【星海出品】Keepalived 基础及概念 (一)
今天遇到一个用户,必须使用keepalived去实现高可用。为了让客户满意,所以就从各方面进行一个全方面的解析研究。
开源 keepalived
前世今生
VRRP,全称 Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议,VRRP的出现是为了解决静态路由的单点故障。
Keepalived 是一款由C编写的软件,一般解决负载均衡器的高可用性问题,提供了负载均衡、健康检查和高可用的功能,高可用功能是由VRRP协议来实现的。
管理 LVS 负载均衡软件
实现 LVS 集群节点的健康检查
作为系统网络服务的高可用性(failover)
Keepalived 软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态。
后来又加入了可以实现高可用的VRRP功能。
功能特性中 LVS 的功能相对单一,主要实现简单的负载均衡策略。而 HAProxy 功能更为强大,支持端口、URL、脚本等多种状态检测方式,可以实现更复杂的负载均衡策略。
因此,Keepalived 除了能够管理 LVS 软件外,还可以作为其他服务(例如:Nginx、Haproxy、MySQL等)的高可用解决方案软件。
现在大部分场景Keepalived 软件主要是通过 VRRP 协议实现高可用功能的。VRRP 是 Virtual Router RedundancyProtocol (虚拟路由器冗余协议)的缩写, VRRP 出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
简单原理
Keepalived高可用对之间是通过VRRP通信的,因此,我们从 VRRP开始了解起:
VRRP,全称 Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议,VRRP 的出现是为了解决静态路由的单点故障。
VRRP 是通过一种竟选协议机制来将路由任务交给某台 VRRP路由器的。
VRRP 用 IP 多播的方式(默认多播地址(224.0_0.18))实现高可用对之间通信。
工作时主节点发包,备节点接包,当备节点接收不到主节点发的数据包的时候,就启动接管程序接管主节点的开源。备节点可以有多个,通过优先级竞选,但一般 Keepalived系统运维工作中都是一对。
VRRP 使用了加密协议加密数据,但Keepalived官方目前还是推荐用明文的方式配置认证类型和密码。
keepalived layer3
网络层 keepalived 使用 layer3 的方式工作时:keepalived会定期向服务器群中的服务器发送一个icmp的数据包。
如果发现某台服务器的ip地址没有激活,keepalived 便报告这台服务器失效,并将它从服务器群众剔除。
在 第3层 ,Keepalived会定期向热备组中的服务器发送一个ICMP数据包来判断某台服务器是否故障,如果故障则将这台服务器从热备组移除。将IP协议解析为MAC地址,从而进行数据交互。
在 第4层 ,Keepalived以TCP端口的状态判断服务器是否故障,比如检测RabbitMQ的5672端口,如果故障则将这台服务器从热备组中移除。
在 第7层 ,Keepalived根据用户设定的策略(通常是一个自定义的检测脚本)判断。
注意:有人喜欢表示、会话和应用层统一模型。
Keepalived启动后由3个进程组成。
- 主进程 - 负责监视和创建子进程
- 子进程1 - 负责VRRP功能
- 子进程2 - 负责健康检查功能
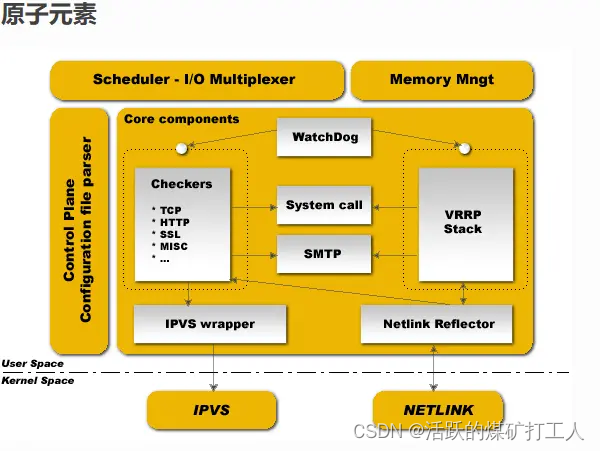
父进程健康框架为watchdog,会周期性的向子进程发送hello数据包,如果发现无法向子进程发送hello包,则父进程会重新启动子进程。
父进程会通过多路IO复用控制程序发送hello数据包来检查子程序中的死循环,也能通过SysV来检查子进程是否存活。
在 Keepalived 服务正常工作时,主 Master 节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备 Backup 节点自己还活看,当主 Master 节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master 节点的心跳了,于是调用自身的接管程序,接管主 Master 节点的 IP 资源及服务。
而当主 Master 节点恢复时,备 Backup 节点又会释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
脑裂
A主机keepalived服务发生故障vip漂移(非脑裂);B主机通信异常vip漂移(脑裂)
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
脚本使用机制(引入第三方仲裁),步骤:
1.查看是否可获取vip,未获取:判断keepalived服务运行状态,运行中不操作,未运行重新启动,结束脚本。
2.服务器周期性地ping一下网关(第三方仲裁ip地址),如果ping通:判断keepalived服务运行状态,运行中不操作,未运行重新启动,结束脚本;如果ping不通则认为自身有问题,累计次数达到阈值,关闭keepalived。
