Python大数据之PySpark(二)PySpark安装
PySpark安装
- 1-明确PyPi库,Python Package Index 所有的Python包都从这里下载,包括pyspark

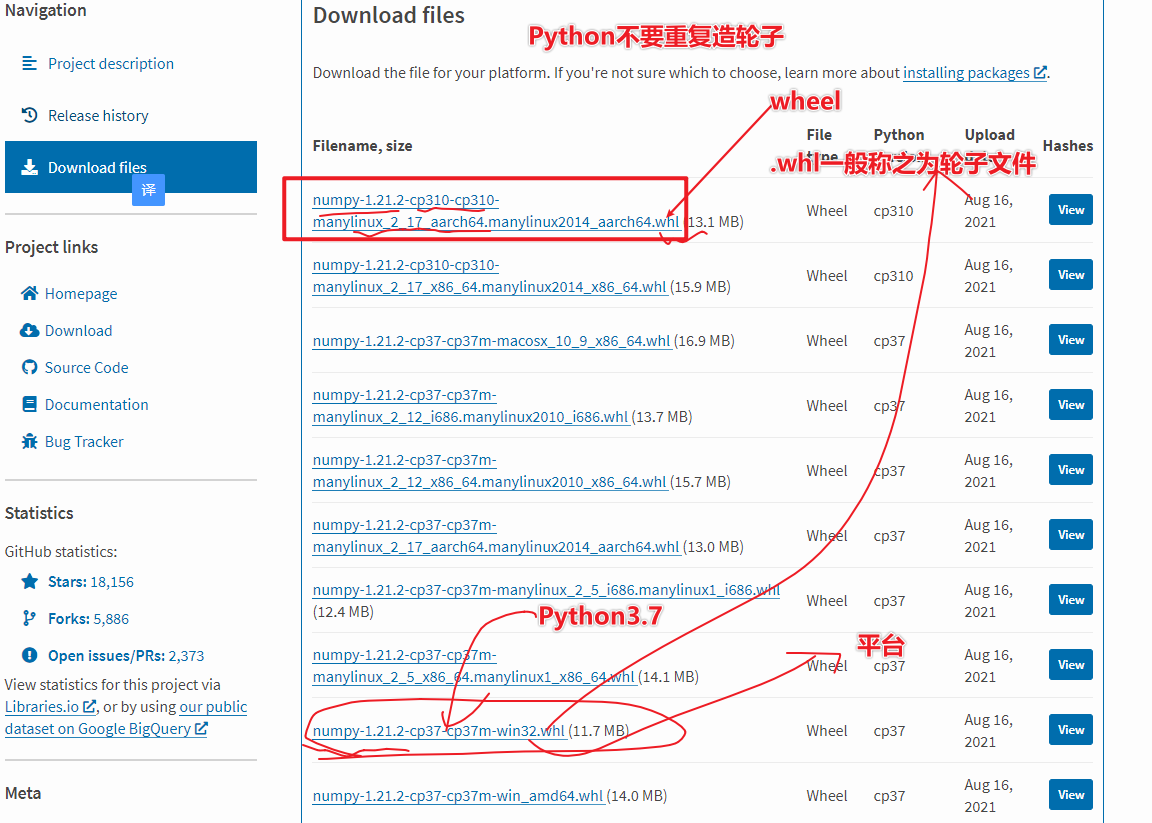
- 2-为什么PySpark逐渐成为主流?
- http://spark.apache.org/releases/spark-release-3-0-0.html
- Python is now the most widely used language on Spark. PySpark has more than 5 million monthly downloads on PyPI, the Python Package Index.
- 记住如果安装特定的版本需要使用指定版本,pip install pyspark2.4.5
- 本地安装使用pip install pyspark 默认安装最新版
PySpark Vs Spark
Python作为Spark的主流开发语言
PySpark安装
1-如何安装PySpark?
- 首先安装anconda,基于anaconda安装pyspark
- anaconda是数据科学环境,如果安装了anaconda不需要安装python了,已经集成了180多个数据科学工具
- 注意:anaconda类似于cdh,可以解决安装包的版本依赖的问题
Linux的Anaconda安装
2-如何安装anconda?
- 去anaconda的官网下载linux系统需要文件 Anaconda3-2021.05-Linux-x86_64.sh
