WeNet语音识别分词制作词云图
2023-12-27 11:32:26
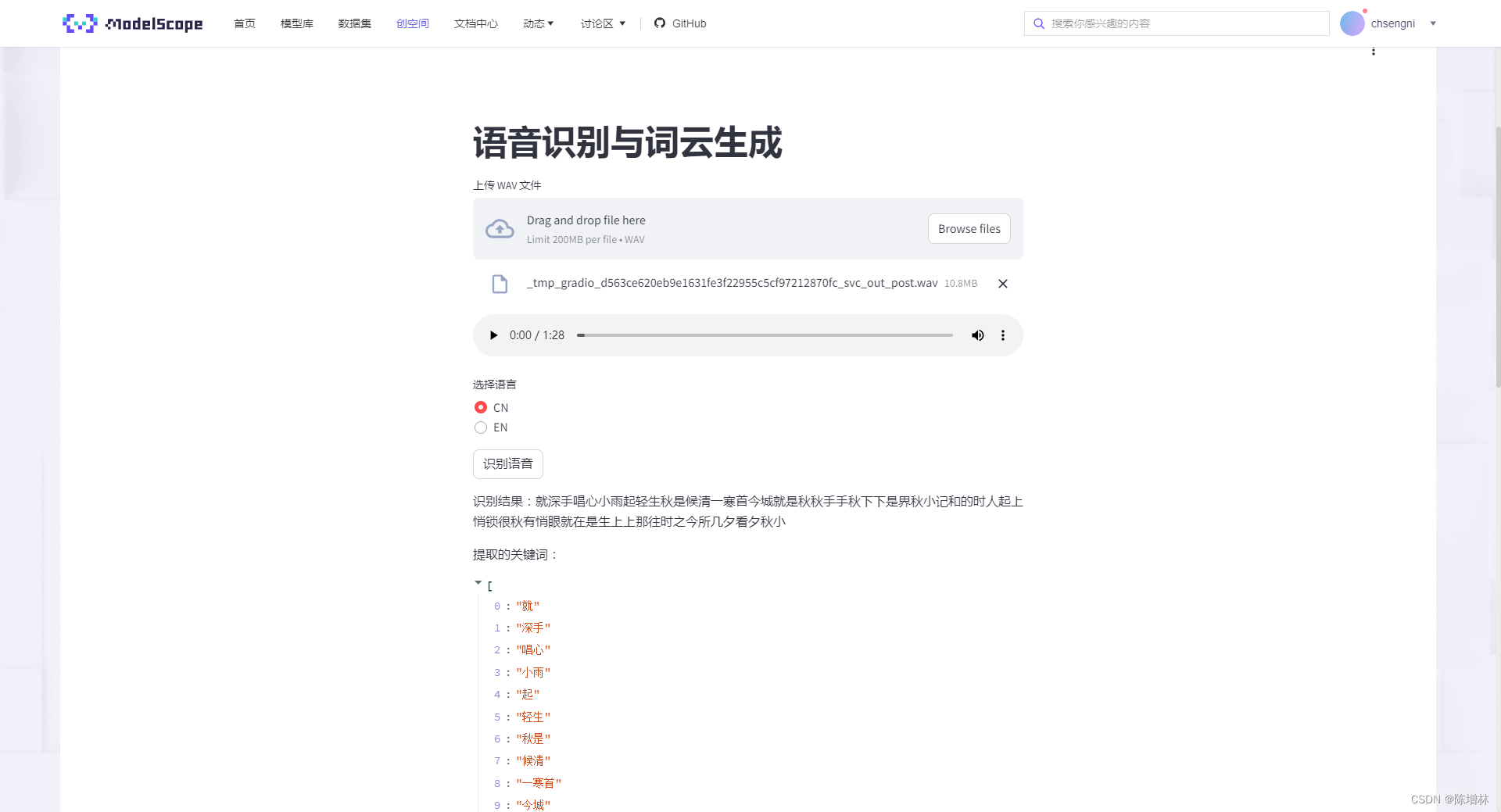
在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错
 —
—
介绍
本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代码示例中的不同部分,并解释其如何实现音频处理、语音识别和文本可视化等功能。
代码概览
首先,让我们来看一下这个应用的主要功能和组成部分:
-
导入必要的库和模型加载
import streamlit as st import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from pydub import AudioSegment from noisereduce import reduce_noise import wenet import base64 import os在这一部分,我们导入了必要的 Python 库,包括 Streamlit、jieba(用于中文分词)、WordCloud(用于生成词云)、matplotlib(用于图表绘制)、pydub(用于音频处理)等。同时,我们还加载了 wenet 库,该库包含用于中英文语音识别的预训练模型。
-
语音识别的函数定义
def recognition(audio, lang='CN'): # 识别语音内容并返回文本 # ...这个函数利用 wenet 库中的预训练模型,根据上传的音频文件进行语音识别。根据用户选择的语言(中文或英文),函数返回识别出的文本。
-
音频处理函数定义
def reduce_noise_and_export(input_file, output_file): # 降噪并导出处理后的音频文件 # ...这个函数对上传的音频文件进行降噪处理,并导出处理后的音频文件,以提高语音识别的准确性。
-
关键词提取函数定义
def extract_keywords(result): # 提取识别文本中的关键词 # ...此函数使用 jieba 库对识别出的文本进行分词,并返回关键词列表。
-
Base64 编码和下载链接函数定义
def save_base64(uploaded_file): # 将上传文件转换为 Base64 编码 # ... def get_base64_link(file_path, link_text): # 生成下载处理后音频的 Base64 链接 # ...这两个函数分别用于将上传的音频文件转换为 Base64 编码,并生成可下载处理后音频的链接。
-
主函数
main()def main(): # Streamlit 应用的主要部分 # ...主函数包含了 Streamlit 应用程序的主要逻辑,包括文件上传、语言选择、按钮触发的操作等。
-
运行主函数
if __name__ == "__main__": main()此部分代码确保主函数在运行时被调用。
应用程序功能
通过上述功能模块的组合,这个应用程序可以完成以下任务:
- 用户上传 WAV 格式的音频文件。
- 选择要进行的语言识别类型(中文或英文)。
- 降噪并处理上传的音频文件,以提高识别准确性。
- 对处理后的音频进行语音识别,返回识别结果。
- 从识别结果中提取关键词,并将其显示为词云图。
- 提供处理后音频的下载链接,方便用户获取处理后的音频文件。
希望这篇博客能够帮助你理解代码示例的每个部分,并激发你探索更多有趣应用的灵感!
streamlit应用程序
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')
# 执行语音识别的函数
def recognition(audio, lang='CN'):
if audio is None:
return "输入错误!请上传音频文件!"
if lang == 'CN':
ans = chs_model.transcribe(audio)
elif lang == 'EN':
ans = en_model.transcribe(audio)
else:
return "错误!请选择语言!"
if ans is None:
return "错误!没有文本输出!请重试!"
txt = ans['text']
return txt
# 降噪并导出处理后的音频的函数
def reduce_noise_and_export(input_file, output_file):
try:
