数据库中的存储过程Procedure
简介
存储过程(Stored Procedure)是大型数据库系统中,一组为了完成特定功能的SQL 语句集,是数据库对象之一。存储过程 预先存储在数据库(MySQL 服务器)中,只在创建时进行编译,一次编译后永久有效,需要执行时 用户 通过客户端 只需要指定存储过程的名字【并给出参数(如果该存储过程带有参数)】、向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。存储过程可以完成所有的数据库操作。存储过程在数据量特别庞大的情况下利用存储过程能达到倍速的效率提升。
比如在实现用户的某些需求时,需要编写一组复杂的SQL语句才能实现的时候,那么我们就可以将这组复杂的SQL语句集提前编写在数据库中,由JDBC调用来执行这组SQL语句。把编写在数据库中的SQL语句集称为存储过程。
MySQL从5.0版本开始支持存储过程和函数。存储过程和函数能够将复杂的SQL逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可。存储过程存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
存储过程的好处有:
- 减少网络传输量(客户端不需要把所有的 SQL 语句通过网络发给服务器)
- 减少了 SQL 语句暴露在网上的风险,也提高了数据查询的安全性
- 代码复用 和 良好的封装性。将代码 封装 成模块,实际上是编程的核心思想之一,这样可以把复杂的问题拆解成不同的模块,然后模块之间可以 重复使用 ,在减少开发工作量的同时,还能保证代码的结构清晰。在进行相对复杂的数据库操作时,原本需要使用一条一条的 SQL 语句,可能要连接多次数据库才能完成的操作,现在变成了一次存储过程,只需要 连接一次即可 。
存储过程的缺点有:
- 可移植性差。存储过程不能跨数据库移植,比如在 MySQL、Oracle 和 SQL Server 里编写的存储过程,在换成其他数据库时都需要重新编写。
- 调试困难。只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容易。虽然也有一些第三方工具可以对存储过程进行调试,但要收费。
- 存储过程的版本管理很困难。比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
- 不适合高并发的场景。高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护, 增加数据库的压力 ,显然就不适用了。
使用语法
声明存储过程
如下所示,[characteristics ...] 表示创建存储过程时指定的【对存储过程的】约束条件,其取值信息如下:
- LANGUAGE SQL
- [NOT] DETERMINISTIC
- CONTAINS SQL NO SQL
- READS SQL DATA
- MODIFIES SQL DATA
- SQL SECURITY DEFINER INVOKER
- COMMENT ‘string’
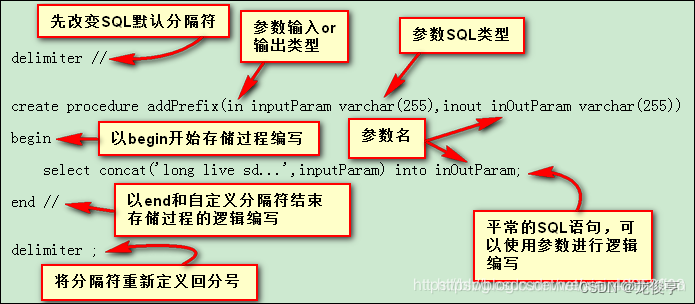
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN
存储过程体,比如:
声明变量:declare name varchar(10); //使用的位置要在 BEGIN…END 语句中间,而且需要在其他语句使用该变量之前。
赋值语句,用于对变量进行赋值:SET 。
将【从数据表中查询的】结果存放到声明的变量中:select Sname into name from student where Sno=sno limit 1;
返回变量:select name;
END
调用存储过程
CALL 存储过程名称(实参列表);:存储过程必须使用CALL语句调用,并且存储过程和数据库相关,如果要执行其他数据库中的存储过程,需要指定数据库名称,例如CALL dbname.procname。
存储过程的参数
存储过程就类似于Java中的方法,需要先定义,使用时需要调用。存储过程可以定义参数,参数分为IN、OUT、INOUT类型三种类型。
- IN类型的参数表示接受调用者传入的参数,在存储过程的参数未指定类型时,IN是默认类型;
- OUT类型的参数表示向调用者返回数据。在存储过程 无返回数据时,可以不表明IN类型,因为都是传入参数;
- INOUT类型的参数即可以接受调用者传入的参数,也可以向调用者返回数据。
有博客总结为:数据库 SQL 语言层面的 一组经过预先编译的 代码封装与重用。
调用存储过程
调用存储过程如下例最后一行所示,通过@sumgrade返回检索结果。
DELIMITER //
CREATE PROCEDURE get_someone_sumgrade2(IN stuid int,OUT sumgrade int)
BEGIN
select sum(grade) into sumgrade from score where stu_id = stuid;
END //
DELIMITER ;
SET @sumgrade;
CALL get_someone_sumgrade2(901,@sumgrade);
SELECT @sumgrade ;
无参数
有参数
该存储过程传入参数为sno,有效性待验证。
- 存储过程为了防止定义重名,第一行就先删除了重名的存储过程。
- 存储过程的sql语句写在
begin与end之间。 - 存储过程将检索结果
Sname存入name中,并在最后通过select name;将检查结果返回。
请注意,使用 select into 语句赋值的时候要确保该语句只返回一条结果,或者加上 limit 1 来限制返回结果的行数。
drop procedure findname;
delimiter $$
create procedure findname(sno int)
begin
declare name varchar(10);
select Sname into name from student where Sno=sno limit 1;
select name;
end$$
delimiter ;
在存储过程中使用 out 类型的参数输出,省去了在最后通过select name;将检查结果返回,该存储过程的定义如下所示。
drop procedure findname;
delimiter $$
create procedure findname(in sno int,out sname varchar(10))
begin
select Sname into sname from student where Sno=sno limit 1;
end$$
delimiter ;
但是请注意,承担返回结果的参数out sname varchar(10)也需要传入参数,如下所示。
set @name='';
call findname(2,@name);
select @name as studentname;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!