- 上传到linux中,执行安装sh Anaconda3-2021.05-Linux-x86_64.sh或bash Anaconda3-2021.05-Linux-x86_64.sh
- 直接Enter下一步到底,完成
- 配置环境变量,参考课件
3-Anaconda有很多软件
IPython 交互式Python,比原生的Python在代码补全,关键词高亮方面都有明显优势
jupyter notebook:以Web应用启动的交互式编写代码交互式平台(web平台)
180多个工具包
conda和pip什么区别?
conda和pip都是安装python package
conda list可以展示出package的版本信息
conda 可以创建独立的沙箱环境,避免版本冲突,能够做到环境独立
conda create -n pyspark_env python==3.8.8
4-Anaconda中可以利用conda构建虚拟环境
- 这里提供了多种方式安装pyspark
- (掌握)第一种:直接安装 pip install pyspark
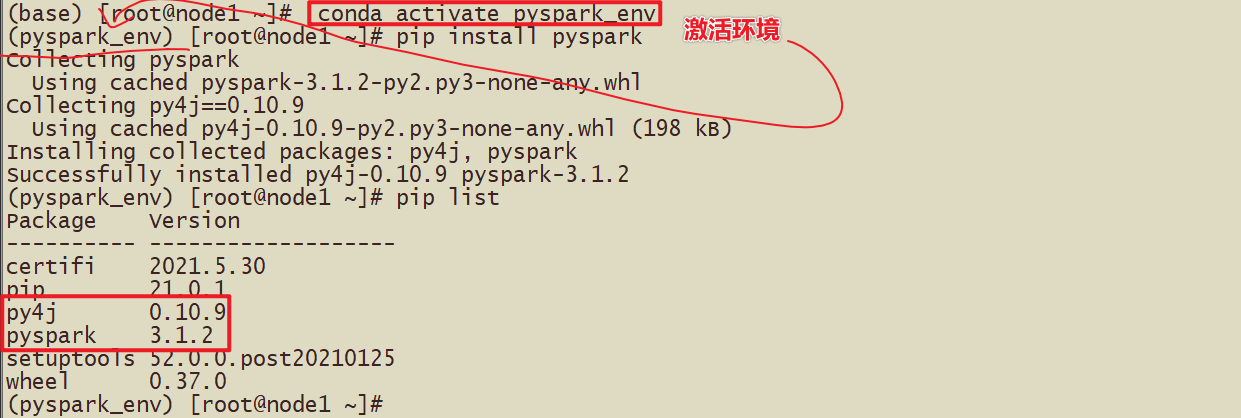
- (掌握)第二种:使用虚拟环境安装pyspark_env中安装,pip install pyspark
- 第三种:在PyPi上下载下来对应包执行安装
5-如何查看conda创建的虚拟环境?
- conda env list
- conda create -n pyspark_env python==3.8.8
- pip install pyspark
PySpark安装
- 1-使用base的环境安装
- 2-使用pyspark_env方式安装
-
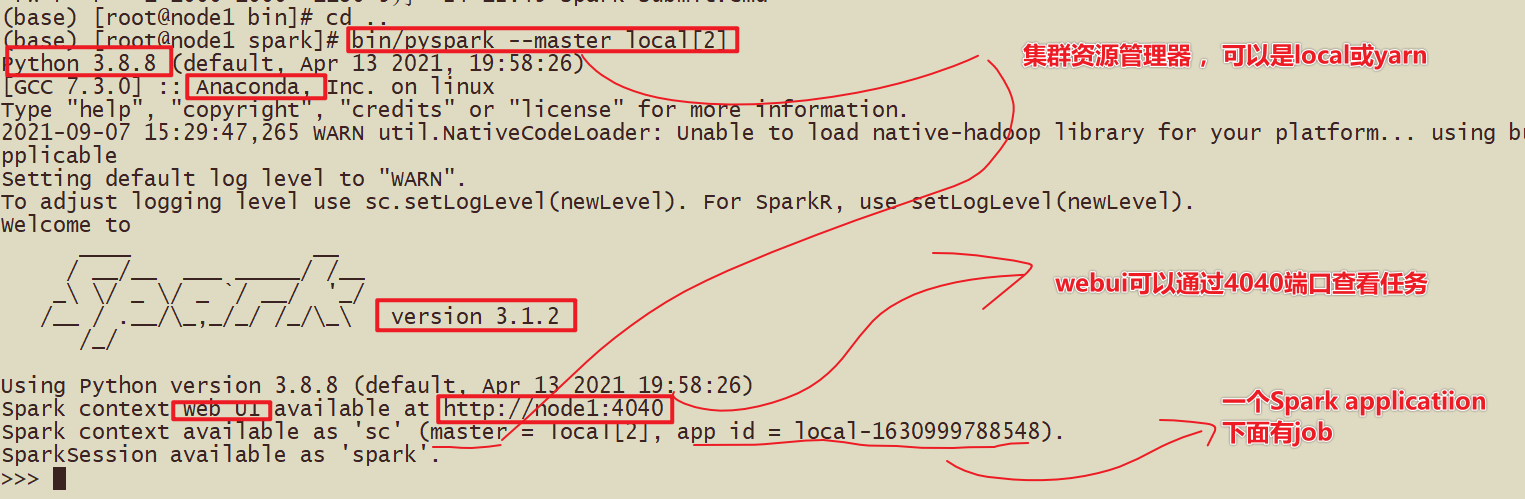
