(7-3-4)金融风险管理实战:制作信贷风控模型
请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
7.3.9 ?创建大模型(Baseline)
基线模型是用于评估机器学习模型性能的一个起点模型,在本项目中,使用逻辑回归(Logistic Regression)作为基线模型。
(1)逻辑回归是一种用于分类任务的常见机器学习算法,首先编写如下代码实现数据的预处理,包括填充缺失值和特征缩放。
# 导入MinMaxScaler和Imputer
from sklearn.preprocessing import MinMaxScaler, Imputer
# 从训练数据中删除目标变量(如果存在)
if 'TARGET' in app_train:
train = app_train.drop(columns=['TARGET'])
else:
train = app_train.copy()
# 提取特征名称列表
features = list(train.columns)
# 复制测试数据
test = app_test.copy()
# 使用中值填充缺失值
imputer = Imputer(strategy='median')
# 将每个特征缩放到0-1的范围
scaler = MinMaxScaler(feature_range=(0, 1))
# 对训练数据进行中值填充和特征缩放
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(app_test)
# 对训练和测试数据进行特征缩放
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
# 打印处理后的训练和测试数据的形状
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)上述代码的功能是执行以下数据预处理步骤:
- 如果训练数据中存在目标变量'TARGET',则从训练数据中删除该变量,以便将其作为特征数据。
- 提取特征名称列表。
- 创建测试数据的副本。
- 使用中值填充训练和测试数据中的缺失值。
- 将每个特征缩放到0-1的范围,以确保不同特征具有相同的尺度。
- 打印处理后的训练和测试数据的形状,以确认预处理步骤已完成。
上述预处理步骤可确保数据准备好用于机器学习模型的训练和测试,执行后会输出:
Training data shape: ?(307511, 240)
Testing data shape: ?(48744, 240)(2)使用Scikit-Learn中的LogisticRegression建立第一个机器学习模型,唯一的变化是降低了正则化参数C的值,该参数控制过拟合的程度(较低的值应该减少过拟合)。这将使我们比默认的LogisticRegression模型稍微好一些,但仍然为任何未来的模型设定了一个低的标准。具体实现代码如下所示。
# 导入Scikit-Learn中的LogisticRegression
from sklearn.linear_model import LogisticRegression
# 创建具有指定正则化参数的模型
log_reg = LogisticRegression(C=0.0001)
# 在训练数据上训练模型
log_reg.fit(train, train_labels)对上述代码的具体说明如下:
- 创建一个LogisticRegression模型,并设置正则化参数C的值为0.0001。
- 使用训练数据(train)和对应的训练标签(train_labels)来训练模型。
- 模型训练完成后,可以用于进行预测。
这里使用的是二分类逻辑回归模型,训练后的模型可以用于预测目标变量的概率值。执行后会输出:
LogisticRegression(C=0.0001, class_weight=None, dual=False,
??????????fit_intercept=True, intercept_scaling=1, max_iter=100,
??????????multi_class='ovr', n_jobs=None, penalty='l2', random_state=None,
??????????solver='liblinear', tol=0.0001, verbose=0, warm_start=False)(3)现在模型已经训练好了,接下来可以使用它进行预测。我们希望预测贷款不偿还的概率,因此我们使用模型的predict_proba方法。这个方法返回一个m x 2的数组,其中m是观测值的数量。第一列是目标变量为0的概率,第二列是目标变量为1的概率(所以对于单个行,这两列的值必须加起来等于1)。我们想要的是贷款不偿还的概率,因此会选择第二列。具体实现代码如下所示。
# 进行预测,确保只选择第二列
log_reg_pred = log_reg.predict_proba(test)[:, 1](4)预测结果必须符合示例提交文件(sample_submission.csv)中显示的格式,其中只包含两列:SK_ID_CURR和TARGET。我们将从测试集和预测中创建一个符合这种格式的数据框,命名为submit,具体实现代码如下所示。
# 创建提交数据框
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
# 显示前几行数据
submit.head()上述代码的功能是从测试数据中提取SK_ID_CURR列,然后将模型的预测结果(log_reg_pred)添加为TARGET列,以生成符合竞赛要求的提交数据框。然后,通过submit.head()显示数据框的前几行,以进行初步检查。执行后会输出:
????????SK_ID_CURR TARGET
0 100001 0.087750
1 100005 0.163957
