SpringBoot 2 集成Spark 3
2023-12-25 15:42:49
前提条件:
运行环境:Hadoop? 3.* + Spark 3.* ,如果还未安装相关环境,请参考:
SpringBoot 2 集成Spark 3
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>SpringBootCase</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>SpringBoot-Spark3</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.0</version>
<exclusions>
<exclusion>
<artifactId>netty-all</artifactId>
<groupId>io.netty</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.58.Final</version>
</dependency>
</dependencies>
</project>配置application.properties
无
核心代码
package cn.zzg.spark.test;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class SparkTest {
public static void main(String[] args) {
String logFile = "hdfs://192.168.43.11:9000/README.md";
SparkConf conf = new SparkConf().setAppName("Spark 应用").setMaster("spark://192.168.43.11:7077");
JavaSparkContext context = new JavaSparkContext(conf);
JavaRDD<String> data = context.textFile(logFile).cache();
long nums = data.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String s) throws Exception {
return s.contains("a");
}
}).count();
System.out.println("包含字母a总数为:" + nums);
}
}
SpringBoot 2? 集成Spark 3 遇到的问题
问题一:java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
造成此类 问题原因:本地环境没有设置 ?HADOOP_HOME 和 hadoop.home.dir 两项。
解决办法:
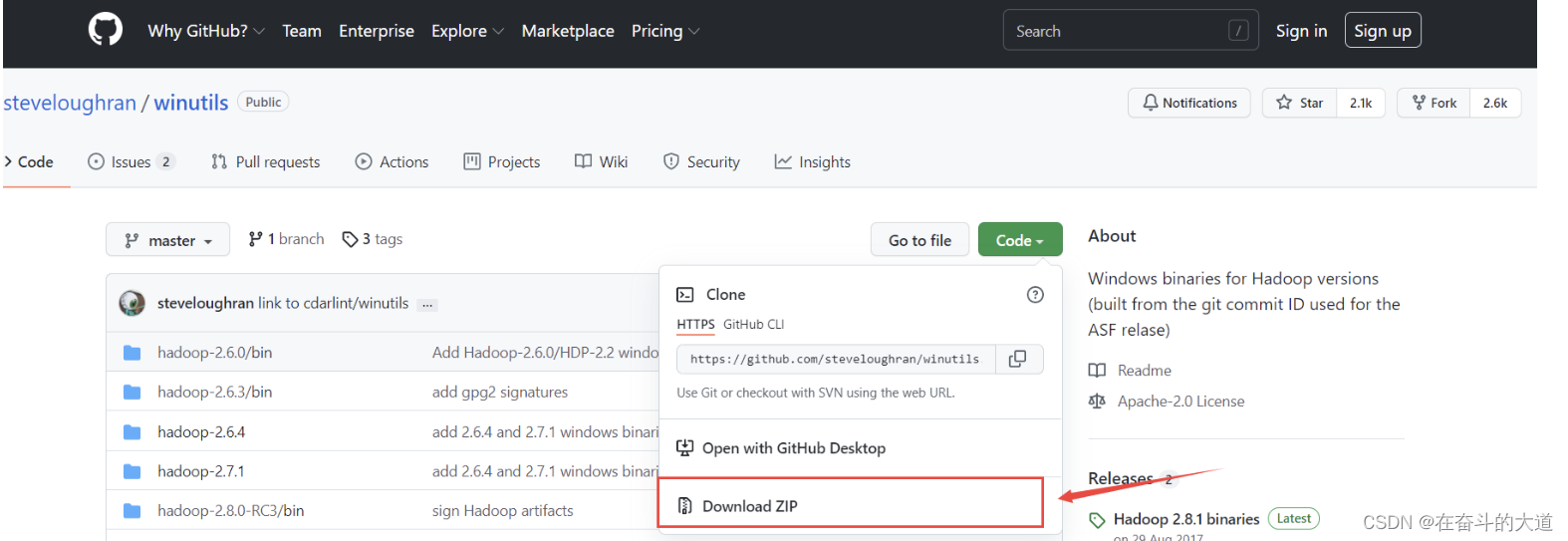
1.下载winutils文件
GitHub地址:winutils
点击绿色的Code按钮,再选择Download Zip下载
 ?
?
2.选择版本
如果没有和你版本一致的文件夹,就选择和你版本最相近的,因为我的Hadoop版本是3.2.2版本,所以我选择的是hadoop-3.0.0

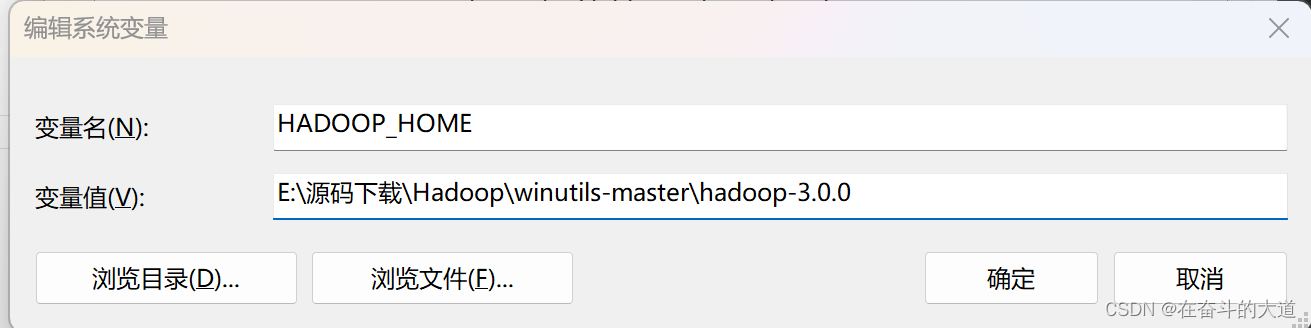
?3.配置环境变量
配置系统环境变量:
新增 变量名:HADOOP_HOME? ?变量值:就是你上面选择的hadoop版本文件夹的位置地址
??在 变量名:path 中新增 变量值:%HADOOP_HOME%\bin

?4. 把hadoop.dll放到C:/windows/system32文件夹下
拷贝bin文件夹下的hadoop.dll文件

复制进C:/windows/system32文件夹下

?6.重启IDEA,再次运行代码,成功。
问题二:java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.<init>(ZIIIIIIZ)
造成此类问题原因:spark-core 依赖的Netty 版本过低,导致相关类方法缺失。
解决办法:移除spark-core 中依赖的netty 包,重新添加netty-all? 版本。
文章来源:https://blog.csdn.net/zhouzhiwengang/article/details/135193083
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!