数据预处理系列: One hot编码原理和案例
数据预处理系列: One hot编码原理和案例
# 导入Image模块用于显示图片
from IPython.display import Image
# 图片来源链接
# https://www.pexels.com/pl-pl/zdjecie/fotografia-sztucznych-ogni-60726/

# 导入matplotlib库中的pyplot模块,并将其命名为plt
from matplotlib import pyplot as plt
# 导入seaborn库
import seaborn as sns
为了适应机器学习算法,在构建模型之前,您必须将分类(非数值)变量转换为数值特征。这个过程被称为分类数据编码。有不同的编码技术可供选择,但最常见和广泛使用的是独热编码。
有两种常用的方法:scikit-learn的OneHotEncoder(OHE)和Pandas的get_dummies方法。
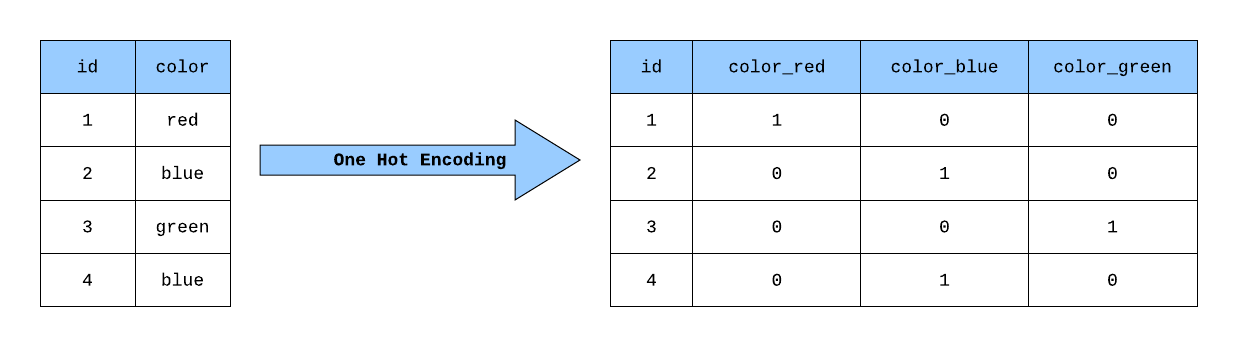
1.1 One Hot Encoder vs get_dummies
get_dummies是一种更方便的方法,可能这就是为什么它是一种流行的方法。
真正的问题是:如何处理在生产中出现的未知分类特征。如果分类列中的唯一值总数在我们的训练集和测试集中不相同,我们将会遇到问题。OneHotEncoder是一个转换器类,因此它可以适应数据。一旦适应完成,它就能根据学习到的类别来转换验证数据。
总的来说,One Hot Encoder和get_dummies都是将分类变量转换为二进制矩阵的方法,但它们在实现细节上有所不同。根据具体的需求和使用场景,可以选择适合的方法来处理分类变量。
基本上,get_dummies可以用于探索性分析,而OneHotEncoder用于计算和估计。
1.2 虚拟变量陷阱:是否要删除?
