联邦学习新探:端边云协同引领大模型训练的未来 | INFOCOM 2024
联邦学习新探:端边云协同引领大模型训练的未来 | INFOCOM 2024
在人工智能领域,无论是从理论还是实践的角度,如何在保护用户隐私和数据安全的前提下,提高模型训练的效率和质量,都是一个重要的研究焦点。联邦学习(Federated Learning)就是一种能够在不损害用户隐私的前提下,训练人工智能模型的技术。随着云计算、边缘计算和终端设备的发展,端边云协同(End-Edge-Cloud Collaboration)计算范式的出现,为联邦学习算法的实施与部署提供了新的路径。由中国科学院计算技术研究所、中国科学院大学、中关村实验室和北京交通大学的研究团队共同完成的论文 “Agglomerative Federated Learning: Empowering Larger Model Training via End-Edge-Cloud Collaboration”,在INFOCOM 2024上提供了一个全新的视角,引领我们进入了联邦学习和端边云协同的新纪元。
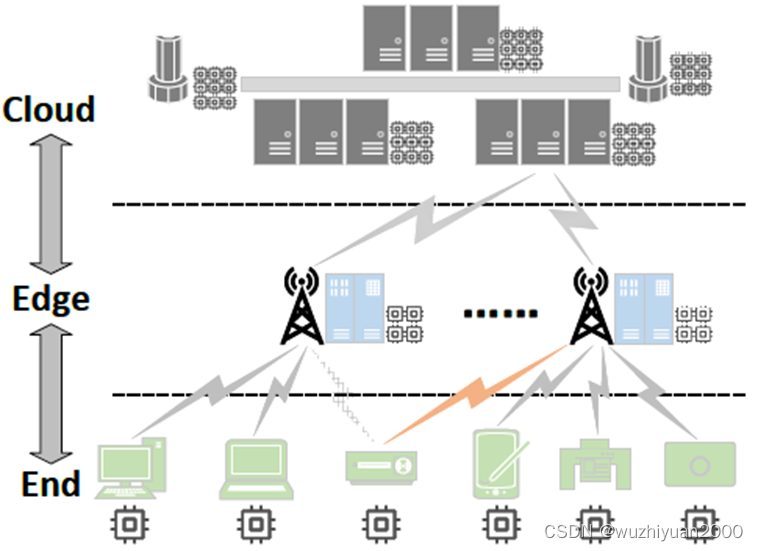
端边云协同是一种新兴的计算范式,它借助远端云数据处理中心、近端边缘服务器和终端设备的分布式算力,提供了一个高效、灵活和可扩展的计算框架。在端边云协同的架构下,云服务器、边缘服务器和终端设备能够充分发挥其各自的优势。云服务器有强大的计算能力,适合处理大规模的数据处理和模型训练任务;边缘服务器靠近用户,可以处理时效性强、对延迟敏感的任务;终端设备则可以在保护用户隐私的前提下,利用丰富的用户数据进行本地化的模型训练和优化。在这种模式下,云服务器、边缘服务器和终端设备可以在不同的计算层级之间进行协作,共同承担计算任务,提高整体的计算效率。在这个背景下,作者探索了如何通过端边云协同来帮助联邦学习处理更大模型的训练任务。
