高级RGA(一):Embedding模型的选择
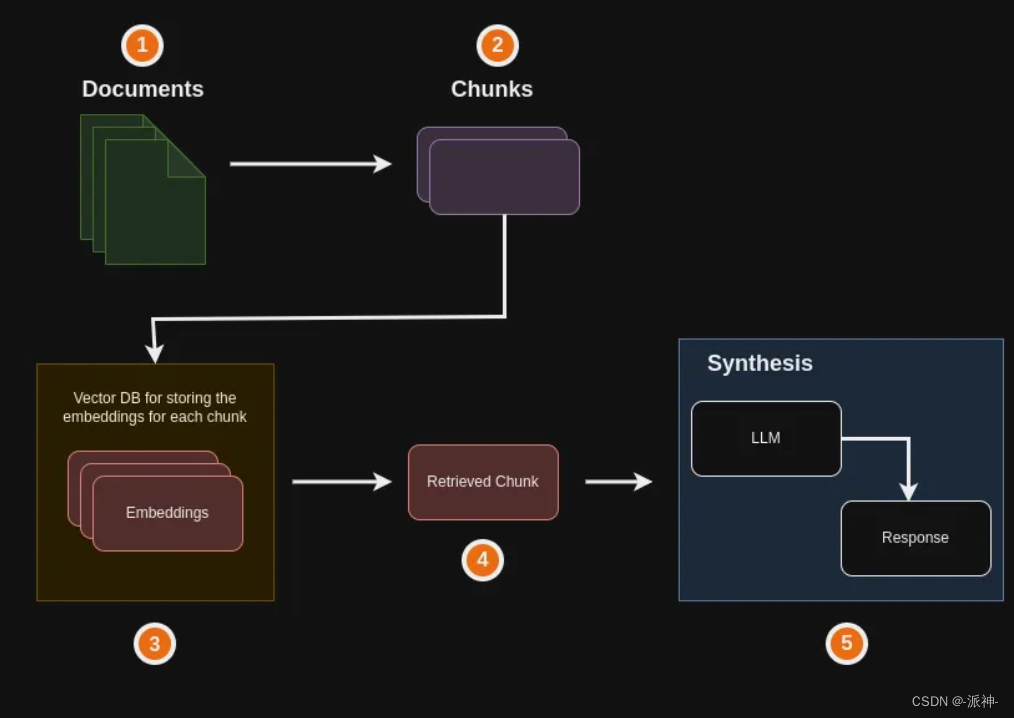
之前我已经写过了一系列的使用Langchain和大模型(LLM)进行应用开发的文章,这里面也涉及到了RGA(Retrieval Augmented Generation?)即“检索增强生成”,它是一种先进的人工智能技术,它结合了信息检索和文本生成,使AI大模型能够从知识源中检索相关信息,并将其融入生成的文本中,我们在做RGA开发时又会涉及到向量数据库,在创建向量数据库时又需要使用Embedding模型对文本进行向量化处理,目前市面上的大模型如OpenAI,Gemini的模型都提供可供调用的Embedding模型,但这些大公司的Embedding模型都存在着种种限制条件比如OpenAI的Embedding模型不是免费的,它是根据token数量来收费的,这显而易见会增加我们的使用成本,而Gemini的Embedding模型目前可以免费使用,但是它又有每分钟不得超过60次调用的限制,这些种种的限制会给我们在创建向量数据库时带来很大的麻烦,为此我们需要找到一种免费的高性能的Embedding模型,经过我在网上不予余力的搜索,终于找到了一个比较适合我们中国人使用的Embedding模型:BAAI的Embedding模型,而且它是我们中国人自己开发的,同时支持中文和英文。大家可以在github或者Huggingface上面查看他们模型的相关信息。

BAAI的模型主要包含三种:同时支持中文和英文,仅支持中文,仅支持英文。他们模型的一大特点是size比较小,比如最大的“BAAI/bge-reranker-large”模型也只有2.24GB,而仅支持中文的“BAAI/bge-small-zh-v1.5”模型只有95M,这意味着如果你的机器没有足够的GPU显存,那它仍然可以在CPU上运行。我们可以在HuggingFace的网站上手工下载他们的各种中/英文的Embedding模型,也可以使用langchain的HuggingFace包在代码中自动下载模型。下面我们需要对Openai、Gemini、BAAI的Embedding模型进行测试,看看他们对自然语言的理解能力孰强孰弱。
一、环境配置
我的机器环境是win11,4080显卡,conda python 3.10,但是我今天没有开启GPU模式,所以BAAI的Embedding模型会在CPU上运行。接下来我们需要安装如下python包:
pip -q install langchain_experimental langchain_core
pip -q install google-generativeai==0.3.1
pip -q install google-ai-generativelanguage==0.4.0
pip -q install langchain-google-genai
pip install -U docarray
pip install pydantic==1.10.9
pip install openai安装了这些python包后如果在运行程序的时候还报错,那请根据报错信息的提示安装相应的python包。安装好这些python包以后,我们需要在代码中导入openai,gemini的api_key的配置文件(.env文件),因为后面我们要对openai,gemini的Embedding模型进行测试需要用到他们的api_key:
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) #加载 .env文件我的.env文件长这样?:
?二、Openai的embedding模型测试
下面我们来创建一个小型的内存向量数据库DocArrayInMemorySearch并在其中插入一些文本,这些文本包括:中文句子,英文句子,数字符号等,这里我们为了在后面检验大模型给出的答案是否是由于"幻觉"而产生的。所以会往向量数据库中插入一些违背常识的文本。