启用磁盘锁。正在服务一方锁住共享磁盘,脑裂发生的时候,让对方完全抢不走共享的磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的乙方不主动解锁,另一方就永远得不到共享磁盘。现实中介入服务节点突然死机或者崩溃,另一方就永远不可能执行解锁命令。后备节点也就截关不了共享的资源和应用服务。于是有人在HA中涉及了“智能”锁,正在服务的一方只在发现心跳线全部断开时才启用磁盘锁,平时就不上锁了
脚本执行方式:
借助keepalived提供的vrrp_script及track_script实现(脚本内keepalived服务如果被关闭,脚本将不在执行,重新启动不生效)
vrrp_script
check_local {
script "/usr/local/src/check_gateway.sh <ip>" #192.168.1.198 需要检查的vip
interval 10 #10秒一次
}
...
track_script {
check_local
}
脚本内容(根据实际环境修改网关ip,是否重新启动keepalived服务)
/usr/local/src/check_gateway.sh
#!/bin/bash
export PATH=$PATH:/usr/sbin
#脑裂检查及控制:第三方仲裁机制,使用ping网关ip方式
#循环次数
CHECK_TIME=3
#虚拟ip
VIP=$1
#网关ip(根据实际环境修改)
GATEWAY=192.168.1.8
#本机网卡
eth=enp2s0
#服务器和网关通信状态 0=失败,1=成功
keepalived_communication_status=1
#是否获取vip状态 0=失败,1=成功
get_vip_status=1
#keepalived服务状态 0=未运行,1=运行中
keepalived_service_status=1
#服务状态运行中字符串
active_status_str='active (running)'
echo "开始执行脚本 check_gateway.sh $VIP;时间:"
date
#查看是否获取vip状态
function check_get_vip_status() {
#通过ip add命令查看ip信息,搜索$VIP,统计行数,是否等于1
if [ $(ip add | grep "$VIP" | wc -l) -eq 1 ]; then
get_vip_status=1
else
get_vip_status=0
fi
return $get_vip_status
}
#检查通信状态
function check_keepalived_status() {
#检测$VIP 能否ping通$GATEWAY:使用$eth网络设备(-I $eth),发送数据包5(-c 5),源地址$VIP询问目的地[vip] $GATEWAY [网关地址 公用参考ip](-s $VIP $GATEWAY) 日志不保存 >/dev/null 2>&1
/sbin/arping -I $eth -c 5 -s $VIP $GATEWAY >/dev/null 2>&1
#判断上一步执行结果 等于0成功
if [ $? = 0 ]; then
keepalived_communication_status=1
else
keepalived_communication_status=0
fi
return $keepalived_communication_status
}
#检查keepalived服务状态
function check_keepalived_service_status() {
#通过systemctl status keepalived.service命令查看keepalived服务状态,搜索$active_status_str,统计行数,是否等于1
if [ $(systemctl status keepalived.service | grep "$active_status_str" | wc -l) -eq 1 ]; then
keepalived_service_status=1
else
keepalived_service_status=0
fi
return $keepalived_service_status
}
#循环执行
#判断$CHECK_TIME 不等于 0
while [ $CHECK_TIME -ne 0 ]; do
#执行check_get_vip_status获取get_vip_status
check_get_vip_status
#未获取vip
if [ $get_vip_status = 0 ]; then
#修改CHECK_TIME值 结束循环
CHECK_TIME=0
#检查服务状态 执行check_keepalived_service_status获取keepalived_service_status
if [ $keepalived_service_status = 0 ]; then
echo "执行脚本 check_gateway.sh $VIP;启动keepalived服务"
systemctl start keepalived.service
fi
echo "执行脚本 check_gateway.sh $VIP;执行结果:未获取vip,无需处理,脚本执行结束,时间:"
date
#正常运行程序并退出程序