当处理分类特征时,一个常见的惯例是从每个特征中删除一个新列。这个论点来自统计学:如果不删除一列,我们知道这些列的总和在每一行中都是1。例如,将性别编码为两个变量,is_male和is_female,会产生两个完全负相关的特征。这被称为虚拟变量陷阱:预测变量之间存在完全多重共线性。
如果我们决定删除第一列,算法会删除集合中按字母数字顺序排列的第一个类别值名称。在性别的例子中,第一列将是Female,因为F在M之前。
- 删除第一列的想法在存在完全共线特征导致问题的情况下非常有用,例如将结果数据输入到非正则化线性模型中。然而,机器学习的原则是构建一个高度预测的模型。因此,我们很少利用非常简单的模型,通常会应用正则化。
1.3 在独热编码过程中删除列的可能缺点
-
在文档中我们可以读到:“删除一个类别会破坏原始表示的对称性,因此可能会对下游模型产生偏差,例如对于惩罚线性分类或回归模型。”
-
还有一个问题。仔细查看OneHotEncoder的参数‘first’。通过查阅文档,我们可以读到:“删除每个特征中的第一个类别。如果只有一个类别存在,则整个特征将被删除。”因此,可能会删除整列数据,但前提是该列只有一个类别。
- 我们可以认为在这种情况下,该特征无论如何都不是有用的,但是考虑到一种情况,即我们必须处理测试集(和生产环境)中存在但训练集中不存在的新条目。例如,我们在训练集中可能只有关于女性的条目。如果我们不删除一列,自然的做法是在那里放置所有的零(即男性不属于我们见过的任何性别)。如果我们删除了一列(比如"男性"),那么就没有办法对新变量进行编码了。一个合理的折中方案可能是添加另一列称为"其他",如果我们想避免虚拟陷阱,可以删除该列。
1.4 基于决策树的模型与独热编码
决策树及其衍生算法(包括回归树和随机森林等集成算法)比任何算法家族(神经网络、支持向量机、基于距离的算法)更好地处理分类变量,除了贝叶斯方法。它们也对未经高度预处理的分类变量具有鲁棒性。为了理解它的工作原理,可以通过这样的观点建立直觉,即决策树几乎像是将所有特征视为分类变量,并以自由的方式处理连续值,只看顺序。
理论上,我们甚至不需要将分类特征转换为整数,但scikit-learn不支持使用分类变量,因此将它们转换为整数是强制性的。
- 基于树的模型通常不适用于具有大量级别的独热编码。这是因为它们的工作原理是增加下一级别的同质性。如果我们有很多级别,那么只有很小一部分数据(通常)会属于任何给定的级别,因此独热编码的列将主要是零。由于在这一列上进行分割只会产生很小的增益,基于树的算法通常会忽略这些信息,而选择其他列。
1.5 独热编码 vs 非常多的分类特征
One-Hot编码
如果类别的数量非常高,则不应执行One-Hot编码。这将导致数据稀疏。根据使用情况,我们需要进行一些探索性数据分析来进行一些特征工程。
因此:
- 行数应至少是特征数的5倍。
- 对于基于树的模型,尽量保持特征的层级数小于5。
如果层级数较大,您可能会更适合使用不同的编码方案。特征工程是构建有效模型最重要的方面。
1.5.1 将级别分组在一起
- 不必处理各种树木类型,可以引入类别:针叶树和落叶树。
- 不必处理街道,可以引入行政区:曼哈顿、布鲁克林、皇后区、布朗克斯和斯塔滕岛。
1.5.2 创建"其他"列
例如:您在欧盟经营一家电子商务企业,您的客户来自所有成员国,但德国占60%,法国占25%,波兰占10%,其余24个国家占5%。
在这种情况下,使用MState_GE、MState_FR、MState_PL、MState_OTHER这样的编码是有意义的。
1.6 管道和独热编码
Pandas get_dummies与Scikit-learn流水线不兼容。
Pandas的get_dummies方法与Scikit-learn的流水线不兼容。OneHotEncoder与scikit-learn的转换器API相匹配,因此它与流水线兼容,并且易于使用以方便我们的操作。
1.7 独热编码 - 在训练集和测试集拆分之前还是之后?