查看启动结果
-
-
简单的代码演示
-
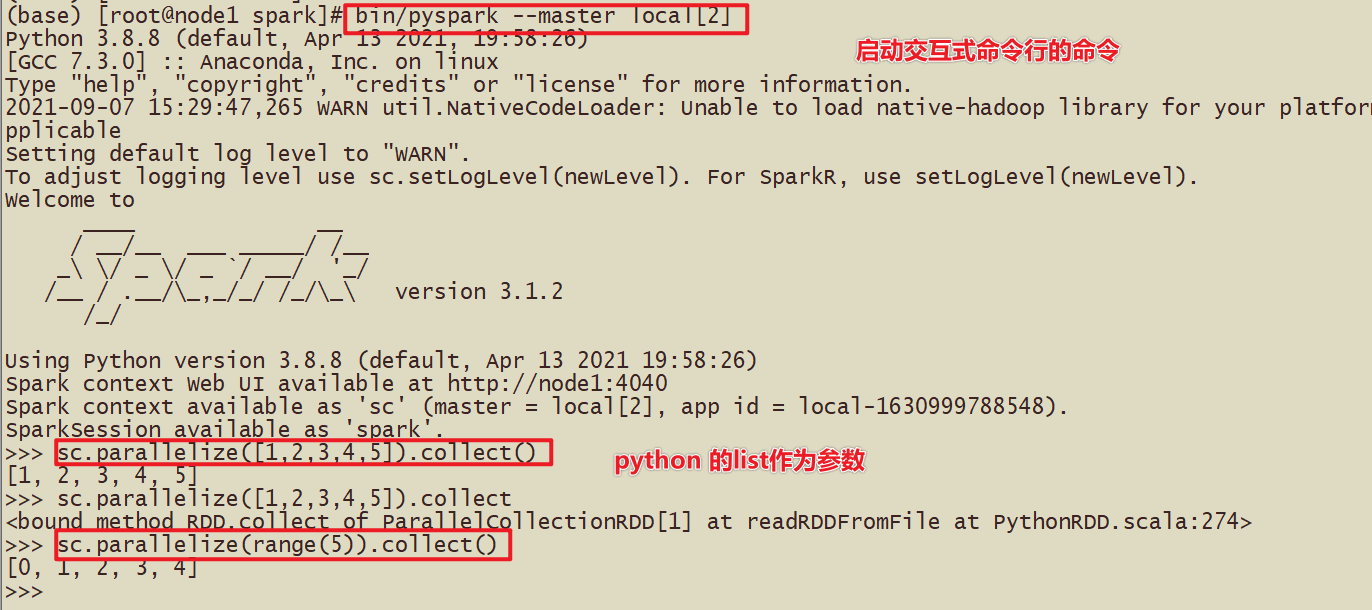
-
在虚拟环境下的补充
-
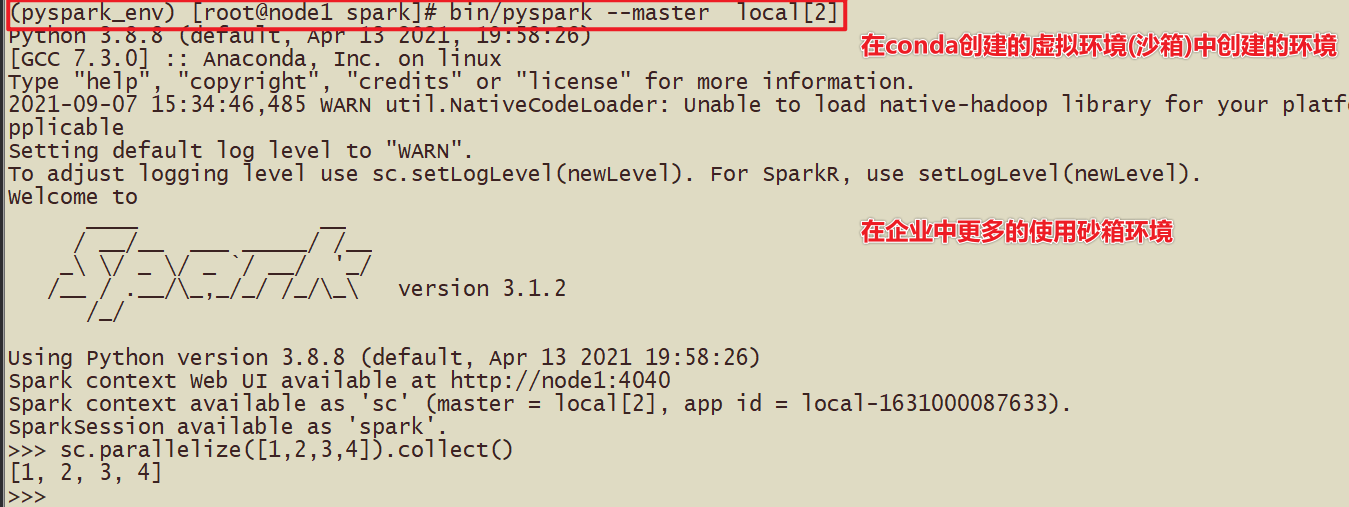
-
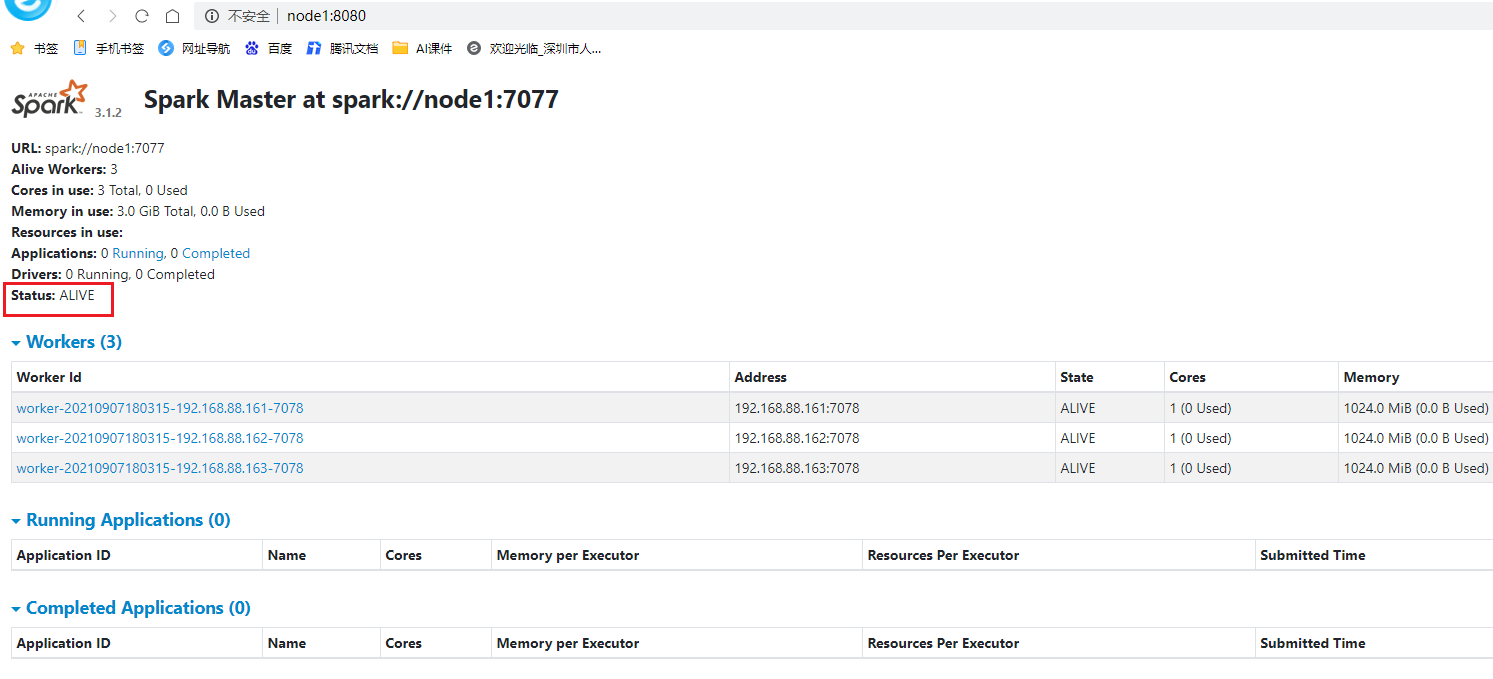
webui
-
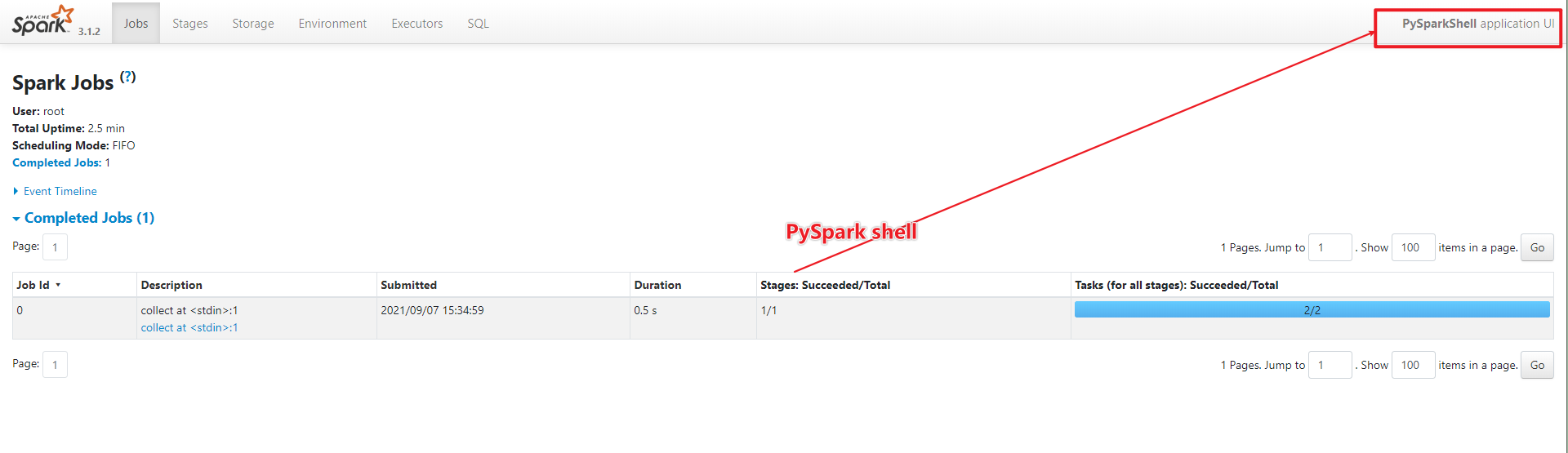
-
注意:
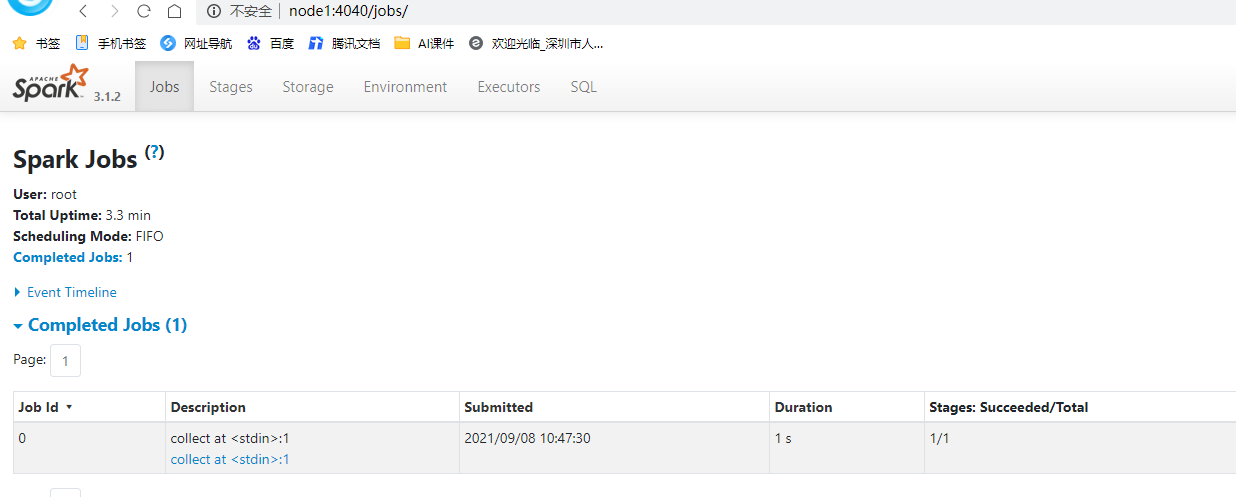
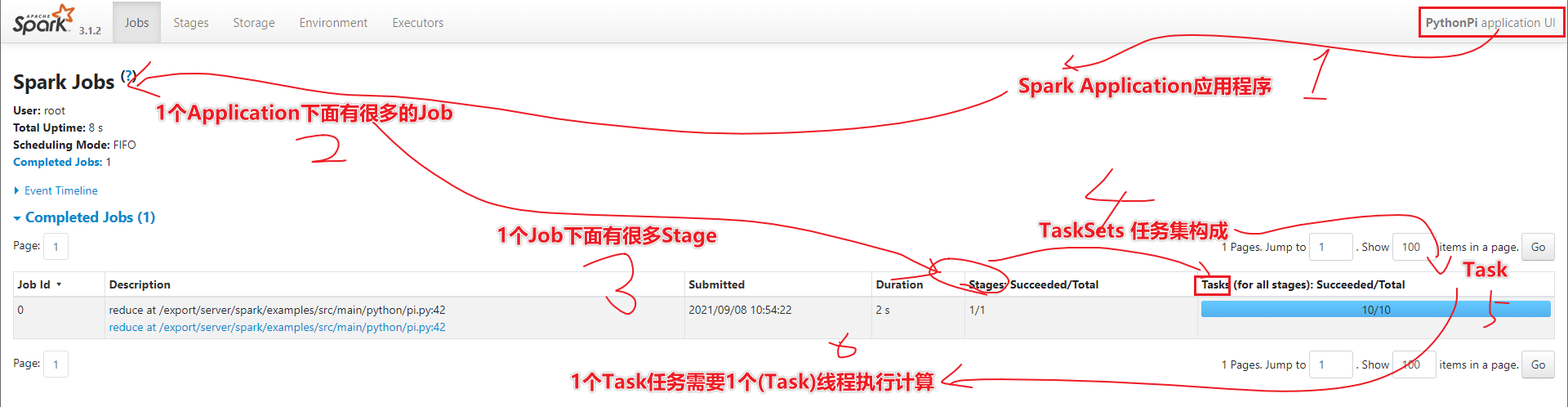
- 1-1个Spark的Applicaition下面有很多Job
- 2-1个Job下面有很多Stage
Jupyter环境设置
监控页面
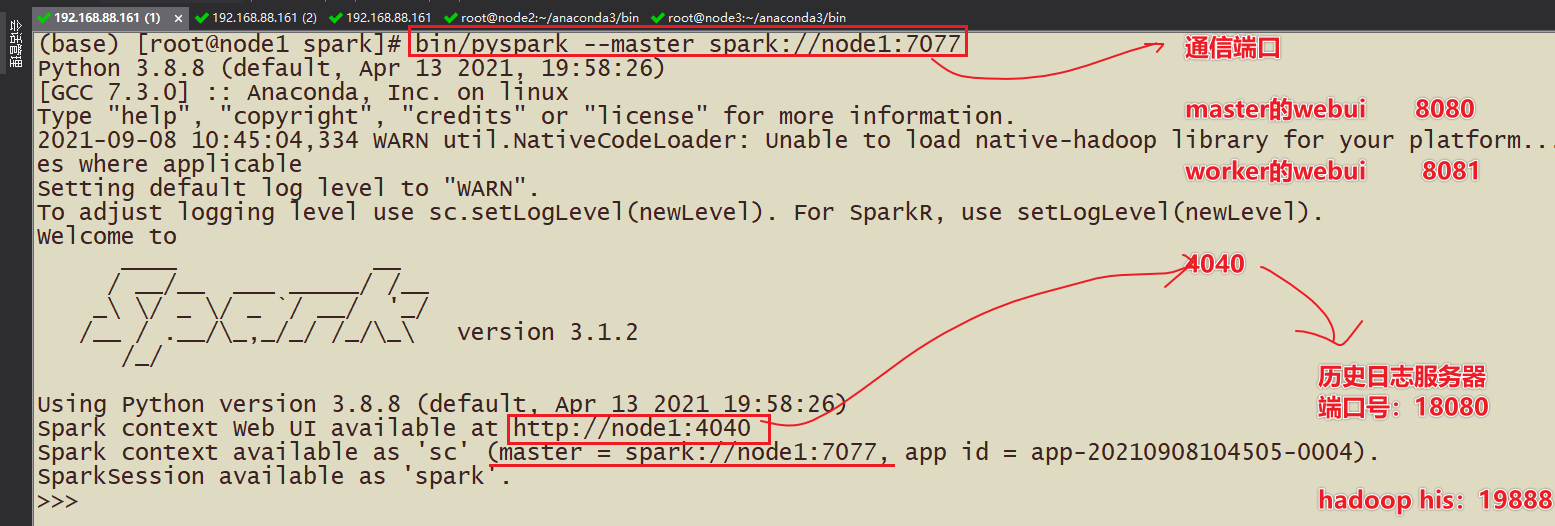
- 4040的端口

运行圆周率
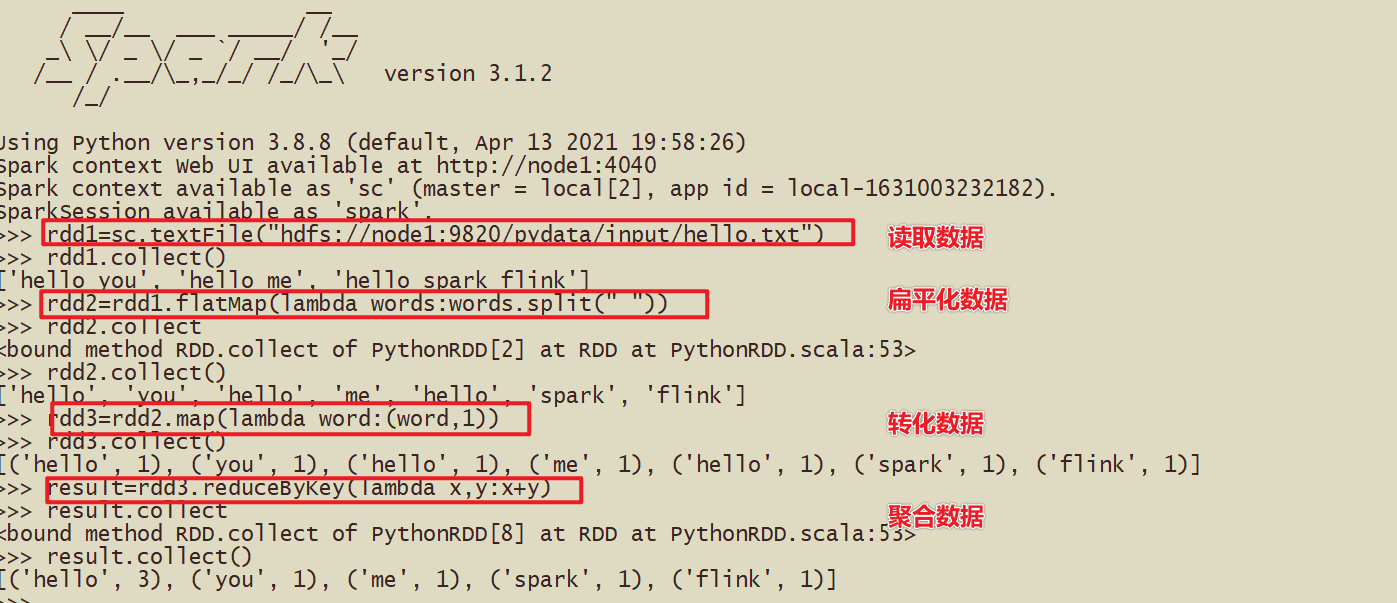
回顾Hadoop中可以使用
hadoop jar xxxx.jar 100
yarn jar xxxx.jar 1000
跑的mr的任务
Spark中也有对应的提交任务的代码
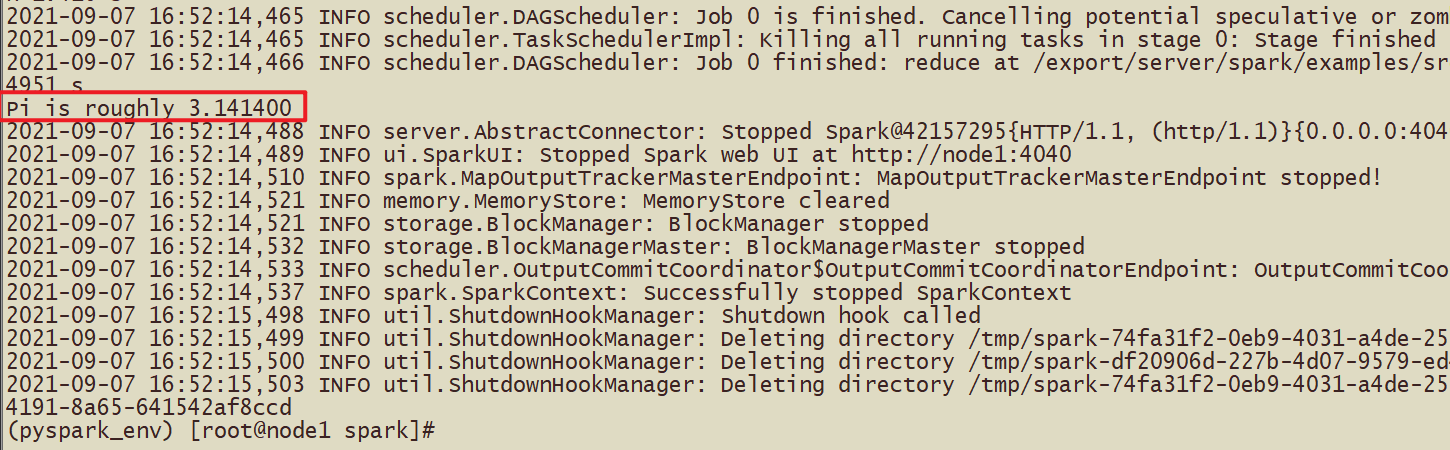
spark-submit 提交圆周率的计算代码 */examples/src/main/python/pi.py*
提交的命令:
bin/spark-submit --master local[2] /export/server/spark/examples/src/main/python/pi.py 10
