用于解释非目标代谢组学数据的集成深度学习框架
摘要
非定向代谢组学正获得广泛应用。数据分析的关键方面包括建模代谢网络的复杂活动、选择与临床结果相关的代谢物以及发现关键代谢途径以揭示生物学机制。数据分析中的一个关键障碍未得到很好解决,即数据特征与已知代谢物之间的匹配不确定性问题。鉴于实验技术的限制,数据特征的身份不能直接在数据中揭示。
将特征映射到代谢物的主要方法是将数据特征的质荷比(m/z)与已知代谢物的理论值匹配。由于一些代谢物共享分子组成,同一代谢物可以衍生出不同的附加物离子,特征与代谢物之间的关系并非一一对应。这种匹配不确定性导致了不可靠的代谢物选择和功能分析结果。
在这里,我们介绍了一种考虑匹配不确定性的集成深度学习框架,用于代谢组学数据。该模型设计有一个基于已知代谢网络和特征与代谢物之间注释关系的渐进稀疏化神经网络。该体系结构刻画了代谢组学数据并反映了生物系统的模块化结构。三个目标可以同时实现,而无需进行复杂的推断和额外的假设:
(1)评估代谢物的重要性
(2)推断特征-代谢物匹配的可能性
(3)选择疾病亚网络。
当应用于COVID代谢组学数据集和老龄化小鼠脑数据集时,我们的方法找到了容易解释的代谢亚网络。
介绍
近年来,越来越多的研究试图探索代谢组学,以揭示疾病病理,寻找早期干预策略[1]。非靶向代谢组学数据是通过对生物样品中小分子物质的无偏测量而获得的,能够反映生物体内调控和代谢途径的功能变化。当分析疾病样本时,代谢组直接反映了身体的病理状态,从而导致了对其他形式的组学测量的补充发现[2,3]。
目前,收集非靶向代谢组学数据的主要方法是使用液相色谱-质谱(LC/MS)。LC/MS 数据具有很高的噪音,并且预处理包括多个步骤,如峰检测、对齐、保留时间校正、弱信号恢复等[4–6]。在LC/MS数据预处理之后,每个特征都通过质荷比(m/z)、保留时间(RT)和样本中的强度进行表征。为了确定特征的分子身份,通常的方法是基于质荷比(m/z)将特征与已知代谢物进行匹配。由于一些代谢物共享分子组成,同一代谢物可以衍生出不同的附加物离子,一个特征可以与多个已知代谢物匹配,一个代谢物也可以与多个特征匹配[7]。最近对数据无关采集(DIA)的进展使得代谢物注释更加准确。然而,当前阶段DIA仍不太适用于大规模研究[8]。已经开发了几种用于LC/MS数据的方法,通过使用已知代谢物作为参考,这些方法融入了代谢物之间的反应相似性[9]。
"数据无关采集"(Data-Independent Acquisition,DIA)是一种质谱分析方法,它的目标是获取样本中所有离子的质谱数据,而不是仅仅选择特定的离子进行分析。在DIA中,质谱仪会按照一定的质荷比窗口(m/z窗口)连续地扫描整个质谱范围,而不是选择性地监测特定的质荷比。这种方法相对于数据相关采集(Data-Dependent Acquisition,DDA)来说,更全面地捕获了样本中的信息。
LC/MS代谢组学数据分析涉及三个主要任务。
- 首先是选择与研究的临床结果相关的特征。
- 其次是找到与显著特征相对应的代谢物。
- 第三是确定哪些代谢途径受到生物条件的影响。?