audio = AudioSegment.from_wav(input_file)
audio_array = audio.get_array_of_samples()
reduced_noise = reduce_noise(audio_array, audio.frame_rate)
reduced_audio = AudioSegment(
reduced_noise.tobytes(),
frame_rate=audio.frame_rate,
sample_width=audio.sample_width,
channels=audio.channels
)
reduced_audio.export(output_file, format="wav")
return output_file
except Exception as e:
return f"发生错误:{str(e)}"
def extract_keywords(result):
word_list = jieba.lcut(result)
return word_list
def save_base64(uploaded_file):
with open(uploaded_file, "rb") as file:
audio_content = file.read()
encoded = base64.b64encode(audio_content).decode('utf-8')
return encoded
def main():
st.title("语音识别与词云生成")
uploaded_file = st.file_uploader("上传 WAV 文件", type="wav")
if uploaded_file:
st.audio(uploaded_file, format='audio/wav')
language_choice = st.radio("选择语言", ('CN', 'EN'))
bu=st.button("识别语音")
if bu:
if uploaded_file:
output_audio_path = os.path.basename(uploaded_file.name)
processed_audio_path = reduce_noise_and_export(uploaded_file, output_audio_path)
if not processed_audio_path.startswith("发生错误"):
result = recognition(processed_audio_path, language_choice)
st.write("识别结果:" + result)
keywords = extract_keywords(result)
st.write("提取的关键词:", keywords)
text = " ".join(keywords)
wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())
st.image(wc.to_array(), caption='词云')
# 提供处理后音频的下载链接
st.markdown(get_base64_link(processed_audio_path, '下载降噪音频'), unsafe_allow_html=True)
else:
st.warning("请上传文件")
def get_base64_link(file_path, link_text):
with open(file_path, "rb") as file:
audio_content = file.read()
encoded = base64.b64encode(audio_content).decode('utf-8')
href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'
return href
if __name__ == "__main__":
main()
requirements.txt
wenet @ git+https://github.com/wenet-e2e/wenet
streamlit
wordcloud
pydub
jieba
noisereduce

文章来源:https://blog.csdn.net/qq_37655607/article/details/135239025
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!