2 100013 0.110238
3 100028 0.076575
4 100038 0.154924(5)将模型的预测结果保存到CSV文件中,预测结果代表了贷款不偿还的概率,处于0到1之间。如果我们要将这些预测用于分类申请人,可以设置一个概率阈值来确定贷款是否风险。具体实现代码如下所示。
submit.to_csv('log_reg_baseline.csv', index = False)在上述代码中,将submit数据框保存为名为'log_reg_baseline.csv'的CSV文件,同时确保不包含行索引。这个CSV文件可以用于提交竞赛结果。
7.3.10 ?优化模型
(1)要想改善前面创建的基线模型的性能,可以尝试使用更强大的模型。在这里,将尝试在相同的训练数据上使用随机森林(Random Forest)来看看它对性能的影响。随机森林是一种非常强大的模型,特别是当我们使用数百棵树时。我们将使用100棵树来构建随机森林模型,具体实现代码如下所示。
# 导入RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
random_forest = RandomForestClassifier(n_estimators=100, random_state=50, verbose=1, n_jobs=-1)
# 在训练数据上训练模型
random_forest.fit(train, train_labels)
# 提取特征重要性
feature_importance_values = random_forest.feature_importances_
feature_importances = pd.DataFrame({'feature': features, 'importance': feature_importance_values})
# 对测试数据进行预测
predictions = random_forest.predict_proba(test)[:, 1]上述代码的功能是:
- 导入Scikit-Learn中的RandomForestClassifier模型。
- 创建一个随机森林分类器,设置树的数量为100,随机种子为50,启用详细日志输出,并使用所有可用的CPU核心进行训练。
- 使用训练数据(train)和对应的训练标签(train_labels)来训练随机森林模型。
- 提取模型的特征重要性,这些重要性值反映了每个特征对模型的预测的贡献程度。
- 使用随机森林模型对测试数据进行预测,并提取贷款不偿还的概率。
随机森林是一种强大的集成模型,通常在各种机器学习问题中表现良好。执行后会输出:
[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done ?42 tasks ?????| elapsed: ??32.7s
[Parallel(n_jobs=-1)]: Done 100 out of 100 | elapsed: ?1.2min finished
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done ?42 tasks ?????| elapsed: ???0.6s
[Parallel(n_jobs=4)]: Done 100 out of 100 | elapsed: ???1.4s finished(2)创建一个提交数据框提交模型,具体实现代码如下所示。
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
#保存提交数据框
submit.to_csv('random_forest_baseline.csv', index=False)执行3后会输出下面的结果,这说明当提交此模型时,预计得分约为0.678。这是一个相对于基线模型有所改进的分数。随机森林通常在多种问题中都表现良好,因为它能够捕捉复杂的数据关系和特征重要性。
This model should score around 0.678 when submitted.(3)要查看多项式特征和领域知识是否改善了模型,唯一的方法是使用这些特征来训练和测试一个模型!然后,可以将提交性能与没有这些特征的模型性能进行比较,以评估我们特征工程的效果。具体实现代码如下所示。
# 获取多项式特征的列名
poly_features_names = list(app_train_poly.columns)
# 填充多项式特征的缺失值
imputer = Imputer(strategy='median')
poly_features = imputer.fit_transform(app_train_poly)
poly_features_test = imputer.transform(app_test_poly)
# 缩放多项式特征
scaler = MinMaxScaler(feature_range=(0, 1))
poly_features = scaler.fit_transform(poly_features)
poly_features_test = scaler.transform(poly_features_test)
# 创建随机森林分类器
random_forest_poly = RandomForestClassifier(n_estimators=100, random_state=50, verbose=1, n_jobs=-1)
# 在训练数据上训练模型
random_forest_poly.fit(poly_features, train_labels)
# 对测试数据进行预测
predictions = random_forest_poly.predict_proba(poly_features_test)[:, 1]对上述代码的具体说明如下:
- 获取多项式特征的列名。
- 使用中值策略填充多项式特征的缺失值。
- 缩放多项式特征,将其缩放到0到1的范围内。
- 创建一个随机森林分类器,设置树的数量为100,随机种子为50,启用详细日志输出,并使用所有可用的CPU核心进行训练。
- 使用多项式特征在训练数据上训练随机森林模型。
- 使用训练好的模型对测试数据进行预测,并提取贷款不偿还的概率。
这将帮助我们评估多项式特征和领域知识特征对模型性能的影响,执行后会输出:
[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done ?42 tasks ?????| elapsed: ??45.9s
[Parallel(n_jobs=-1)]: Done 100 out of 100 | elapsed: ?1.7min finished
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done ?42 tasks ?????| elapsed: ???0.4s
[Parallel(n_jobs=4)]: Done 100 out of 100 | elapsed: ???0.9s finished(4)提交优化后的模型,具体实现代码如下所示。
#创建一个提交数据框
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
#保存提交数据框
submit.to_csv('random_forest_baseline_engineered.csv', index=False)当将此模型提交到竞赛时,得分为0.678,与没有工程特征的模型得分完全相同。
(5)根据前面的结果,说明我们的特征构建在这种情况下没有帮助。这意味着多项式特征和领域知识特征对模型性能的影响很小。在某些情况下,特征工程可能不会改善模型的性能,这取决于数据和问题的特点。接下来,我们可以测试手工创建的领域特征,具体实现代码如下所示。
# 删除目标列
app_train_domain = app_train_domain.drop(columns='TARGET')
# 获取领域特征的列名
domain_features_names = list(app_train_domain.columns)
# 填充领域特征的缺失值
imputer = Imputer(strategy='median')
domain_features = imputer.fit_transform(app_train_domain)
domain_features_test = imputer.transform(app_test_domain)
# 缩放领域特征
scaler = MinMaxScaler(feature_range=(0, 1))
domain_features = scaler.fit_transform(domain_features)
domain_features_test = scaler.transform(domain_features_test)
# 创建随机森林分类器
random_forest_domain = RandomForestClassifier(n_estimators=100, random_state=50, verbose=1, n_jobs=-1)
# 在训练数据上训练模型
random_forest_domain.fit(domain_features, train_labels)
# 提取特征重要性
feature_importance_values_domain = random_forest_domain.feature_importances_
feature_importances_domain = pd.DataFrame({'feature': domain_features_names, 'importance': feature_importance_values_domain})
# 对测试数据进行预测
predictions = random_forest_domain.predict_proba(domain_features_test)[:, 1]对上述代码的具体说明如下:
- 删除训练数据中的目标列。
- 获取领域特征的列名。
- 使用中值策略填充领域特征的缺失值。
- 缩放领域特征,将其缩放到0到1的范围内。
- 创建一个随机森林分类器,设置树的数量为100,随机种子为50,启用详细日志输出,并使用所有可用的CPU核心进行训练。
- 使用领域特征在训练数据上训练随机森林模型。
- 提取模型的特征重要性,这些重要性值反映了每个特征对模型的预测的贡献程度。
- 使用训练好的模型对测试数据进行预测,并提取贷款不偿还的概率。
上述代码将帮助我们评估手工创建的领域特征对模型性能的影响,执行后会输出:
[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done ?42 tasks ?????| elapsed: ??34.0s
[Parallel(n_jobs=-1)]: Done 100 out of 100 | elapsed: ?1.3min finished
[Parallel(n_jobs=4)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done ?42 tasks ?????| elapsed: ???0.6s
[Parallel(n_jobs=4)]: Done 100 out of 100 | elapsed: ???1.4s finished(6)再次提交模型,具体实现代码如下所示。
#创建一个提交数据框
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
#保存提交数据框
