Mongodb复制集架构
目录
复制集架构
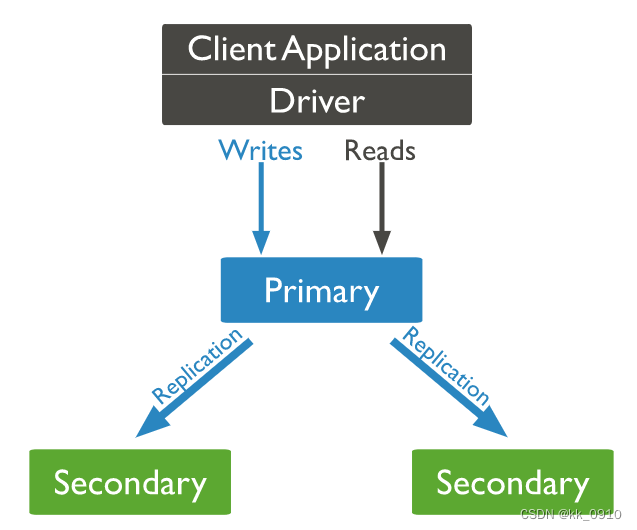
复制集优点
- 数据复制:?数据在Primary节点上进行写入,然后异步地复制到Secondary节点,确保数据冗余和高可用性。复制是通过Oplog(操作日志)来完成的,Secondary节点通过Oplog来复制Primary节点的操作。
- 读写分离:?应用程序可以将读操作分发给Secondary节点,实现读写分离,从而提高读取性能。
- 故障自动转移:?当Primary节点不可用时,复制集会自动选择一个Secondary节点升级为Primary节点,以保持服务的可用性。
复制集模式
1. PSS模式(推荐)
PSS模式由一个主节点和两个备节点所组成,Primary+Secondary+Secondary。
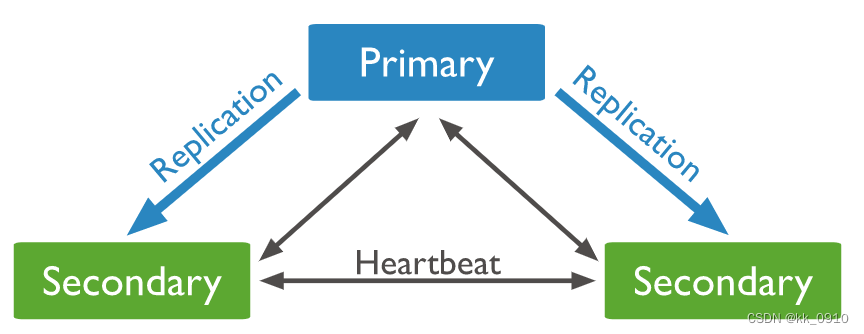
此模式提供数据集的两个完整副本,如果主节点不可用,则新选举出备节点作为主节点并继续正常操作。旧的主节点在可用时重新加入复制集。
2. PSA
PSA模式由一个主节点、一个备节点和一个仲裁者节点组成,即Primary+Secondary+Arbiter
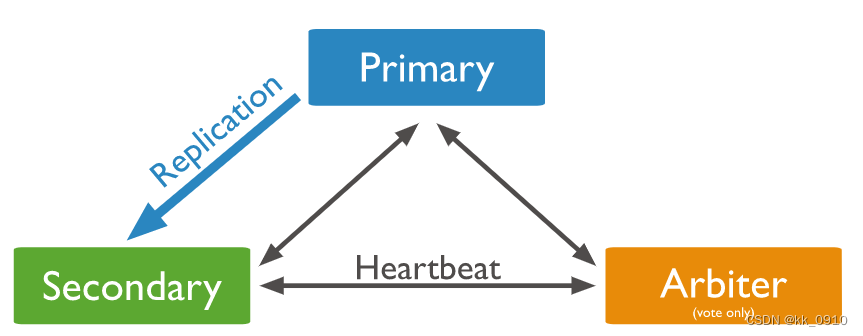
Arbiter节点不存储数据副本,也不提供业务的读写操作。Arbiter节点发生故障不影响业务,仅影响选举投票。此模式仅提供数据的一个完整副本,如果主节点不可用,则复制集将选择备节点作为主节点。
复制集搭建
1. 下载mongo安装包, 解压
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-6.0.5.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-6.0.5.tgz2. 分别建db1,db2,db3三个目录, 存放conf配置文件以及数据, 编辑配置文件, 三个文件夹下面分别修改path,dbPath,port
vim ../data/db1/mongod.confsystemLog:
destination: file
path: /home/kk/local/mongodb-linux-x86_64-rhel70-6.0.5/data/db1/mongod.log # log path
logAppend: true
storage:
dbPath: /home/kk/local/mongodb-linux-x86_64-rhel70-6.0.5/data/db1 # data directory
net:
bindIp: 0.0.0.0
port: 28017 # port
replication:
replSetName: rs0
processManagement:
fork: true3. 配置mongo环境变量, 方便后面启动
export PATH=/home/kk/local/mongodb-linux-x86_64-rhel70-6.0.5/bin:$PATH4. 启动三个mongo实例
mongod -f ./data/db1/mongod.conf
mongod -f ./data/db2/mongod.conf
mongod -f ./data/db3/mongod.conf
5. 下载mongosh连接客户端
wget https://downloads.mongodb.com/compass/mongodb-mongosh-1.8.0.x86_64.rpm
yum install -y mongodb-mongosh-1.8.0.x86_64.rpm6. 用mongosh连接, 并初始化复制集
# 连接客户端
mongosh --port 28017
# 初始化复制集
rs.initiate({
_id: "rs0",
members: [{
_id: 0,
host: "192.168.6.128:28017"
},{
_id: 1,
host: "192.168.6.128:28018"
},{
_id: 2,
host: "192.168.6.128:28019"
}]
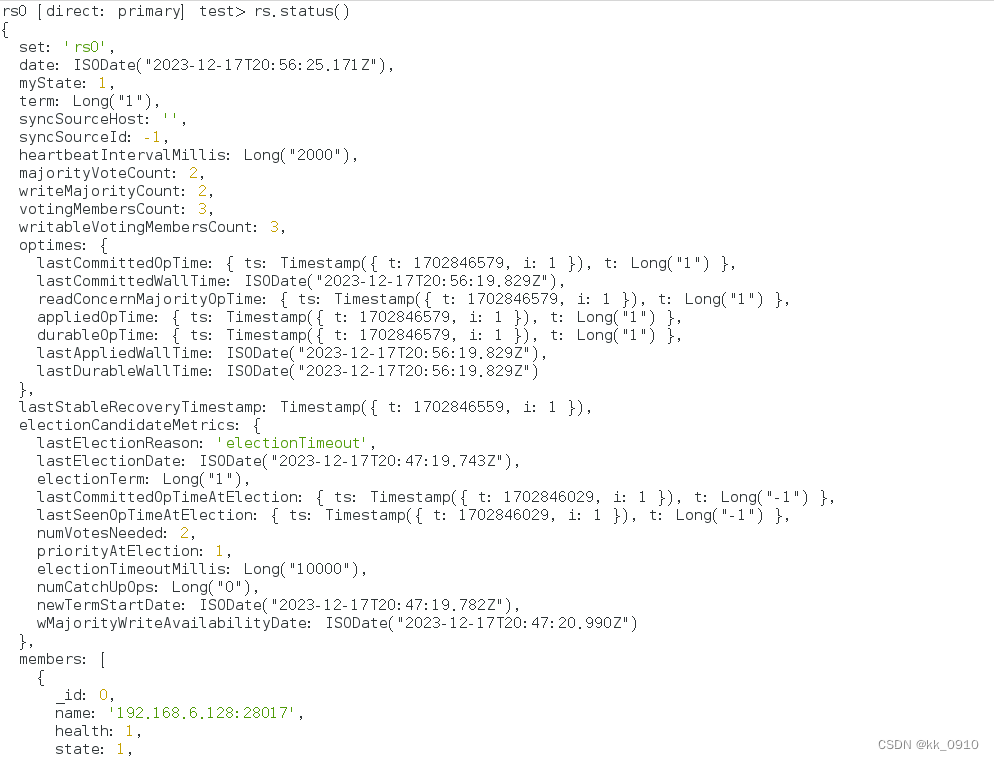
})7. 验证集群状态,?rs.status()
复制集常用命令
# 客户端执行
rs.help()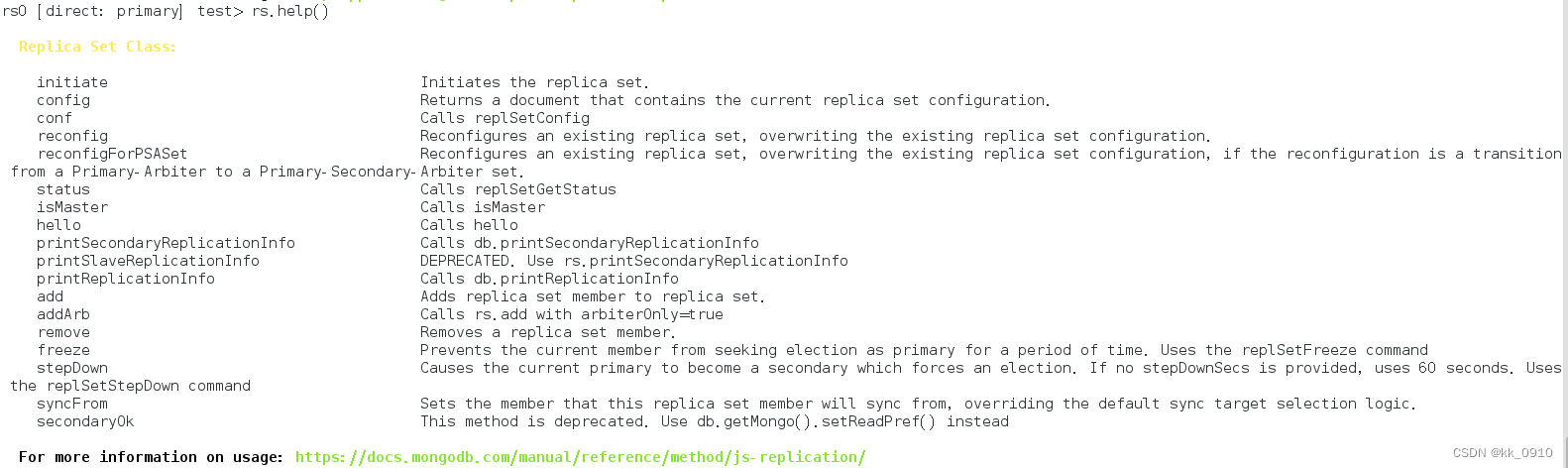
| 命令 | 描述 |
| rs.add() | 为复制集新增节点 |
| rs.addArb() | 为复制集新增一个?arbiter |
| rs.conf() | 返回复制集配置信息 |
| rs.freeze() | 防止当前节点在一段时间内选举成为主节点 |
| rs.help() | 返回?replica set?的命令帮助 |
| rs.initiate() | 初始化一个新的复制集 |
| rs.printReplicationInfo() | 以主节点的视角返回复制的状态报告 |