通常与特定临床结果相关的代谢物只占所有代谢物的一小部分。确定有效的代谢物对于理解潜在的生物学机制至关重要。存在许多用于高维特征选择的方法[10, 11]。然而,鉴于代谢组学数据中的匹配不确定性,所选特征与代谢物之间并没有一对一的对应关系,这使得难以明确确定重要的代谢物。
除了代谢物的选择之外,代谢网络或途径分析是代谢组学数据分析的关键部分[12]。整合网络知识使生物标志物签名的发现更加稳健、稳定和可解释[13]。已经开发了许多用于使用基因表达数据进行子网络选择的方法[14–16]。同样,在代谢组学数据分析中,特征-代谢物匹配引入了额外的不确定性,这是上述方法无法解决的。
在专门为代谢组学数据开发的一些方法中,一些途径分析方法忽略了匹配不确定性问题[17, 18]。考虑到每个特征只能有一个正确的匹配,一些最近的研究尝试通过对匹配进行统计推断来消除/减少不确定性。特征之间的关系,比如符合常见附加物离子理论差异的质荷比差异,以及相似的保留时间,可以帮助确定两个特征是否可能来自同一代谢物[7, 19]。Cai等人[20]尝试将最佳匹配选择与预测模型中的特征选择相结合,但选择是二元的且缺乏适当的推断。Shen等人[21]利用了MS2的相似性,这通常对于大多数特征不可用,在反应对配邻域中推断真实匹配。这些工作并未提供代谢组学数据分析的集成流程,因为它们没有系统地计算潜在特征-代谢物匹配的可能性,并且它们没有评估个体代谢物对预测的重要性,这两者都是下游分析的基础。此外,当前方法不允许在代谢物丰度和疾病状态之间进行灵活建模,而这经常涉及非线性关系。为了填补这一空白,我们提出了一个统一框架,同时实现三个目标:(1)评估代谢物重要性,(2)推断特征-代谢物匹配的可能性,以及(3)从整体代谢网络中选择疾病亚网络。
为实现这一目标,我们采用了深度神经网络方法,该方法在许多组学领域取得了良好的性能[22–25]。我们还从最近关于通过添加特定结构或损失函数将领域知识融入神经网络的研究中汲取了灵感[26]。我们设计了一种新颖的深度学习模型,该模型包含一个基于特征-代谢物匹配和已知代谢网络的逐渐稀疏化结构,并设计了中间变量重要性和边缘重要性的新度量,以找到重要的代谢物和最可能的特征-代谢物匹配。在技术上,该方法可以被视为基于知识图的结构稀疏模型,因为它包含一个逐层逐渐稀疏化的结构,以更好地反映生物系统的模块化特性。在应用方面,我们新提出的方法可以作为分析非定向代谢数据的便利工具。其稀疏结构避免了在高维数据 - 低样本量(N << p)情境中的过度参数化,并倾向于选择落入亚网络的代谢物。它实现了良好的代谢物选择结果,并同时推断了最可能的特征-代谢物匹配。
3. **倾向于选择落入亚网络的代谢物:**
? ?- "亚网络"指的是整体代谢网络中的子网络或相关联的集合。
? ?- 由于采用了稀疏结构,该方法更有可能选择与生物学相关性更强、更有意义的代谢物,这些代谢物可能在生物学系统中形成特定的亚网络。因此,该方法通过在高维数据和低样本量情境中采用稀疏结构,有助于提高模型的泛化能力,选择更具生物学意义的代谢物,并更好地反映生物系统的模块化结构。
方法
方法概述
我们提出了一个用于分析非定向代谢组学数据的统一深度学习框架(图1)。该框架利用特征-代谢物注释关系和已知代谢网络来构建逐层逐渐稀疏的神经网络。该模型以全面的方式分析非定向代谢组学数据,支持分类、代谢物/亚网络选择以及推断特征与代谢物之间可能的匹配等任务。
该方法以一个特征丰度矩阵和一个包括潜在特征与代谢物匹配关系的表格作为起点,这个表格可以通过诸如xMSAnnotator等工具获得[27]。众所周知,存在一个匹配不确定性问题。由于许多代谢物共享相同的分子组成,因此一个特征可以与多个代谢物匹配。同时,每个代谢物可以生成多个附加物离子(图1A)。我们提出的框架将两种现有连接嵌入到一个稀疏神经网络中,这两种连接分别是:
(1)特征-代谢物潜在匹配和
(2)通过代谢网络中的共同反应的代谢物连接(图1B)。
总体来说,这个框架通过将这两种连接嵌套到神经网络中,以更好地考虑特征与代谢物之间的潜在匹配关系,同时也综合了代谢网络中的信息,使得模型能够更全面地分析代谢组学数据。这有助于解决匹配不确定性问题,提高分析的鲁棒性和可解释性。
在神经网络中,第一个隐藏层被命名为匹配嵌入层。它的隐藏神经元与代谢物一一对应。输入节点与这些隐藏神经元之间的连接由特征与代谢物之间的注释关系确定(图1C)。在第二个隐藏层中,我们将代谢网络结构嵌入为图嵌入层。该层再次包含一一对应于代谢物的神经元。
图嵌入层中的神经元仅在已知代谢网络中通过反应连接的相应代谢物对之间建立连接。在图嵌入层之后是几个逐渐稀疏化的层。这些层中每一层只包含在已知代谢网络中具有连接度 ≥ 预先指定阈值的神经元。层次越深,阈值越高。在达到足够的稀疏性后,接下来是传统的全连接层和输出层(图1C)。?
整体而言,这个设计意味着通过逐渐稀疏化的处理,模型更集中地关注具有较高连接度的代谢物,以更有效地捕捉代谢网络中的关键信息。
该网络通过使用Adam优化器最小化交叉熵损失在训练数据集上进行训练。基于训练好的模型,我们可以实现四个目标:(1)对新数据进行预测,(2)评估代谢物和特征的重要性,(3)进行代谢物和亚网络的选择进行功能分析,以及(4)推断可能的特征-代谢物匹配(图1D)。?
