MIMIC云数据库安装及使用
一、MIMIC-IV数据库介绍
1.1 MIMIC IV数据库简介
MIMIC数据库就是一个可为临床研究者提供临床数据的利器。
该数据库于2003年在美国国立卫生研究院的资助下,由美国麻省理工学院计算生理学实验室、美国哈佛医学院贝斯以色列女执事医疗中心(Beth Israel Deaconess Medical Center,BIDMC)和飞利浦医疗公司共同建立。
研究者可根据一定的纳排标准筛选感兴趣患者的临床信息,利用这些信息可进行后续的数据分析然后撰写文章,通过数据收集与分析可作为发表sci论文的重要依据。另外,MIMIC是一个公开数据库,所有患者的信息都经过脱敏处理,发文不需要临床伦理审查。
以下各类疾病都有涉及:

1.2 数据库样本量
MIMIC 数据库目前已经产生了MIMIC Ⅱ、Ⅲ、Ⅳ三个版本。MIMIC数据库包含了BIDMC所有内外科ICU患者的数据,数据团队为保护患者隐私,对患者信息进行去标识化处理,向全世界的研究人员免费开放。
- MIMIC Ⅲ数据库收集了BIDMC 2001年6月至2012年10月ICU收治的53423例成年患者数据和2001年至2008年收治的7870例新生儿重症患者数据。
- MIMIC Ⅳ数据库在MIMIC Ⅲ的基础上做了一些改进,包括数据更新和部分表格重构,收集了 2008至2019年BIDMC收治的超过19万名患者、45万次住院记录的临床数据。数据库记录了患者的人口统计学信息、实验室检查、用药情况、生命体征、手术操作、疾病诊断、药物管理、随访生存状态等详细信息。
MIMIC Ⅳ数据库主要有三类数据:
- 第一类是从EHR中提取的临床数据,包括患者的人口统计学、疾病诊断、实验室检测、药物治疗、生命体征等。
- 第二类是ICU床旁监护设备采集的波形数据、生命体征、液体管理和事件记录,主要来自于IMDSoft MetaVision系统。
