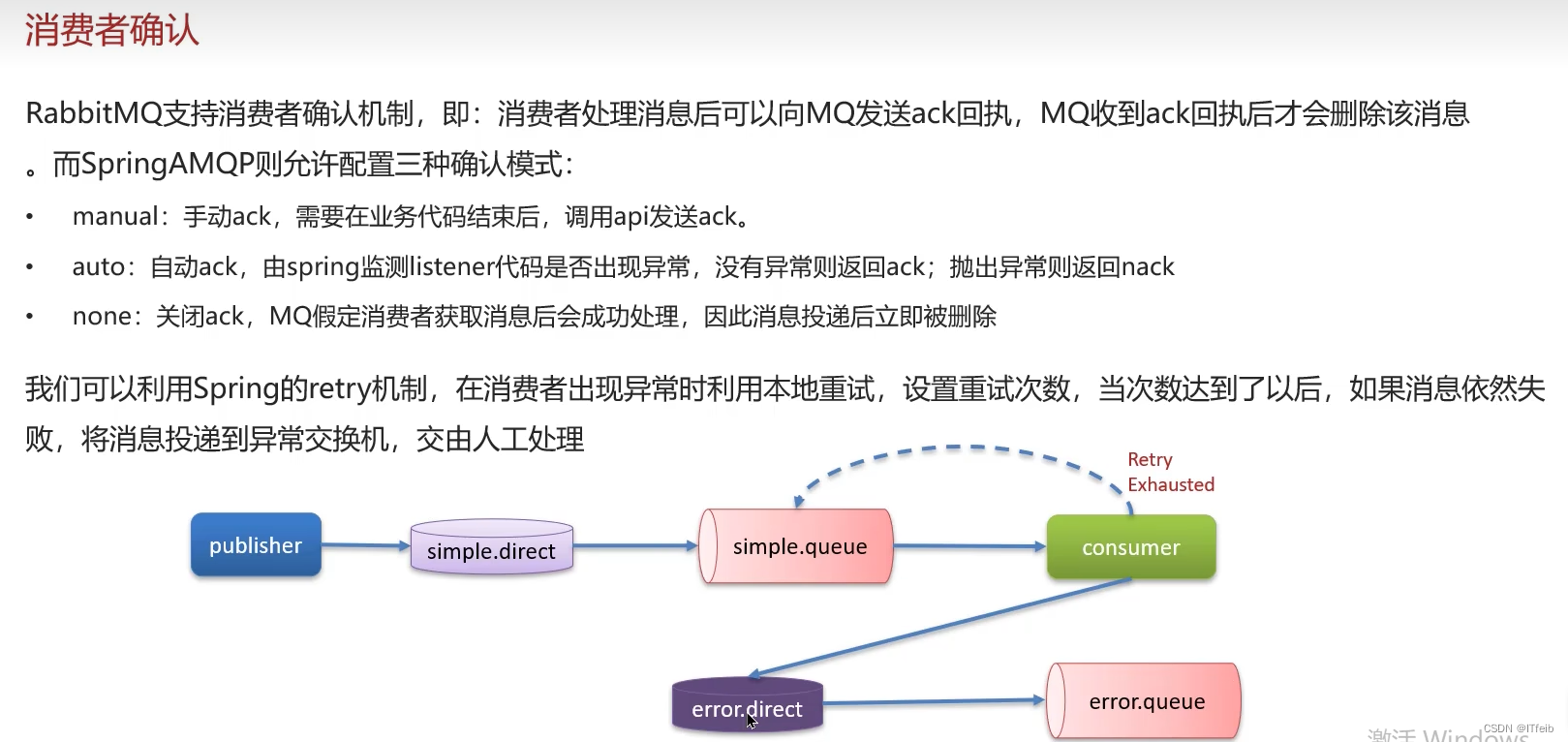
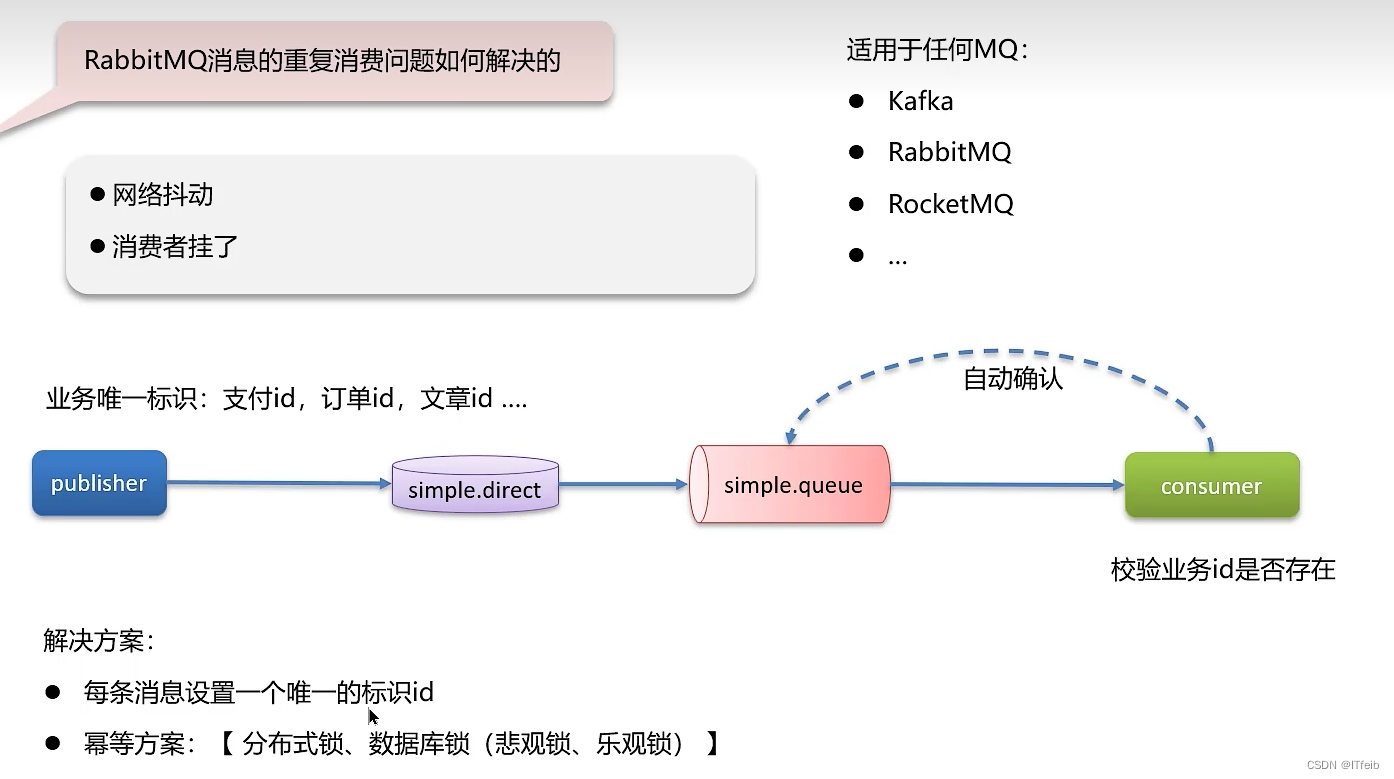
2. 消息重复消费
3. 死信交换机实现延时队列
延时队列 = 死信交换机 + TTL
延时队列用在有时间限制的消息的消费问题,可以对消息设置超时时间,当消息超时后就会转发到死信交换机,它也绑定了队列,比如说一个订单,时间到了之后就会由死信交换机路由到队列,拿到这个消息后判断是不是已经支付成功,没有支付成功的话就取消订单。