或者# 基于蒙特卡洛方法求解的Pi,需要参数10,或100代表的次数 bin/spark-submit \ --master local[2] \ /export/server/spark/examples/src/main/python/pi.py \ 10
蒙特卡洛方法求解PI
采用的扔飞镖的方法,在极限的情况下,可以用落入到圆内的次数除以落入正方形内的次数
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 10 10
hadoop提交任务中使用 第一个10代表是map任务,第二10代表每个map任务投掷的次数
spark-submit的提交的参数10的含义是投掷的次数
简单的py代码

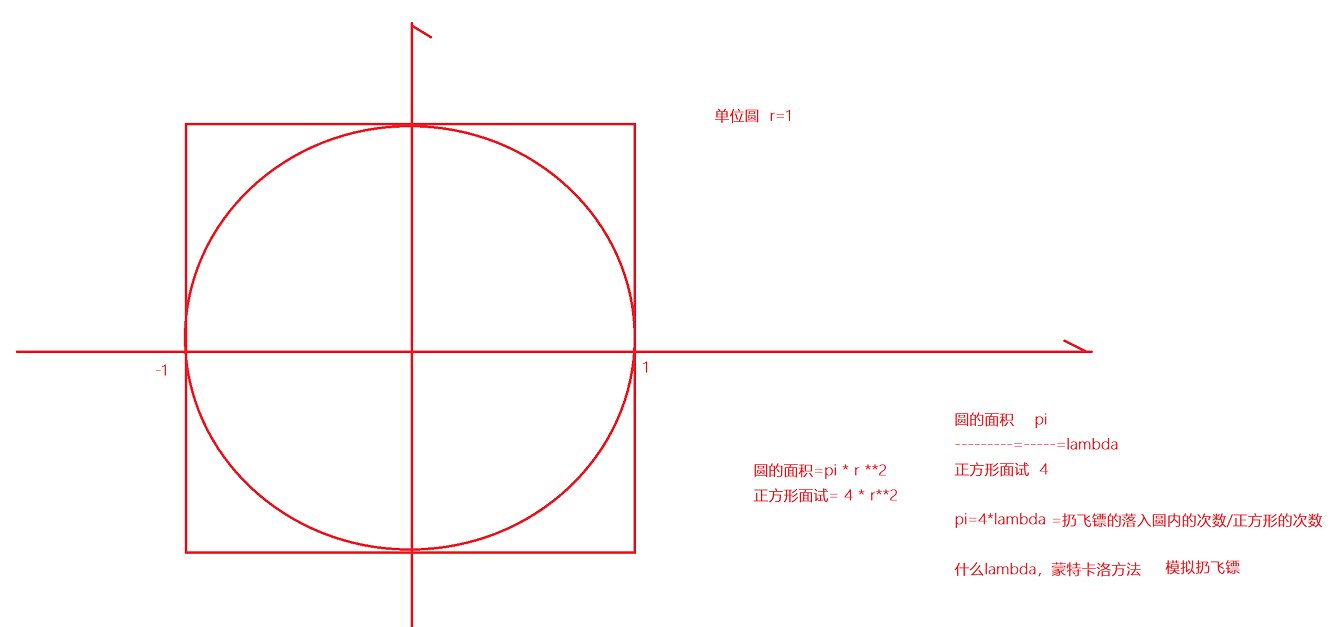
def pi(times): # times的意思是落入到正方形的次数
x_time = 0
for i in range(times):
# 有多少落入到圆内
x = random.random()
y = random.random()
if x * x + y * y <= 1:
x_time += 1
return x_time / times * 4.0
print(pi(10000000))#3.1410412
环境搭建-Standalone
- 完成了Spark的local环境搭建
- 完成了Spark的PySpark的local环境搭建
- 基于PySpark完成spark-submit的任务提交
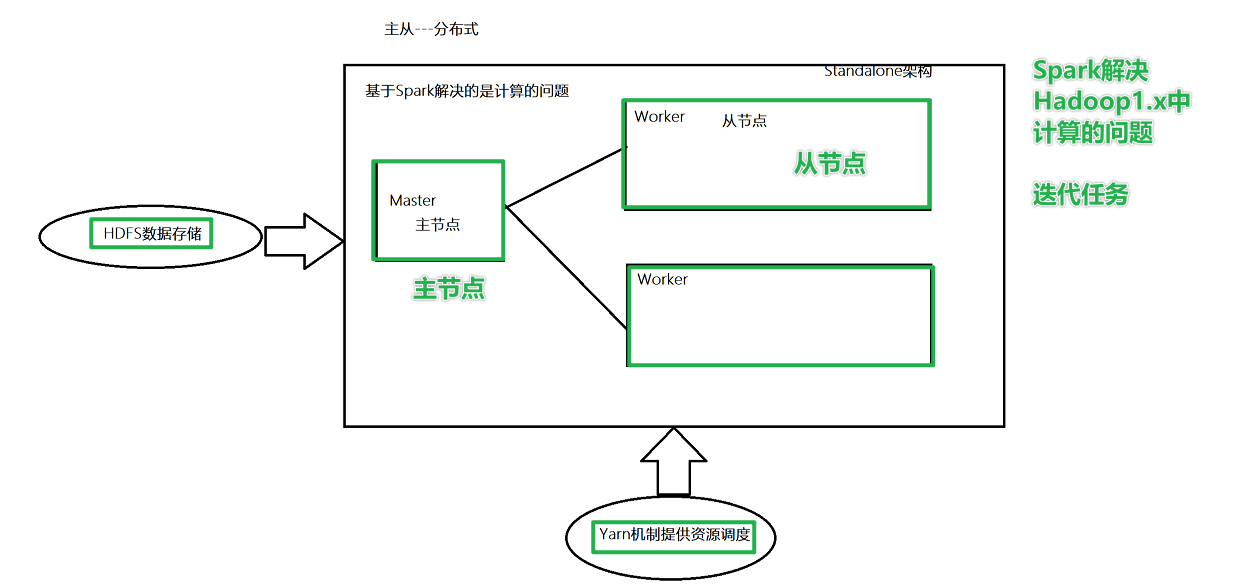
Standalone 架构
- 如果修改配置,如何修改?
