高级RAG(四):RAGAs评估
之前我完成了父文档检索器和llamaIndex从小到大的检索这两篇博客,我在这两篇博客中分别介绍了使用langchain和llamaIndex进行文档检索的方法和步骤,其中包含了不同的RAG的检索策略,通常来说一个典型的RAG系统一般包含两个主要的部件:
- 检索器组件:根据用户问题从外部数据源(如pdf,word,text等)检索相关信息并提供给LLM 以便回答用户问题。
- 生成器组件:LLM根据检索到的相关信息,生成正确的、完整的对用户友好的答案。
那么当我们完成了一个RAG系统的开发工作以后,我们还需要对RAG系统的性能进行评估,那如何来对RAG系统的性能进行评估呢?我们可以仔细分析一下RAG系统的产出成果,比如检索器组件它产出的是检索出来的相关文档即context, 而生成器组件它产出的是最终的答案即answer,除此之外还有我们最初的用户问题即question。因此RAG系统的评估应该是将question、context、answer结合在一起进行评估,下面我们就来介绍一下RAGAs评估。
一、什么是RAGAs评估
RAGAs (Retrieval-Augmented?Generation?Assessment) 它是一个框架(github,官方文档),它可以帮助我们来快速评估RAG系统的性能,为了评估 RAG 系统,RAGAs 需要以下信息:
- question:用户输入的问题。
- answer:从 RAG 系统生成的答案(由LLM给出)。
- contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。
- ground_truths: 人类提供的基于问题的真实(正确)答案。 这是唯一的需要人类提供的信息。?
当RAGAs拿到上述这些信息后会基于大型语言模型(LLMs)来对RAG系统进行打分,就像在任何机器学习系统中一样,LLM 和 RAG 管道中各个组件的性能对整体体验具有重大影响。Ragas 提供了专门用于单独评估 RAG 管道的每个组件的指标

二、评估指标
Ragas提供了五种评估指标包括:
- 忠实度(faithfulness)
- 答案相关性(Answer relevancy)
- 上下文精度(Context precision)
- 上下文召回率(Context recall)
- 上下文相关性(Context relevancy)
2.1 忠实度(faithfulness)
忠实度(faithfulness)衡量了生成的答案(answer)与给定上下文(context)的事实一致性。它是根据answer和检索到的context计算得出的。并将计算结果缩放到 (0,1) 范围且越高越好。
如果答案(answer)中提出的所有基本事实(claims)都可以从给定的上下文(context)中推断出来,则生成的答案被认为是忠实的。为了计算这一点,首先从生成的答案中识别一组claims。然后,将这些claims中的每一项与给定的context进行交叉检查,以确定是否可以从给定的context中推断出它。忠实度分数由以下公式得出:

例子:

2.2 答案相关性(Answer relevancy)
评估指标“答案相关性”重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案将获得较低分数。该指标是通过计算question和answer获得的,它的取值范围在 0 到 1 之间,其中分数越高表示相关性越好。
当答案直接且适当地解决原始问题时,该答案被视为相关。重要的是,我们对答案相关性的评估不考虑真实情况,而是对答案缺乏完整性或包含冗余细节的情况进行惩罚。为了计算这个分数,LLM会被提示多次为生成的答案生成适当的问题,并测量这些生成的问题与原始问题之间的平均余弦相似度。基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从答案中生成与原始问题相符的问题。
例子:

2.3 上下文精度(Context precision)?
上下文精度是一种衡量标准,它评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。理想情况下,所有相关文档块(chunks)必须出现在顶层。该指标使用question和计算contexts,值范围在 0 到 1 之间,其中分数越高表示精度越高。

2.4 上下文召回率(Context recall)
上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出来的,取值范围在 0 到 1 之间,值越高表示性能越好。
为了根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。 在理想情况下,真实答案中的所有句子都应归因于检索到的Context。

例子:

2.5?上下文相关性(Context relevancy)
该指标衡量检索到的上下文(Context)的相关性,根据用户问题(question)和上下文(Context)计算得到,并且取值范围在 (0, 1)之间,值越高表示相关性越好。理想情况下,检索到的Context应只包含解答question的信息。 我们首先通过识别检索到的Context中与回答question相关的句子数量来估计 |S| 的值。 最终分数由以下公式确定:

说明:
这里的|S|是指Context中存在的与解答question相关的句子数量。
例子:

