国产ToolLLM的课代表---OpenBMB机构(清华NLP)旗下ToolBench的安装部署与运行(附各种填坑说明)
ToolBench项目可以理解为一个能直接提供训练ToolLLM的平台,该平台同时构建了ToolLLM的一个开源训练指令集。,该项目是OpenBMB机构(面壁智能与清华NLP联合成立)旗下的一款产品,OpenBMB机构名下还同时拥有另外一款明星产品–XAgent。
ToolBench的简介
该项目旨在构建开源、大规模、高质量的指令调整 SFT 数据,以促进构建具有通用工具使用能力的强大LLMs。其目标是赋予开源 LLMs 掌握成千上万多样的真实世界API能力。项目通过收集高质量的指令调整数据集来实现这一目标。该数据集使用最新的ChatGPT(gpt-3.5-turbo-16k)自动构建,该版本升级了增强的函数调用功能。
与此同时,通过项目提供的数据集、相应的训练和评估脚本,可以得到ToolBench上经过微调的一个强大的工具调用模型ToolLLaMA。
项目数据集的构建
以下是数据集构建方法、模型训练、推理模式的整体概览
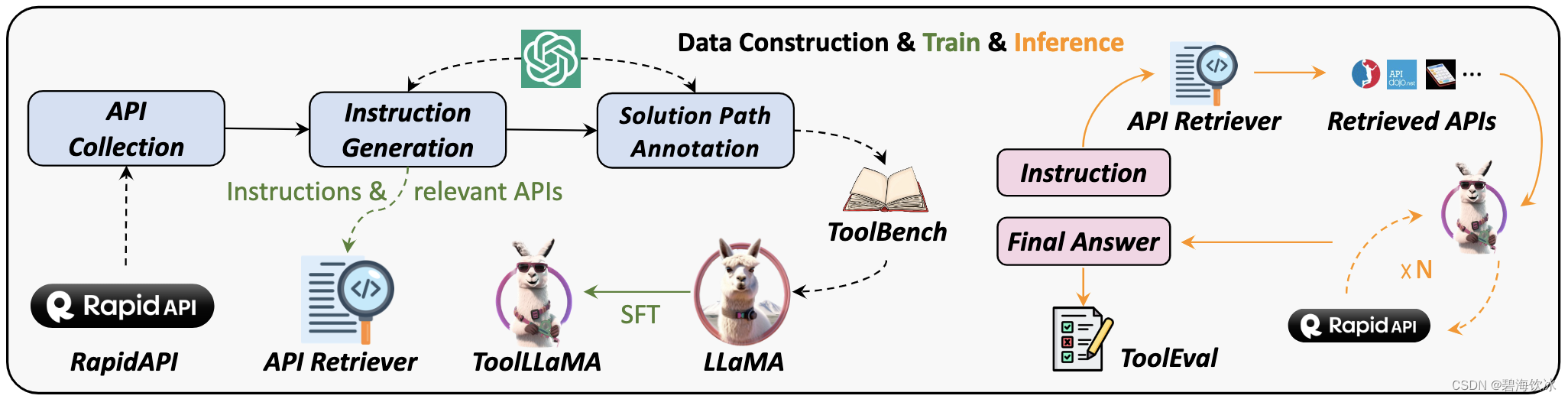
产品自身特点
API收集: 项目从 RapidAPI 收集了 16464 个API。RapidAPI 是一个托管开发者提供的大规模真实世界API的平台。
指令生成: 项目生成了涉及单工具和多工具场景的指令。
回答标注: 项目设计了一种新颖的深度优先搜索决策树方法(DFSDT),以增强LLMs的规划和推理能力。这显著提高了标注效率,并成功地对那些不能用CoT或ReACT回答的复杂指令进行了标注。项目提供的回答不仅包括最终答案,还包括模型的推理过程、工具执行和工具执行结果。