exit 0
fi
#$CHECK_TIME = $CHECK_TIME-1
let "CHECK_TIME -= 1"
#执行check_keepalived_status获取keepalived_communication_status
check_keepalived_status
#判断 $keepalived_communication_status = 1 通信成功
if [ $keepalived_communication_status = 1 ]; then
#修改CHECK_TIME值 结束循环
CHECK_TIME=0
#检查服务状态 执行check_keepalived_service_status获取keepalived_service_status
check_keepalived_service_status
if [ $keepalived_service_status = 0 ]; then
echo "执行脚本 check_gateway.sh $VIP;启动keepalived服务"
systemctl start keepalived.service
fi
echo "执行脚本 check_gateway.sh $VIP;GATEWAY=$GATEWAY,执行结果:通信正常,无需处理,脚本执行结束,时间:"
date
#正常运行程序并退出程序
exit 0
fi
#通信失败&&连续3次
if [ $keepalived_communication_status -eq 0 ] && [ $CHECK_TIME -eq 0 ]; then
#关闭keepalived
echo "执行脚本 check_gateway.sh $VIP;关闭keepalived服务"
systemctl stop keepalived.service
echo "执行脚本 check_gateway.sh $VIP;GATEWAY=$GATEWAY,执行结果:通信失败&&连续3次 关闭keepalived,脚本执行结束,时间:"
date
#非正常运行程序并退出程序
exit 1
fi
sleep 3
done
规避方法:
使用配置仲裁:
打开 Keepalived 的配置文件。通常,该文件的路径为 /etc/keepalived/keepalived.conf。
在配置文件中找到 vrrp_instance 部分,这是定义虚拟路由器实例的地方。
在 vrrp_instance 部分中,找到 priority 参数。该参数用于设置路由器的优先级。
将 priority 参数的值修改为所需的优先级。优先级的取值范围为1到254,数值越大表示优先级越高。
保存并关闭配置文件。
重新启动 Keepalived 服务,以使配置更改生效。
使用共享存储限制:
确保所有节点都可以访问同一个共享存储。这可以通过配置网络存储(如NFS、iSCSI或SAN)或使用分布式文件系统(如GFS或HDFS)来实现。
在vrrp_instance部分中,添加以下参数来配置共享存储:
virtual_router_id:设置一个唯一的虚拟路由器ID,以确保节点之间的标识符不会冲突。
state MASTER或BACKUP:根据节点的角色配置状态。MASTER表示该节点为主节点,BACKUP表示该节点为备用节点。
interface:指定用于通信的网络接口。
priority:设置节点的优先级。数值越大表示优先级越高。
virtual_ipaddress:添加虚拟IP地址和相关的网络配置。
在vrrp_instance部分中,添加以下参数来配置共享存储的验证:
authentication_type PASS
authentication_data:设置共享存储的验证密码或密钥。确保所有节点使用相同的验证数据。
重新启动Keepalived服务,以使配置更改生效。
在HA中涉及了“智能”锁,正在服务的一方只在发现心跳线全部断开时才启用磁盘锁,平时就不上锁了
深度刨析嗅探
keepalived根据TCP/IP参考模型的第三层、第四层、第五层交换机制监测每个服务节点的状态,专门用来监控集群系统中各个服务节点的状态。如果某个服务器节点出现异常,或者工作出现故障,keepalived将检测到,并将出现故障的节点从集群系统中剔除。这些操作自动完成,需要人工完成的知识修复出现故障的服务节点。
tcpdump -i ens33 vrrp -w ~/tcpdump/x-keepalived.pcap
>>no time source destination proto len info
18 17.022250 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2)
19 18.023463 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2)
20 19.024858 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2)
21 19.614008 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2)
22 20.224988 192.168.220.102 224.0.0.18 VRRP 60 Announcement (v2) #这个时间进行了切换 间隔有0.6秒
