Encoder-Decoder和Auto-Encoder的简介
目录
# 一、Encoder-Decoder
1.Encoder
Encoder也就是编码器,作用是将输入序列转化成一个固定维度的向量,这个向量就可以看成输入序列的语义,利用语义可以做一些下游的任务比如说特征提取等。
简单来说就是机器理解数据的过程,这个过程将现实问题转化成数学问题,如下图所示:
2.Decoder
Decoder也就是解码器,负责根据Encoder部分输出的语义向量来做解码工作。以图像生成为例,Decoder相当于一个Generator(VAE),其要做的就是根据特征信息来生成图片。
简单来说,Decode的过程就是将数学问题转换为现实世界的过程,如下图所示:
Encoder-Decoder是一个模型通用的框架,是一类算法统称,在这个框架下可以使用不同的算法来解决不同的任务。其具体架构可以如下所示:
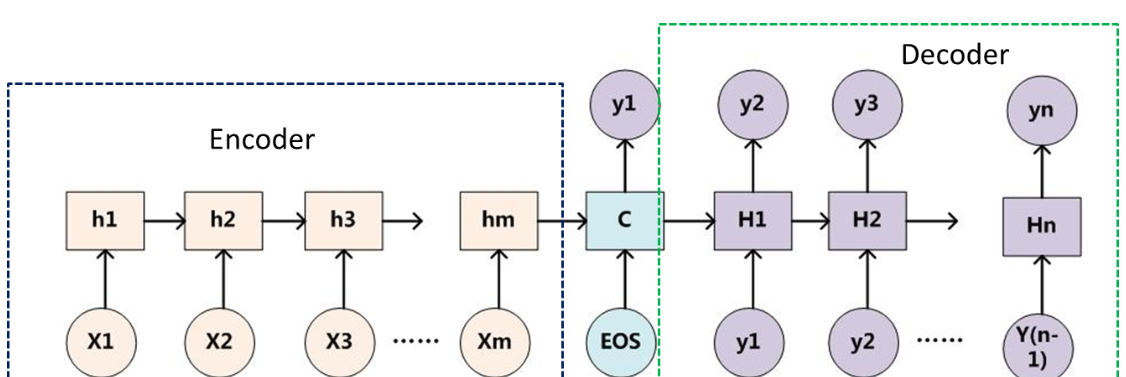
3.Encoder-Decoder
几点说明
- 不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
- Encoder-Decoder的一个显著特征就是:它是一个End-To-End的学习算法,End-To-End译为端到端的学习,就是把特征提取的任务也交给模型去做,直接输入原始数据或者经过些微预处理的数据,让模型自己进行特征提取。
- 只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
存在的问题
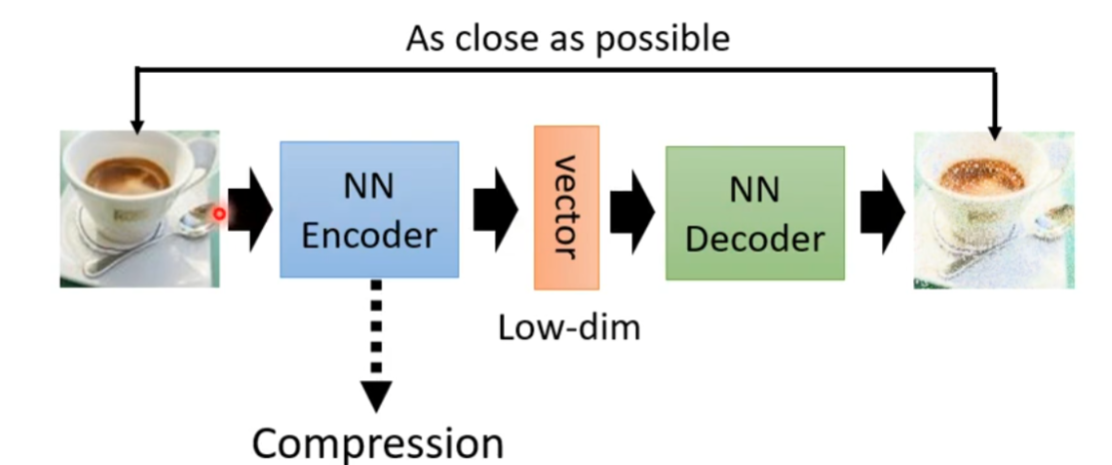
通过Encoder-Decoder的架构图可以发现,Encoder和Decoder之间共享向量 c c c,而且向量 c c c的长度是固定的。以图像生成为例,Encoder将输入图像 X X X(RGB)经过Encoder进行特征提取后压缩成向量 c c c,由于向量 c c c只包含了输入图像 X X X的主要特征信息,所以这一个Encoder这一过程便导致了信息丢失。你可能会问,为什么不扩充向量 c c c的维度以保存更多输入图像的信息呢?