API Retriever: 项目整合了API检索模块,为ToolLLaMA提供了开放域的工具使用能力。
数据生成:所有数据均由OpenAI API自动生成并由项目组筛选,整个数据创建过程易于扩展。
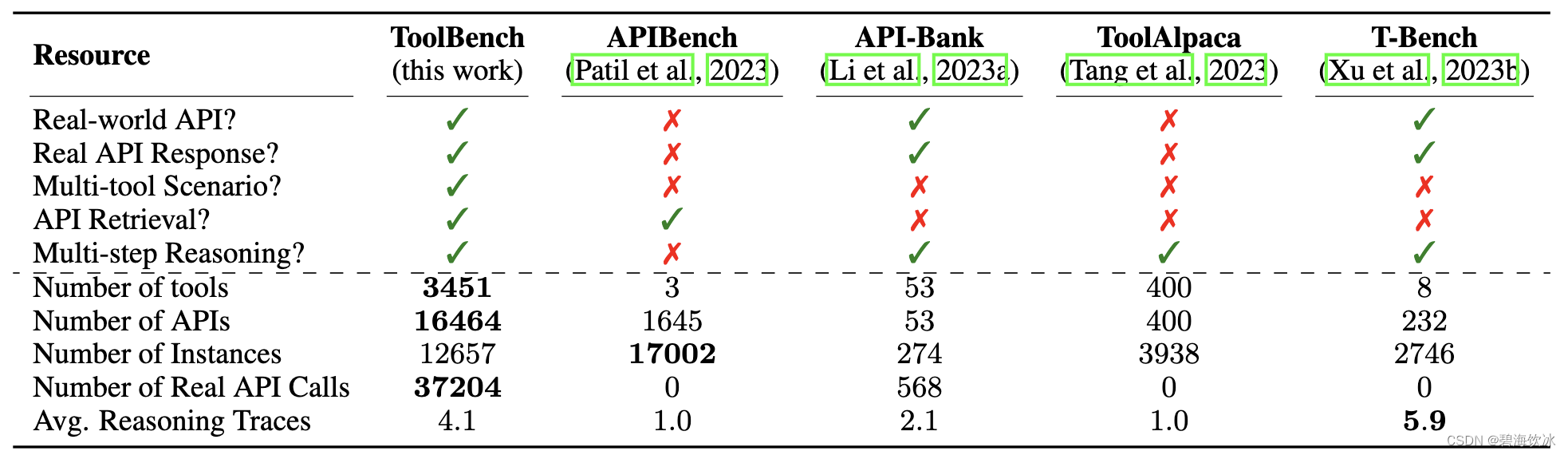
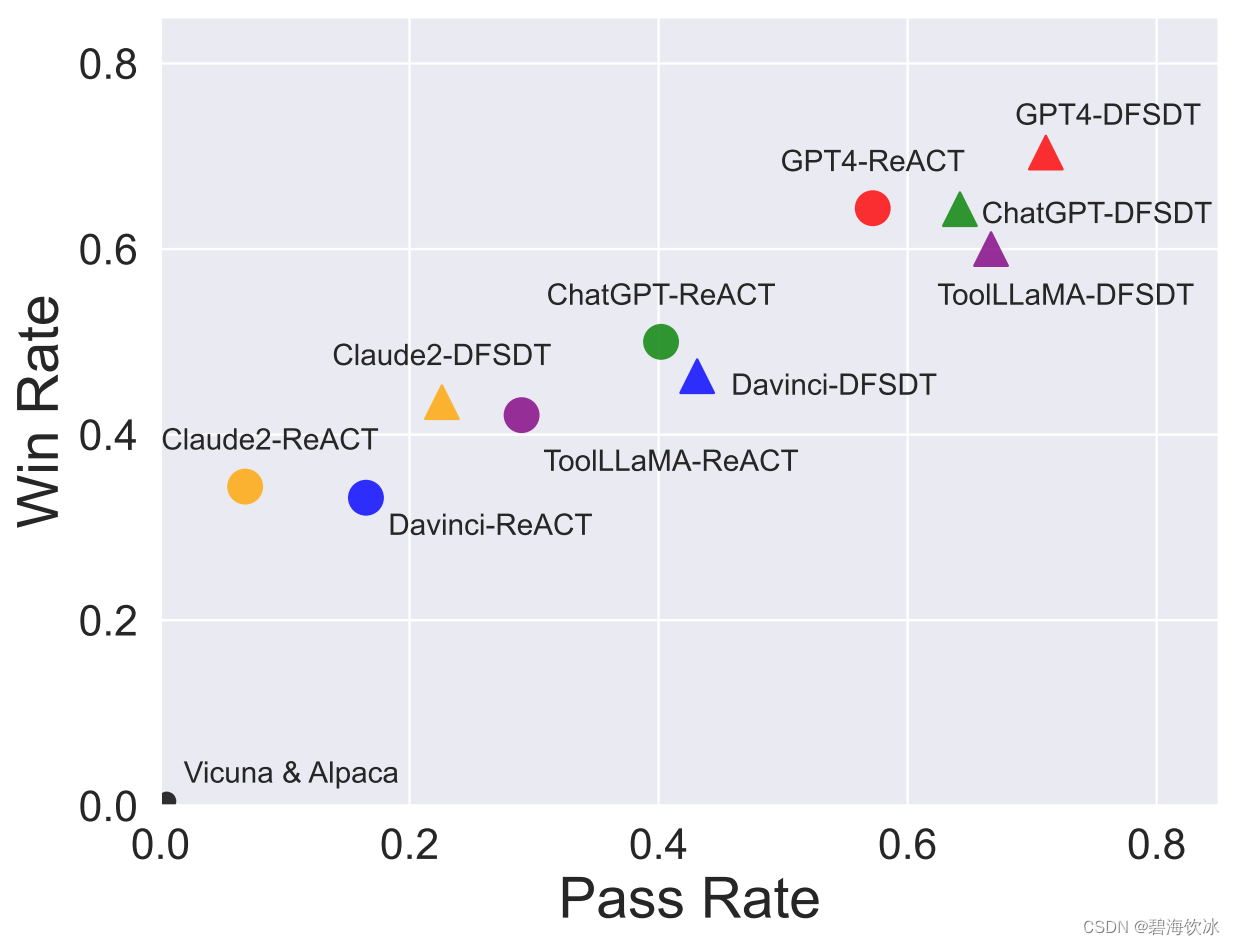
ToolLLaMA已经达到了和ChatGPT(turbo-16k)接近的工具使用能力,未来我们将不断进行数据的后处理与清洗,以提高数据质量并增加真实世界工具的覆盖范围。
产品的FT(FineTuning)
该项目提供了ToolLLaMA的FT方法,本篇不做更多介绍,又兴趣的同学可以到这里查看其具体流程
ToolBench的安装
Clone项目
克隆这个仓库并进入ToolBench文件夹。
git clone git@github.com:OpenBMB/ToolBench.git
cd ToolBench
申请项目方的ToolbenchKey
因为项目方自建了RapidAPI的服务,可以向项目方申请使用该RapidAPI服务进行推理。
请点击这里填写问卷,大概2个工作日内,工作人员会给你ToolBench项目方给您发送toolbench key。然后初始化您的toolbench key:
export TOOLBENCH_KEY="your_toolbench_key"
当然,您也可以使用自己私有的RapidAPI Account进行推理,具体操作可以看这里
ToolBench 的设置与启动
ToolBench运行环境是要求Python>=3.9,此处我们用了Python3.10,为防止环境间的干扰,使用了Conda,Conda的安装配置可以自行百度解决,要注意下载2023年的版本,能够支持到3.10才可以
# 新创建toolbench_env环境,使用python3.10
conda create -n toolbench_env python=3.10 -y
# 查看已建立的所有的虚拟环境
conda env list
# conda environments:
#
# base * /root/anaconda3
# py310 /root/anaconda3/envs/py310
# toolbench_env /root/anaconda3/envs/toolbench_env
# 切换到toolbench_env
conda active toolbench_env
# 在Toolbench的根目录下执行以下命令安装依赖包
pip install -r requirements.txt
DataSet的下载
推理时会需要一些预设的数据(其实,大部分数据时训练ToolLLaMA模型所使用的),可以到 Tsinghua Cloud.这个地方去下载
下载的数据解压后,就在项目目录的data文件夹下,400M大小,其数据的目录格式如下
├── /data/
│ ├── /instruction/
│ ├── /answer/
│ ├── /toolenv/
│ ├── /retrieval/
│ ├── /test_instruction/
│ ├── /test_query_ids/
│ ├── /retrieval_test_query_ids/
│ ├── toolllama_G123_dfs_train.json
│ └── toolllama_G123_dfs_eval.json
├── /reproduction_data/
│ ├── /chatgpt_cot/
│ ├── /chatgpt_dfs/
│ ├── ...