23 21.226812 192.168.220.102 224.0.0.18 VRRP 60 Announcement (v2)
systemctl stop keepalived.service
PID=`ps -ef | grep x | grep -v grep | awk '{cmd="echo "$2;system(cmd)}'`
kill -9 $PID
>no time source destination proto len info
13 12.015911 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2)
14 13.017103 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2) #一般大约1秒一次。
15 13.044299 192.168.220.101 224.0.0.18 VRRP 54 Announcement (v2) #这个突然连续发送了一个包会通知该切换了。
16 13.655466 192.168.220.102 224.0.0.18 VRRP 60 Announcement (v2) #这个时间进行了切换 间隔有0.6秒
17 14.658398 192.168.220.102 224.0.0.18 VRRP 60 Announcement (v2)
18 15.660342 192.168.220.102 224.0.0.18 VRRP 60 Announcement (v2)
reboot -f
tcpdump -i ens33 vrrp -w ~/tcpdump/x-keepalived.pcap
no time source destination proto len info
8 7.009335 192.168.220.101 224.0.0.18 VRRP 60 Announcement (v2)
9 8.010574 192.168.220.101 224.0.0.18 VRRP 60 Announcement (v2)
10 9.011795 192.168.220.101 224.0.0.18 VRRP 60 Announcement (v2)
11 12.622001 192.168.220.102 224.0.0.18 VRRP 54 Announcement (v2) #切换间隔有3秒,使用了keepalived的 backup超时机制。
12 13.623395 192.168.220.102 224.0.0.18 VRRP 54 Announcement (v2)
13 14.623648 192.168.220.102 224.0.0.18 VRRP 54 Announcement (v2)
一般情况下 master keepalived 的最后一条vrrp包会通知。
backup它退出了。但是断电的情况,只能靠backup的超时机制。
backup 超时机制计算
vrrp->ms_down_timer = 3 * vrrp->master_adver_int + VRRP_TIMER_SKEW(vrrp)
vrrp->master_adver_int 是配置文件中的advert_int,这个值在上面的例子中被设定成 1,因此
根据公式算下来 1 * 3 = 3 秒
VRRP_TIMER_SKEW(vrrp) = (256 - Backup路由器的优先级) / 256
Backup路由器的优先级是 100。
(256 - 100)/ 256 = 0.6秒 、
如果优先级是 1 .
(256 - 1)/256 = 1秒
该选项用于精准调制。优先级的取值范围为0到255(数值越大表明优先级越高),可配置的范围是1到254,优先级0为系统保留给特殊用途来使用,255则是系统保留给IP地址拥有者。
Backup路由器的优先级可以通过修改配置文件来实现。具体步骤如下:
打开Keepalived的配置文件。通常,该文件的路径为/etc/keepalived/keepalived.conf。
在配置文件中找到vrrp_instance部分,这是定义虚拟路由器实例的地方。
在vrrp_instance部分中,找到priority参数。该参数用于设置路由器的优先级。
将priority参数的值修改为所需的优先级。优先级的取值范围为1到254,数值越大表示优先级越高。
保存并关闭配置文件。
重新启动Keepalived服务,以使配置更改生效。
注意:
advert_int 这个参数可以大范围改变超时时间,但是要注意,这个参数在vrrp verion2里面最小值只能设为1s,
只有在 vrrp version3 里面才能设为小于1s(测试时配adver_int 0.5)
所以需要在conf中的全局定义中配置:vrrp_version 3
极限:
在global_def中加入vrrp_version 3
将advert_int改为0.1
3 * 0.1 + 0.6 = 1
centos7的arping是iputils工具包下的一个命令,但centos和ubuntu系列自带的arping命令是不同的,centos7的arping没有ubuntu的arping好用,因为功能比较少,比如centos7不能通过某个mac地址获取它的ip地址。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!