submit.to_csv('random_forest_baseline_domain.csv', index=False)此时提交模型后的得分会有进步。
(7)定义函数plot_feature_importances(),该函数的功能是绘制特征重要性的水平条形图,并将特征按重要性排序。该函数接受一个包含特征名和对应重要性的数据框作为参数,并返回按重要性排序的特征重要性数据框。具体实现代码如下所示。
def plot_feature_importances(df):
# 按照重要性对特征进行排序
df = df.sort_values('importance', ascending=False).reset_index()
# 归一化特征重要性,使其总和为1
df['importance_normalized'] = df['importance'] / df['importance'].sum()
# 绘制特征重要性的水平条形图
plt.figure(figsize=(10, 6))
ax = plt.subplot()
# 需要颠倒索引以绘制最重要的特征在顶部
ax.barh(list(reversed(list(df.index[:15]))),
df['importance_normalized'].head(15),
align='center', edgecolor='k')
# 设置yticks和标签
# 绘图标签
plt.xlabel('Normalized Importance');
plt.title('Feature Importances')
plt.show()
return df(8)接下来,使用函数plot_feature_importances()显示随机森林模型中特征的重要性具体实现代码如下所示。
# 显示默认特征的特征重要性
feature_importances_sorted = plot_feature_importances(feature_importances)执行效果如图7-14所示。特征重要性用于衡量每个特征对模型预测的贡献程度,越重要的特征在图表中显示得越高。这个图显示了基于原始特征的特征重要性,显示了模型认为哪些原始特征对于预测的重要性较高,可以帮助我们了解哪些特征对模型的预测最重要。

图7-14 ?原始特征的重要性图
正如预期的那样,最重要的特征是与EXT_SOURCE和DAYS_BIRTH有关的特征。我们可以看到只有少数几个特征对模型具有显著的重要性,这表明可能可以在不降低性能的情况下删除许多特征(甚至可能会提高性能)。特征重要性并不是解释模型或进行降维的最复杂方法,但它们让我们开始了解模型在进行预测时考虑了哪些因素。
(9)接下来,使用相同的方法来显示手工制作的领域特征的特征重要性。具体实现代码如下所示。
feature_importances_domain_sorted = plot_feature_importances(feature_importances_domain)执行效果如图7-15所示,这个图显示了基于手工制作的领域特征的特征重要性。这些领域特征是根据领域知识创建的,用于尝试提高模型性能。这些领域特征是我们根据贷款数据的领域知识创建的。同样,特征重要性图表可以帮助我们了解这些手工制作的特征对模型的预测的重要性。
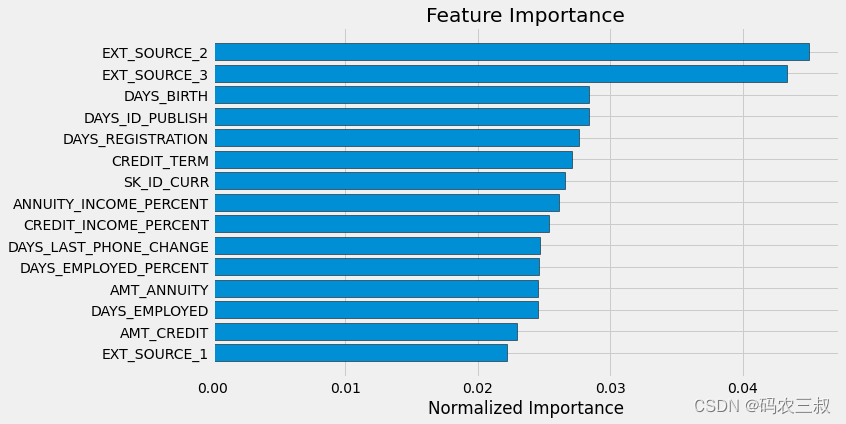
图7-15 ?领域特征重要性图
可以看到,我们手工制作的四个特征都进入了前15个最重要的特征之列,这说明领域特征部分的代码很成功。
7.3.11 ?制作LightGBM模型
轻量级梯度提升机(LightGBM)是一个基于梯度提升机(Gradient Boosting Machine)算法的高性能、分布式、开源机器学习框架。它是Microsoft开发的,并在机器学习社区中广泛使用。LightGBM在处理大规模数据集时表现出色,速度快,具有高效的内存使用,通常被认为是一种强大的集成学习方法。LightGBM的主要特点和优势包括:
- 高效性: LightGBM 使用了直方图算法和按叶子结点分裂的方式,这些技术使得它在处理大规模数据时非常高效。它能够处理百万级别的样本和特征。
- 低内存占用: LightGBM 使用了按列存储数据,以及压缩技术,可以显著减小内存占用,使得它可以运行在内存受限的环境中。
- 高准确性: LightGBM 在性能和准确性之间取得了很好的平衡,通常能够获得竞赛中的高排名。
- 支持分类和回归问题: LightGBM 可以用于分类问题和回归问题,并支持多类别分类。
- 并行和分布式计算: LightGBM 支持并行计算和分布式训练,可以充分利用多核CPU和分布式计算资源。
总之,轻量级梯度提升机是一个强大的机器学习工具,适用于各种类型的数据科学和机器学习任务。在Kaggle等竞赛中,它经常被用作获得高分数的关键模型之一。
(1)编写函数model(),功能是使用LightGBM(轻量级梯度提升机)实现模型的训练、测试以及基本的交叉验证功能,函数model()的参数说明如下:
- features:训练数据的特征集,必须包括TARGET列。
- test_features:测试数据的特征集。
- encoding:用于编码分类变量的方法,可以选择'one-hot encoding'('ohe')或'integer label encoding'('le')。
- n_folds:交叉验证的折数,默认为5。
函数model()的具体实现代码如下所示。
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
import lightgbm as lgb
import gc
def model(features, test_features, encoding='ohe', n_folds=5):
# 提取标识号
train_ids = features['SK_ID_CURR']