三、代码实操
接下来我们来评估一下我之前的博客:高级RAG(二):父文档检索器-CSDN博客中的案例,我们仍然使用langchain的父文档检索器来对百度百科上的一篇关于恐龙的文章:恐龙(一类主要生活在中生代的蜥形纲动物)_百度百科的内容进行检索和问答。

为了评估LLM的答案我设计了10个关于恐龙的问题,和10个真实答案(ground_truths):

 ?
?
?3.1 环境配置
我们首先需要安装如下python包:
pip install ragas
pip install langchain
pip install chromadb接下来我们需要导入存放Openai和谷歌的gemini模型的api_key,这里我们会使用openai的gpt-3.5-turbo和gemini-pro模型,并对它们的评估结果进行比对.
import os
import google.generativeai as genai
from dotenv import load_dotenv, find_dotenv
#导入.env配置文件
_ = load_dotenv(find_dotenv()) 3.2?Embeddings模型配置
这里我们还是使用BAAI的中文embedding模型,对此不熟悉的朋友可以看一下我之前写的这篇博客:高级RAG(一):Embedding模型的选择_embedding模型应该下载哪一个-CSDN博客
from langchain.embeddings import HuggingFaceBgeEmbeddings
#创建BAAI的embedding
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5",
cache_folder="D:\\models")?3.3 加载文档
下面我来加载百度百科的文档,这里我们使用的是langchain的爬虫工具WebBaseLoader:
from langchain.document_loaders import WebBaseLoader
urls = "https://baike.baidu.com/item/恐龙/139019"
loader = WebBaseLoader(urls)
docs = loader.load()
docs 
?3.4 创建父文档检索器
这里我们使用的是langchain的父文档检索器,对此不熟悉的朋友可以看一下我之前写的博客:高级RAG(二):父文档检索器-CSDN博客
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
#创建主文档分割器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
#创建子文档分割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 创建向量数据库对象
vectorstore = Chroma(
collection_name="split_parents", embedding_function = bge_embeddings
)
# 创建内存存储对象
store = InMemoryStore()
#创建父文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
# verbose=True,
search_kwargs={"k": 2}
)
#添加文档集
retriever.add_documents(docs)3.5 创建Chain
接下来我们来利用LangChain的表达式语言(LCEL)来创建一个用于实现文档问答的chain, 如何还不熟悉LCEL的朋友可以看一下我之前写的博客:LangChain的表达式语言(LCEL)
这里我们将会创建openai和gemini两种模型,大家可以在下面的代码中切换不同的模型:?
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langchain.schema.output_parser import StrOutputParser
from langchain.chat_models import ChatOpenAI
# from langchain_google_genai import ChatGoogleGenerativeAI
#创建gemini model
# model = ChatGoogleGenerativeAI(model="gemini-pro")
#创建openai model
model = ChatOpenAI()
#创建prompt模板
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use two sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
#由模板生成prompt
prompt = ChatPromptTemplate.from_template(template)
#创建chain
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | StrOutputParser()3.6 创建文档集
接下来我们需要让LLM来回答我之前设计的10个问题,并收集LLM给出的10个答案,最终生成一个问答集:
