webshell检测方式深度剖析 --- Pixy系列二(数据流分析)
开篇
书接上文,这次我们来聊聊数据流分析,数据流分析的内容非常广泛,我们力求深入浅出通俗易懂,在简短的篇幅内将这一概念描述清楚。
简单来说,数据流分析是一种用来获取相关数据沿着程序执行路径流动的信息分析技术,分析对象是程序执行路径上的数据流动或数据可能的取值,最早用于编译优化过程中。由于程序数据流的某些特点和性质与程序漏洞紧密相关,比如在SQL注入漏洞中,检测系统需要知道某个变量的取值是否源自某个可信的数据源,比如在缓冲区溢出漏洞中,需要获得内存操作长度的可能取值范围来判断是否存在缓冲区溢出漏洞,所以数据流分析也成为了一种重要的漏洞分析技术。数据流分析技术除了可以直接应用于漏洞分析,对多种程序漏洞或者缺陷进行分析和检测,还可以作为漏洞分析的支撑技术,为其它漏洞分析方法提供重要的数据支持。
如前所述,数据流分析是从程序执行路径上获取相关数据信息,所以它依赖于程序的执行路径,而描述程序执行路径的最有效工具就是控制流图(control flow graph,CFG)。下面我们就先从CFG开始讲起。
控制流图
控制流图是一种有向图G = (N,E,entry,exit)。其中:
- N是节点集,每个节点对应程序中的一条语句、一个条件判断或一个控制流汇合点;
- 边集E = {<s1,s2> | s1,s2 ∈ N且s1执行后可能立即执行s2};
- entry和exit分别是控制流图的唯一入口节点和唯一出口节点;
控制流图是具有单一入口节点和出口节点的有向图。对于非单入口和单出口的程序,可以通过添加统一入口和出口的方法解决。控制流图的节点可以分为如下5类:
- entry节点:唯一的入口节点,具有0个前驱和1个后继;
- exit节点:唯一的出口节点,具有1个前驱和0个后继;