test_ids = test_features['SK_ID_CURR']
# 提取训练标签
labels = features['TARGET']
# 移除标识号和目标列
features = features.drop(columns=['SK_ID_CURR', 'TARGET'])
test_features = test_features.drop(columns=['SK_ID_CURR'])
# 独热编码
if encoding == 'ohe':
features = pd.get_dummies(features)
test_features = pd.get_dummies(test_features)
# 按列对齐数据框
features, test_features = features.align(test_features, join='inner', axis=1)
# 没有分类索引需要记录
cat_indices = 'auto'
# 整数标签编码
elif encoding == 'le':
# 创建标签编码器
label_encoder = LabelEncoder()
# 用于存储分类变量索引的列表
cat_indices = []
# 遍历每一列
for i, col in enumerate(features):
if features[col].dtype == 'object':
# 将分类特征映射为整数
features[col] = label_encoder.fit_transform(np.array(features[col].astype(str)).reshape((-1,)))
test_features[col] = label_encoder.transform(np.array(test_features[col].astype(str)).reshape((-1,)))
# 记录分类变量的索引
cat_indices.append(i)
# 捕获编码方案无效的错误
else:
raise ValueError("Encoding must be either 'ohe' or 'le'")
print('Training Data Shape: ', features.shape)
print('Testing Data Shape: ', test_features.shape)
# 提取特征名称
feature_names = list(features.columns)
# 转换为 np 数组
features = np.array(features)
test_features = np.array(test_features)
# 创建 KFold 对象
k_fold = KFold(n_splits=n_folds, shuffle=True, random_state=50)
# 特征重要性数组
feature_importance_values = np.zeros(len(feature_names))
# 测试数据预测结果数组
test_predictions = np.zeros(test_features.shape[0])
# 交叉验证外部验证预测结果数组
out_of_fold = np.zeros(features.shape[0])
# 记录验证和训练分数的列表
valid_scores = []
train_scores = []
# 遍历每个折叠
for train_indices, valid_indices in k_fold.split(features):
# 当前折叠的训练数据
train_features, train_labels = features[train_indices], labels[train_indices]
# 当前折叠的验证数据
valid_features, valid_labels = features[valid_indices], labels[valid_indices]
# 创建模型
model = lgb.LGBMClassifier(n_estimators=10000, objective='binary',
class_weight='balanced', learning_rate=0.05,
reg_alpha=0.1, reg_lambda=0.1,
subsample=0.8, n_jobs=-1, random_state=50)
# 训练模型
model.fit(train_features, train_labels, eval_metric='auc',
eval_set=[(valid_features, valid_labels), (train_features, train_labels)],
eval_names=['valid', 'train'], categorical_feature=cat_indices,
early_stopping_rounds=100, verbose=200)
# 记录最佳迭代次数
best_iteration = model.best_iteration_
# 记录特征重要性
feature_importance_values += model.feature_importances_ / k_fold.n_splits
# 进行预测
test_predictions += model.predict_proba(test_features, num_iteration=best_iteration)[:, 1] / k_fold.n_splits
# 记录外部验证预测结果
out_of_fold[valid_indices] = model.predict_proba(valid_features, num_iteration=best_iteration)[:, 1]