- 第三类是死亡随访数据,通过社会保险系统得到患者院外死亡的日期,作为MIMIC 数据库的组成部分,这部分数据对研究患者的预后很重要。
1.3 基本字段表述
患者入院信息, 以每次入院为单位记录, 每条记录有一个单独的hadm_id, hospital_expire_flag只当次住院是否院内死亡, 部分院内死亡患者没有deathtime, 可能是数据库本身问题
病人定义:
- subject_id:每个患者有唯一的subject_id
- hadm_id:患者的每一次入院会有一个唯一的hadm_id
- transfer_id:患者每一次更换病房会有一个唯一的transfer_id
- stay_id:在相同类型病房内进行转移,则会更新一个transfer_id,但会有相同的stay_id,例如用ICU中的一个病房转移到另一个病房,则stay_id不变,transfer_id更新。所有id的分配都是随机的,与时间先后无关。
date and time:后缀为date的,分辨率最低为天;后缀为timed的字段,分辨率最低为分钟。 - charttime and storetime:分别是测量的记录时间与储存时间。通常以charttime为准
d and icd 命名为d_开头,为编码表。d_icd开头,为icd编码表。icd结尾的表,为使用icd编码的记录表。
1.4 MIMIC-IV数据表说明
分为六个模块,Core、Hosp、ICU、ED、CXR、Note
Core
Core模块包含患者跟踪数据。这里描述了人口统计、入院信息和住院病房转院情况
- admission:患者入院信息,以每次入院为单位记录,每条记录有一个单独的hadm_id
- patient:患者信息
