关联规则 python实现Apriori算法
2023-12-17 06:33:11
python实现Apriori算法
根据我们上个博客的例子
def load_dataset():
# 载入数据集的函数
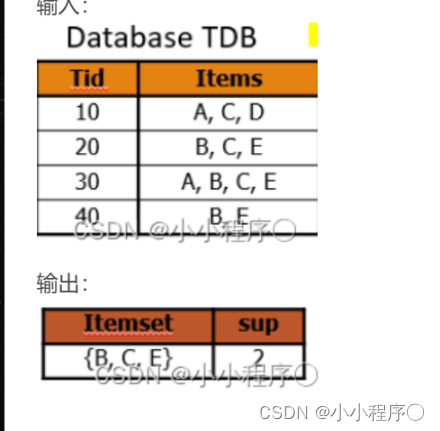
dataset = [
['A', '', 'D'],
['B', 'C', 'E'],
['A', 'B', 'C', 'E'],
['B', 'E']
]
return dataset
def create_candidates(dataset):
# 生成1项集的候选集函数
candidates = []
for transaction in dataset:
for item in transaction:
if [item] not in candidates:
candidates.append([item])
candidates.sort()
return list(map(frozenset, candidates))
def scan_dataset(dataset, candidates, min_support):
# 扫描数据集,计算候选集的支持度
item_count = {} # 记录候选集出现的次数
for transaction in dataset:
for candidate in candidates:
if candidate.issubset(transaction):
item_count[candidate] = item_count.get(candidate, 0) + 1
num_transactions = len(dataset)
frequent_set = [] # 存储频繁项集
support_data = {} # 存储支持度数据
for item in item_count:
support = item_count[item] / num_transactions
if support >= min_support:
frequent_set.append(item)
support_data[item] = support
return frequent_set, support_data
def generate_next_candidates(prev_frequent_set, k):
# 生成下一轮的候选集函数
next_candidates = [] # 存储下一轮的候选集
num_frequent_set = len(prev_frequent_set)
for i in range(num_frequent_set):
for j in range(i + 1, num_frequent_set):
item1 = list(prev_frequent_set[i])[:k - 2]
item2 = list(prev_frequent_set[j])[:k - 2]
item1.sort()
item2.sort()
if item1 == item2:
next_candidate = prev_frequent_set[i] | prev_frequent_set[j]
next_candidates.append(next_candidate)
return next_candidates
def apriori(dataset, min_support=0.5):
# Apriori 算法主函数
candidates = create_candidates(dataset)
dataset = list(map(set, dataset))
frequent_set1, support_data = scan_dataset(dataset, candidates, min_support)
frequent_sets = [frequent_set1]
k = 2
while len(frequent_sets[k - 2]) > 0:
candidates = generate_next_candidates(frequent_sets[k - 2], k)
frequent_set, support_data_k = scan_dataset(dataset, candidates, min_support)
support_data.update(support_data_k)
frequent_sets.append(frequent_set)
k += 1
return frequent_sets, support_data
# 示例用法
dataset = load_dataset()
frequent_sets, support_data = apriori(dataset, min_support=0.5)
print("频繁项集:")
for i, itemset in enumerate(frequent_sets):
if itemset:
print(f"第 {i + 1} 轮: {itemset}")
print("\n支持度数据:")
for item, support in support_data.items():
print(f"{item}: {support}")
结果
频繁项集:
第 1 轮: [frozenset({‘A’}), frozenset({‘B’}), frozenset({‘C’}), frozenset({‘E’})]
第 2 轮: [frozenset({‘C’, ‘B’}), frozenset({‘E’, ‘B’}), frozenset({‘C’, ‘E’})]
第 3 轮: [frozenset({‘C’, ‘E’, ‘B’})]
支持度数据:
frozenset({‘A’}): 0.5
frozenset({‘D’}): 0.25
frozenset({‘B’}): 0.75
frozenset({‘C’}): 0.5
frozenset({‘E’}): 0.75
frozenset({‘C’, ‘B’}): 0.5
frozenset({‘E’, ‘B’}): 0.75
frozenset({‘C’, ‘E’}): 0.5
frozenset({‘A’, ‘B’}): 0.25
frozenset({‘C’, ‘A’}): 0.25
frozenset({‘A’, ‘E’}): 0.25
frozenset({‘C’, ‘E’, ‘B’}): 0.5
文章来源:https://blog.csdn.net/2201_75381449/article/details/135039646
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!