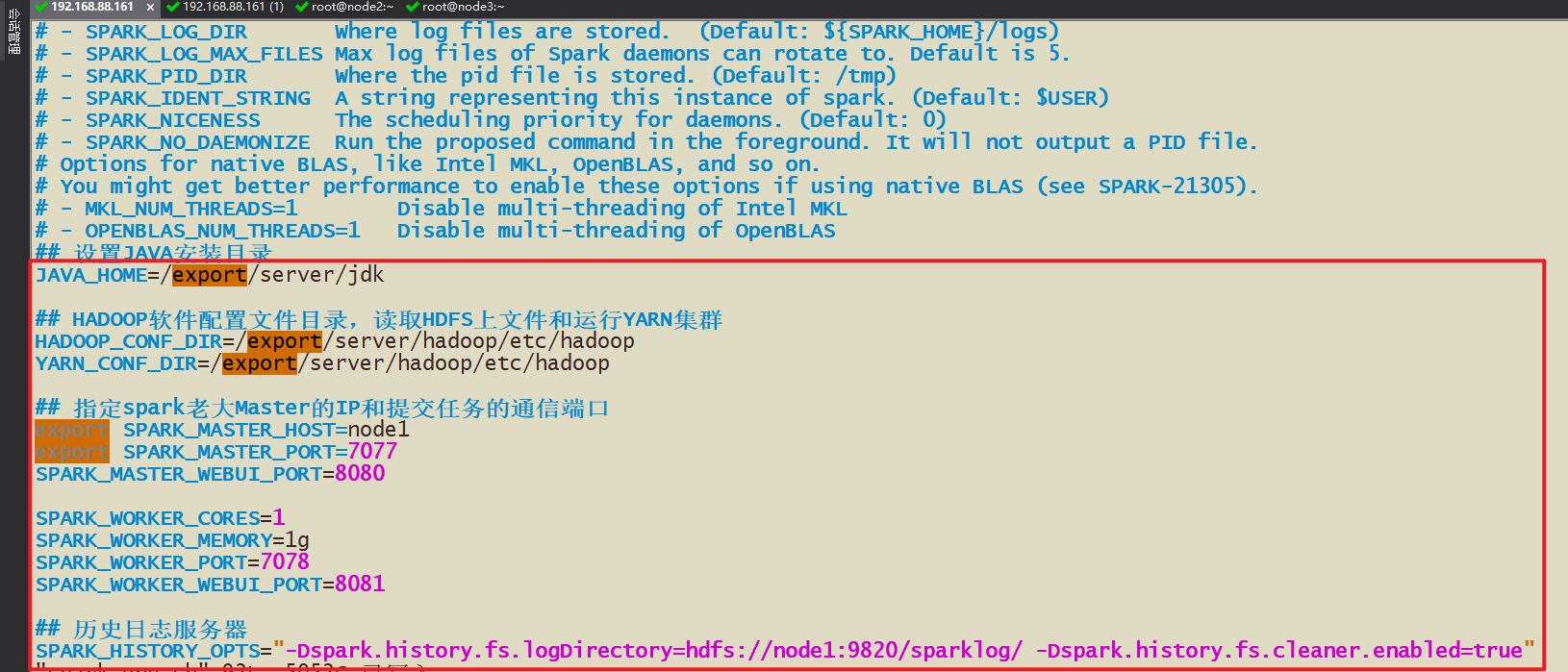
- 1-设定谁是主节点,谁是从节点
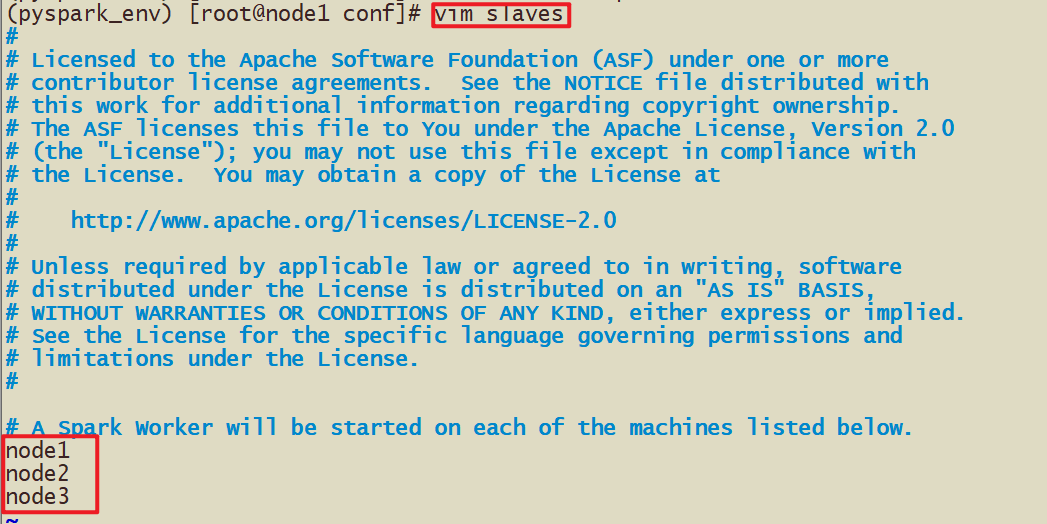
- node1是主节点,node1,node2,node3是从节点
- 2-需要在配置文件中声明,
- 那个节点是主节点,主节点的主机名和端口号(通信)
- 那个节点是从节点,从节点的主机名和端口号
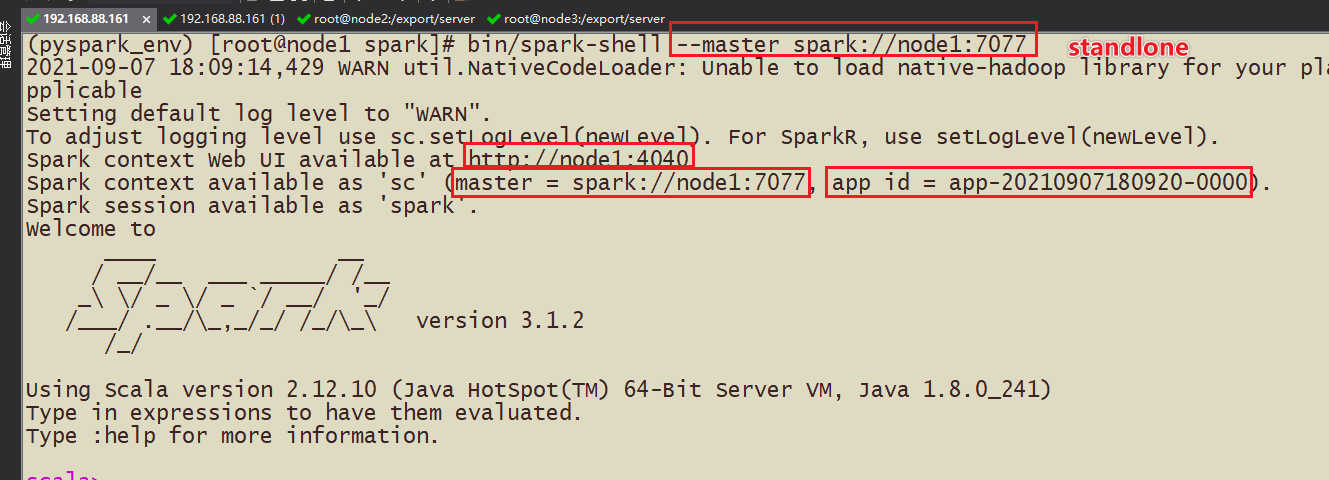
- 3-现象:进入到spark-shell中或pyspark中,会开启4040的端口webui展示,但是一旦交互式命令行退出了,wenui无法访问了,需要具备Spark的历史日志服务器可以查看历史提交的任务
角色分析
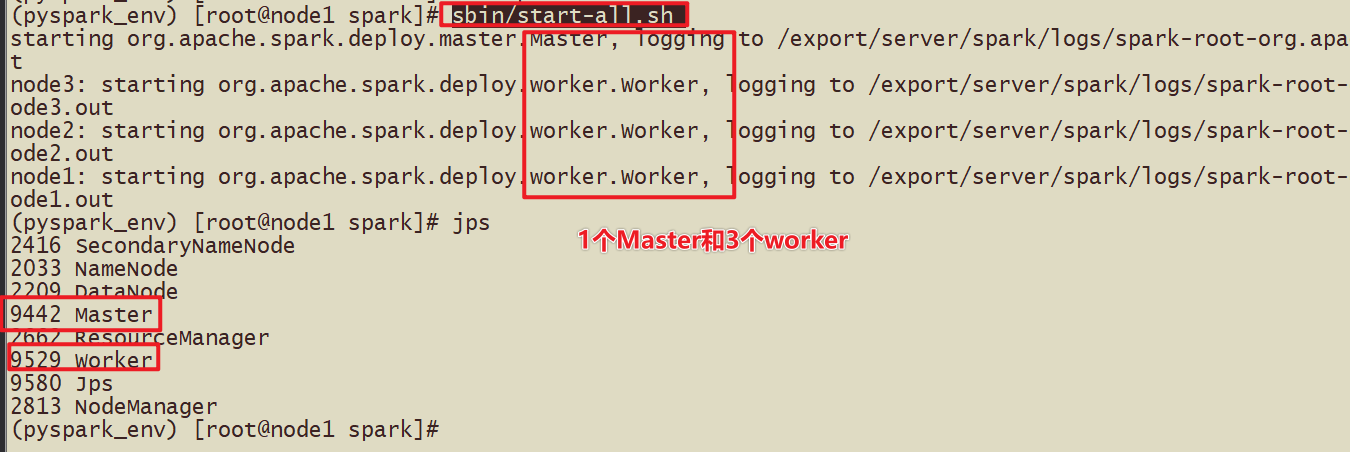
Master角色,管理节点, 启动一个名为Master的进程, *Master进程有且仅有1个*(HA模式除外)
Worker角色, 干活节点,启动一个名为 Worker的进程., Worker进程****最少1个, 最多不限制****
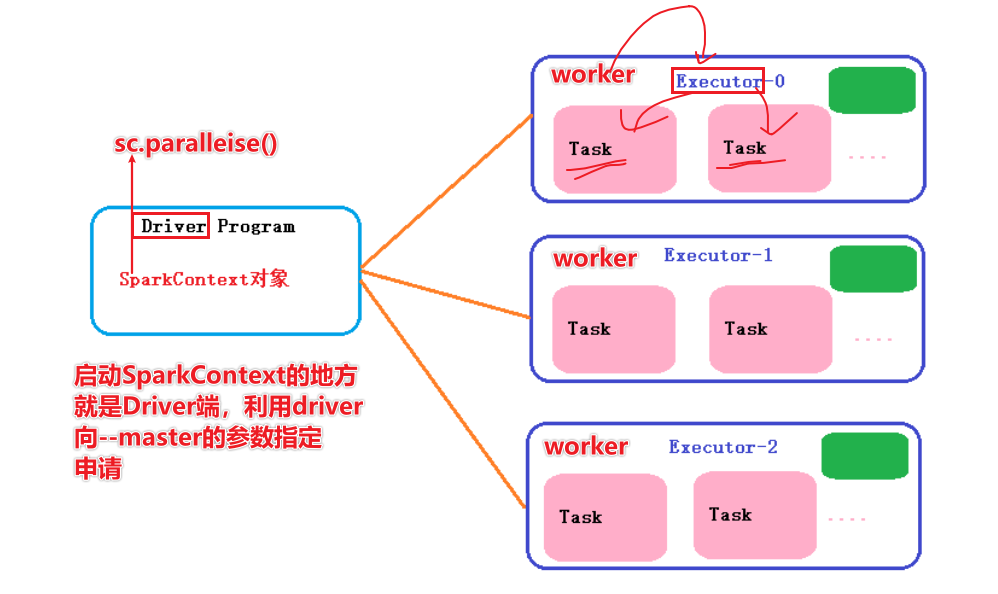
Master进程负责资源的管理, 并在有程序运行时, 为当前程序创建管理者Driver
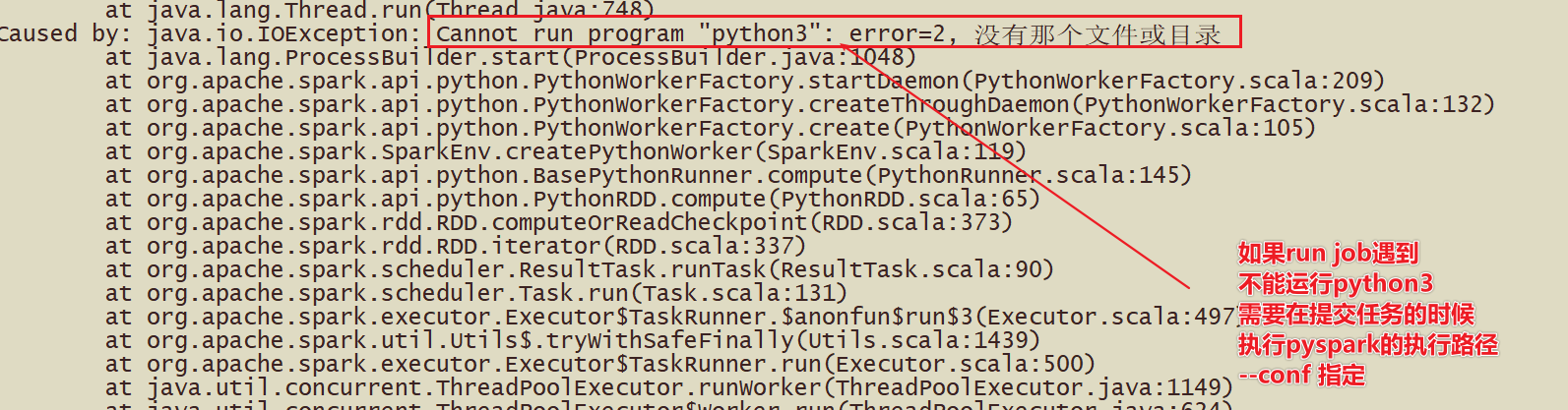
Driver:驱动器,使用SparkCOntext申请资源的称之为Driver,告诉任务需要多少cpu或内存
Worker进程负责干活, 向Master汇报状态, 并听从程序Driver的安排,创建Executor干活
在Worker中有Executor,Executor真正执行干活
集群规划
谁是Master 谁是Worker
node1:master/worker
node2:slave/worker
node3:slave/worker
为每台机器安装Python3
安装过程
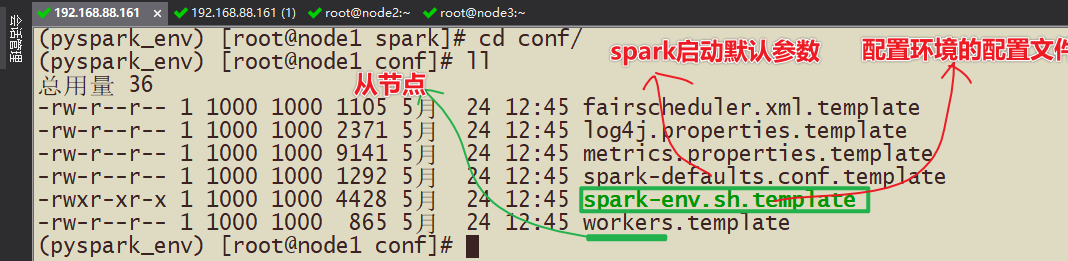
- 1-配置文件概述
- spark-env.sh 配置主节点和从节点和历史日志服务器
- workers 从节点列表
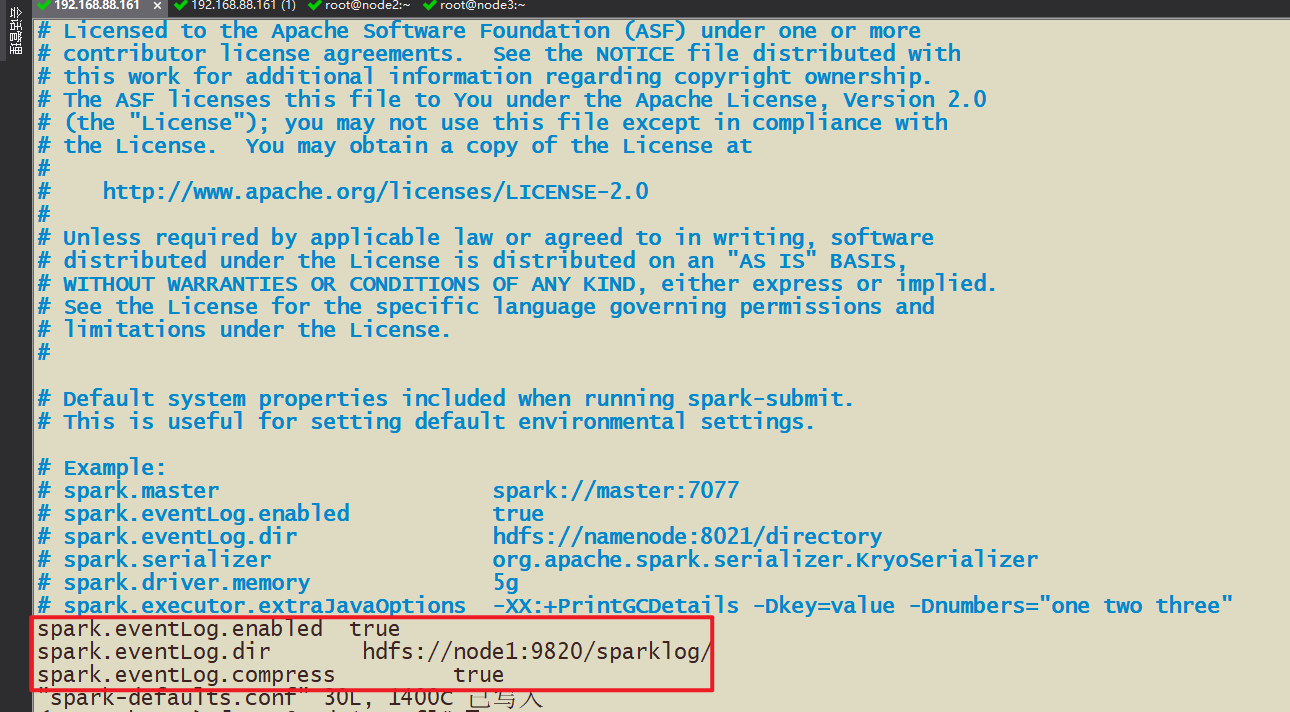
- spark-default.conf spark框架启动默认的配置,这里可以将历史日志服务器是否开启,是否有压缩等写入该配置文件
- 2-安装过程
- 2-1 修改workers的从节点配置文件
- 2-2 修改spark-env.sh配置文件
- hdfs dfs -mkdir -p /sparklog/
- 2-3 修改spark-default.conf配置文件
- 2-4 配置日志显示级别(省略)
测试
WebUi
(1)Spark-shell