- transfers:病房转移信息
Hosp
Hosp模块涵盖的信息包括实验室测量,微生物学,药物管理,和收费诊断等

ICU
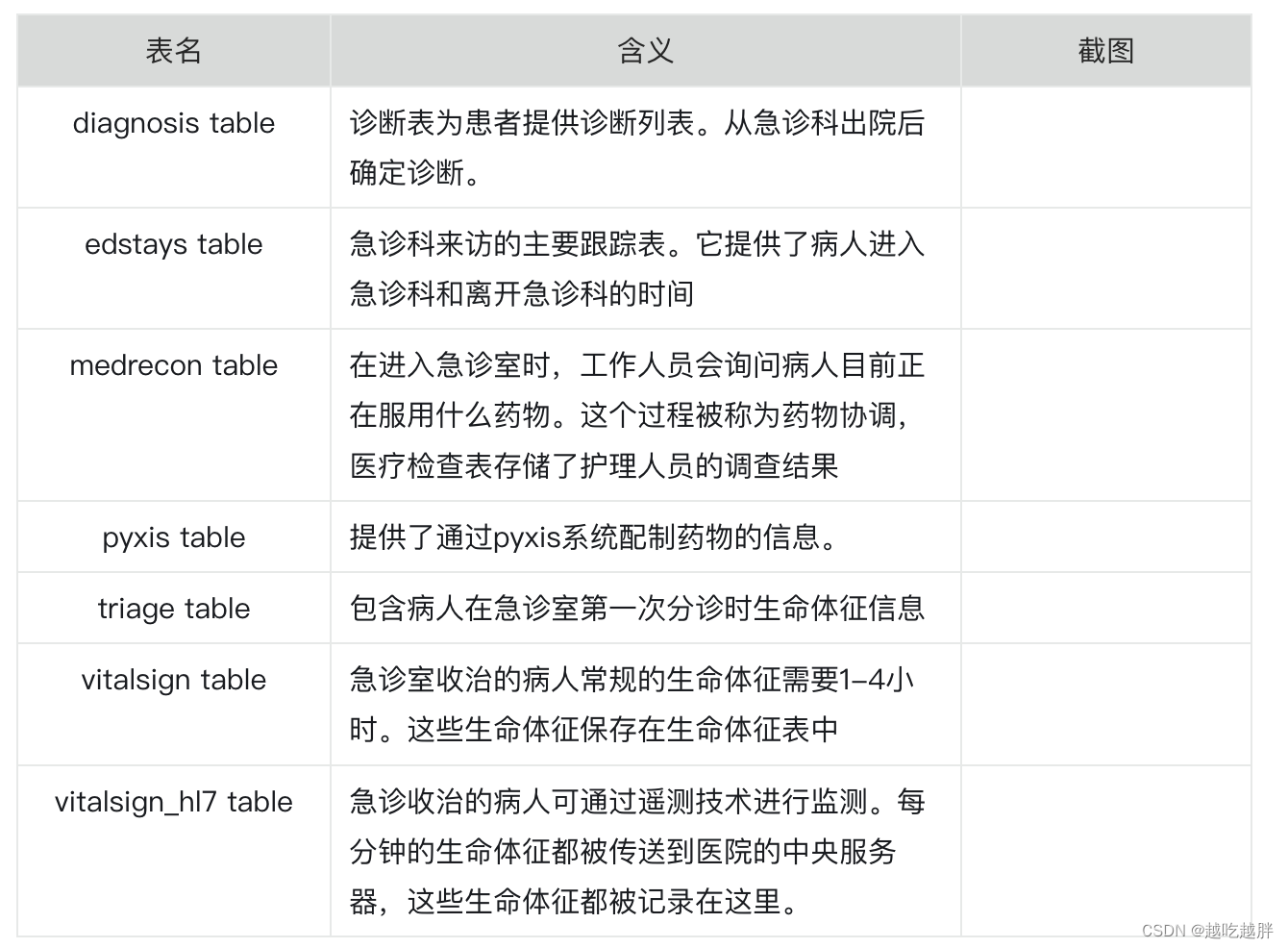
ED
官方链接:https://physionet.org/content/mimic-iv-ed/2.2/
文件大小:116.3 MB
官方介绍:MIMIC-IV-ED是贝斯以色列女执事医疗中心2011年至2019年期间急诊科(ED)入院情况的大型免费数据库。该数据库包含约425,000个ED停留。生命体征,分诊信息,药物调解,药物管理和出院诊断是可用的。所有数据都符合健康信息可携带性和责任法案(HIPAA)安全港规定。MIMIC-IV-ED旨在支持各种教育活动和研究。
内容介绍:急诊信息,包含急诊诊断,病人体征等信息。通过subject_id和hadm_id与其他模块相连接。急诊的患者如有hadm_id,则说明该患者住院治疗。ed患者不一定住院,住院的患者也不一定从急诊入院。
CXR
官方链接:https://physionet.org/content/mimic-cxr/2.0.0/
文件大小:4.6 TB
官方介绍:MIMIC胸部x射线(MIMIC- cxr)数据库v2.0.0是DICOM格式的大型公开胸片数据集,具有自由文本放射学报告。该数据集包含377,110张图像,对应于马萨诸塞州波士顿Beth Israel Deaconess医疗中心进行的227,835项放射学研究。为了满足1996年美国健康保险流通与责任法案(HIPAA)的安全港要求,该数据集被去识别化。已删除受保护的健康信息(PHI)。该数据集旨在支持医学领域的广泛研究,包括图像理解、自然语言处理和决策支持。