我们在对训练集进行模型拟合并在不同形状的测试特征上进行预测时会遇到错误。
这就是为什么很多人建议在训练集和测试集分离之前进行独热编码。
通常情况下,你应该将测试集视为在训练过程中没有的数据。在分离之前进行编码会导致数据泄露(训练集和测试集的污染)。例如,测试集可能包含一个或多个在训练集中不存在的类别。这在实际应用中经常发生。
然而,如果目标是探索性数据分析,可以在将数据分成训练集和测试集之前进行独热编码。
1.8 最佳实践
- Scikit-learn的OneHotEncoder比Pandas的get_dummies在机器学习中更好。您仍然可以利用Pandas的get_dummies进行数据准备和探索性数据分析。
- 在进行训练集和测试集划分之前,应该进行独热编码以避免数据泄漏(训练集和测试集污染)。
- 当输出标签的数量很大时,独热编码的效果不好。例如,在语言建模中,输出标签的数量非常大。这意味着在进行独热编码后,我们将得到大量的特征。
- 无论我们有多少数据,基于树的模型在级别很多的情况下都会遇到困难。
- 线性模型可以处理大量级别,前提是我们有足够的数据来准确估计系数。
- 如果您正在对特征进行独热编码,则可以利用特征工程来减少输出的数量,以提高模型的效果。
- 在某些情况下,删除第一列的想法很有用,特别是当完全共线的特征导致问题时,例如将生成的数据输入到未正则化的线性模型中时。
- 在进行独热编码后,每个向量与其他向量的距离相等。在某些情况下,分布式表示可以捕捉到更重要的信息(例如用于NLP任务)。
1.9 简单示例
import pandas as pd
# 创建一个空的DataFrame对象data,其中包含一个Series对象,该Series对象包含三个值:'red','green','blue'
data=pd.DataFrame(pd.Series(['red','green','blue']))
# 创建一个空的DataFrame对象new_data,其中包含一个Series对象,该Series对象包含五个值:'red','green','blue','yellow','purple'
# new_data比data多出两个值
new_data= pd.DataFrame(pd.Series(['red','green','blue','yellow','purple']))
1.9.1 使用 get_dummies
# 使用pd.get_dummies()函数对data进行独热编码,并将结果赋值给gd_df
gd_df = pd.get_dummies(data)
# 打印gd_df
print(gd_df)
0_blue 0_green 0_red
0 0 0 1
1 0 1 0
2 1 0 0
get_dummies 返回一个 DataFrame。
# 将gd_df的列名转换为列表
col_list = gd_df.columns.tolist()
# 对new_data进行独热编码
new_df = pd.get_dummies(new_data)
# 处理未知数据,使用.reindex和.fillna()方法
# .reindex方法将new_df的列名按照col_list重新排序
# .fillna方法将NaN值填充为0
new_df = new_df.reindex(columns=col_list).fillna(0)
# 打印处理后的new_df
print(new_df)
0_blue 0_green 0_red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 0
4 0 0 0
1.9.2 使用OneHotEncoder
# 导入OneHotEncoder类
from sklearn.preprocessing import OneHotEncoder
# 创建OneHotEncoder对象,设置handle_unknown参数为"ignore",表示在转换过程中忽略未知的特征值
# 设置sparse参数为False,表示返回的结果是一个密集矩阵
ohe = OneHotEncoder(handle_unknown="ignore", sparse=False)
# 使用OneHotEncoder对象对数据进行拟合,以获取特征值的编码规则
ohe.fit(data)
# 使用OneHotEncoder对象对新的数据进行转换,将特征值转换为编码后的形式
ohe.transform(new_data)
array([[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
OneHotEncoder 返回一个类似数组的编码数据对象,可以后续转换为密集矩阵或数据框。
2.1 导入库
# 导入所需的库
import numpy as np
import pandas as pd
import seaborn as sns
import plotly.express as px
import tkinter
from matplotlib import pyplot as plt
from sklearn.model_selection import cross_val_score
from collections import Counter
# 这段代码没有需要添加的注释,只是导入了所需的库。
2.2 导入数据
# 尝试从指定路径读取csv文件,如果路径不存在,则从默认路径读取
try:
raw_df = pd.read_csv('/kaggle/input/telco-customer-churn/WA_Fn-UseC_-Telco-Customer-Churn.csv')
# 如果指定路径不存在,则从默认路径读取csv文件
except:
raw_df = pd.read_csv('telco.csv')
2.3 数据集特征
每一行代表一个客户,每一列包含在该列元数据中描述的客户属性。
数据集包括以下信息:
- 最近一个月内离开的客户 - 该列称为流失。
- 每个客户签约的服务 - 电话、多行、互联网、在线安全、在线备份、设备保护、技术支持以及流媒体电视和电影。
- 客户账户信息 - 他们成为客户的时间、合同、付款方式、无纸化账单、月费用和总费用。
- 关于客户的人口统计信息 - 性别、年龄范围以及是否有伴侣和家属。
数据集中没有缺失值。
2.4 数据集属性
-
customerID- 客户ID -
gender- 客户的性别,男性或女性 -
SeniorCitizen- 客户是否为老年人(1,0) -
Partner- 客户是否有伴侣(是,否) -
Dependents- 客户是否有家属(是,否) -
tenure- 客户在公司停留的月数 -
PhoneService- 客户是否有电话服务(是,否) -
MultipleLines- 客户是否有多条线路(是,否,无电话服务) -
InternetService- 客户的互联网服务提供商(DSL,光纤,无) -
OnlineSecurity- 客户是否有在线安全服务(是,否,无互联网服务) -