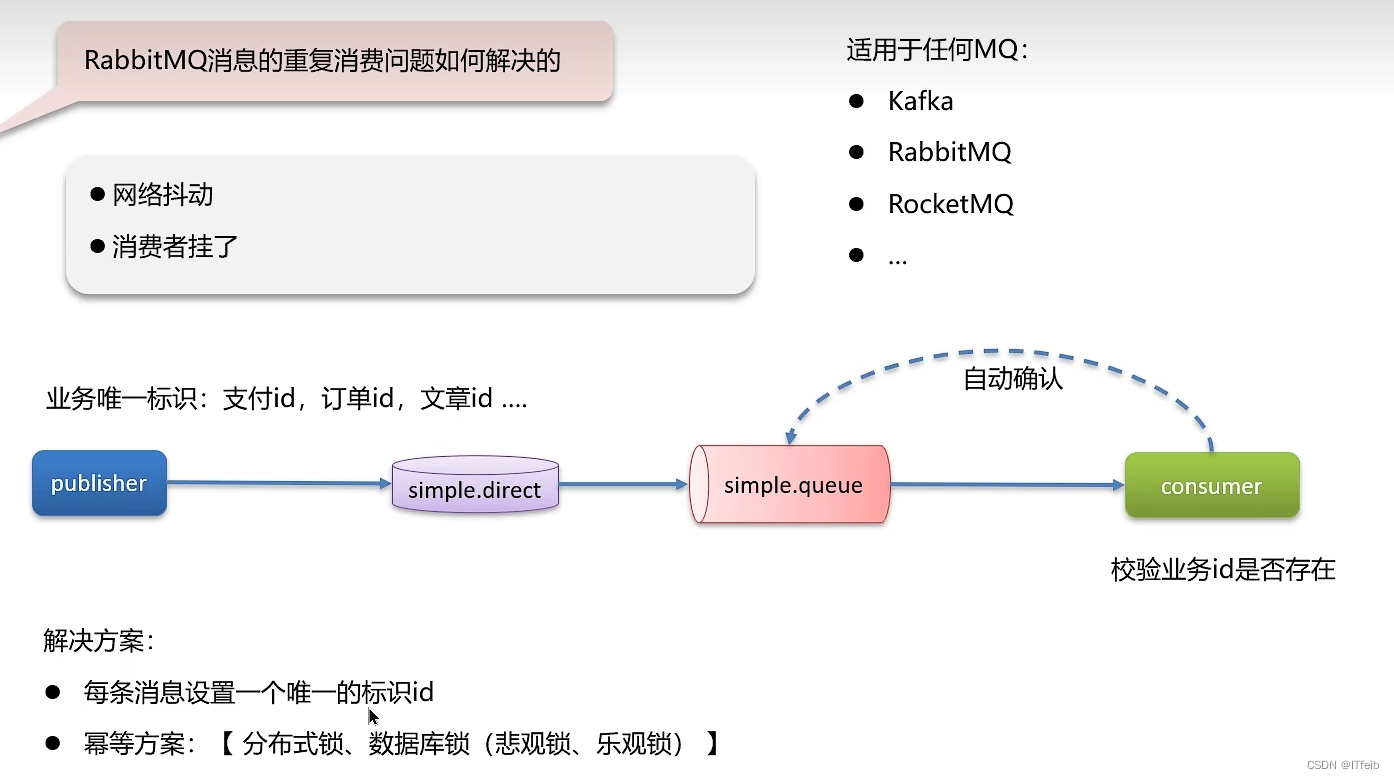
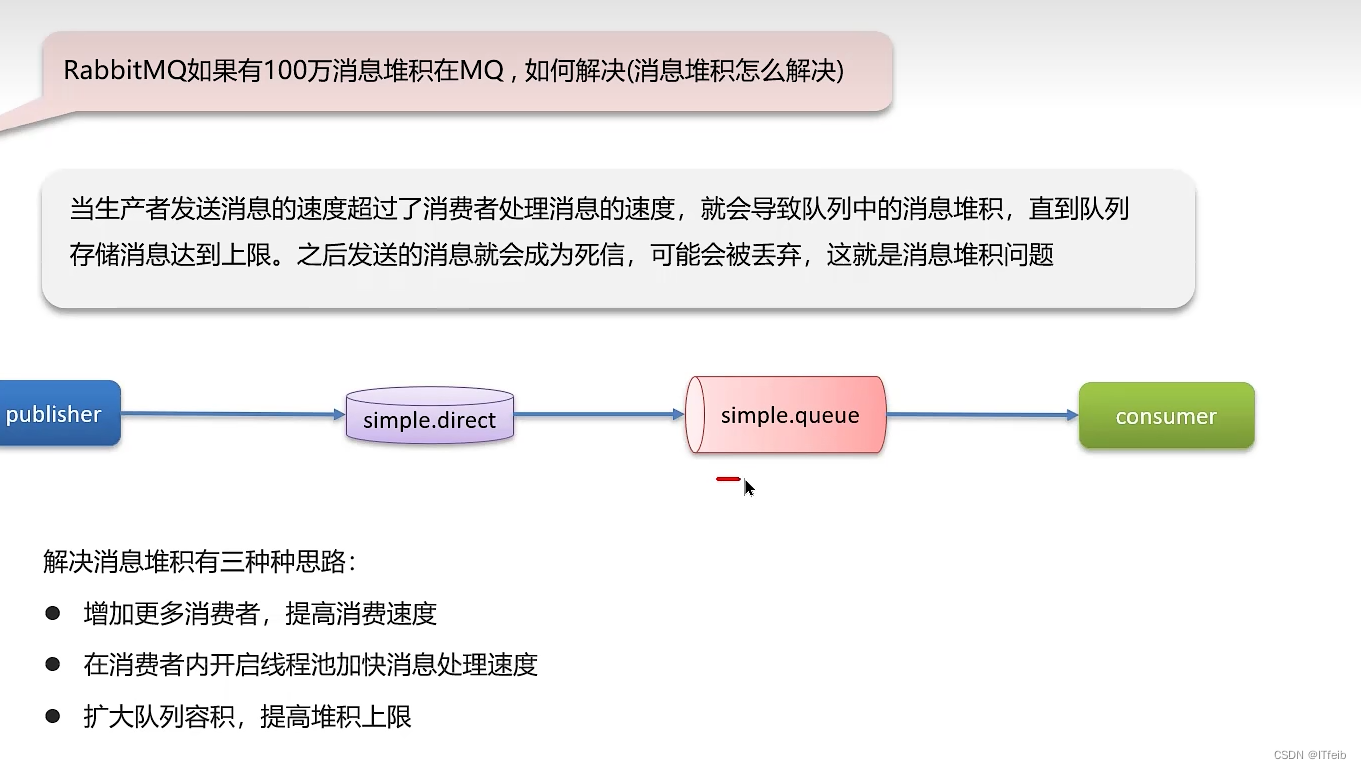
4. 消息堆积问题

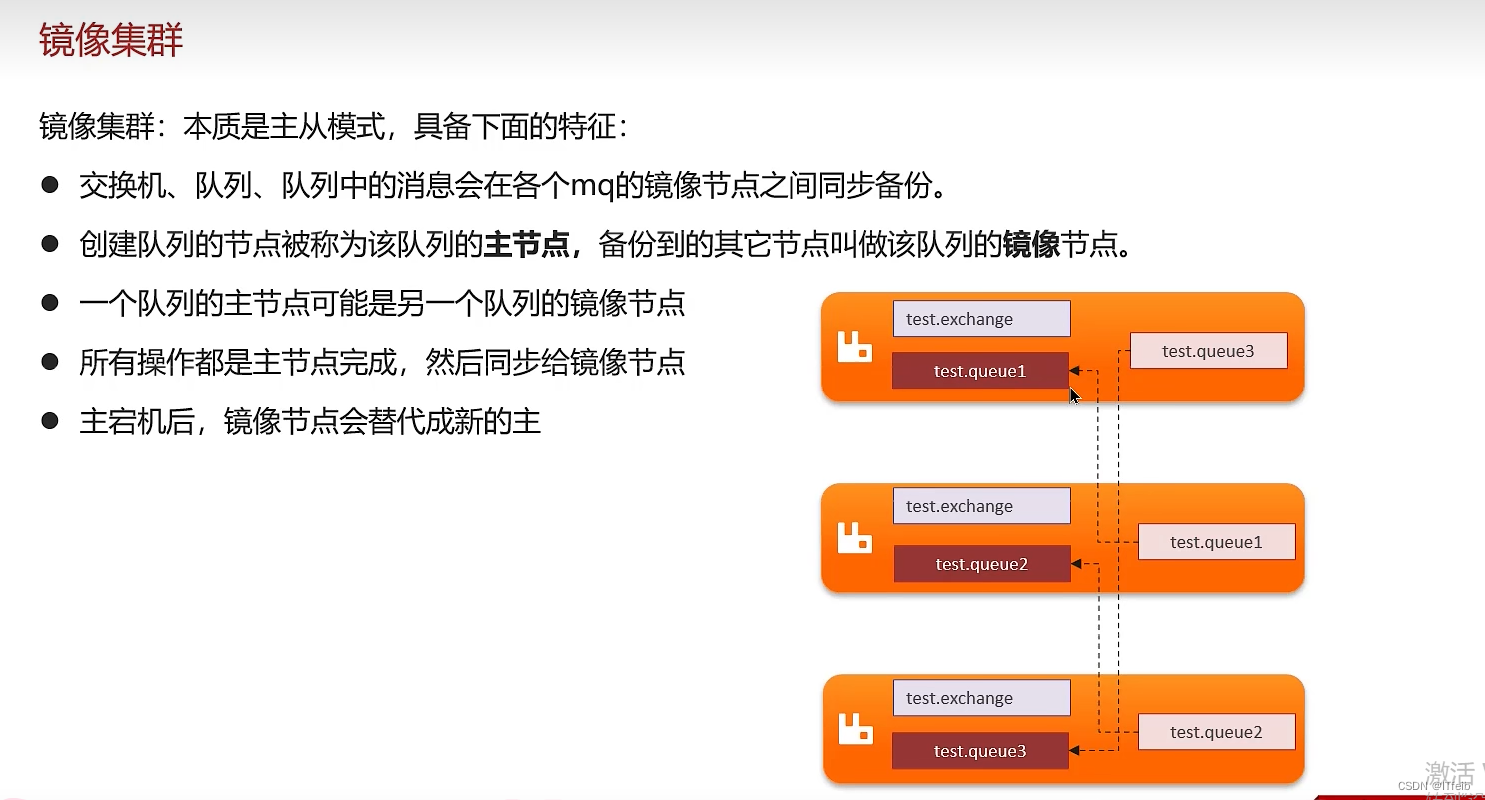
5. rabbitMQ高可用机制
镜像队列和仲裁队列


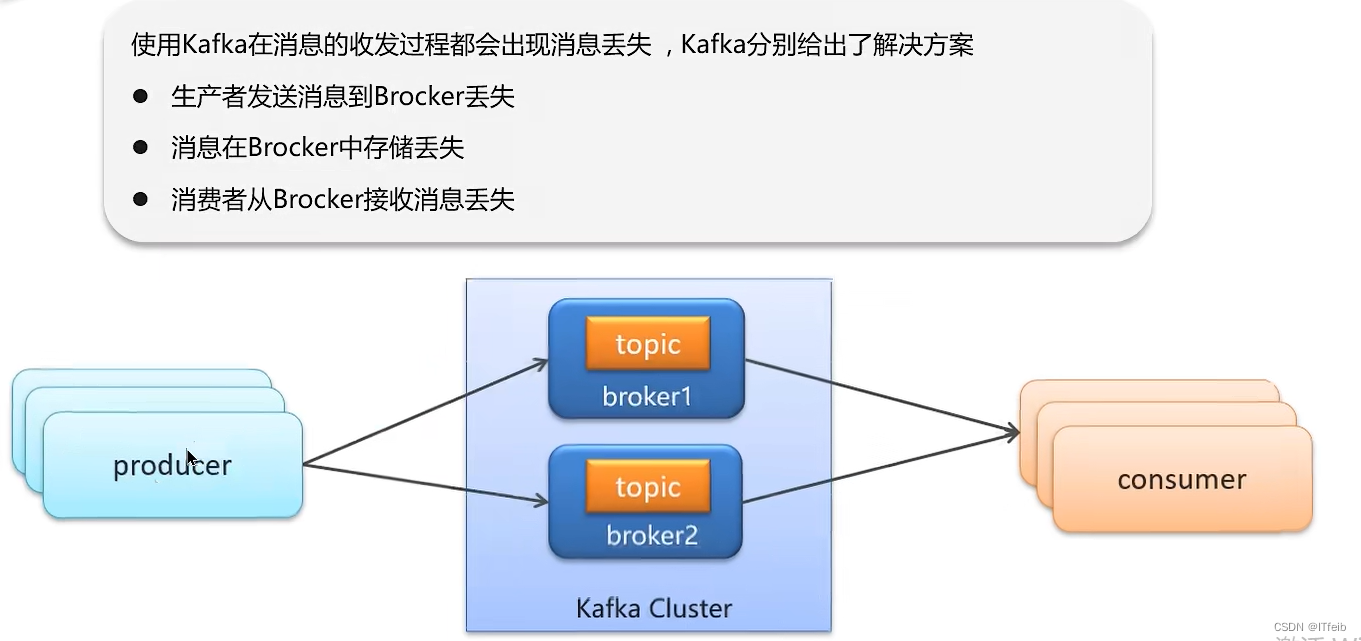
6. Kafka是如何保证消息不丢失的
