torch中张量与数据类型的介绍
PyTorch张量的定义介绍
PyTorch最基本的操作对象是张量,它表示一个多维数组,类似NumPy的数组,但是前者可以在GPU上加速计算
初始化张量
t=torch.tensor([1,2]) # 创建一个张量
print(t)
t.dtype #打印t的数据类型为torch.int64
如果直接从Python数据创建张量,无须指定类型,PyTorch会自动推荐其类型,可通过张量的dtype属性查看其数据的类型,与numpy中的语法很相似
#创建float类型
t=torch.FloatTensor([1,2])
print(t)
print(t.dtype)
# 创建int类型的数据
t=torch.LongTensor([1,2])
print(t)
print(t.dtype)
也可以使用torch.from_numpy()方法从NumPy数组ndarray创建张量。
np_array=np.array([[1,2],[3,4]])
t_np=torch.from_numpy(np_array.reshape(1,4)).type(torch.FloatTensor)
print(t_np)
print(t_np.dtype)
首先我们能够看得到np_array依然是numpy的对象数据,依旧可以使用reshape等相关的方法
我们可以使用torch.from_numpy()方法在numpy数组上创建张量
t=torch.tensor([1,2],dtype=torch.int64)
print(t)
print(t.dtype)
t=torch.tensor([1,2],dtype=torch.float32)
print(t)
print(t.dtype)
这里用的最多的两种类型为int64,float32,这两种类型也尝尝被表示为torch.long和torch.float,其实这两种了类型对应了两种创建张量的方法,分别为
torch.FloatTensor()和torch.LongTensor()
#三种方法创建int64类型的数据
#1.
t1=torch.LongTensor([1,2])
print(t1)
print(t1.dtype)
#2.
t2=torch.tensor([1,2],dtype=torch.long)
print(t2)
print(t2.dtype)
#3.
t3=torch.tensor([1,2],dtype=torch.int64)
print(t3)
print(t3.dtype)
#三种方法创建float32类型的数据
#1.
t1=torch.FloatTensor([1,2])
print(t1)
print(t1.dtype)
#2.
t2=torch.tensor([1,2],dtype=torch.float)
print(t2)
print(t2.dtype)
#3.
t3=torch.tensor([1,2],dtype=torch.float32)
print(t3)
print(t3.dtype)
那他们确实是相等的吗,我们用代码来实现一下
print(torch.float==torch.float32)#判断是否相等,结果放回为true
print(torch.long==torch.int64)
PyTorch中张量的类型可以使用type()方法进行转换
t=torch.tensor([1,2],dtype=torch.float)
print(t.dtype)
#使用type()方法进行数据类型转化
t=t.type(torch.int64)
print(t.dtype)
torch框架中提供了两个快捷的实力转换方法
t=torch.tensor([1,2],dtype=torch.float)
print(t.dtype)
t=t.long()#使用long()将float32数据转换类int64的数据类型
print(t.dtype)
t=t.float()
print(t.dtype)
创建随机值张量
t=torch.rand(2,3)#创建一个2列3行的0-1均匀分布的随机数
print(t)
t=torch.randn(2,3)#创建一个2列3行的标准正态分布随机数
print(t)
t=torch.zeros(3,3)#创建一个3行3列的全是0的张量
print(t)
t=torch.ones(3,2)#创建一个3行2列的全是1的张量
print(t)
t=torch.ones(3,3,3)#创建三维的数组,就只需要传入3个数据进入就行
print(t)
x=torch.zeros_like(t) #类似的方法还有torch.ones_like()
print(x)
x=torch.rand_like(t)
print(x)
张量的属性
t=torch.ones(2,3,dtype=torch.float32)
print(t.shape)
print(t.size())
print(t.size(0))
print(t.dtype)
print(t.device)
将张量移动到显存
张量可以在cpu上运行,也可以在GPU上运行,在GPU上的运算速度通常高于CPU,默认是在CPU上创建张量,如下可以使用tensor.to()方法将张量移动到GPU上
# 如果GPU可用,将张量移动到显存
if torch.cuda.is_available():
t=t.to('cuda')
print('true')
print(t.device)
#一般使用如下代码获取当前可用设备
device="cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
t=t.to(device)
print(t.device)
张量的运算
t1=torch.randn(2,3)
t2=torch.ones(2,3)
print(t1)
print(t2)
print(t1+3) # t1中每一个元素都加3
print(t1+t2) #t1与t2中每一个相同位置的元素相加 #不能将不同维数的张量相加,张量当中也有一个广播机制存在