这是因为Encoder的过程就是为了减少计算量,如果扩充了向量 c c c的维度岂不是违背了Encoder的原意了?也就是说,Encoder的过程存在两个弊端:一是语义向量 c c c无法完全表示整个序列的信息,二是先输入的内容携带的信息会被后输入的信息稀释(这一点在文本生成中比较明显)。
就拿Encoder-Decoder的一个应用方向信息压缩为例,通过Encoder的降维功能可以实现数据的压缩(但这是一种失真的压缩技术,会丢失一些信息),如下图所示:
Auto-Encoder
简介
Auto-Encoder,称自编码器,是一种无监督式学习模型。它基于反向传播算法与最优化方法(如梯度下降法),AE(Auto-Encoder)的结构图可以如下所示;
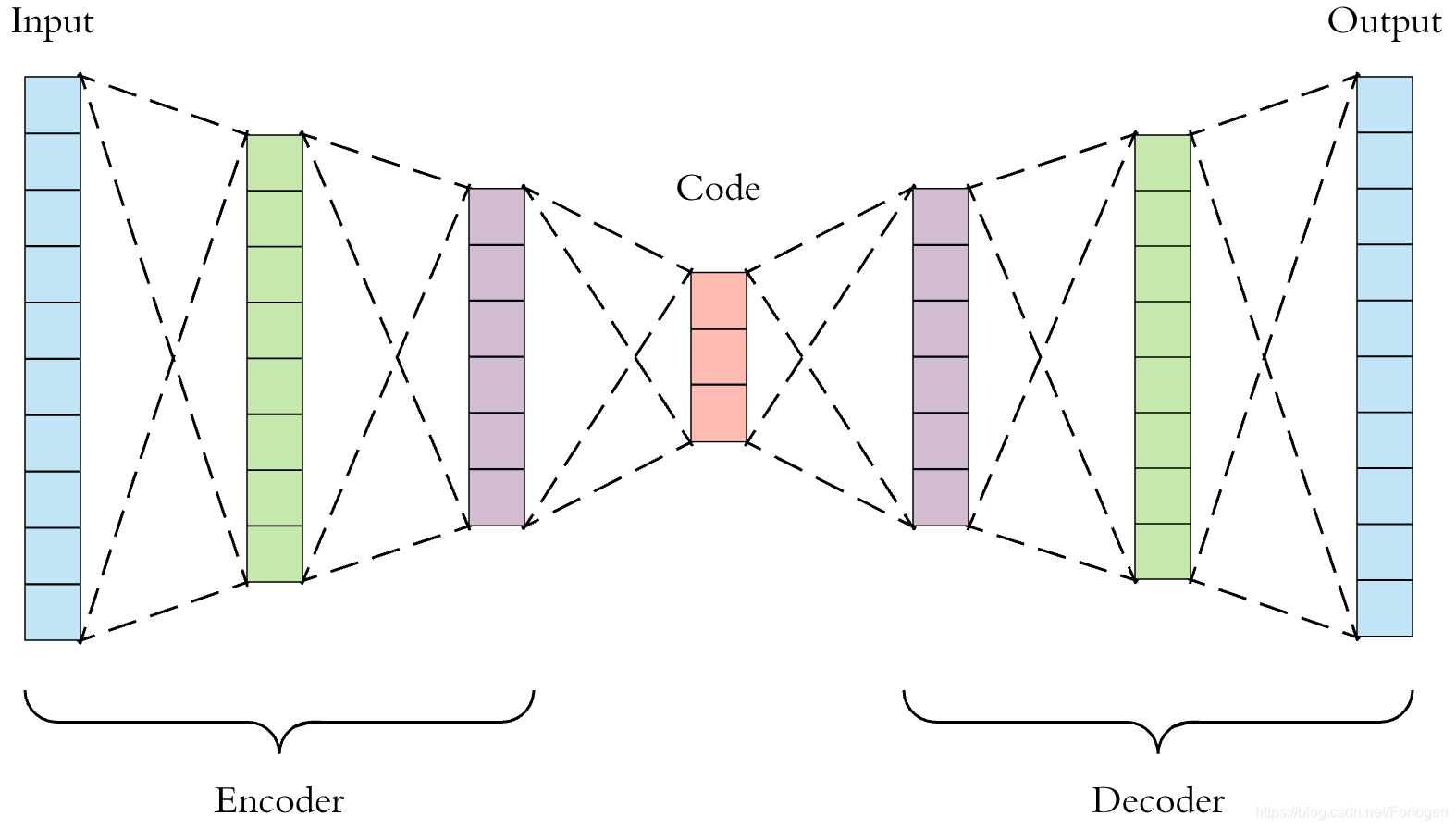
记 X X X为整个数据集的集合, x i x_{i} xi?是数据集中的一个样本。
自编码器包含一个编码器 z = g ( X ) z=g(X) z=g(X),称 z z z为编码,并且往往 z z z的维度远小于输入 X X X的维度。此外还包含一个解码器 X ~ = f ( z ) \tilde{X} =f(z) X~=f(z),这个解码器从编码 z z z中还原输入 X X X的信息。
我们自然希望 X ~ \tilde{X} X~与 X X X尽可能地接近,因此我们可以定义自编码器的损失函数为 ? = ∥ X ? X ~ ∥ \ell=\begin{Vmatrix} X-\tilde{X} \end{Vmatrix} ?= ?X?X~? ?,于是模型训练结束后,我们便可以认为 z z z蕴含了输入 X X X的大部分信息,则能够表达原始数据以实现数据降维的目的。
为此,我们可以将自编码器简记为:
X
∈
R
C
×
H
×
W
?
z
=
g
(
X
)
∈
R
d
?
X
~
=
f
(
z
)
∈
R
C
×
H
×
W
X \in \mathbb{R}^{C\times H\times W}\longrightarrow z=g(X) \in \mathbb{R}^{d}\longrightarrow \tilde{X} =f(z) \in \mathbb{R}^{C\times H\times W}