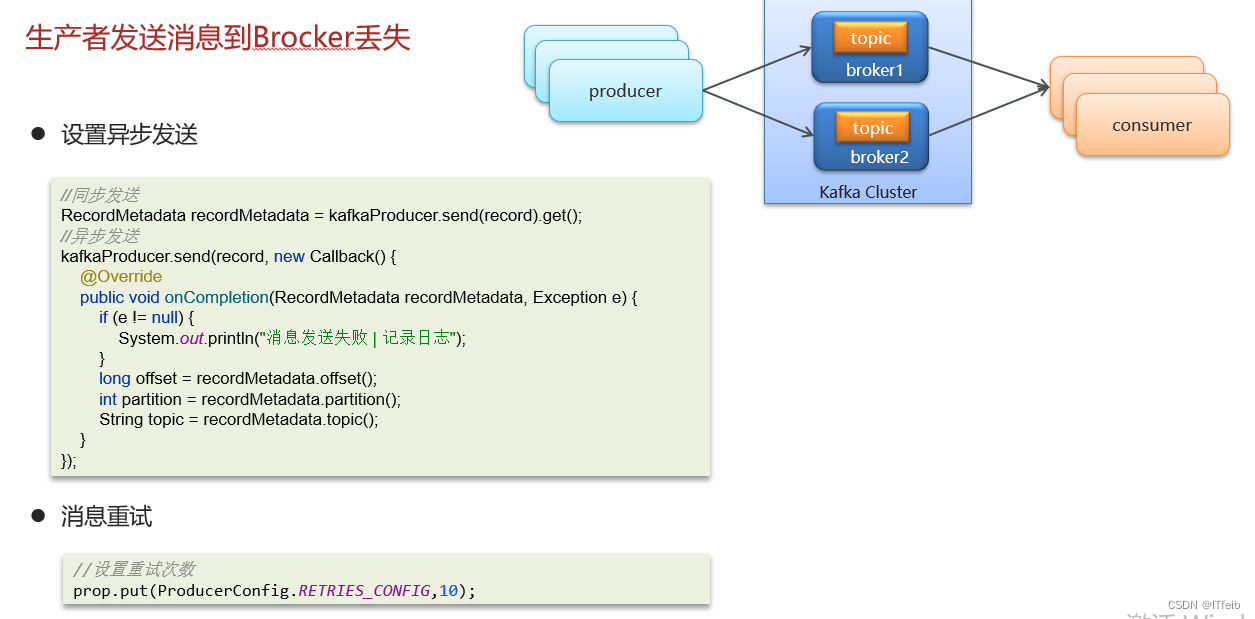
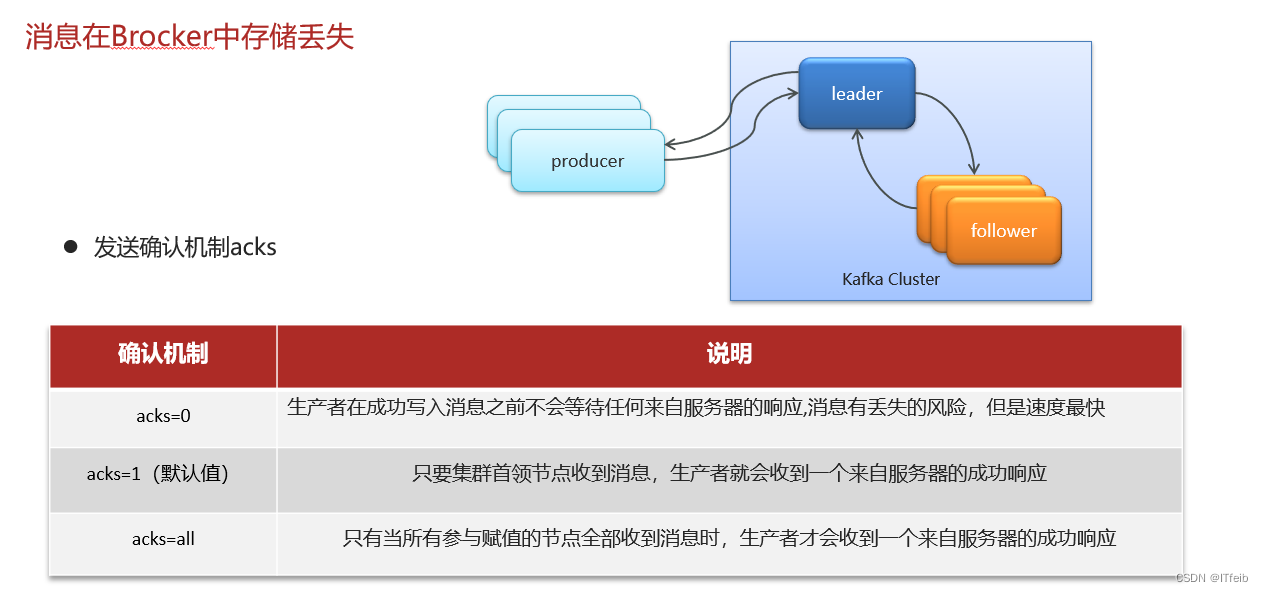
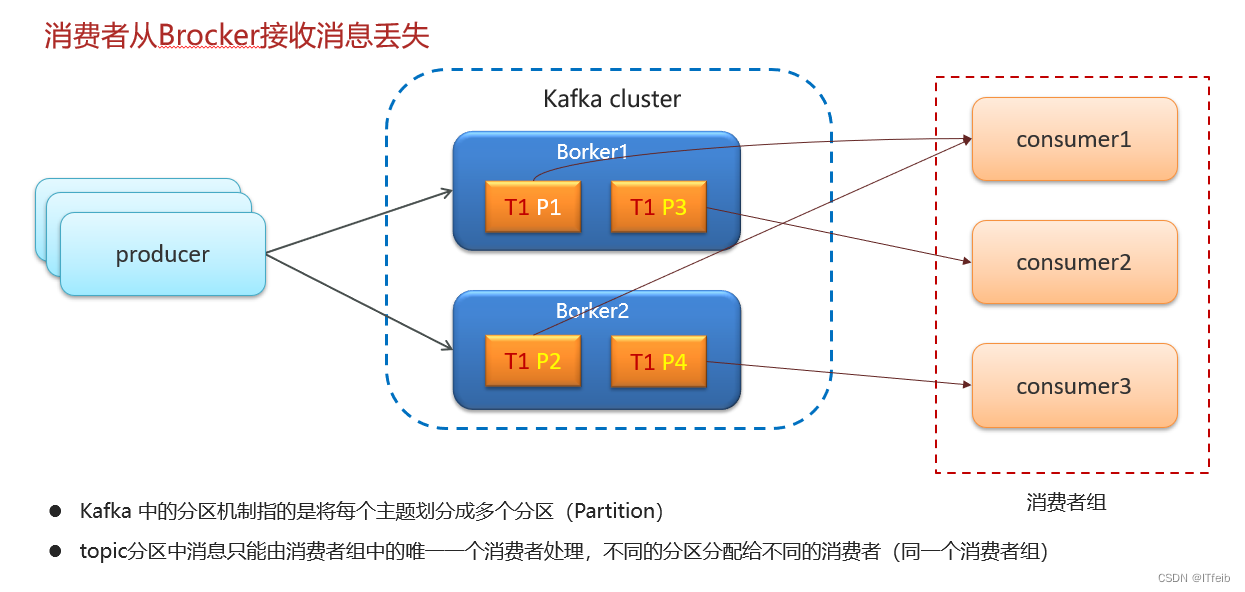

7. 消息的顺序消费
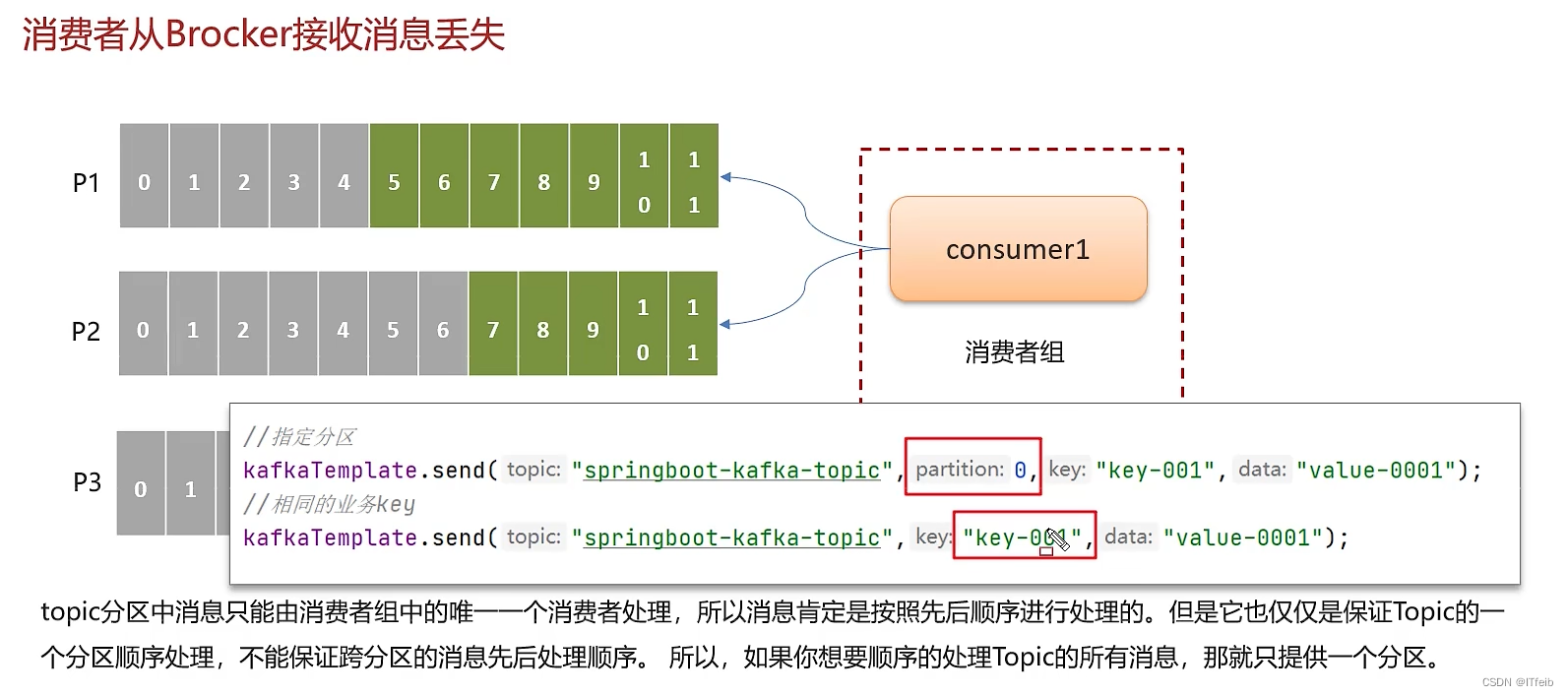

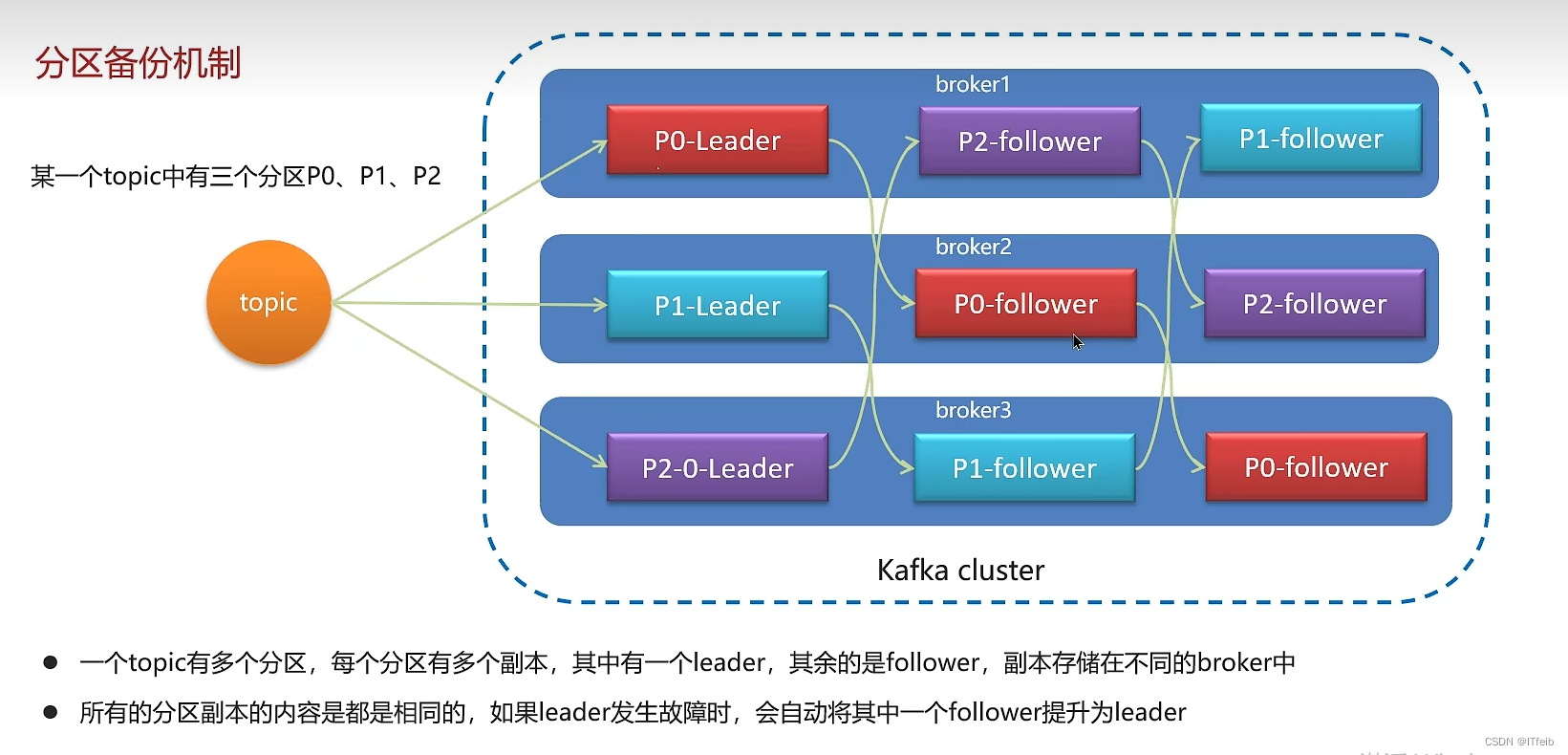