| rs.printSecondaryReplicationInfo() | 以从节点的视角返回复制状态报告 |
| rs.reconfig() | 通过重新应用复制集配置来为复制集更新配置 |
| rs.remove() | 从复制集中移除一个节点 |
| rs.secondaryOk() | 为当前的连接设置?从节点可读 |
| rs.status() | 返回复制集状态信息。 |
| rs.stepDown() ? | 让当前的?primary?变为从节点并触发?election |
| rs.syncFrom() | 设置复制集节点从哪个节点处同步数据,将会覆盖默认选取逻辑 |
复制集增删节点?
1. 通过remove删除节点
# 1. 进入要删除的节点, 关闭该实例
db.shutdownServer()
# 2.连接主节点,执行remove
rs.remove("ip:port")2. 通过reconfig, 修改节点
cfg = rs.conf()
cfg.members[0].host = "ip:port"
rs.reconfig(cfg)复制集选举
MongoDB的复制集选举使用Raft算法(Raft Consensus Algorithm)来实现,选举成功的必要条件是大多数投票节点存活。
另外,MongoDB对raft协议添加了一些自己的扩展:
- 支持chainingAllowed链式复制,即备节点不只是从主节点上同步数据,还可以选择一个离自己最近(心跳延时最小)的节点来复制数据。
- 增加了预投票阶段,即preVote,这主要是用来避免网络分区时产生Term(任期)值激增的问题
- 支持投票优先级,如果备节点发现自己的优先级比主节点高,则会主动发起投票并尝试成为新的主节点。
当复制集内存活的成员数量不足大多数时,整个复制集将无法选举出主节点,此时无法提供写服务,这些节点都将处于只读状态。此外,如果希望避免平票结果的产生,最好使用奇数个节点成员。在MongoDB复制集的实现中,对于平票问题提供了解决方案:
- 为选举定时器增加少量的随机时间偏差,这样避免各个节点在同一时刻发起选举,提高成功率。
- 使用仲裁者角色,该角色不做数据复制,也不承担读写业务,仅仅用来投票。
复制集同步

在复制集架构中,主节点与备节点之间是通过oplog来同步数据的,oplog是local库的一个集合,当主节点上的一个写操作完成后,会向oplog集合写入一条对应的日志,而从节点通过这个oplog不断拉取到新的日志,在本地进行回放以达到数据同步的目的。?