X∈RC×H×W?z=g(X)∈Rd?X~=f(z)∈RC×H×W其中
C
C
C表示通道数(彩色图片为RGB三通道),
H
,
W
H,W
H,W分别表示图片数据的高和宽。
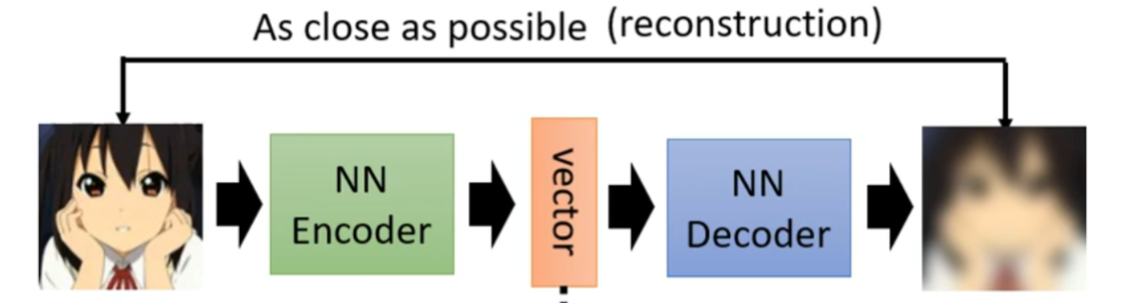
借用李宏毅老师课程的图片,Auto-Encoder的结构如图所示:
Auto-Encoder代码实现(以 MNIST手写数据集为例)
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from torch import nn, optim
# 定义AE类
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# encoder [b,784] => [b,64] # 784就指的是数据集的个数,有10个特征
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
)
# decoder [b,64] => [b,784]
self.decoder = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid(),
)
def forward(self, x):
batch_size = x.size(0)
# 拉成向量
x = x.view(batch_size, 784)
# 编码
x = self.encoder(x)
# 解码
x = self.decoder(x)
# 变成四维张量,(batch_size, channel, height, width)
x = x.view(batch_size, 1, 28, 28)
# 返回
return x
def main():
# 构建训练集
mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([transforms.ToTensor()]),
download=True)
mnist_train = DataLoader(mnist_train, batch_size=64, shuffle=True)