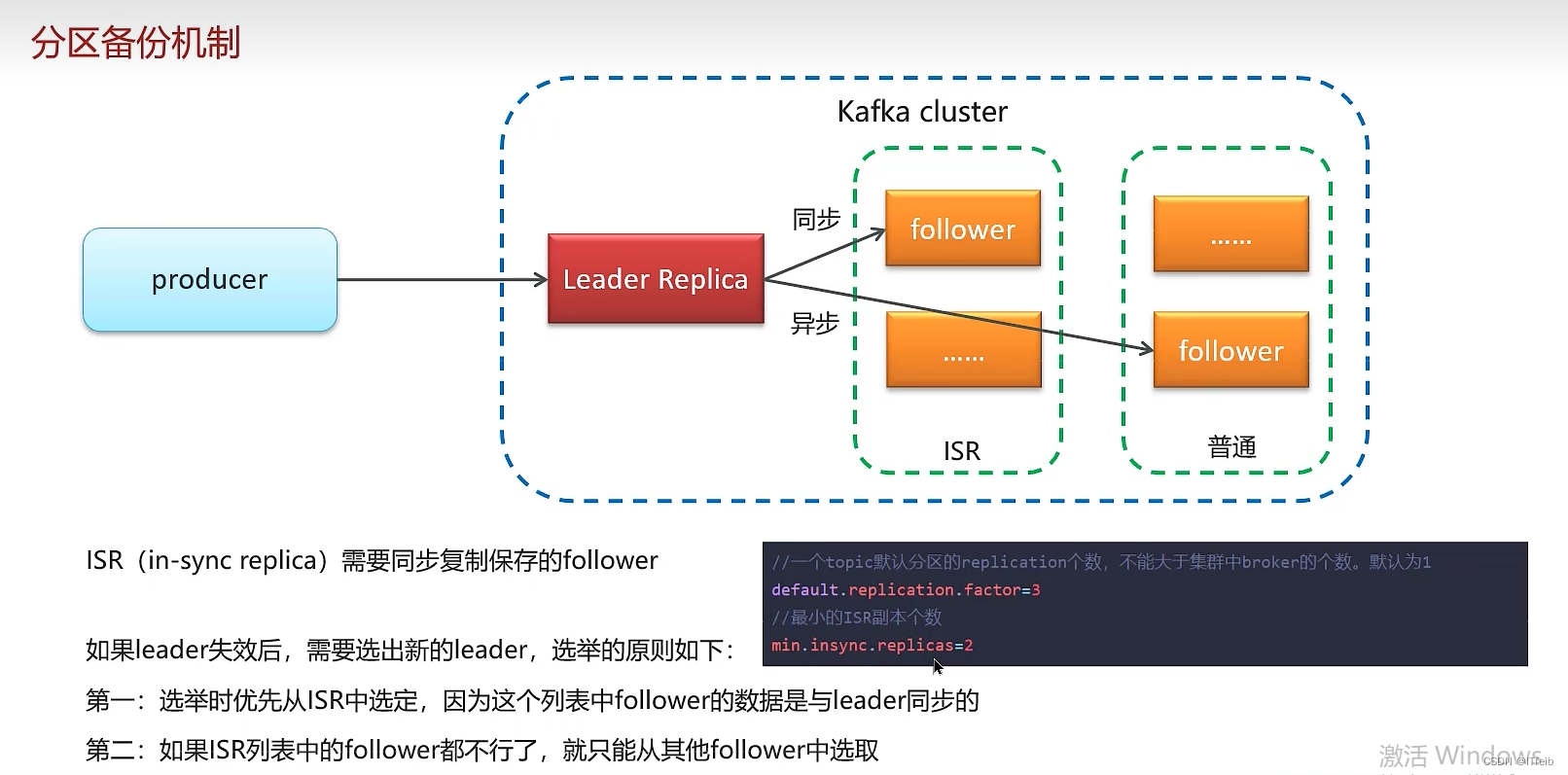
8. Kafka高可用机制
kafka的高可用其实是基于分区备份机制实现的,一个分区的消息会保存在不同的broker中,当这个分区的leader对应的broker宕机后,其他的broker中也会有这个分区的备份数据,分区的leader是负责读写数据的,那从这个分区的副本中可以选择一个作为分区的leader,也就实现的高可用。
9. kafka数据清理机制