oplog分析
什么是oplog
- MongoDB oplog 是 Local 库下的一个集合,用来保存写操作所产生的增量日志(类似于 MySQL 中 的 Binlog)。
- 它是一个 Capped Collection(固定集合),即超出配置的最大值后,会自动删除最老的历史数据,MongoDB 针对 oplog 的删除有特殊优化,以提升删除效率。
- 主节点产生新的 oplog数据,从节点通过复制 oplog 来保证和主节点的状态一致
查看oplog?
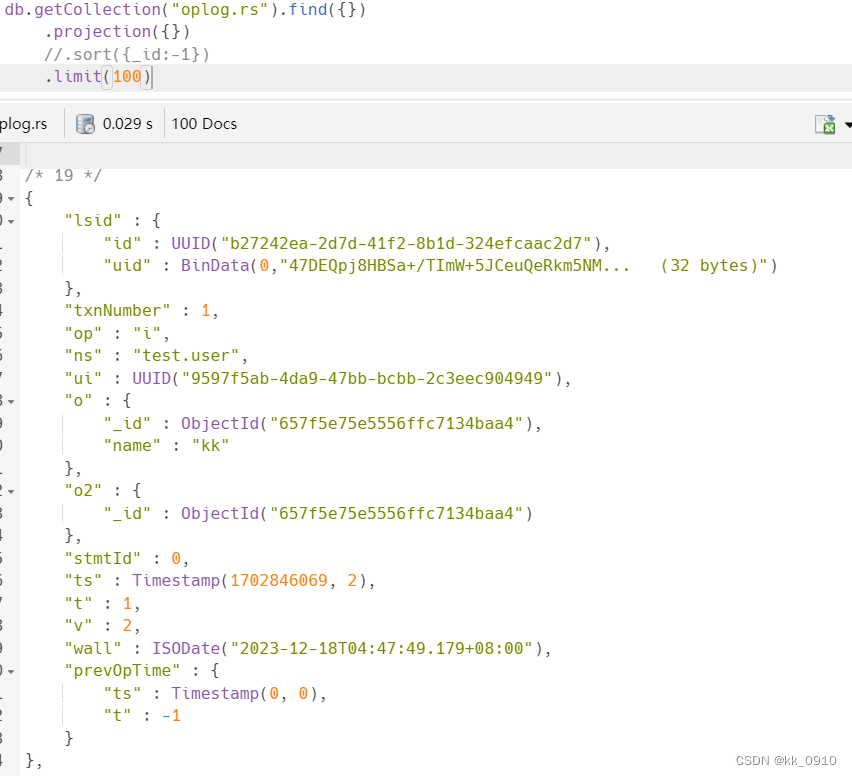
ts: 操作时间,当前timestamp + 计数器,计数器每秒都被重置
v:oplog版本信息
op:操作类型:
i:插?操作
u:更新操作
d:删除操作
c:执行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作针对的集合
o:操作内容
o2:操作查询条件,仅update操作包含该字段
?oplog大小
oplog如果设置太小, 主从同步延迟严重时, 容易覆盖老的oplog, 造成数据丢失, 所以通常需要修改默认的oplog大小(默认90M)
# oplog大小修改为60g
db.adminCommand({replSetResizeOplog: 1, size: 60000})
# 查看oplog大小
db.oplog.rs.stats().maxSize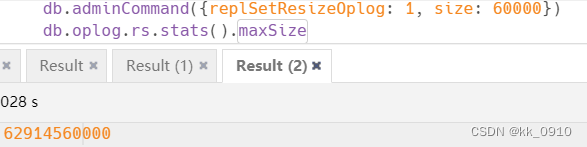
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!