OnlineBackup- 客户是否有在线备份服务(是,否,无互联网服务) -
DeviceProtection- 客户是否有设备保护服务(是,否,无互联网服务) -
TechSupport- 客户是否有技术支持服务(是,否,无互联网服务) -
StreamingTV- 客户是否有流媒体电视服务(是,否,无互联网服务) -
StreamingMovies- 客户是否有流媒体电影服务(是,否,无互联网服务) -
Contract- 合同类型(按月付费,一年,两年) -
PaperlessBilling- 客户是否使用电子账单(是,否) -
PaymentMethod- 支付方式(电子支票,邮寄支票,银行转账(自动),信用卡(自动)) -
MonthlyCharges- 客户当前每月订阅费用 -
TotalCharges- 客户迄今为止支付的总费用 -
Churn- 表示客户是否流失
# 创建一个颜色调色板用于绘图
palette = ['#008080','#FF6347', '#E50000', '#D2691E']
我们不需要一个customerID列,所以我将删除它。
# 从原始数据框中删除'customerID'列
df = raw_df.drop('customerID', axis=1)
3.1 处理TotalCharges中的缺失值
# 将df中的'TotalCharges'列转换为浮点型数据类型
df['TotalCharges'] = df['TotalCharges'].astype(float)
在尝试执行上面的代码时发生了错误:无法将字符串转换为浮点数:‘’。
要转换的字符串不能包含任何字符或符号。错误是由于将值错误地初始化为字符串变量而导致的。
我们可能在’TotalCharges’列中有空字符串,但由于它们被定义为字符串,它们并没有显示为Null值。
# 统计每个'TotalCharges'元素的单词数量
step1 = [len(i.split()) for i in df['TotalCharges']]
# 存储'TotalCharges'中长度不等于1的元素的索引值
step2 = [i for i in range(len(step1)) if step1[i] != 1]
# 打印'TotalCharges'中空字符串的条目数量
print('空字符串的条目数量:', len(step2))
Number of entries with empty string: 11
我们可以尝试通过建立一个模型来填补缺失值,或者使用一些常用的值来填充,比如平均值、中位数或众数,但是由于空字符串的数量非常少(11个),所以直接从数据集中删除相应的行可能更简单(也可能更好)。
# 从数据框中删除具有空值的行
df = df.drop(step2, axis = 0).reset_index(drop=True)
# 将'TotalCharges'列的数据类型转换为浮点型
df['TotalCharges'] = df['TotalCharges'].astype(float) # Finally we can convert string to float in 'Total_charges' column
3.2 处理重复值
# 打印训练数据集中重复值的数量
print('Number of duplicated values in training dataset: ', df.duplicated().sum())
Number of duplicated values in training dataset: 22
# 删除重复值
df.drop_duplicates(inplace=True)
# 打印删除成功的提示信息
print("Duplicated values dropped succesfully")
# 打印分隔线
print("*" * 100)
Duplicated values dropped succesfully
****************************************************************************************************
3.3 创建数字和分类列表
# 将DataFrame的列名存储在列表columns中
columns = list(df.columns)
# 创建两个空列表,用于存储分类变量和数值变量的列名
categoric_columns = []
numeric_columns = []
# 遍历每个列名
for i in columns:
# 如果该列的唯一值数量大于6,则将其列名添加到数值变量列表中
if len(df[i].unique()) > 6:
numeric_columns.append(i)
# 否则将其列名添加到分类变量列表中
else:
categoric_columns.append(i)
# 由于最后一个分类变量是目标变量,所以将其从列表中移除
categoric_columns = categoric_columns[:-1]
# 打印数值特征列
print('Numerical fetures: ',numeric_columns)
# 打印分类特征列
print('Categorical fetures: ',categoric_columns)
Numerical fetures: ['tenure', 'MonthlyCharges', 'TotalCharges']
Categorical fetures: ['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
4.1 训练测试拆分 - 分层拆分
分层拆分意味着在生成训练/验证数据集拆分时,它将尝试保持每个拆分中类别的相同百分比。
这些数据集的划分通常是根据目标变量随机生成的。然而,在这样做时,不同拆分中目标变量的比例可能会有所不同,尤其是在小数据集的情况下。
# 从数据框中删除'Churn'列,得到特征矩阵X
X = df.drop('Churn', axis=1)
# 从数据框中获取'Churn'列,得到目标向量y
y = df['Churn']
# 导入train_test_split函数用于划分训练集和测试集
from sklearn.model_selection import train_test_split
# 使用train_test_split函数划分数据集
# 参数X表示特征数据集,y表示目标数据集
# 参数stratify=y表示按照目标数据集y的类别比例进行分层抽样
# 参数test_size=0.25表示将数据集划分为训练集和测试集,其中测试集占总数据集的25%
# 参数random_state=42表示设置随机种子,保证每次划分的结果一致
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.25, random_state=42)