- 顺序节点:对应程序中的顺序执行语句,具有1个前驱和1个后继;
- 分支节点:对应程序中的条件判断,具有多个后继;
- 汇合节点:对应程序中的控制流汇合点,具有多个前驱;
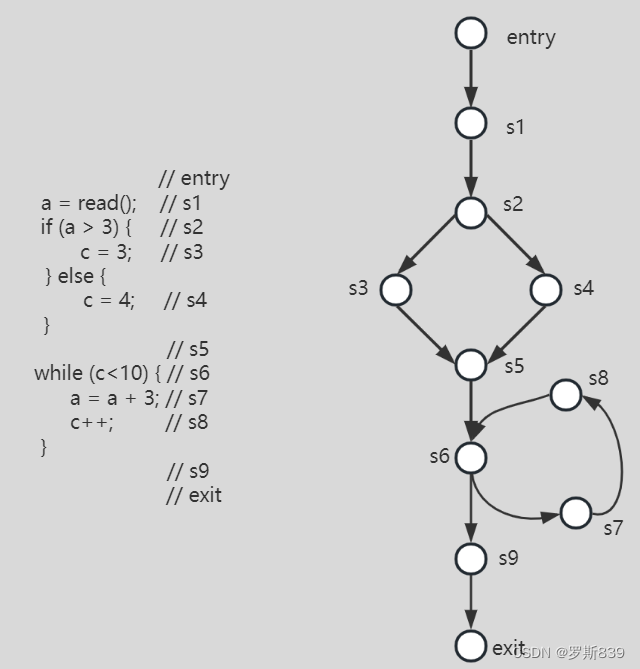
基本块
控制流分析都是基于控制流图的基本块(BB,basic block)来进行的。基本块是程序顺序执行的语句序列,只有一个入口和一个出口,入口是其中的第一个语句,出口是其中的最后一个语句。具体而言,只有一个入口表示程序中不会有其它任何地方能通过jump跳转类指令进入此基本块,只有一个出口表示只有该基本块的最后一条语句能导致进入其它基本块去执行。只要基本块中的第一条语句被执行了,那么该基本块内的所有语句都会被执行一次。
BB1:
t:=2 * x
y:=t + x
Goto BB2
如果从 BB1 的最后一条指令是跳转到 BB2,那么从 BB1 到 BB2 就有一条边。
一个函数(或过程)里如果包含多个基本块,可以以基本块为单位表达为一个 CFG。
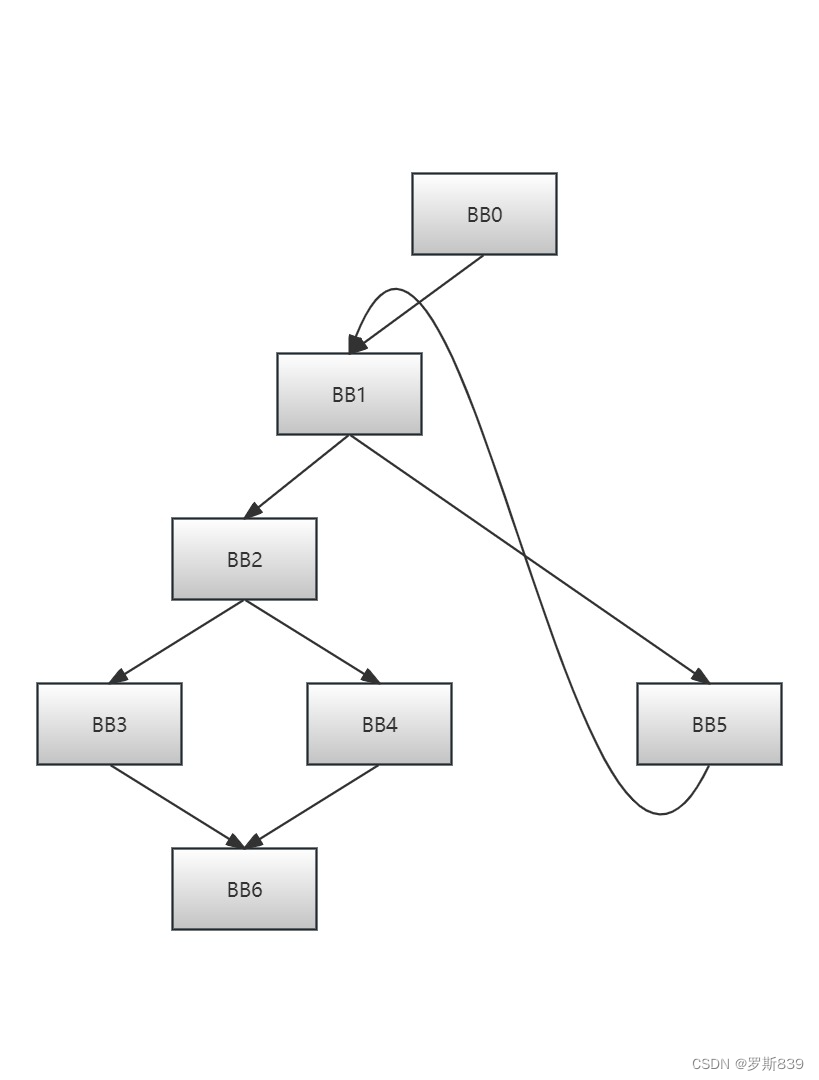
数据流分析
很多代码优化的场景都使用了数据流分析技术,比如代数优化、常数折叠、删除不可达的基本块等等。接下来,我们以代码优化中的“活跃性分析”为例,来简要说明数据流分析的一般过程,最后总结出数据流分析的一个统一框架。
活跃性分析
在代码优化中,活跃性分析(Liveness Analysis)是一种静态分析技术,用于确定程序中哪些变量在某个特定点上是“活跃”的,即这些变量在该点之后的代码中仍然会被使用。我们说一个变量是活的,意思是它的值在改变前,会被其他代码读取。
活跃性分析可以帮助编译器进行一些优化,比如死代码删除。如果一个变量在其后的程序中再也不会被使用,那么这个变量就可以被认为是“死的”(dead),编译器可以直接移除这些没有实际用处的变量。