│ └── /toolllama_dfs/
ToolBench的python应用推理
运行推理时,可以使用项目方已经训练完毕的ToolLLaMA版本,也可以使用OpenAI的key来调用GPT3.5或GPT4.0服务。
使用项目方的ToolLLaMA
项目方已经训练的ToolLLaMA版本已升级到ToolLLaMA-2-7b-v2,其模型利用了Toolbench项目的数据集,经由LLaMA-2-7b微调而来, 可免费下载使用。
抱抱脸那边时常连接不太稳定,而且,当前的ToolLLaMA-2-7b-v2模型文件的总和已经到达20G+,连接外网不方便或机器资源不那么充裕的,大概率会被劝退,这时可以使用OpenAI的Key来试试效果~~
使用OpenAI的key
- 用rapidAPI作答
将您的OPENAI_KEY设定后,使用以下代码运行(官方的指引直接跑不起来,请使用我的这个命令)
export TOOLBENCH_KEY=""
export OPENAI_KEY=""
export PYTHONPATH=./
python toolbench/inference/qa_pipeline.py \
--tool_root_dir data/toolenv/tools/ \
--backbone_model chatgpt_function \
--openai_key $OPENAI_KEY \
--max_observation_length 1024 \
--method DFS_woFilter_w2 \
--input_query_file data/test_instruction/G1_instruction.json \
--output_answer_file chatgpt_dfs_inference_result/qa_answer \
--toolbench_key $TOOLBENCH_KEY
注意的坑:如果代码提示有说OpenAI版本过高的问题,可以直接运行以下命令,将openai包还原到1.00以下
pip install openai==0.28.0
执行以上的命令时,会解析ata/test_instruction/G1_instruction.json文件的请求,然后进行响应,这个文件如果不做任何编辑,猜想应该会把里面的所有Task都跑一遍,我还是很心疼自己的美刀,于是只留出一个看看效果就行了,G1_instruction.json文件裁剪后的内容如下:
[
{
"api_list": [
{
"category_name": "Food",
"tool_name": "Nutrition by API-Ninjas",
"api_name": "/v1/nutrition",
"api_description": "API Ninjas Nutrition API endpoint.",
"required_parameters": [
{
"name": "query",
"type": "STRING",
"description": "Query text to extract nutrition information (e.g. **bacon and 3 eggs**).",
"default": "1lb brisket with fries"
}
],
"optional_parameters": [],
"method": "GET",
"template_response": {
"name": "str",
"calories": "float",
"serving_size_g": "float",
"fat_total_g": "float",
"fat_saturated_g": "float",
"protein_g": "float",
"sodium_mg": "int",
"potassium_mg": "int",
"cholesterol_mg": "int",
"carbohydrates_total_g": "float",
"fiber_g": "float",
"sugar_g": "float"
}
}
],
"query": "I'm planning a family dinner and I need to know the nutrition information for a recipe. Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?",
"relevant APIs": [
[
"Nutrition by API-Ninjas",
"/v1/nutrition"
]
],
"query_id": 88193
}
]
上面那个文件的示例,其实也就是要问这句话:
I’m planning a family dinner and I need to know the nutrition information for a recipe.
Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?
如果运行成功,可以看到输出的内容如下:
[process(0)]now playing I'm planning a family dinner and I need to know the nutrition information for a recipe. Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?, with 2 APIs
[process(0)]total tokens: 698
Action: v1_nutrition_for_nutrition_by_api_ninjas
query to Food-->nutrition_by_api_ninjas-->v1_nutrition_for_nutrition_by_api_ninjas
Action Input: {
"query": "2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil"
}
Observation: {"error": "", "response": "[{'name': 'chicken', 'calories': 2019.8, 'serving_size_g': 907.184, 'fat_total_g': 117.0, 'fat_saturated_g': 33.2, 'protein_g': 215.3, 'sodium_mg': 655, 'potassium_mg': 1625, 'cholesterol_mg': 835, 'carbohydrates_total_g': 0.4, 'fiber_g': 0.0, 'sugar_g': 0.0}, {'name': 'rice', 'calories': 201.3, 'serving_size_g': 158.0, 'fat_total_g': 0.4, 'fat_saturated_g': 0.1, 'protein_g': 4.2, 'sodium_mg': 1, 'potassium_mg': 67, 'cholesterol_mg': 0, 'carbohydrates_total_g': 44.9, 'fiber_g': 0.6, 'sugar_g': 0.1}, {'name': 'olive oil', 'calories': 352.0, 'serving_size_g': 40.5, 'fat_total_g': 41.0, 'fat_saturated_g': 5.6, 'protein_g': 0.0, 'sodium_mg': 0, 'potassium_mg': 0, 'cholesterol_mg': 0, 'carbohydrates_total_g': 0.0, 'fiber_g': 0.0, 'sugar_g': 0.0}]"}