# 记录最佳分数
valid_score = model.best_score_['valid']['auc']
train_score = model.best_score_['train']['auc']
valid_scores.append(valid_score)
train_scores.append(train_score)
# 清理内存
gc.enable()
del model, train_features, valid_features
gc.collect()
# 创建提交数据数据框
submission = pd.DataFrame({'SK_ID_CURR': test_ids, 'TARGET': test_predictions})
# 创建特征重要性数据框
feature_importances = pd.DataFrame({'feature': feature_names, 'importance': feature_importance_values})
# 计算总体验证分数
valid_auc = roc_auc_score(labels, out_of_fold)
# 添加总体分数到指标数据框
valid_scores.append(valid_auc)
train_scores.append(np.mean(train_scores))
# 用于创建验证分数的数据框所需的内容
fold_names = list(range(n_folds))
fold_names.append('overall')
# 指标数据框
metrics = pd.DataFrame({'fold': fold_names,
'train': train_scores,
'valid': valid_scores})
return submission, feature_importances, metrics
# 使用函数进行模型训练和测试
submission, fi, metrics = model(app_train, app_test)
print('Baseline metrics')
print(metrics)总之,这上述代码是一个使用LightGBM模型进行二元分类的示例,并使用交叉验证来评估模型性能的基本框架。在训练过程中,还记录了特征的重要性,以便后续分析和特征选择。函数model()的具体实现流程如下:
- 从特征集中提取SK_ID_CURR和TARGET列,然后移除这两列。
- 根据指定的编码方法对分类变量进行编码。
- 创建LightGBM模型,并使用交叉验证进行训练。训练过程中记录了每个折叠的验证和训练指标(ROC AUC)以及特征的重要性。
- 使用训练好的模型对测试数据进行预测,并计算出每个折叠的测试数据预测结果。
- 汇总所有折叠的测试结果,得到最终的提交数据。
- 返回提交数据、特征重要性和交叉验证指标。
- 此外,还打印输出了交叉验证的指标,包括每个折叠的训练和验证ROC AUC,以及总体的ROC AUC。
此时执行后会输出:
Training Data Shape: ?(307511, 239)
Testing Data Shape: ?(48744, 239)
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.754949 train's auc: 0.79887
Early stopping, best iteration is:
[208] valid's auc: 0.755109 train's auc: 0.80025
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.758539 train's auc: 0.798518
Early stopping, best iteration is:
[217] valid's auc: 0.758619 train's auc: 0.801374
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.762652 train's auc: 0.79774
[400] valid's auc: 0.762202 train's auc: 0.827288
Early stopping, best iteration is:
[320] valid's auc: 0.763103 train's auc: 0.81638
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.757496 train's auc: 0.799107
Early stopping, best iteration is:
[183] valid's auc: 0.75759 train's auc: 0.796125
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.758099 train's auc: 0.798268
Early stopping, best iteration is:
[227] valid's auc: 0.758251 train's auc: 0.802746
Baseline metrics
??????fold ????train ????valid
0 ???????0 ?0.800250 ?0.755109
1 ???????1 ?0.801374 ?0.758619
2 ???????2 ?0.816380 ?0.763103
3 ???????3 ?0.796125 ?0.757590
4 ???????4 ?0.802746 ?0.758251
5 ?overall ?0.803375 ?0.758537(2)绘制特征重要性的可视化图,具体实现代码如下所示。
