Kafka集群架构原理(待完善)
2023-12-22 06:19:25
kafka在zookeeper数据结构
controller选举
客户端同时往zookeeper写入, 第一个写入成功(临时节点), 成为leader, 当leader挂掉, 临时节点被移除, 监听机制监听下线,重新竞争leader, 客户端也能监听最新leader
leader partition自平衡
leader不均匀时, 造成某个节点压力过大, 达到阈值时, 会触发自平衡, 均匀分配leader, 默认头节点
partition故障恢复机制
Leo:?每个Partition的最后一个Offset
HW:?一组Partiton中最小的LEO
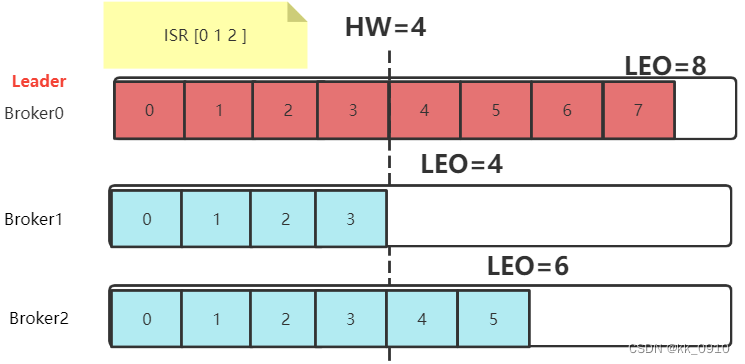
HW一致性保障
当Leader切换时, 可能产生HW不一致 ,Kafka设计Epoch保证HW一致性
文章来源:https://blog.csdn.net/weixin_64027360/article/details/135142854
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!