张量加法运算
t3=torch.ones(1,3)
print(t3)
print(t1+t3)
t4=torch.randn(2,3)
t5=torch.ones(2,3)
print(t4)
print(t5)
t4.add_(t5)
print(t4)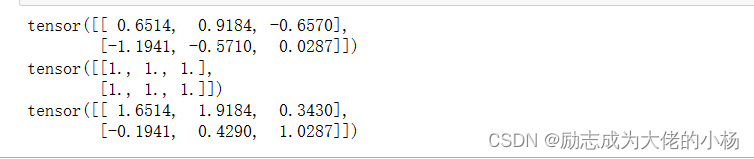
如果一个运算方法后面加上下划线,代表就地改变原值,即上方中的t1.add_(t2)会直接将运算结果保存为t1,这样做可以节省内存,但是缺点就是会直接改变t1原值,在使用此方法的时候一定要谨慎使用。
矩阵乘法
print(t5.T)
print(t4.matmul(t5.T)) # matmul中没有下划线的方法
print(t4 @ (t5.T)) #都是对t1和t2的转置进行矩阵乘法
tensor.item
#输出一个python浮点数
print(t3)
print(t3.item())
#首先将张量中的所有的元素求和,得到只有一个元素的张量,然后使用tensor.item()方法将其转换为标量
#这种转换在我们希望打印模型正确率和损失值的时候很常见![]()
与numpy数据类型的转换
a=np.random.randn(2,3) #创建一个形状为(2,3)的ndarray对象
print("ndarray为:\n",a)
t=torch.from_numpy(a) #使用torch.from_numpy创建一个ndarray创建一个张量
print("tensor为:\n",t)
print("numpy所对应的ndarray为:\n",t.numpy()) #使用torch.numpy()方法获得张量对应的ndarray
张量的变形
tensor.size()和tensor.shape属性可以返回张量的形状,方需要改变张量的形状时,可以通过tensor.view()方法,这个方法相当于NumPy中的reshape方法,用于改变张量的形状,但是在转换的过程中,一定要确保元素数量一致。
t=torch.randn(4,6,dtype=torch.float32)
print(t)
print(t.shape)
t1=t.view(3,8)
print(t1)
print(t1.shape)
t1=t.view(-1,1)
print(t1)
如果想展成横着的一维,就默认让view(1,-1)中设置1
t1=t.view(1,-1)
print(t1)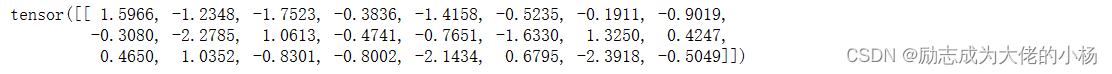
# 也可以使用view增加维度,当然元素个数是不变的
t1=t.view(1,4,6)
print(t1)
print(t1.shape)
对于维度长度为1的张量,可以使用torch.squeeze()方法去掉长度为1的维度,相应的也有一个增加长度为1维度的方法,即torch.unsqueeze()
print(t1.shape)
print(t1)
t2=torch.squeeze(t1)
print(t2.shape)
print(t2)
t3=torch.unsqueeze(t2,0)
print(t3.shape)
print(t3)
张量的自动微分
在PyTorch中,张量有一个requires_grad属性可以在创建张量时指定此属性为True,如果requires_grad属性被设置为True,PyTorch将开始跟踪对此张量的所有计算,完成计算,可以对计算记过调用backward()方法,PyTorch将自动计算所有梯度。该张量的梯度将累加到张量的grad属性中,张量的grad_fn属性则指向运算生成此张量的方法。
张量的requires_grad属性用来明确是否跟踪张量的梯度,grad属性表示计算得到的梯度,grad_fn属性表示运算得到生成此张量的方法。
t=torch.ones(2,2,requires_grad=True) # 这里将requires_grad设为True
print(t)
print(t.requires_grad) # 输出是否跟踪计算张量梯度,输出True
print(t.grad) #输出tensor.grad输出张量的梯度,输出为None,表示目前t没有梯度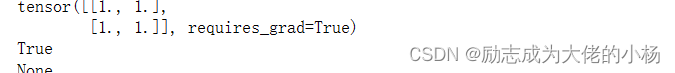
接下来进行张量运算,得到y
y=t+5
print(y)
print(y.grad_fn)
print(y.grad)
# 进行其他运算
z=y*2
out=z.mean()
print(out)![]()
上面的代码中,首先创建了张量,并指定requires_grad属性为True,目前其grad和grad_fn属性均为空。然后经过加法、乘法和取均运算,我们得到了out这个最终结果,注意,现在out只有单个元素,它是一个标量。下面在out上执行自动微分运算,并且输出t的梯度(d(out)/d(x))
out.backward()
print(t.grad)
print(t.requires_grad)
print((t+2).requires_grad)![]()
# 将代码块包装在with torch.no_grad():上下文中
with torch.no_grad():
print((t+2).requires_grad) # PyTorch没有继续跟踪此张量的运算
也可以使用tensor.detach()方法获得具有相同内容但是不需要跟踪运算的新张量,可以认为是获得张量的值
print(out.requires_grad)
s=out.detach() # 获得out的值,也可以使用out.data()方法
print(s.requires_grad)

可以使用requires.grad_()方法就地改变张量的这个属性,当我们希望模型的参数不在随着训练变化时,我们可以使用此方法
print(t.requires_grad)
t.requires_grad_(False)
print(t.requires_grad)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!