接下来我们要考察一下Openai的embedding模型对中文,英文,数字符号的理解能力,因为Openai的embedding模型是根据token数量来收费的,因此为了演示所以我们使用小型的内存向量数据库并在里面插入一些简单的文本。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import DocArrayInMemorySearch
#创建openai的embeddings
openai_embeddings = OpenAIEmbeddings()
#创建向量数据库
vectordb = DocArrayInMemorySearch.from_texts(
["青蛙是食草动物",
"人是由恐龙进化而来的。",
"熊猫喜欢吃天鹅肉。",
"1+1=5",
"2+2=8",
"3+3=9",
"Gemini Pro is a Large Language Model was made by GoogleDeepMind",
"A Language model is trained by predicting the next token"
],
embedding=openai_embeddings
)
#创建检索器,让它每次只返回1条最相关的文档:search_kwargs={"k": 1}
openai_retriever = vectordb.as_retriever(search_kwargs={"k": 1})这里我们创建了一个内存向量数据库vectordb,并在里面创建了3句中文,3句数字符号,2句英文的文本。然后我们又创建了一个检索器openai_retriever,它可以根据问题从向量数据库中检索出与问题最相关的文档,这里我们设置了openai_retriever的参数search_kwargs={"k": 1},这表示openai_retriever每次只检索1条最相关的文档给用户,你也可以设置为检索多条相关文档。下面我们来测试openai_retriever对文本的理解能力:

这里我们看到openai_retriever基本上能够检索出相关的文档,尽管也存在错误,比如最后一个问题"token",检索出来的是"青蛙是食草动物",这显然是错误的。不过总体来说还可以。
三、Gemini的embedding模型测试
接下来我们要对Gemini的embedding模型测试,我们也让gemini的检索器回答同样的问题:
gemini_embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
vectordb = DocArrayInMemorySearch.from_texts(
["青蛙是食草动物",
"人是由恐龙进化而来的。",
"熊猫喜欢吃天鹅肉。",
"1+1=5",
"2+2=8",
"3+3=9",
"Gemini Pro is a Large Language Model was made by GoogleDeepMind",
"A Language model is trained by predicting the next token"
],
embedding=gemini_embeddings
)
# #创建检索器
gemini_retriever = vectordb.as_retriever(search_kwargs={"k": 1})
这里我们看到gemini_retriever对文本的理解能力非常差,几乎所有的问题都答错了,只回答对了第一个问题,目前我也不清楚这到底是什么原因造成的。如果是这样的一个水平,那么gemini的embedding我们是不能用的。下面我们来测试BAAI的embedding模型。
四、BAAI的embedding模型测试
下面我们要进行最后一个开源免费的BAAI的embedding模型测试,因为BAAI发布了好几款embedding模型模型,所以这里我挑选一个支持中文的模型:"BAAI/bge-large-zh-v1.5"它的大小为1.3GB,我让它跑在了CPU上。
from langchain.embeddings import HuggingFaceBgeEmbeddings
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vectordb = DocArrayInMemorySearch.from_texts(
