2.8 EXERCISES
-
如果我们想使用每个线程来计算向量加法的一个输出元素,那么将线程/块索引映射到数据索引的表达式是什么?

答:C -
假设我们想用每个线程来计算向量加法的两个(相邻)元素。将线程/块索引映射到i(由线程处理的第一个元素的数据索引)的表达式是什么?

答:C -
我们想用每个线程来计算向量加法的两个元素。每个线程块处理2*blockDim.x连续的元素,形成两个部分。每个块中的所有线程将首先处理一个部分,每个线程处理一个元素。然后,他们都将移动到下一节,每个部分处理一个元素。假设变量i应该是线程处理的第一个元素的索引。将线程/块索引映射到第一个元素的数据索引的表达式是什么?

答:D -
对于向量加法,假设向量长度为8000,每个线程计算一个输出元素,线程块大小为1024线程。程序员将内核启动配置为具有最小数量的线程块,以覆盖所有输出元素。网格中将有多少个线程?

答:C -
如果我们想在CUDA设备全局内存中分配一个v整数元素的数组,对于cudaMalloc调用的第二个参数,适当的表达式是什么?

答:C -
如果我们想分配一个由n个浮点元素组成的数组,并有一个foating-point指针变量d_A来指向分配的内存,那么cudaMalloc()调用的第一个参数的适当表达式是什么?

答:D -
如果我们想从主机数组h_A(h_A是源数组元素0的指针)复制3000字节的数据到设备数组d_A(d_A是目标数组元素0的指针),那么CUDA中此数据副本的适当APl调用是什么?

答:C -
如何声明可以适当接收CUDA API调用的返回值的变量err?
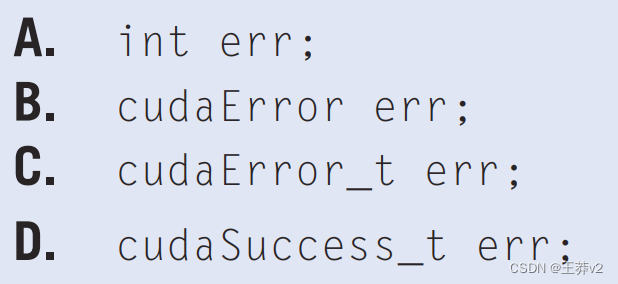
答:C -
一名新的暑期实习生对CUDA感到沮丧。他一直抱怨CUDA非常乏味:他不得不声明他计划在主机和设备上执行的许多功能两次,一次作为主机功能,一次作为设备功能。你的回应是什么?
答: 对于新接触 CUDA 的开发者来说,CUDA 编程模型的一些要求可能会感到有些重复和繁琐,特别是在声明函数(即“kernels”)时需要区分主机(host)和设备(device)代码。对于这位实习生的困扰,以下是一些可能的回应和建议:
解释 CUDA 的设计理由:
解释为什么需要在主机和设备上分别声明函数。在 CUDA 中,主机(CPU)和设备(GPU)有着不同的内存空间和执行环境。因此,需要明确指出哪些函数是在主机上运行,哪些是在设备上运行。这样的设计有助于优化性能,因为它允许开发者精确控制代码在硬件上的执行方式。
使用 host 和 device 修饰符:
在 CUDA 中,可以使用 host 和 device 修饰符来声明函数,这样一个函数就可以在主机和设备上都执行。这可以减少一些重复性的代码声明。例如:
__host__ __device__ void myFunction() {
// ...函数实现...
}
模板和宏:
如果有大量重复代码,可以考虑使用宏或模板来减少重复。虽然这可能会使代码的可读性降低,但它可以减少代码量并提高开发效率。
代码组织和抽象:
鼓励实习生寻找提高代码可重用性的方法。例如,共享的逻辑可以抽象成函数库,或者在主机和设备代码之间共享代码片段。
利用现代 CUDA 特性:
随着 CUDA 的发展,一些新特性可以减少代码的重复。例如,CUDA Unified Memory(统一内存)允许主机和设备共享内存,这样就不需要手动管理不同内存空间的数据传输。
学习和耐心:
鼓励实习生保持学习和实践。熟悉 CUDA 编程模型后,许多最初看起来乏味的任务会变得更加直观。同时,随着经验的积累,他们可以学会编写更高效和更优雅的 CUDA 代码。
最后,理解 CUDA 的设计理念和编程模型对于开发高效的 GPU 加速应用是很重要的。随着经验的积累,实习生将能更好地掌握如何在这个平台上进行高效编程,并可能开始欣赏 CUDA 那些特别设计的地方,这些设计使得高性能并行计算成为可能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!