kafka文件存储机制: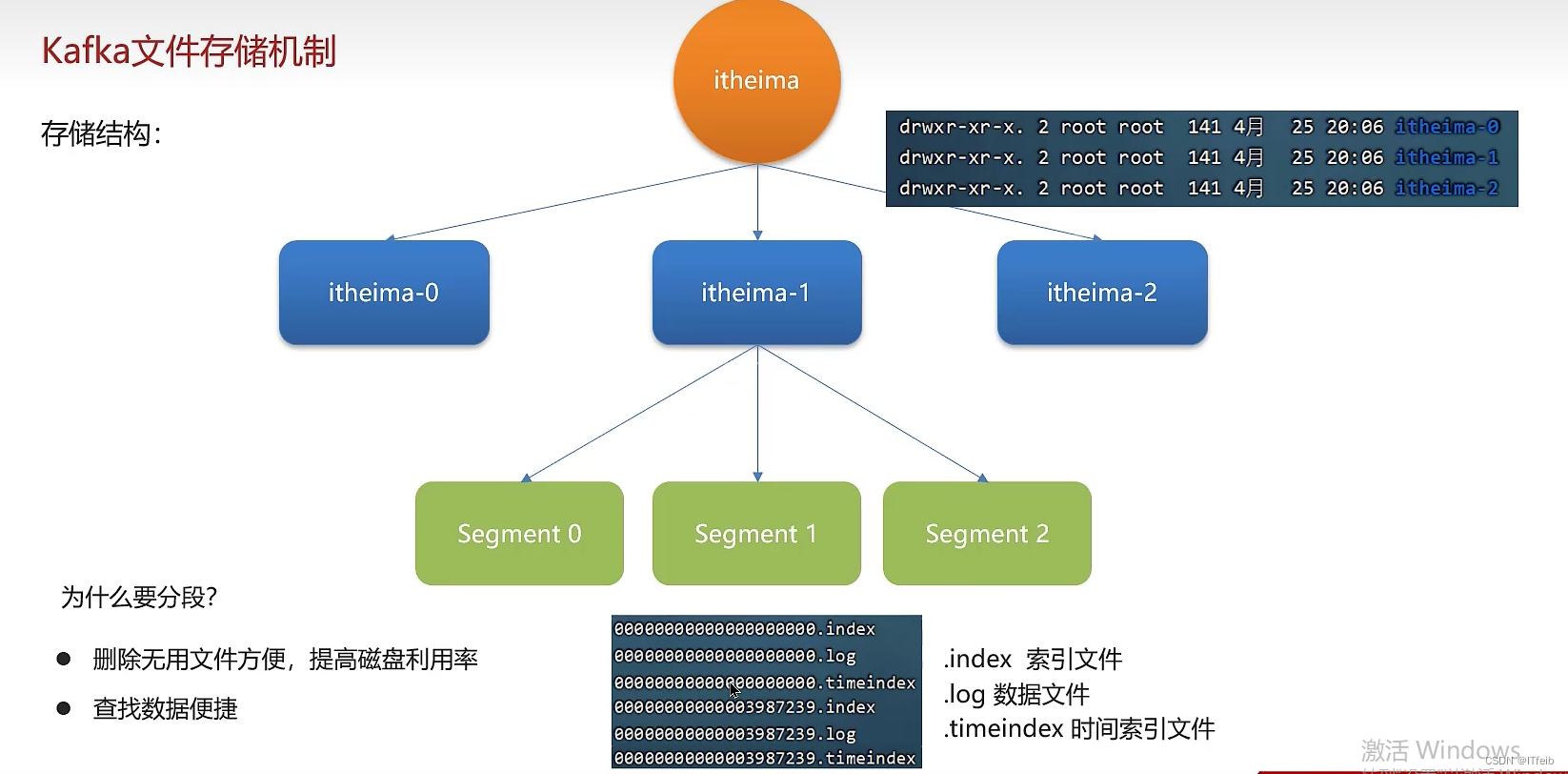


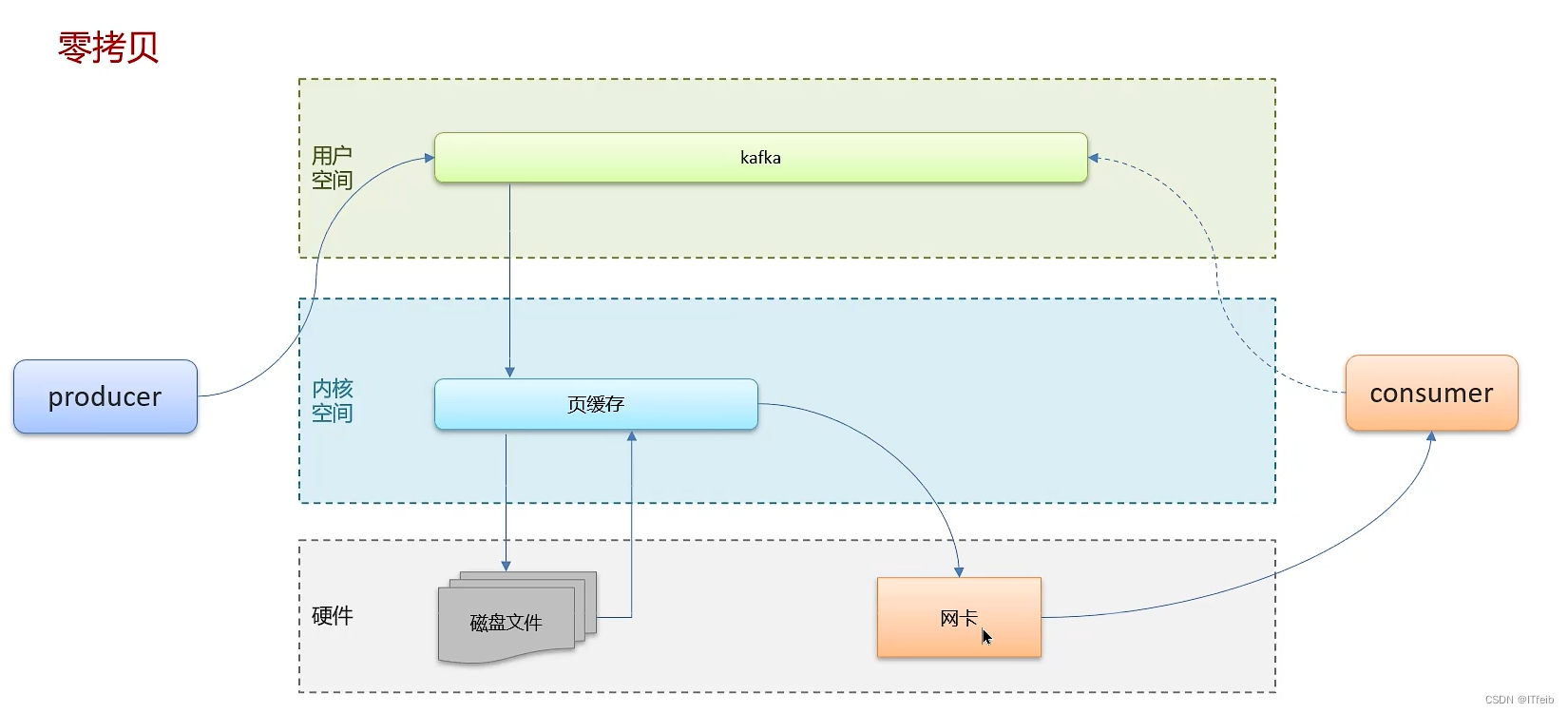
10. kafka中实现高性能的设计
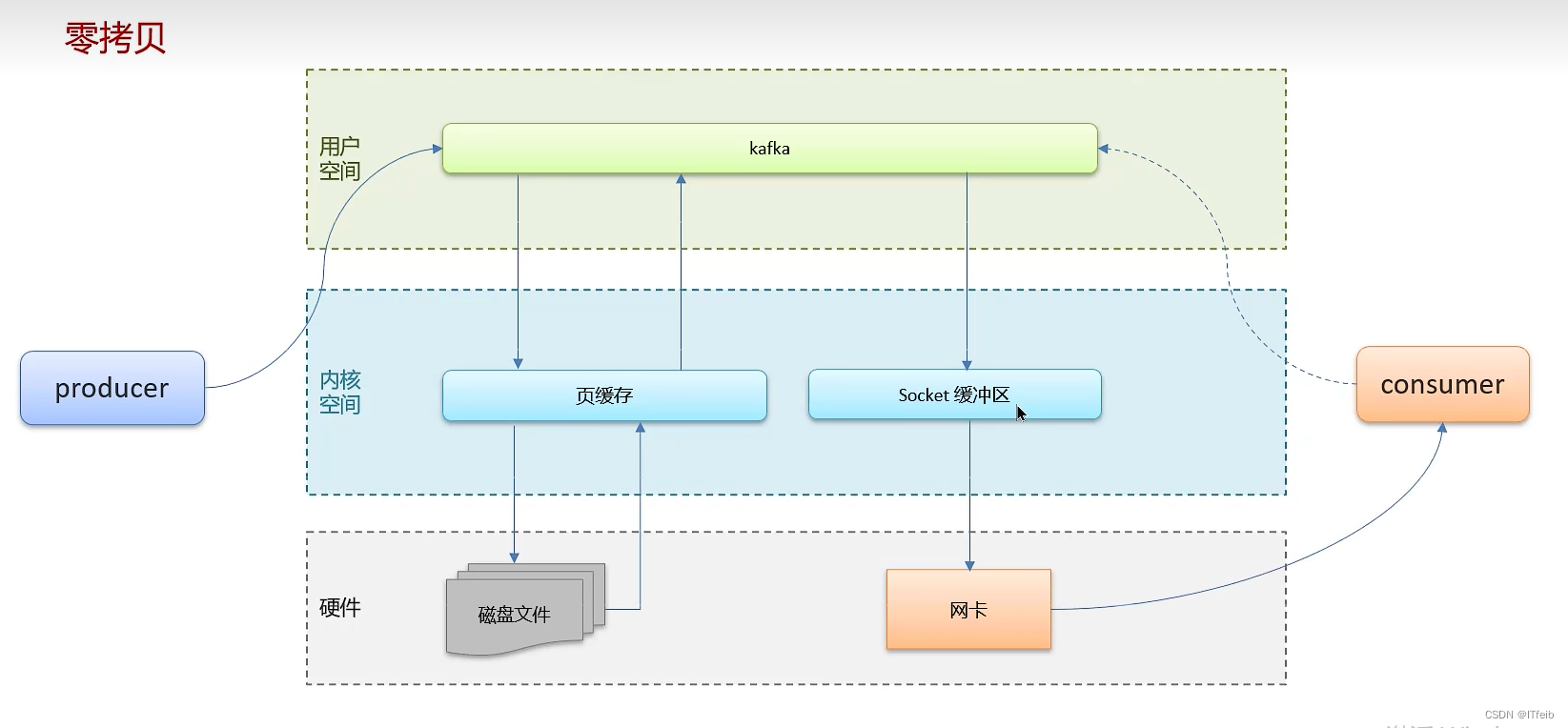
口述:高性能的设计无非是从两个维度来进行考虑,计算和IO,其实像kafka啊MQ啊,还是说其他的消息队列,都是一个 IO 密集型应用,从IO的角度来看,其实它涉及都两种IO磁盘IO与网络IO,对