请查看此笔记本以获取有关处理不平衡数据集的**更多信息和最佳技术和指标**:处理不平衡数据集的最佳技术和指标
4.2 特征缩放
# 导入StandardScaler类
from sklearn.preprocessing import StandardScaler
# 创建StandardScaler对象
Standard_Scaler = StandardScaler()
# 使用训练集的数值型特征进行标准化处理,并返回标准化后的结果
X_train_scaled = Standard_Scaler.fit_transform(X_train[numeric_columns])
# 使用训练集的标准化参数对测试集的数值型特征进行标准化处理,并返回标准化后的结果
X_test_scaled = Standard_Scaler.transform(X_test[numeric_columns])
# 注:numeric_columns是一个包含数值型特征列名的列表,X_train和X_test是训练集和测试集的特征数据。标准化是一种常用的数据预处理方法,通过将特征数据按照均值为0,方差为1的标准正态分布进行转换,使得不同特征之间具有可比性,提高模型的训练效果。StandardScaler类是sklearn.preprocessing模块中的一个标准化类,fit_transform方法用于计算训练集的均值和方差,并进行标准化处理,transform方法则使用训练集的标准化参数对测试集进行标准化处理。
array([[ 0.27610257, 1.01769998, 0.61931885],
[-1.24037213, -1.53347618, -0.98780549],
[-1.28135793, -1.33620306, -0.99803605],
...,
[-1.19938633, 0.13498634, -0.90549797],
[-0.05178385, 0.98259205, 0.30461881],
[ 0.39905998, 1.17652156, 0.85307838]])
4.3 独热编码
# 打印categoric_columns的值
print(categoric_columns)
['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
# 导入所需的库
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import make_column_transformer
# 创建一个列转换器,用于对多个列进行编码
# 使用OneHotEncoder对指定的列进行编码,handle_unknown参数设置为'ignore',表示在遇到未知类别时忽略
# 列表中的每个元素表示一个需要进行编码的列
transformer = make_column_transformer(
(OneHotEncoder(handle_unknown='ignore'),
['gender', 'SeniorCitizen', 'Partner', 'Dependents',
'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
'TechSupport', 'StreamingTV', 'StreamingMovies',
'Contract', 'PaperlessBilling', 'PaymentMethod']))
4.3.1 X_train 编码
# Transforming
# 使用transformer对X_train进行转换
transformed = transformer.fit_transform(X_train)
# Transformating back
# 将转换后的数据转换为DataFrame,并设置列名为转换器的输出特征名称
transformed_df = pd.DataFrame(transformed, columns=transformer.get_feature_names_out())
# One-hot encoding removed an index. Let's put it back:
# 将转换后的DataFrame的索引设置为X_train的索引,以保持一致
transformed_df.index = X_train.index
# Joining tables
# 将X_train和转换后的DataFrame按列合并
X_train = pd.concat([X_train, transformed_df], axis=1)
# Dropping old categorical columns
# 删除原始的分类列
X_train.drop(categoric_columns, axis=1, inplace=True)
# CHecking result
# 查看转换后的X_train的前几行数据
X_train.head()
| tenure | MonthlyCharges | TotalCharges | onehotencoder__gender_Female | onehotencoder__gender_Male | onehotencoder__SeniorCitizen_0 | onehotencoder__SeniorCitizen_1 | onehotencoder__Partner_No | onehotencoder__Partner_Yes | onehotencoder__Dependents_No | ... | onehotencoder__StreamingMovies_Yes | onehotencoder__Contract_Month-to-month | onehotencoder__Contract_One year | onehotencoder__Contract_Two year | onehotencoder__PaperlessBilling_No | onehotencoder__PaperlessBilling_Yes | onehotencoder__PaymentMethod_Bank transfer (automatic) | onehotencoder__PaymentMethod_Credit card (automatic) | onehotencoder__PaymentMethod_Electronic check | onehotencoder__PaymentMethod_Mailed check | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1956 | 42 | 60.15 | 2421.60 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3135 | 14 | 76.45 | 1117.55 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 5058 | 44 | 54.30 | 2390.45 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 4647 | 32 | 74.75 | 2282.95 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 118 | 41 | 20.65 | 835.15 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