fi_sorted = plot_feature_importances(fi)执行效果如图7-16所示。

图7-16 ?特征重要性的可视化图
(3)保存提交结果到文件baseline_lgb.csv中,具体实现代码如下所示。
submission.to_csv('baseline_lgb.csv', index=False)(4)测试这个包含领域知识特征的模型,并评估其性能。具体实现代码如下所示。
submission_domain, fi_domain, metrics_domain = model(app_train_domain, app_test_domain)
print('Baseline with domain knowledge features metrics')
print(metrics_domain)对上述代码的具体说明如下:
- model(app_train_domain, app_test_domain):调用名为model的函数,将训练数据集app_train_domain和测试数据集app_test_domain作为参数传递给函数。这个函数用于训练一个机器学习模型并进行交叉验证。
- submission_domain, fi_domain, metrics_domain:将函数model的返回值解包,将结果分别赋值给三个变量:submission_domain、fi_domain和metrics_domain。其中,submission_domain包含了模型的预测结果,fi_domain包含了特征重要性信息,metrics_domain包含了模型的性能指标。
- print('Baseline with domain knowledge features metrics'):打印出一条描述性的文本信息,提示接下来要展示包含领域知识特征的基准模型的性能指标。
- print(metrics_domain):打印出包含领域知识特征的基准模型的性能指标,这些指标通常包括训练集和验证集的 ROC AUC 分数。
总之,这段代码的主要作用是训练一个包含领域知识特征的机器学习模型,并输出该模型在不同指标下的性能表现,这有助于评估领域知识特征对模型性能的影响。执行后会输出:
Training Data Shape: (307511, 243)
Testing Data Shape: (48744, 243)
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.762577 train's auc: 0.804531
Early stopping, best iteration is:
[237] valid's auc: 0.762858 train's auc: 0.810671
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.765594 train's auc: 0.804304
Early stopping, best iteration is:
[227] valid's auc: 0.765861 train's auc: 0.808665
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.770139 train's auc: 0.803753
[400] valid's auc: 0.770328 train's auc: 0.834338
Early stopping, best iteration is:
[302] valid's auc: 0.770629 train's auc: 0.820401
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.765653 train's auc: 0.804487
Early stopping, best iteration is:
[262] valid's auc: 0.766318 train's auc: 0.815066
Training until validation scores don't improve for 100 rounds.
[200] valid's auc: 0.764456 train's auc: 0.804527
Early stopping, best iteration is:
[235] valid's auc: 0.764517 train's auc: 0.810422
Baseline with domain knowledge features metrics
fold train valid
0 0 0.810671 0.762858
1 1 0.808665 0.765861
2 2 0.820401 0.770629
3 3 0.815066 0.766318
4 4 0.810422 0.764517
5 overall 0.813045 0.766050(5)使用函数plot_feature_importances来可视化领域知识特征在模型中的重要性,并将结果存储在变量fi_sorted中。具体实现代码如下所示。
fi_sorted = plot_feature_importances(fi_domain)总之,上述代码的作用是生成并存储一个按特征重要性排序的可视化图,如图7-17所示。会再次看到一些我们构建的特征出现在最重要的特征列表中,这样可以进一步分析和理解哪些领域知识特征对模型的性能有重要影响。
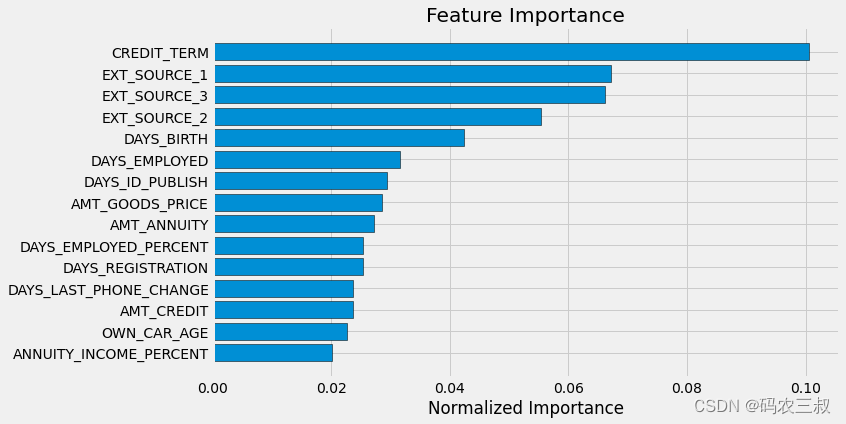
图7-17 ?按特征重要性排序的可视化图
本项目已完结:
(7-3-1)金融风险管理实战:制作信贷风控模型-CSDN博客
(7-3-2)金融风险管理实战:制作信贷风控模型-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!