图1. 综合深度学习框架概述。
- (A) 数据来源的图示,包括分析LC-MS数据以生成数据特征(样本间对齐的峰值),以及将特征映射到已知代谢物。
- 输入代谢组学样本——LC-MS进行分析——加合物图标——已知代谢物数据库
- (B) 综合信息,包括特征丰度矩阵与临床结果、已知代谢网络结构和潜在特征匹配到代谢物的信息。
- 特征丰度矩阵——代谢网络——匹配特征信息
- (C) 逐层逐渐稀疏的神经网络,以特征表达数据为输入,样本类别为输出。它包括三个部分:基于潜在特征注释的特征-代谢物嵌入、代谢网络嵌入和逐层逐渐稀疏化、以及全连接层。
- 输入层——匹配嵌入层——图嵌入层——第一稀疏层——第二稀疏层——全连接层——输出层
- (D) 经过训练的模型的结果。该模型可以进行分类,确定可能的特征-代谢物匹配,进行代谢物和代谢子网络的选择,用于功能分析。
基于知识图的稀疏神经网络模型
我们新提出的模型是一个逐层逐渐稀疏的神经网络,它逐渐聚集在对应于输入图中枢节点的神经元周围的信号。这种稀疏结构的设计旨在解决训练数据有限和当网络随着大量输入变量变宽时出现的计算负载急剧增加的问题[28]。当没有输入变量之间的知识图可用时,获得稀疏网络的一般方法是从训练一个全连接网络开始,然后迭代地修剪连接。已经验证了适当的稀疏网络在准确性上可以与全连接网络相媲美[29]。
在组学数据的情况下,要考虑的变量数量通常在数千数量级,而样本大小通常在数百个。存在一个描述变量之间功能关系的知识图。利用知识图在两个方面是有益的:
(1)在样本量较小时,实现更具鲁棒性的稀疏模型训练
(2)产生符合现有知识的变量选择结果,使结果更具可解释性。
由于特征-代谢物匹配的不确定性,非定向代谢组学数据尤为具有挑战性。代谢网络可用于描述代谢物之间的功能关系,我们的兴趣是找出与临床结果最相关的代谢物和代谢途径(整个代谢网络的子网络)。
我们的模型建立在以下假设的基础上。
- 第一假设是每个特征在所有给定的潜在匹配中都有其真实的注释。
- 第二假设是只有很小一部分的代谢物对疾病结果有真实的预测作用,并且它们倾向于位于完整代谢网络的小子网络中。这些假设在先前的研究中被广泛使用和承认。
为了从原始特征丰度数据中找到有效的代谢物,我们的模型通过在统一框架中将潜在的匹配关系与代谢网络结合起来,解决了匹配不确定性的问题。







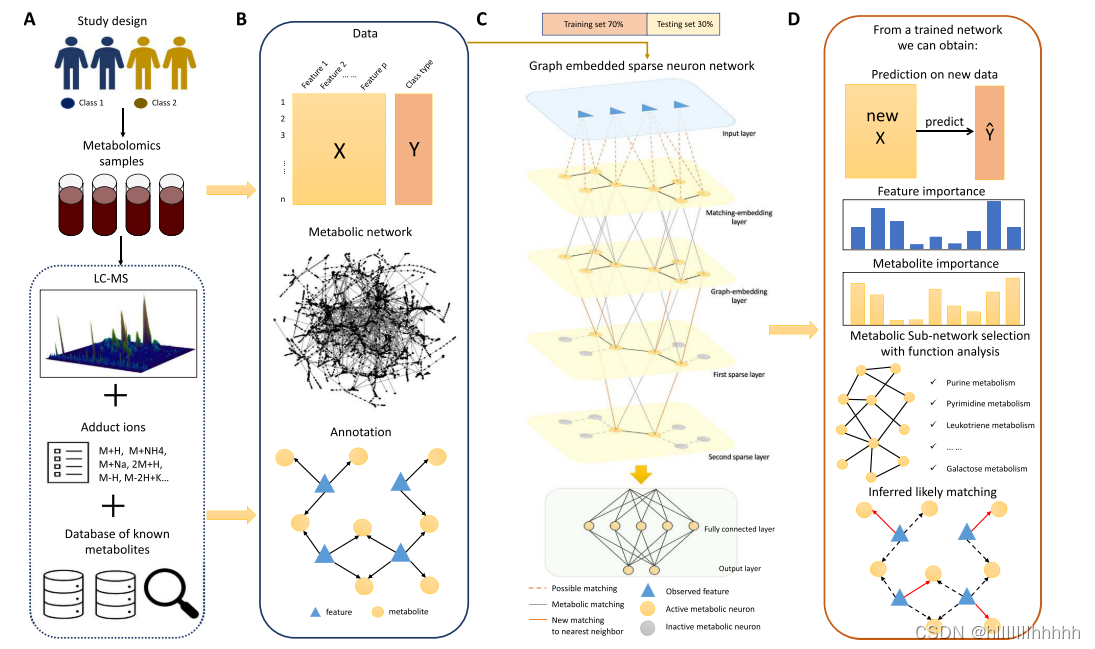
输入层与第一隐层(匹配嵌入层)之间的连接由矩阵M确定
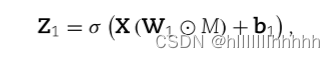

使用逐元素乘法是为了确定原始矩阵中哪些元素重要
在下一个稀疏层中,我们首先确定一个稀疏化因子 μ(0 < μ < 1),然后决定稀疏层的大小为 |L3| = m × μ。根据这个数量,我们包括在 G 中度排名最高的节点,这些节点被称为活跃节点。我们将未被选择进入下一个稀疏层的节点称为非活跃节点。活跃节点的连接从代谢网络继承而来。一些非活跃节点没有连接到下一层,因为它们在代谢网络上的第一邻居都是非活跃节点。对于这样的节点,通过将非活跃节点链接到其在代谢网络上的最近邻的活跃节点之一来添加新连接。