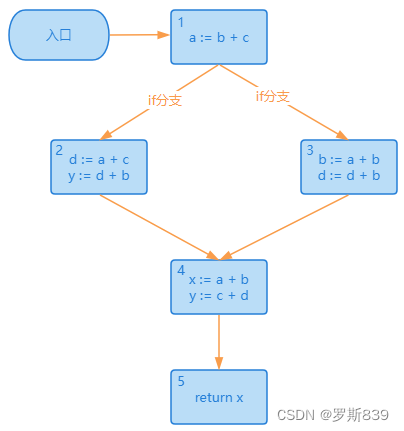
考虑上面的CFG,我们从最底下的基本块开始,倒着向前计算活跃变量的集合(也就是从基本块 5 倒着向基本块 1 计算)。这里需要注意,对基本块 1 进行计算的时候,它的输入是基本块 2 的输出,也就是{a, b, c},和基本块 3 的输出,也就是{a, c},计算结果是这两个集合的并集{a, b, c}。也就是说,基本块 1 的后序基本块,有可能用到这三个变量。这里在分支相遇时求输出的运算,即应用了之前讲过的格理论。
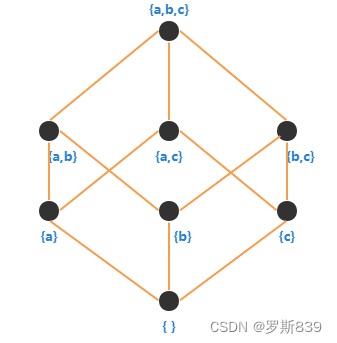
本质为计算上述格中两个节点的最小上界。你可能会奇怪,不就是集合运算吗?两个分支相遇,就计算它们的并集,不就可以了吗?事情没那么简单。因为并不是所有的数据流分析,每个语句计算后的结果都是一个集合,就算是集合,相交时的运算也不一定是求并集,而有可能是求交集。
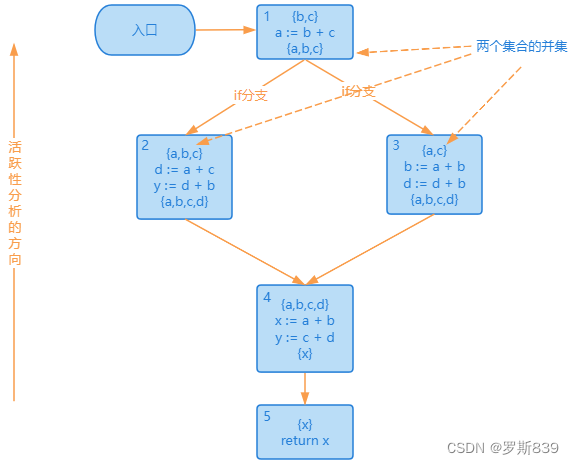
基于这个分析图,我们马上发现 y 变量可以被删掉(因为它前面的活变量集合{x}不包括 y,也就是不被后面的代码所使用),并且影响到了活跃变量的集合。
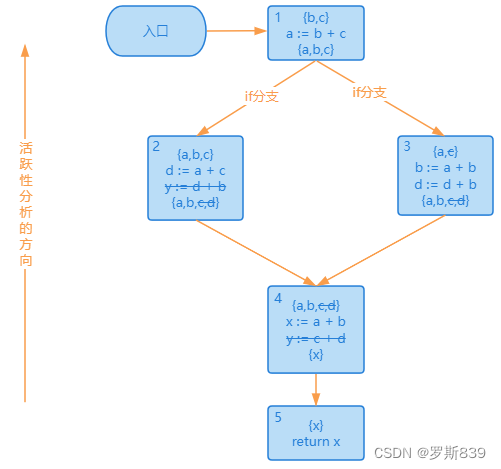
删掉 y 变量以后,从下向上再继续优化一轮,会发现 d 也可以删掉。
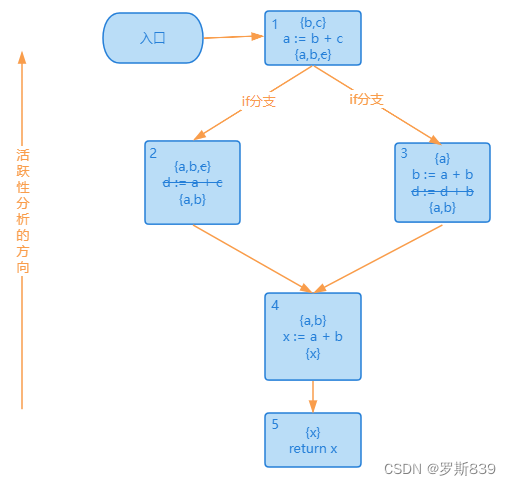
d 删掉以后,2 号基本块里面已经没有代码了,也可以被删掉,最后的 CFG 是下面这样:
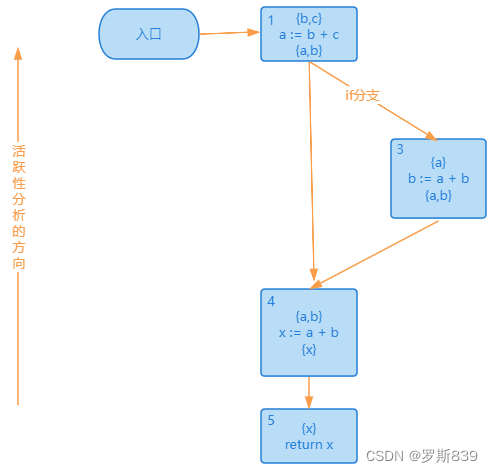