包含内容:X光胸片文件,源数据是dicom格式,但也提供了jpg格式的下载。包含了胸片及影像学报告。值得注意的是,存在有影像的患者没有住院记录的情况。
- cxr-record-list:影像列表
- cxr-study-list:影响报告列表
- mimic-cxr-2.0.0-chexpert:使用CheXpert labeler(基于影像学报告的非人工标注,斯坦福与麻省理工合作)标注了14个标签,标签如下表
- mimic-cxr-2.0.0-split:提供了参考的训练集、验证集、测试集划分
Note
官方链接:https://physionet.org/content/mimic-iv-note/2.2/
文件大小:1.8GB
官方介绍:大型开放访问文本数据库的出现推动了自然语言处理(NLP)中最先进的模型性能的进步。可用于NLP的临床数据相对有限,这被认为是该领域发展的一个重大障碍。在这里,我们描述了MIMIC-IV- note:在MIMIC-IV临床数据库中包含的患者的去识别的自由文本临床笔记的集合。MIMIC-IV-Note包含来自美国马萨诸塞州波士顿贝斯以色列女执事医疗中心医院和急诊科收治的145,915名患者的331,794份未确定的出院摘要。该数据库还包含237,427名患者的2,321,355份未确定的放射学报告。根据《健康保险流通与责任法案》(HIPAA)的安全港规定,所有注释都删除了受保护的健康信息。所有笔记都可链接到MIMIC-IV,为其中的临床数据提供重要的背景。该数据库旨在促进临床自然语言处理和相关领域的研究。
二、云数据库准备与使用
官方参考安装地址:https://github.com/MIT-LCP/mimic-code
2.1 云数据库介绍与使用
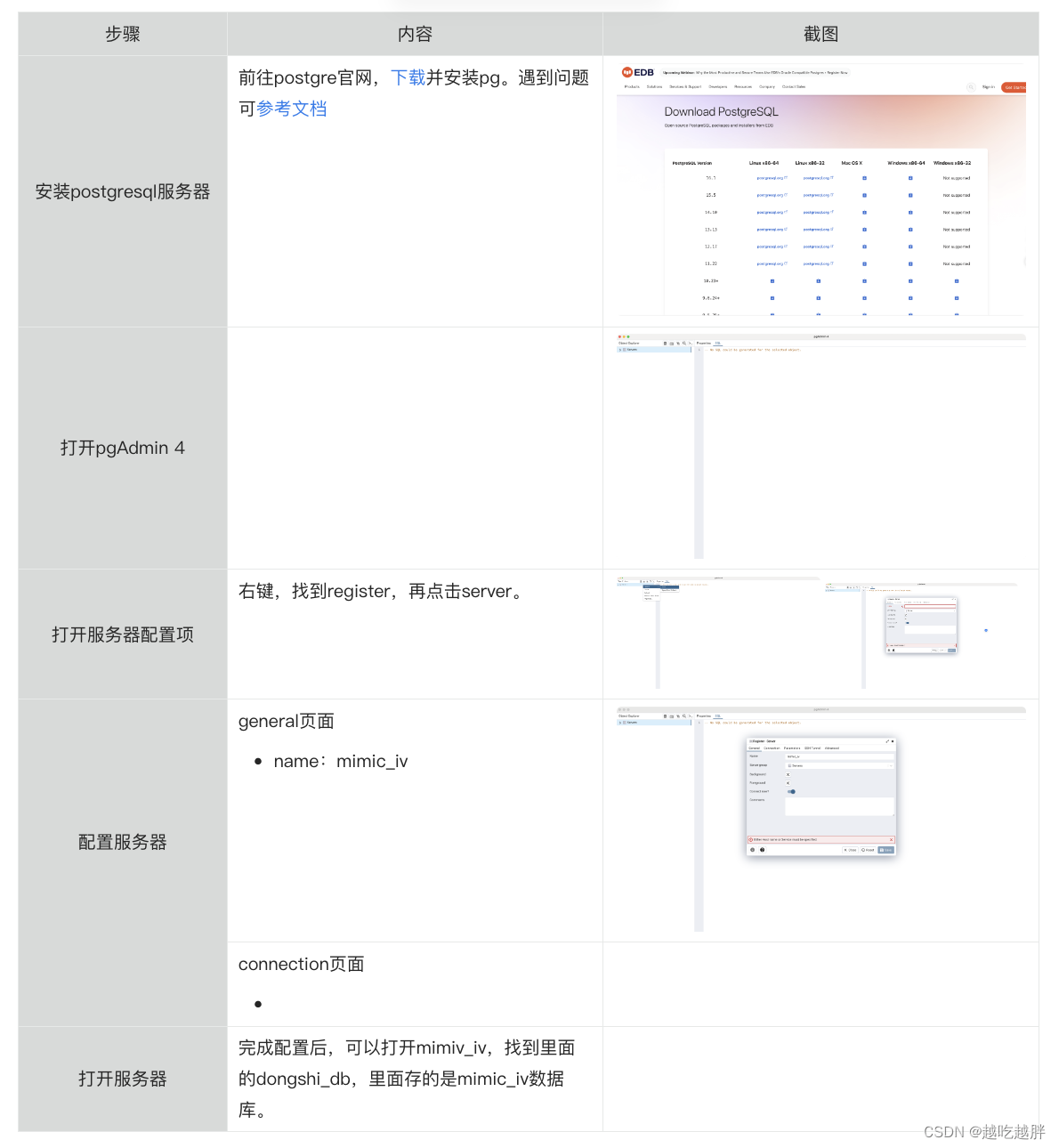
基于阿里云hologres进行mimic数据库组装,该数据库具有强大的性能和计算速度。