["青蛙是食草动物",
"人是由恐龙进化而来的。",
"熊猫喜欢吃天鹅肉。",
"1+1=5",
"2+2=8",
"3+3=9",
"Gemini Pro is a Large Language Model was made by GoogleDeepMind",
"A Language model is trained by predicting the next token"
],
embedding=bge_embeddings
)
# #创建检索器
bge_retriever = vectordb.as_retriever(search_kwargs={"k": 1})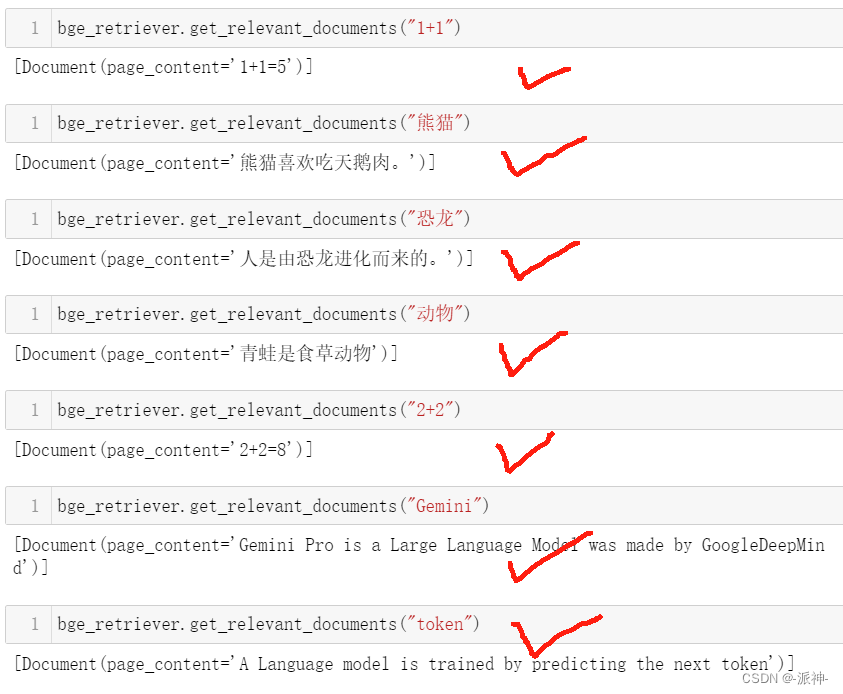
这里我们看到bge_retriever对所有的中文,英文,数字符号的问题都回答正确,非常漂亮!因此我感觉BAAI的embedding模型可以用在以后的RAG的应用开发上。因为它是开源免费的,所以我们既节省了成本,又提高了检索的性能。
五、BAAI的embedding的应用开发
下面我们通过之前学习的LangChain的表达式语言(LCEL)来创建一个Chain,并结合Gemini的大模型"gemini-pro"来完成对向量数据库内容进行问答的功能:
from langchain.schema.runnable import RunnableMap
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_google_genai import ChatGoogleGenerativeAI
#创建model
model = ChatGoogleGenerativeAI(model="gemini-pro")
#创建prompt模板
template = """Answer the question a full sentence,
based only on the following context:
{context}
Question: {question}
"""
#由模板生成prompt
prompt = ChatPromptTemplate.from_template(template)
#创建chain
chain = RunnableMap({
"context": lambda x: bge_retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | StrOutputParser()下面我们针对向量数据库中的文本提出针对性的问题,看看Gemini模型是怎么回答的,这里需要说明的是当chain在执行invoke的时候会像通过检索器bge_retriever去向量数据库中检索与问题相关的文档,并将这些相关文档和问题一同发送给Gemini大模型,Gemini模型会根据问题和相关文档渲染出一个对用户友好的回复:

?这里我们看到chain返回的结果都是来自于向量数据库中的相关文档,对于最后一个问题:chatgpt是什么?,由于向量库中没有存放关于chatgpt的文本,所以最后返回了的是:这个语料里没有关于ChatGPT的信息,因此我无法回答这个问题。这说明gemini模型并没有因"幻觉"给出一个答案,它只是严格的根据prompt模板的要求来回答问题。
六、总结
今天我们测试了openai,gemini,baai它们的embedding模型,我们发现baai的embedding模型表现最为优秀,它检索出了所有的相关文档,而gemini的embedding模型表现最差,它机会都没有检索出任何相关文档,我并不清楚这是什么原因造成的。openai的embedding模型表现尚可,但是由于它不是免费的,所以存在一定的使用成本,而baai的embedding模型却是开源免费的,而且性能也是非常好的,所以大家可以使用baai的embedding模型来代替openai或者gemini的embedding模型。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!