# 构建测试集
mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([transforms.ToTensor()]),
download=True)
mnist_test = DataLoader(mnist_test, batch_size=64, shuffle=False)
# 打印测试集的个数
print(len(mnist_train))
# 有GPU则使用GPU进行训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = AutoEncoder().to(device)
# 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 损失函数,L2平方损失函数
criterion = nn.MSELoss()
# 迭代训练
for epoch in range(1001):
for batch_idx, (x, _) in enumerate(mnist_train):
# [b,1,28,28]
x = x.to(device) # 放到device上训练
# forward
x_hat = model(x) # X'
loss = criterion(x_hat, x) # 计算X'和X的距离(L2范数)
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
if epoch % 20 == 0:
print("loss:", loss.item())
if __name__ == '__main__':
main()
除此之外,还有一种DAE(Denoising Auto-Encoder),仍然是借用李宏毅老师的ppt,其架构图如下:
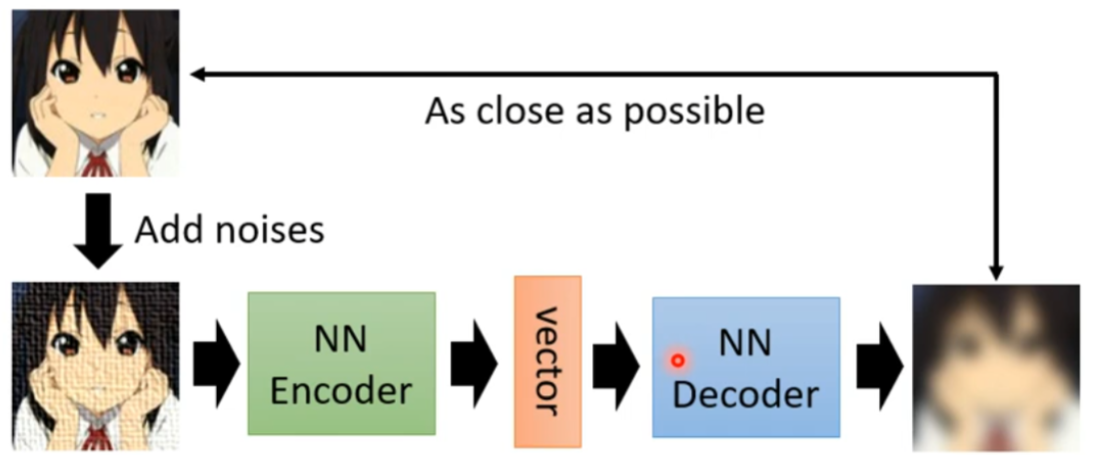
在此就不再多言DAE啦,以上便是Encoder-Decoder的一个简单介绍,下次得看看VAE啦。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!