bin/spark-shell --master spark://node1:7077
(2)pyspark
前提:需要在三台机器上都需要安装Anaconda,并且安装PySpark3.1.2的包
步骤:
如果使用crt上传文件一般使用rz命令,yum install -y lrzsz
1-在3台虚拟机上准备anconda
2-安装anaconda,sh anaconda.sh
3-安装pyspark,这里注意环境变量不一定配置,直接进去文件夹也可以
4-测试
调用:bin/pyspark --master spark://node1:7077
(3)spark-submit
#基于Standalone的脚本 #driver申请作业的资源,会向--master集群资源管理器申请 #执行计算的过程在worker中,一个worker有很多executor(进程),一个executor下面有很多task(线程) bin/spark-submit \ --master spark://node1:7077 \ --driver-memory 512m \ --executor-memory 512m \ --conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \ --conf "spark.pyspark.python=/root/anaconda3/bin/python3" \ /export/server/spark/examples/src/main/python/pi.py \ 10* 完毕
Spark 应用架构
两个基础driver和executor
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
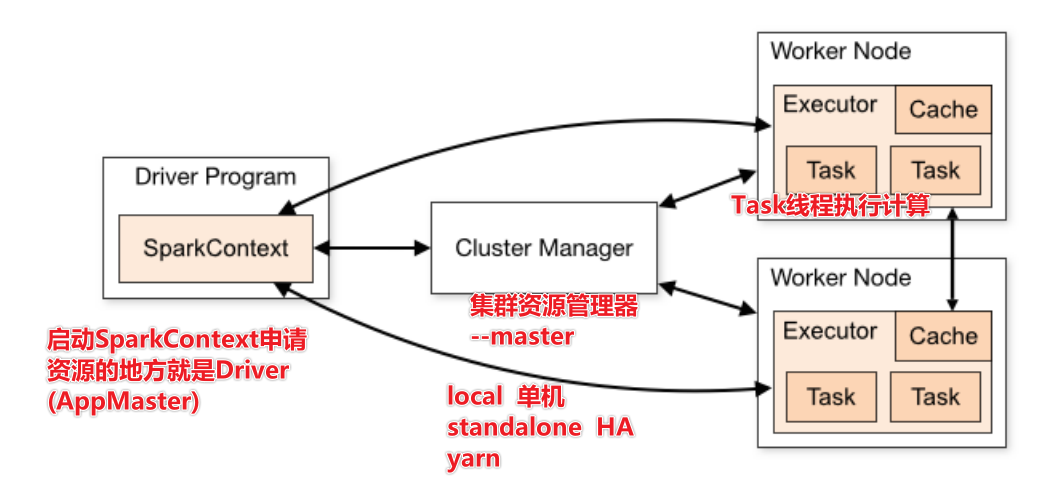
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
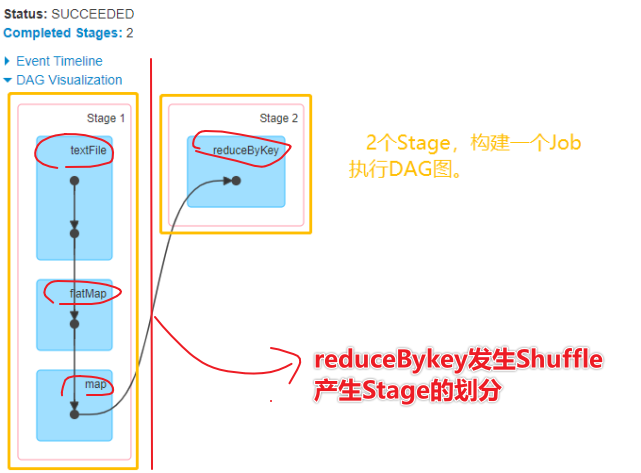
2)、Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task;
3)、Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver;
4)、Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)、Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止;
环境搭建StandaloneHA
- 回顾:Spark的Standalone独立部署模式,采用Master和Worker结构进行申请资源和执行计算
- 问题:如果Master出问题了,整个Spark集群无法工作,如何处理?