5 rows × 46 columns
4.3.2 X_test 编码
# Transforming
# 使用transformer对X_test进行转换
transformed = transformer.transform(X_test)
# Transformating back
# 将转换后的数据转换为DataFrame,并设置列名为transformer的输出特征名
transformed_df = pd.DataFrame(transformed, columns=transformer.get_feature_names_out())
# One-hot encoding removed an index. Let's put it back:
# 将索引重新赋值为X_test的索引
transformed_df.index = X_test.index
# Joining tables
# 将X_test和transformed_df按列拼接
X_test = pd.concat([X_test, transformed_df], axis=1)
# Dropping old categorical columns
# 删除X_test中的旧的分类列
X_test.drop(categoric_columns, axis=1, inplace=True)
# CHecking result
# 查看处理后的X_test的前几行数据
X_test.head()
| tenure | MonthlyCharges | TotalCharges | onehotencoder__gender_Female | onehotencoder__gender_Male | onehotencoder__SeniorCitizen_0 | onehotencoder__SeniorCitizen_1 | onehotencoder__Partner_No | onehotencoder__Partner_Yes | onehotencoder__Dependents_No | ... | onehotencoder__StreamingMovies_Yes | onehotencoder__Contract_Month-to-month | onehotencoder__Contract_One year | onehotencoder__Contract_Two year | onehotencoder__PaperlessBilling_No | onehotencoder__PaperlessBilling_Yes | onehotencoder__PaymentMethod_Bank transfer (automatic) | onehotencoder__PaymentMethod_Credit card (automatic) | onehotencoder__PaymentMethod_Electronic check | onehotencoder__PaymentMethod_Mailed check | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5770 | 39 | 95.55 | 3692.85 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1129 | 2 | 19.25 | 48.35 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2290 | 1 | 25.15 | 25.15 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 658 | 37 | 20.35 | 697.65 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3623 | 17 | 25.15 | 412.60 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
5 rows × 46 columns
4.3.3 重命名特征
在进行One Hot编码之后,您可能希望重命名特征名称。
# 打印出X_train的列名
print(X_train.columns)
Index(['tenure', 'MonthlyCharges', 'TotalCharges',
'onehotencoder__gender_Female', 'onehotencoder__gender_Male',
'onehotencoder__SeniorCitizen_0', 'onehotencoder__SeniorCitizen_1',
'onehotencoder__Partner_No', 'onehotencoder__Partner_Yes',
'onehotencoder__Dependents_No', 'onehotencoder__Dependents_Yes',
'onehotencoder__PhoneService_No', 'onehotencoder__PhoneService_Yes',
'onehotencoder__MultipleLines_No',
'onehotencoder__MultipleLines_No phone service',
'onehotencoder__MultipleLines_Yes',
'onehotencoder__InternetService_DSL',
'onehotencoder__InternetService_Fiber optic',
'onehotencoder__InternetService_No', 'onehotencoder__OnlineSecurity_No',
'onehotencoder__OnlineSecurity_No internet service',
'onehotencoder__OnlineSecurity_Yes', 'onehotencoder__OnlineBackup_No',
'onehotencoder__OnlineBackup_No internet service',
'onehotencoder__OnlineBackup_Yes', 'onehotencoder__DeviceProtection_No',