类似地,我们构建了几个稀疏连接层,超过第 3 个隐藏层,每个都比前一个小。在稀疏神经网络部分之后,我们附加全连接层,最后一层输出不同类别的概率预测。
特征和代谢物重要性评价
识别预测性代谢物对于下游分析至关重要,有助于揭示潜在的生物学机制,从而更好地理解临床结果。我们从训练好的模型中推断真实的匹配,并评估特征和代谢物的重要性。这个想法类似于 [23] 引入的图连接权重(Graph Connection Weights,GCWs)方法。在GCW中,一个预测变量的重要性由其相关权重的大小反映。我们的提议是,在反向传播训练过程中,真实匹配的权重在过程中获得更多的关注。
真实匹配的权重在过程中获得更多的关注。
意思是说能够找到匹配的代谢物
首先,我们考虑代谢物重要性的估计。与 GCW 相比,我们尝试消除链接数量的影响,其中包括与特征的匹配数量,以及在代谢网络中的度。为了避免零分母,我们对每个代谢物的代谢物-特征链接数添加了1。对于第一和第二隐藏层的神经元,每个神经元与一个代谢物有一对一的映射,因此对其关联权重的绝对值求和得到了一个重要性的估计,即:
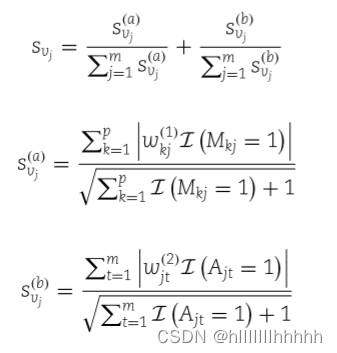

类似地,我们可以使用第一层中的权重来推断特征的重要性。对于每个特征,我们将其重要性定义为其潜在相关代谢物的重要性之和,即
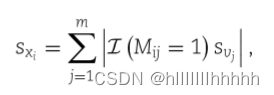


详细的模型设置

结果
COVID代谢组学数据分析
在前所未有的全球冠状病毒病 2019(COVID-19)大流行期间,代谢组学技术已被采用来研究 COVID 感染的代谢反应。理解代谢模式与疾病严重程度之间的关联,并识别可能导致严重疾病结果的生理过程至关重要。Metabolomics Workbench 上的 ST001849 数据集是为了找到 COVID 感染的预后标志物而收集的[32]。我们将我们的模型应用于在患者入院时(第0天)收集的血浆代谢组学数据的子集,以找到与患者后来是否被送入重症监护室(ICU)相关的代谢物和代谢途径。
我们下载了原始的液相色谱/质谱(LC/MS)数据,并使用 apLCMS [6, 33] 进行了数据预处理,随后使用 combat [34] 进一步处理以消除批次效应。我们移除了在超过 75% 样本中具有零丰度的特征,并进行了 log(1+x) 转换。对数据进行了最小-最大归一化和等距投影,以统一数据的尺度。使用 xMSannotator [27] 进行了特征到代谢物的注释。分析使用了KEGG代谢网络[35]。在过滤后,我们得到了一个包含 1351 个特征、匹配到 913 个代谢物的数据集,共包括 263 个样本,其中 123 个样本后来被送入了重症监护室(标签 1),而 140 个样本未被送入(标签 0)(图2A)。每个代谢物的平均匹配值为3.11,范围为1-13。在观察的特征方面,平均匹配值为2.11。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!