于网络IO,Kafka采用了批量消息的发送方式减少了网络的开销,包括像消息压缩啊,就减少了数据量,提高了网络的传输率,并且kafka也采用了IO多路复用技术,它采用的是典型的Reactor 网络通信模型, 1个 Acceptor 线程,负责监听新的连接,然后将新连接交给 Processor 线程处理,N 个 Processor 线程,每个 Processor 都有自己的 selector,负责从 socket 中读写数据, M 个 业务处理线程负责业务处理,它可以复用一个线程去处理大量的 Socket 连接,从而保证高性能。对于磁盘IO的话,kafka采用了顺序IO的方式,将消息追加到文件中,所以性能也比较高,并且kafka还使用了页缓存技术,磁盘顺序写加上页缓存更好地解决了日志文件的高性能读写问题,为了同时去读写这些文件,kafka使用了分区分段的设计,将一个topic数据分区存储,那就提高了并发度。
这些都是kafka高性能的体现,其实kafka中也有线程池的这种思想,它采用了内存池的复用机制,其实和线程池的本质是一样的都是为了提高复用,减少频繁的创建和释放,只不过kafka其实它复用的是内存,是batch为单位的内存,其实就是当这个batch中数据发送完了,那这块内存就要释放了,其实JVM在GC的过程是会STW的,kafka采用了内存的复用技术,当需要用的时候直接从内存池中去取,不用了就放回内存池等待复用,不会涉及到GC,这其实也是高性能的体现吧。




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!