数据流分析框架
首先我们来总结一下上面的活跃性分析过程:
- 我们首先做一个从下向上的反向扫描,建立活变量的集合;
- 接着,我们从下向上分析每个活变量集合,识别出死变量,并依据它删除给死变量赋值的代码。
- 上述优化可能需要做不止一遍,才能得到最后的结果。
我们可以把上面的过程用更加形式化的方式表达出来。无论是活跃性分析,还是其它数据流分析方法,都可以看做是由下面 5个元素构成的:
- D(方向):是朝前还是朝后遍历。
- V(值):代码的每一个地方都要计算出一个值。活跃性分析的值是一个集合,也有些分析的值并不是集合,而是具体的取值。
- F(转换函数,对 V 进行转换):比如,在做活跃性分析的时候,基本块输入的活跃变量集合为{x},基本块内遇到x:=a+b,那么基本块的输出活跃变量集合变为{a,b}。这里遵守的转换规则是:因为变量x被重新赋值了,那么就从集合里,把变量x去掉,并把给x赋值的右侧表达式中用到的变量添加进集合。
- I(初始值,是算法开始时 V 的取值):在做活跃性分析的时候,初始值是后面代码中还会访问的变量,也就是活变量集合。
- Λ运算:在遇到分支的情况下,两个或多个分支相遇的时候,要做一个运算,计算他们相交的值。比如活跃性分析的场景下是求并集,其它分析可能是其它的运算。这里需要使用之前讲过的“格”理论进行计算。
总结
将数据流分析作为主要分析技术的漏洞分析系统常常具有分析速度快、精度良好等特点,因此非常适用于对大规模程序代码进行分析。
在使用数据流分析方法对程序继续分析时,我们总是一方面追求精确的分析,另一方面希望分析过程不会耗费大量的空间和时间。怎样在效率和精度上进行折中处理,是自始至终都要考虑的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!