[process(0)]total tokens: 1405
Action: Finish
Action Input: {
"return_type": "give_answer",
"final_answer": "The nutrition information for the dish is as follows:\n- Chicken:\n - Calories: 2019.8\n - Fat: 117g\n - Saturated Fat: 33.2g\n - Protein: 215.3g\n - Sodium: 655mg\n - Potassium: 1625mg\n - Cholesterol: 835mg\n - Carbohydrates: 0.4g\n - Fiber: 0g\n - Sugar: 0g\n- Rice:\n - Calories: 201.3\n - Fat: 0.4g\n - Saturated Fat: 0.1g\n - Protein: 4.2g\n - Sodium: 1mg\n - Potassium: 67mg\n - Cholesterol: 0mg\n - Carbohydrates: 44.9g\n - Fiber: 0.6g\n - Sugar: 0.1g\n- Olive Oil:\n - Calories: 352\n - Fat: 41g\n - Saturated Fat: 5.6g\n - Protein: 0g\n - Sodium: 0mg\n - Potassium: 0mg\n - Cholesterol: 0mg\n - Carbohydrates: 0g\n - Fiber: 0g\n - Sugar: 0g"
}
Observation: {"response":"successfully giving the final answer."}
[process(0)]valid=True
另外,以上命令运行一次以后,就会在chatgpt_dfs_inference_result/qa_answer文件夹中生成回复文件,再次运行时不会重复生成
- 用customAPI作答
这种方式,其开源项目地址已有描述,可以参照这里
需要注意的坑:
第一, API描述的json文件中,tool_name字段名要和文件名保持一致,是不是一定英文没有验证过
第二,json描述文件的位置要在data/toolenv/tools/目录下面,且要新建文件夹,文件夹的名字不一定非要是’Customized’,但位置不能变,因为所有tools的白名单都是从data/toolenv/tools/目录获取的
后端:server启动
正常提供服务时,我们还是需要把各个可执行命令转化为server服务,方便进行连续测试,以下则是server启动的操作方法(此处用的还是openai key,如果你想使用ToolLLaMA来启动,请参照github上的说明):
export TOOLBENCH_KEY="your toolbench key is applied from ToolBench platform"
export OPENAI_KEY="your OpenAI key"
export PYTHONPATH=./
# 该条命令能够启动Toolbenchserver,不过目前官方的server启动模式还尚未能完全兼容gpt的指令,
# 在前端发出指令后,其响应的代码逻辑仍存在问题.
# 查看了一下源码,应该是toolbench_server.py代码中定义data_dict = { "query": user_input},这个对象的包装缺少api_tools的相关定义,
# 其缺失的代码逻辑需要补足后才能正常工作(本来是打算server启动后再来hack代码尝试的,发现可能需要不少变动甚至重构,还没有成型的解决方案)
python toolbench/inference/toolbench_server.py \
--corpus_tsv_path data/retrieval/G1/corpus.tsv \
--retrieved_api_nums 5 \
--tool_root_dir data/toolenv/tools/ \
--backbone_model chatgpt_function \
--openai_key $OPENAI_KEY \
--max_observation_length 1024 \
--method DFS_woFilter_w2 \
--input_query_file data/test_instruction/G1_instruction.json \
--output_answer_file chatgpt_dfs_inference_result/server_answer \
--toolbench_key $TOOLBENCH_KEY
注意的坑:以上使用openai key的方式启动,如果有关于model path的错误爆出时,可以将toolbench\inference\toolbench_server.py的部分代码进行变动以绕过。
# 在class Model初始化的那部分代码中变动以下内容:
print("Loading retriever...")
# 注释下面这句,然后将retriever赋None值,因为使用chatgpt_function时,不会使用retriever相关代码
# self.retriever = self.pipeline.get_retriever()
self.retriever = None
正常启动后,可以看到以下提示:
Server ready
* Serving Flask app 'toolbench_server'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://10.0.0.11:5000
Press CTRL+C to quit
前端:chatbot-ui-toolllama
ToolBench 项目和一个基于ChatBotUi的Web UI项目可以搭配使用, 以用于后端的Tools调用。
# 本地运行chatbot-ui-toolllama的步骤
git clone https://github.com/lilbillybiscuit/chatbot-ui-toolllama
cd chatbot-ui-toolllama
# 此处运行前请先通过nvm来快速安装node v18版本
npm install
npm run dev
运行之后,你能看到以下提示:
> ai-chatbot-starter@0.1.0 dev
> next dev
ready - started server on 0.0.0.0:3000, url: http://localhost:3000
Attention: Next.js now collects completely anonymous telemetry regarding usage.
