软考架构案例之大数据架构
前言
前不久参加了11月份的软考系统架构师,下午案例中还是有很多的架构相关的知识点,比如大数据架构和动静分离架构图等等。其中大数据架构的题目是填空Lambda和Kappa架构的架构图各个层次的组成部分,还有一个大数据架构的特点以及两种架构对比的维度,这个题目是案例第一题必选,分值25分。那么,今天就来解答一下这个题目并以大数据架构为主题分享一下官方软考大纲中的大数据架构。
大数据架构特点
1、鲁棒性和容错性
对于大规模分布式系统中,机器可能存在宕机,但系统需要健壮性,行为正确,即使遇到了机器错误。机器错误和人错误都是存在的,每天都难以避免。
2、低延迟读取和更新能力
有的需要毫秒的更新能力,有的允许几个小时的延迟更新,只要有低延迟需求,系统应该保证鲁棒性。
3、横向扩展
当负载增大的时候,通常可以通过增加机器数量来横向扩展。
4、通用性
要支持绝大多数应用程序,包括金融领域,社交领域和电子商务。
5、延展性
有新的需求出现时候,可以把新的功能加入到系统。
6、查询能力
用户可以按照自己的需求进行查询,可以产生更高的价值。
7、最少维护能力
系统在大多数时候保持平衡,减少系统的维护次数重要途径。
8、可调式性
系统在运行中,产生的每一个值,都是可追踪调试的。
Lambda架构
Lambda架构设计目的在于提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等。其整合离线计算与实时计算,融合不可变性、读写分离和复杂性隔离等原则。
Lambda 是用于同时处理离线和实时数据的,可容错的,可扩展的分布式系统。它具备强鲁棒性,提供低延迟和持续更新。Lambda架构应用场景: 机器学习、物联网、流处理。

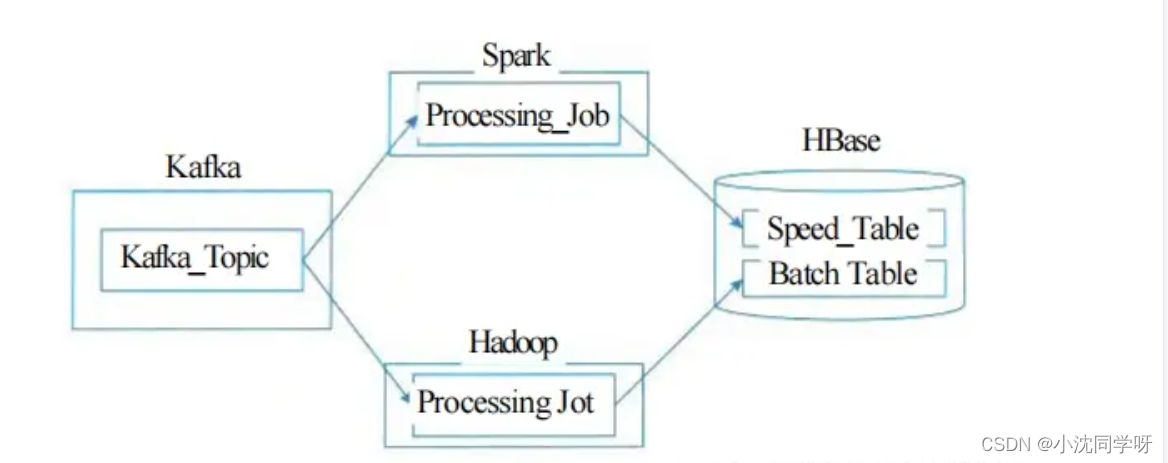
如图所示,Lambda 架构可分解为三层,即批处理层、加速层和服务层。
一般情况下批处理层采用Hadoop技术栈,加速层采用Spark技术栈,服务层则是由HBase进行数据存储,并由Hive创建可查询视图。
Kappa架构
Kappa架构在Lambda的基础上进行了优化,删除了Batch Laver 的架构,将数据道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。
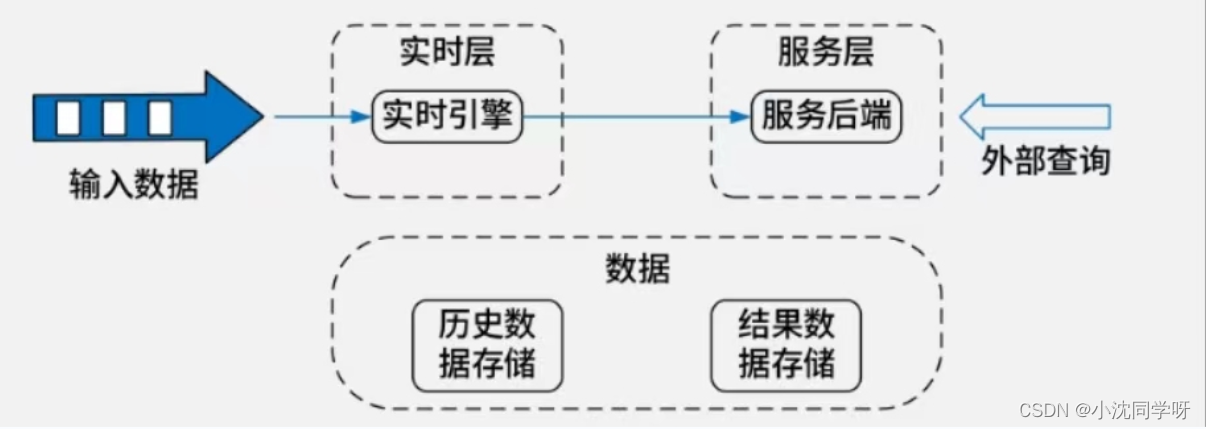
如图所示,输入数据直接由实时层的实时数据处理引擎对源源不断的源数据进行处理,再由服务层的服务后端进一步处理以提供上层的业务查询。而中间结果的数据都是需要存储的,这些数据包括历史数据与结果数据,统一存储在存储介质中。
在实际的开发场景中Kappa架构的实时层采用Fink技术栈,服务层当然还是HBase,另外有Hive创建查询视图。
Lambda架构与Kappa架构对比
根据两种架构对比分析
| 对比内容 | Lambda 架构 | Kappa 架构 |
|---|---|---|
| 复杂度与开发、维护成本 | 需要维护两套系统(引擎),批处理层采用Hadoop,加速层采用Spark,复杂度高,开发、维护成本高 | 只需要维护一套系统(引擎),实时层采用Flink,复杂度低,开发、维护成本低 |
| 计算开销 | 需要一直运行批处理和伪实时计算,计算开销大 | 必要时进行全量计算,计算开销相对较小 |
| 实时性 | 满足实时性,属于伪实时,在加速层采用Spark只是粒度细了一些 | 满足实时性 |
| 满足实时性 | 批式全量处理,吞吐量大,历史数据处理能力强 | 流式全量处理,吞吐量相对较低,历史数据处理能力相对较弱 |
写在最后
软考大纲的大数据架构分为Lambda、Kappa两种架构,Lambda架构采用Hadoop、Spark实现批量处理数据,而Kappa架构则是采用Flink流式处理实现实时数据处理。在我们实际的开发实战场景中一般还是偏实时数据处理较多,比如广告平台、证券交易等等。
下一篇博客我们继续介绍软考架构案例之Redis一致性如何保证,敬请期待。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!