依次遵循一下步骤可以完成配置
2.2 数据准备
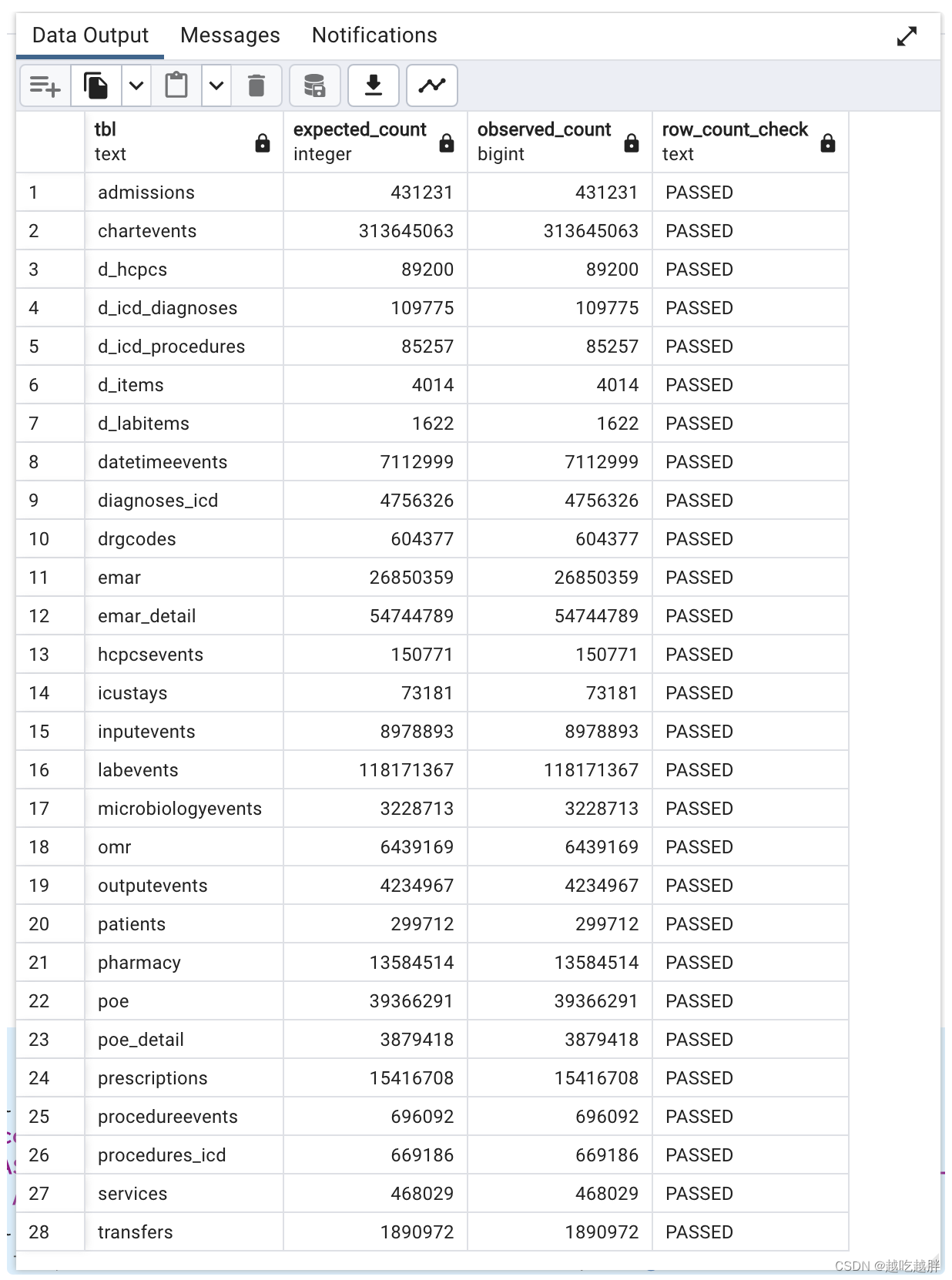
MIMIC-IV
包含内容:mimiciv_hosp、mimiciv_icu
参考地址:https://github.com/MIT-LCP/mimic-code/blob/main/mimic-iv/buildmimic/postgres/validate.sql
数据验证:
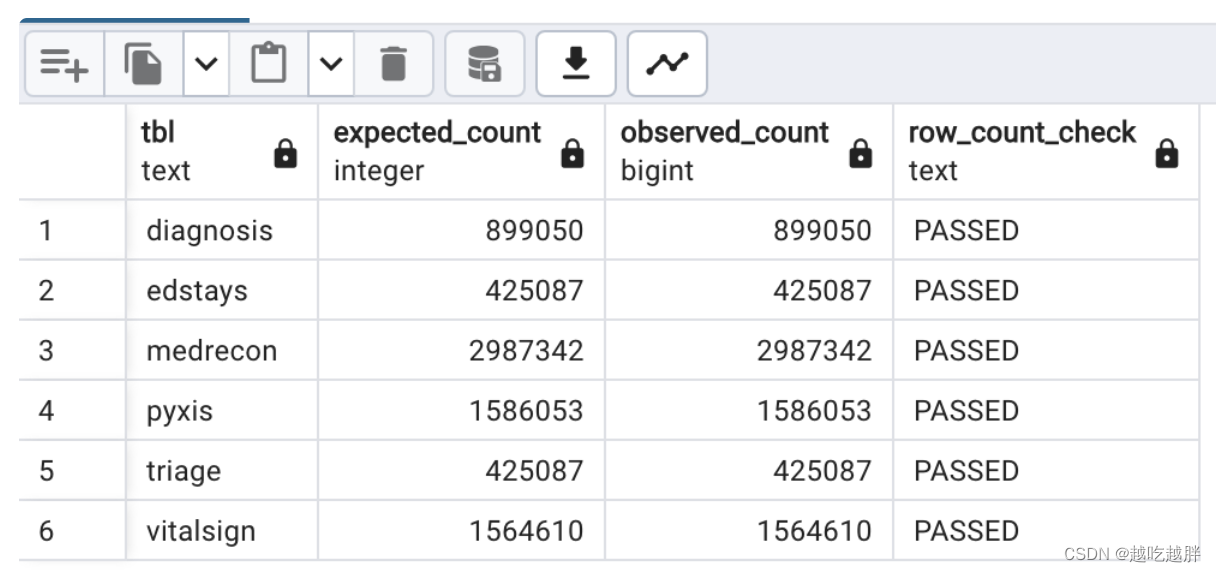
MIMIC-IV-ED
包含内容:mimiciv_ed
参考地址:https://github.com/MIT-LCP/mimic-code/blob/main/mimic-iv-ed/buildmimic/postgres/validate.sql
数据验证:
MIMIC-IV-NOTE
包含内容:mimiciv_note
参考地址:
数据验证:

附件
附件1:【code】大文件数据拆分导入
为了避免耽搁大文件压垮内存
import os
def split_csv_file(source_file, target_path, batch_num, is_header=True):
# 打开源文件
with open(source_file, 'r') as f:
header = f.readline()
# 分批读取文件并切分
batch_count = 0
while True:
lines = [header] if is_header else []
for _ in range(batch_num):
line = f.readline()
if not line:
break
lines.append(line)
if len(lines) == 0 and is_header == False:
break
if len(lines) == 1 and is_header == True:
break
# 写入切分后的文件
with open(os.path.join(target_path, f"batch_{batch_count}.csv"), 'w') as batch_file:
batch_file.writelines(lines)
print(f'{batch_count}: {os.path.join(target_path, f"batch_{batch_count}.csv")}')
batch_count += 1
#使用示例
source_file = "/Users/jinzhang/Documents/mimic-iv-2.2/icu/chartevents.csv"
target_path = "/Users/jinzhang/Documents/mimic-iv-2.2/icu/split"
batch_num = 5000000
is_header = True
split_csv_file(source_file, target_path, batch_num, is_header)
附件2:【code】数据上传
\copy mimiciv_icu.chartevents FROM '/Users/jinzhang/Documents/mimic-iv-2.2/icu/split/batch_10.csv' DELIMITER ',' CSV HEADER NULL '' ENCODING 'UTF8';
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!