- 解决:涉及主备,需要一个主节点,需要一个备用节点,通过ZK选举,如果主节点宕机备份节点可以接替上主节点继续执行计算
高可用HA
- 架构图
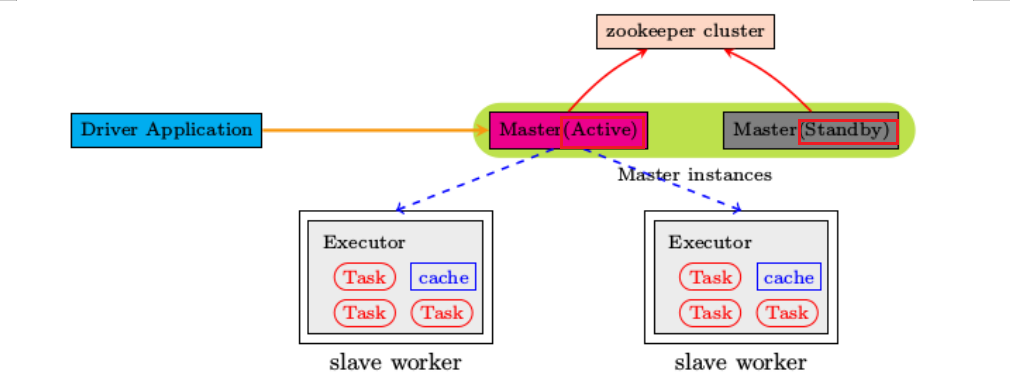
基于Zookeeper实现HA
- 如何实现HA的配置?
- 1-需要修改spark-env.sh中的master的ip或host,注释掉,因为依靠zk来选择
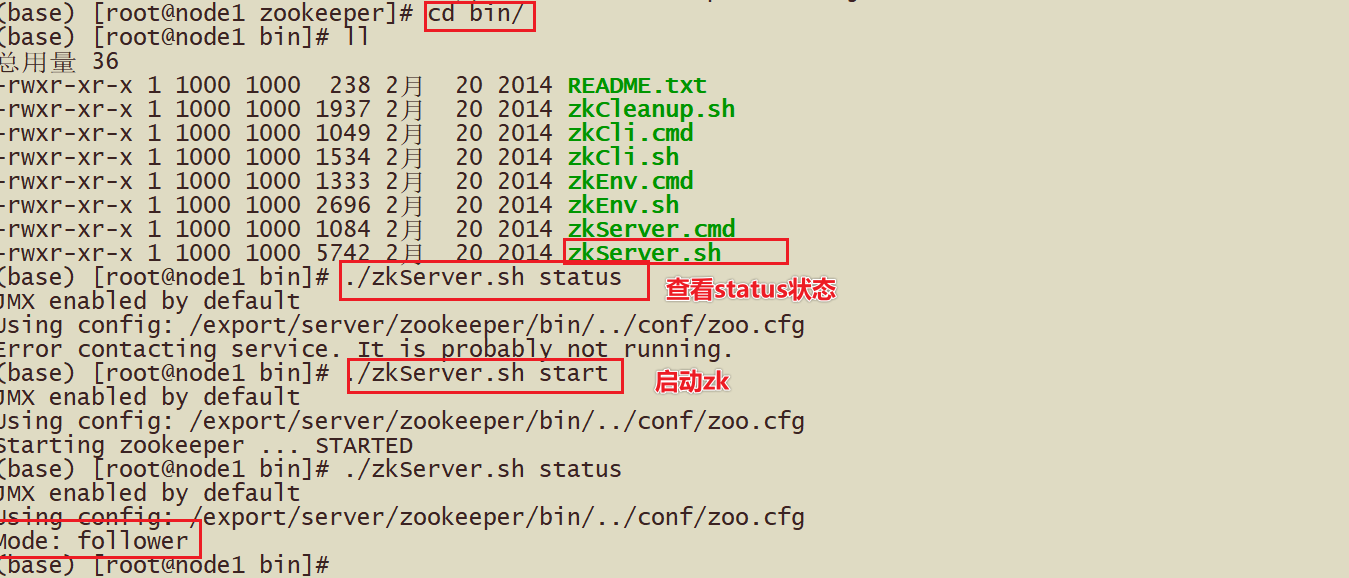
- 2-开启zk,zkServer.sh status
- 3-需要在原来的基础上启动node2的master的命令 start-master.sh
- 4-重启Spark的Standalone集群,然后执行任务
- sbin/stop-all.sh
- sbin/start-all.sh
- webUI
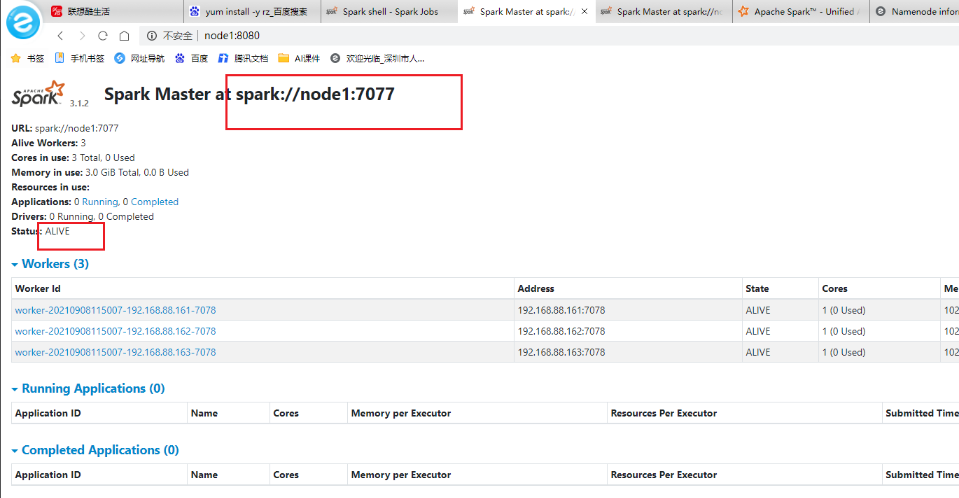
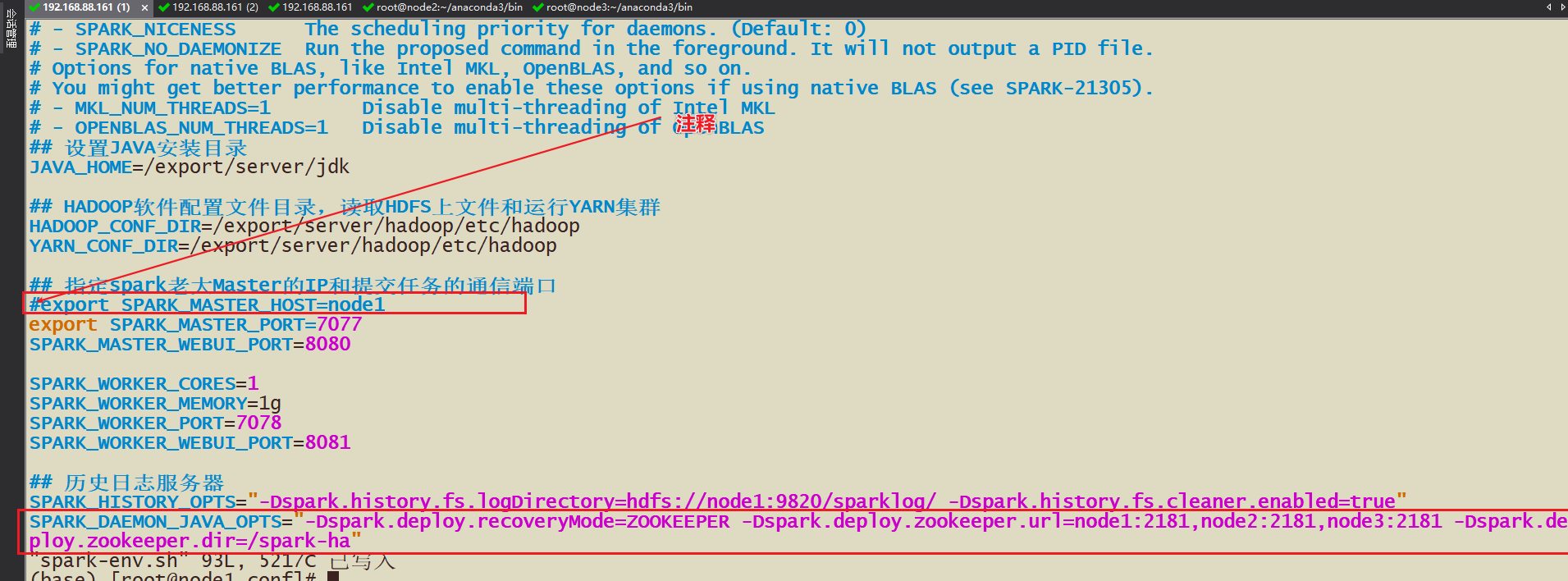
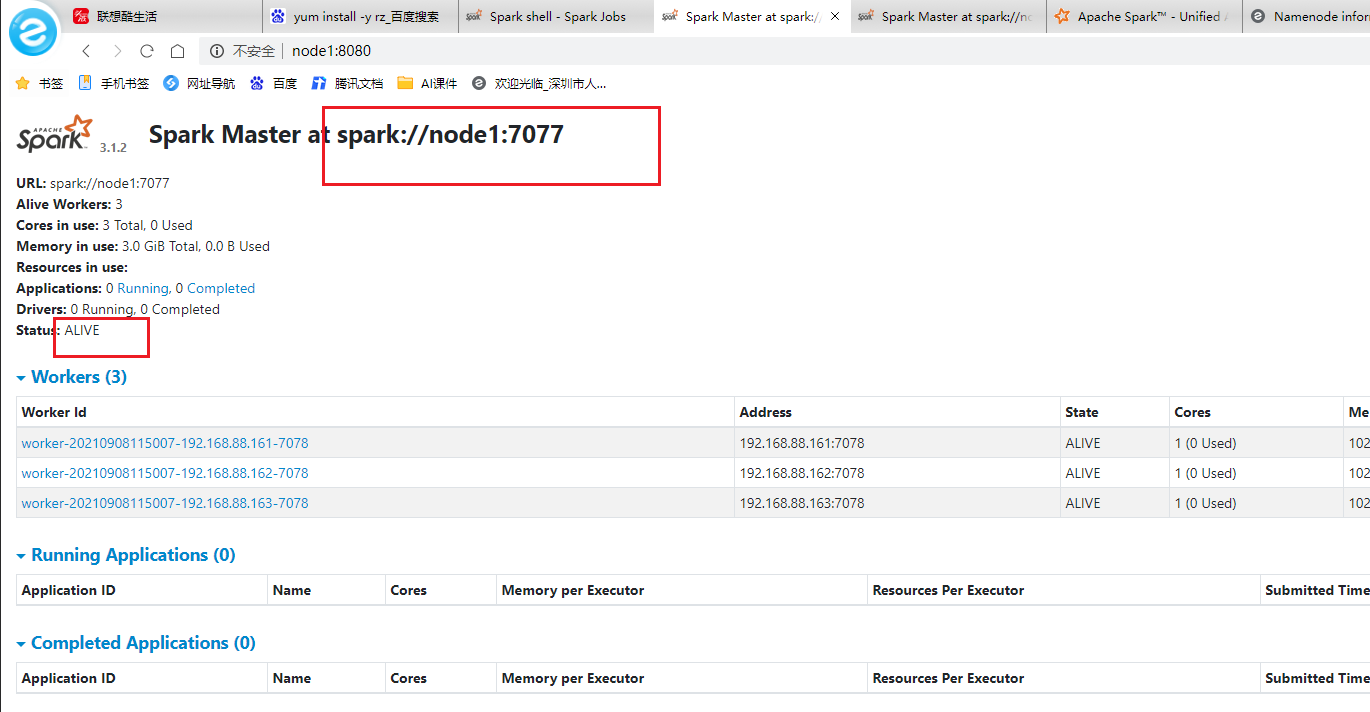
测试运行
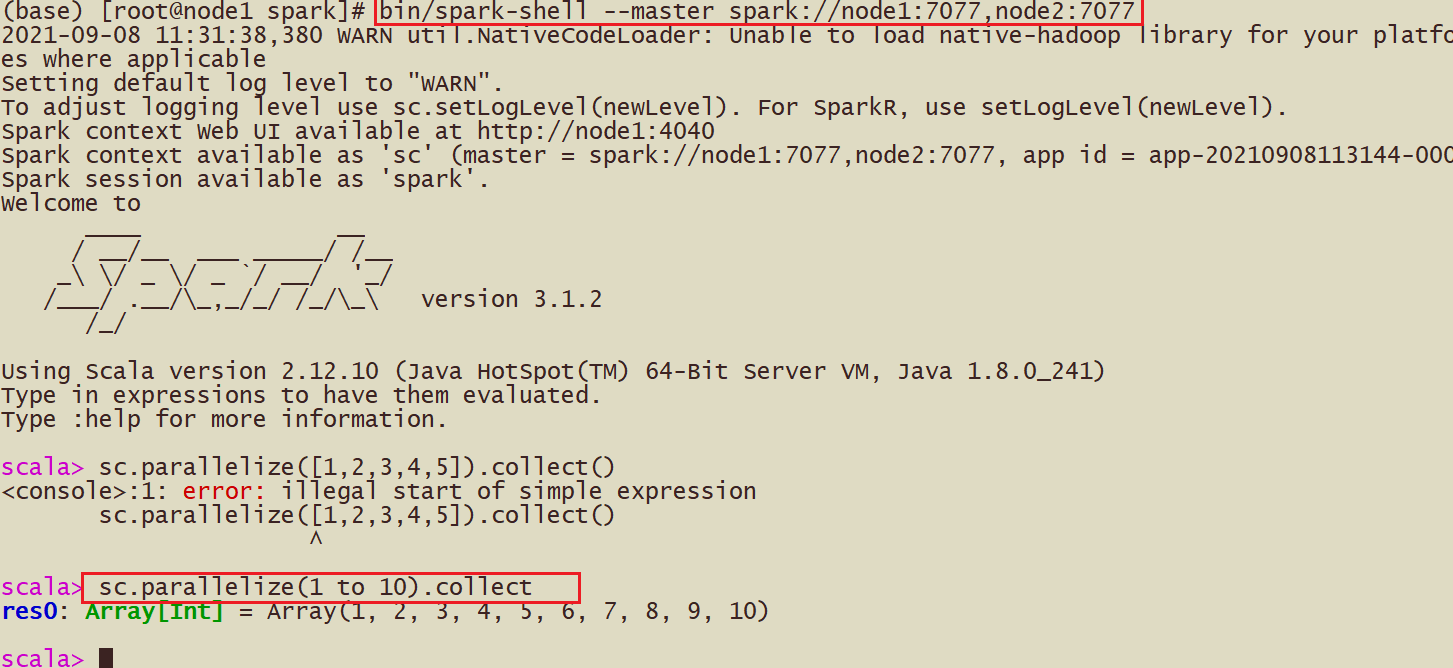
spark-shell