from datasets import Dataset
questions = ["恐龙是怎么被命名的?",
"恐龙怎么分类的?",
"体型最大的是哪种恐龙?",
"体型最长的是哪种恐龙?它在哪里被发现?",
"恐龙采样什么样的方式繁殖?",
"恐龙是冷血动物吗?",
"陨石撞击是导致恐龙灭绝的原因吗?",
"恐龙是在什么时候灭绝的?",
"鳄鱼是恐龙的近亲吗?",
"恐龙在英语中叫什么?"
]
ground_truths = [["1841年,英国科学家理查德·欧文在研究几块样子像蜥蜴骨头化石时,认为它们是某种史前动物留下来的,并命名为恐龙,意思是“恐怖的蜥蜴”。"],
["恐龙可分为鸟类和非鸟恐龙。"],
["恐龙整体而言的体型很大。以恐龙作为标准来看,蜥脚下目是其中的巨无霸。"],
["最长的恐龙是27米长的梁龙,是在1907年发现于美国怀俄明州。"],
["恐龙采样产卵、孵蛋的方式繁殖。"],
["恐龙是介于冷血和温血之间的动物"],
["科学家最新研究显示,0.65亿年前小行星碰撞地球时间或早或晚都可能不会导致恐龙灭绝,真实灭绝原因是当时恐龙处于较脆弱的生态系统中,环境剧变易导致灭绝。"],
["恐龙灭绝的时间是在距今约6500万年前,地质年代为中生代白垩纪末或新生代第三纪初。"],
["鳄鱼是另一群恐龙的现代近亲,但两者关系较非鸟恐龙与鸟类远。"],
["1842年,英国古生物学家理查德·欧文创建了“dinosaur”这一名词。英文的dinosaur来自希腊文deinos(恐怖的)Saurosc(蜥蜴或爬行动物)。对当时的欧文来说,这“恐怖的蜥蜴”或“恐怖的爬行动物”是指大的灭绝的爬行动物(实则不是)"]]
answers = []
contexts = []
# Inference
for query in questions:
answers.append(chain.invoke({"question": query}))
contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])
# To dict
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truths": ground_truths
}
# Convert dict to dataset
dataset = Dataset.from_dict(data)3.7 评估
最后我们来让RAGAs对我们的问答集进行评估,我们选择了:context_precision、context_recall、faithfulness、answer_relevancy这4个作为我们的评估指标,然后分别评估openai和gemini模型给出的答案,下面首先是对openai的gpt-3.5-turbo模型的评估:
#openai的结果
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
result = evaluate(
dataset = dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
df = result.to_pandas()
df ?
? ?
?
这里我们看到在评估结果中?上下文精度context_precision的结果都为0,而context_precision是用来评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。由于这里我们采样的是父文档检索器,因此原始的文档会被切割成父文档和子文档,在检索的时候是通过比较子文档与问题的相似度,然后返回相似度较高的子文档所在的父文档,因此子文档在父文档中的位置不一定是在顶部,也很有可能是在父文档的中部或者底部,因此这就会导致较低的context_precision得分。除此之外其他的3个指标都获得了较高的分数。
接下来我们来看看Gemini的模型的评估结果,这里我们省去了代码中的模型切换步骤,直接给出评估结果:
#gemini的结果
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
result = evaluate(
dataset = dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy,
],
)
df = result.to_pandas()
df ?
?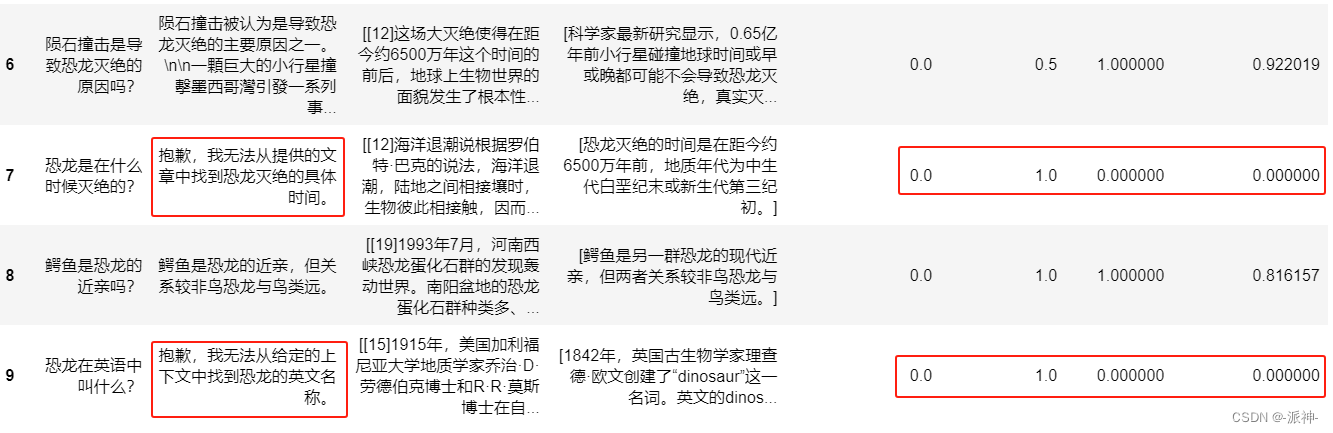 ?
?
这里我们看到gemini模型有4题无法从给定的上下文(context)中总结出答案,显然gemini模型的总结和推理的能力明显要弱与Openai的模型。
四、总结
今天我们学习了RAGAs的评估指标其中包含了忠实度(faithfulness)、答案相关性(Answer relevancy)、上下文精度(Context precision)、上下文召回率(Context recall)、上下文相关性(Context relevancy)。并且我们通过一个真实的案例来介绍ragas指标的使用方法,最后我们对比了openai和gemini两种模型的评估结果,我们发现openai模型的推理和总结的能力明显要强于gemini模型。
五、参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!