This information is used to shape Next.js' roadmap and prioritize features.
You can learn more, including how to opt-out if you'd not like to participate in this anonymous program, by visiting the following URL:
https://nextjs.org/telemetry
event - compiled client and server successfully in 4.3s (273 modules)
wait - compiling...
event - compiled successfully in 302 ms (233 modules)
*注意的坑:*如果碰到以下错误信息:
showAll: args["--show-all"] ?? false,
syntaxError: Unexpected token '?'
上面的错误提示,意味着你的node环境是不是 v18版本,可以用nvm install v18来安装该环境
nvm install v18
# 根据nvm所安装的版本,把node版本切换到v18
nvm use v18.19.0
# 将v18更改为默认node版本
nvm alias default v18.19.0
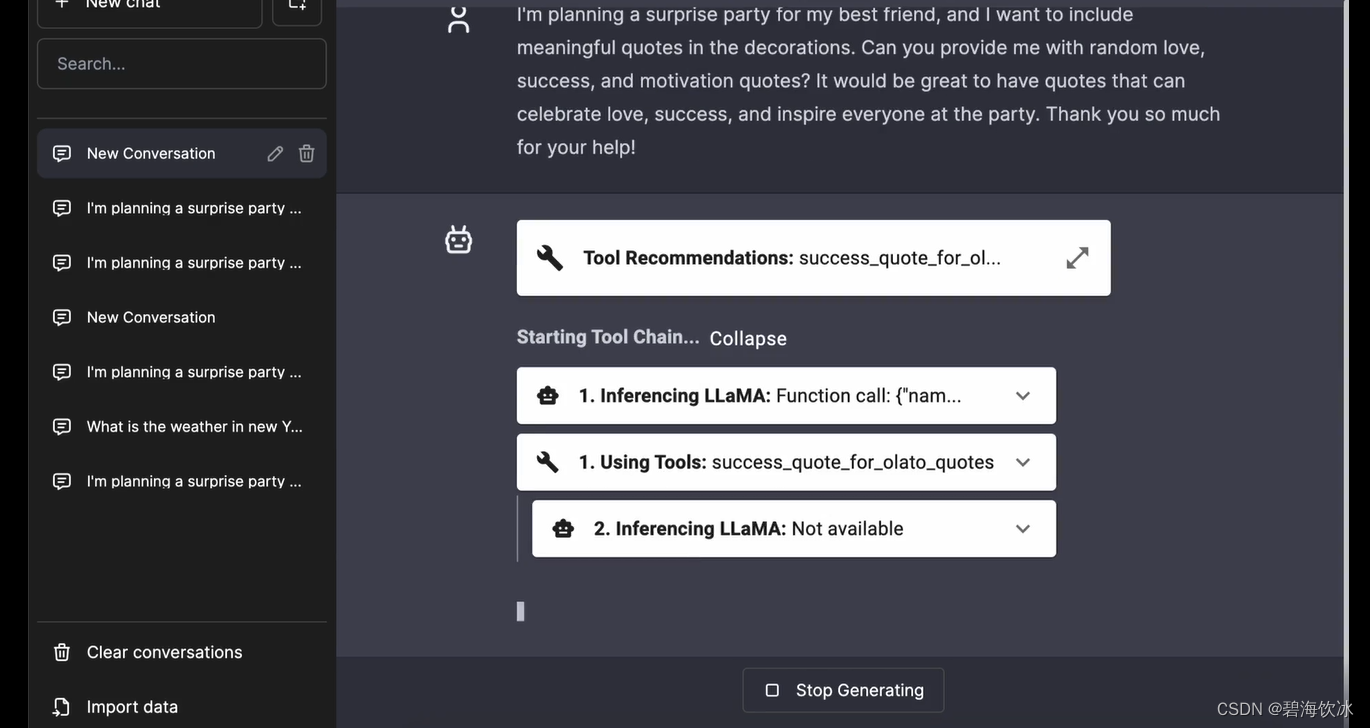
启动后,访问http://localhost:3000就能打开一个类似chatgpt的聊天页面,和下面这个应该相似(借官网的一用)。这是部署了ToolbenchLLaMA的应答效果,但那个model实在是大,暂时手上没有闲置的GPU机器,自己改造了后台GPT直连,只是将python单应用跑通,了解下这个项目的应用潜力和设计思路,本人尚未将server的gpt模式和前台的联动代码调通,有兴趣的同学可以继续尝试哈。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!