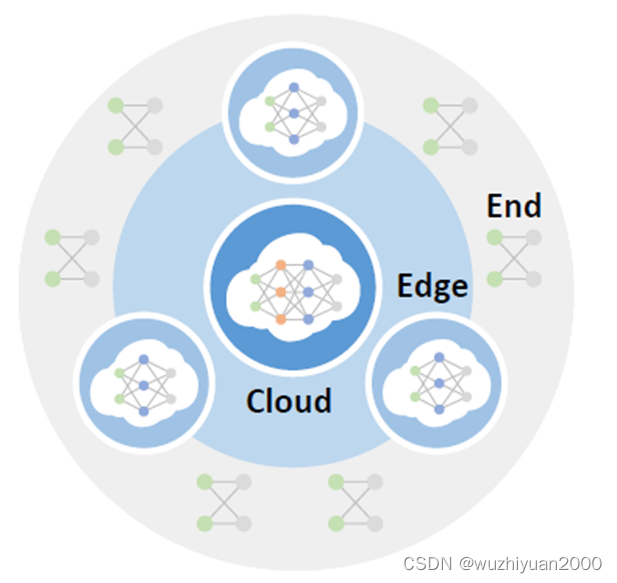
本文作者提出了凝聚联邦学习(Agglomerative Federated Learning)框架,该框架通过桥接样本在线蒸馏协议(Bridge Sample Based Online Distillation Protocol),递归地组织树状拓扑的端边云算力网,实现了端边云之间每对父子节点的模型无关(Model Agnostic)的协同训练。具体来说,低层级节点先用一个轻量级编码器对本地数据进行编码,再上传编码到上级节点;上级节点用一个预训练好的解码器对编码生成伪样本。不同层级节点之间的模型在这些伪样本上进行在线蒸馏,逐层向上传递知识。这样,不同层节点可以根据本地算力资源训练大小合适的模型,而云端集成所有知识后可以训练规模显著超过端侧设备承载能力的模型。
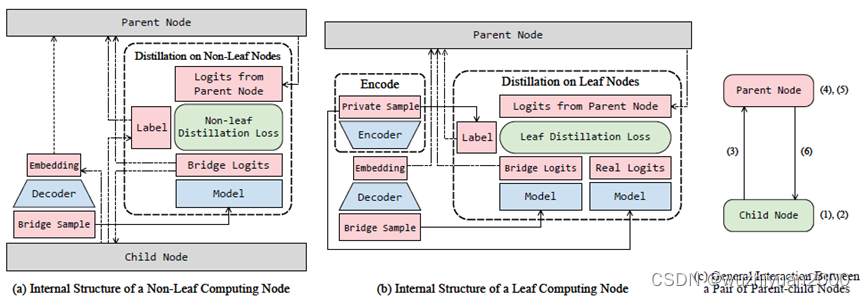
此外,本文作者还证明了该框架在端边云算力网中的灵活性,即每一个非根节点算力节点均可在同一层级随意切换接入的父节点,这为算力网中单点宕机修复、负载均衡等操作提供了空间。
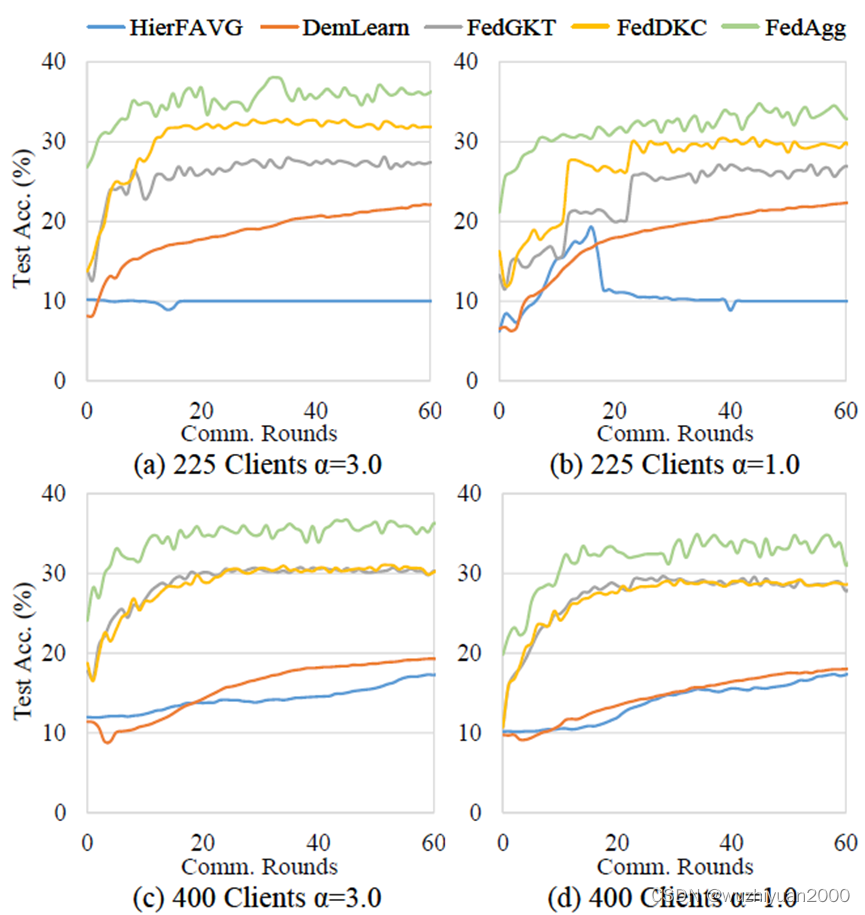
实验结果表明,相比现有框架,凝聚联邦学习可以带来模型精度和收敛性的显著提升。

论文地址:https://www.techrxiv.org/users/691165/articles/692087-agglomerative-federated-learning-empowering-larger-model-training-via-end-edge-cloud-collaboration
代码链接:https://github.com/wuzhiyuan2000/FedAgg
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!