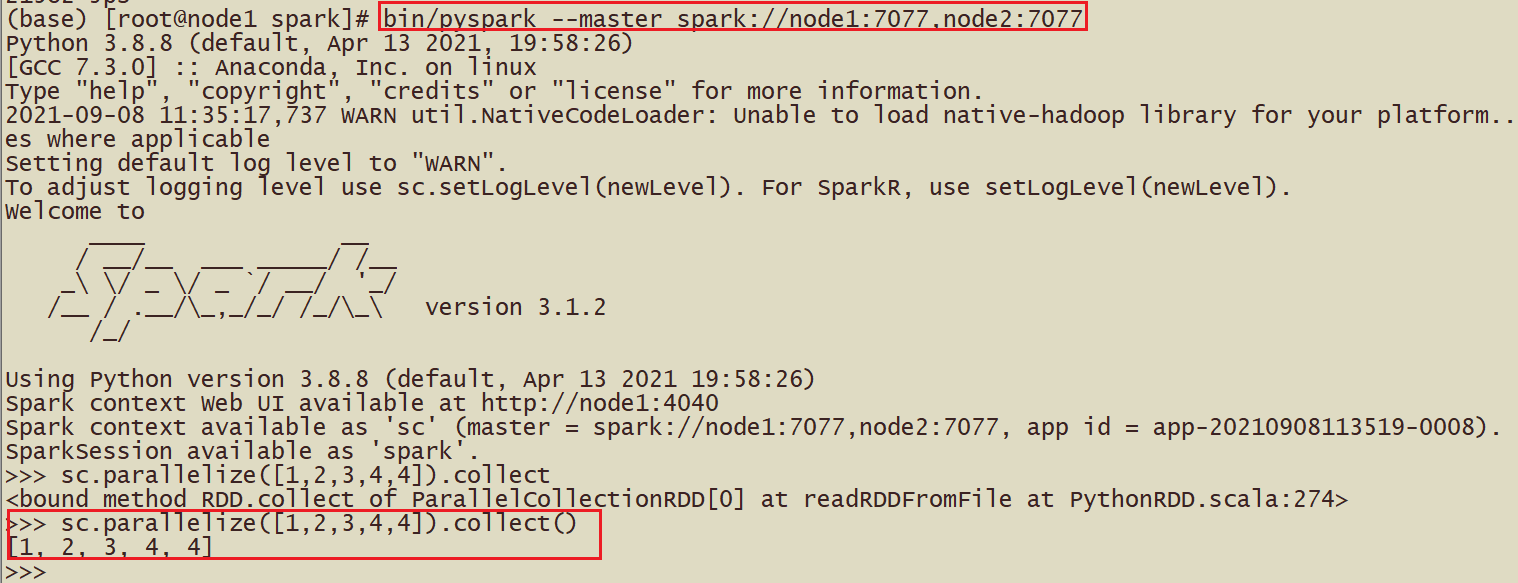
pyspark
- bin/pyspark --master spark://node1:7077,node2:7077
spark-submit
#基于StandaloneHA的脚本
bin/spark-submit
–master spark://node1:7077,node2:7077
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
/export/server/spark/examples/src/main/python/pi.py
10
测试:目前node1是主节点,node2是standby备用主节点,这时候将node1 的master进程干掉,然后看node2的master是否能够接替node1的master的作用,成为active的master
如果一个master节点宕机另外一个master启动需要1-2分钟
完毕

后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢感觉这辈子,最深情绵长的注视,都给了手机?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!