'onehotencoder__DeviceProtection_No internet service',
'onehotencoder__DeviceProtection_Yes', 'onehotencoder__TechSupport_No',
'onehotencoder__TechSupport_No internet service',
'onehotencoder__TechSupport_Yes', 'onehotencoder__StreamingTV_No',
'onehotencoder__StreamingTV_No internet service',
'onehotencoder__StreamingTV_Yes', 'onehotencoder__StreamingMovies_No',
'onehotencoder__StreamingMovies_No internet service',
'onehotencoder__StreamingMovies_Yes',
'onehotencoder__Contract_Month-to-month',
'onehotencoder__Contract_One year', 'onehotencoder__Contract_Two year',
'onehotencoder__PaperlessBilling_No',
'onehotencoder__PaperlessBilling_Yes',
'onehotencoder__PaymentMethod_Bank transfer (automatic)',
'onehotencoder__PaymentMethod_Credit card (automatic)',
'onehotencoder__PaymentMethod_Electronic check',
'onehotencoder__PaymentMethod_Mailed check'],
dtype='object')
# 设置新的特征名称
X_train.columns = ['Tenure', 'MonthlyCharges', 'TotalCharges', # 设置列名为Tenure, MonthlyCharges, TotalCharges
'gender_Female','gender_Male', # 设置列名为gender_Female, gender_Male
'SeniorCitizen_0','SeniorCitizen_1', # 设置列名为SeniorCitizen_0, SeniorCitizen_1
'Partner_No','Partner_Yes', # 设置列名为Partner_No, Partner_Yes
'Dependents_No','Dependents_Yes', # 设置列名为Dependents_No, Dependents_Yes
'PhoneService_No','PhoneService_Yes', # 设置列名为PhoneService_No, PhoneService_Yes
'MultipleLines_No','MultipleLines_No phone service','MultipleLines_Yes', # 设置列名为MultipleLines_No, MultipleLines_No phone service, MultipleLines_Yes
'InternetService_DSL','InternetService_Fiber','InternetService_No', # 设置列名为InternetService_DSL, InternetService_Fiber, InternetService_No
'OnlineSecurity_No','OnlineSecurity_NoInternetService','OnlineSecurity_Yes', # 设置列名为OnlineSecurity_No, OnlineSecurity_NoInternetService, OnlineSecurity_Yes
'OnlineBackup_No','OnlineBackup_NoInternetService','OnlineBackup_Yes', # 设置列名为OnlineBackup_No, OnlineBackup_NoInternetService, OnlineBackup_Yes
'DeviceProtection_No','DeviceProtection_NoInternetService','DeviceProtection_Yes', # 设置列名为DeviceProtection_No, DeviceProtection_NoInternetService, DeviceProtection_Yes
'TechSupport_No', 'TechSupport_NoInternetService','TechSupport_Yes', # 设置列名为TechSupport_No, TechSupport_NoInternetService, TechSupport_Yes
'StreamingTV_No', 'StreamingTV_NoInternetService','StreamingTV_Yes', # 设置列名为StreamingTV_No, StreamingTV_NoInternetService, StreamingTV_Yes
'StreamingMovies_No','StreamingMovies_NoInternetService','StreamingMovies_Yes', # 设置列名为StreamingMovies_No, StreamingMovies_NoInternetService, StreamingMovies_Yes
'Contract_Month-to-month','Contract_One year', 'Contract_Two year', # 设置列名为Contract_Month-to-month, Contract_One year, Contract_Two year
'PaperlessBilling_No','PaperlessBilling_Yes', # 设置列名为PaperlessBilling_No, PaperlessBilling_Yes
'PaymentMethod_BankTransfer','PaymentMethod_CreditCard','PaymentMethod_ElectronicCheck','PaymentMethod_MailedCheck'] # 设置列名为PaymentMethod_BankTransfer, PaymentMethod_CreditCard, PaymentMethod_ElectronicCheck, PaymentMethod_MailedCheck
X_test.columns = ['Tenure', 'MonthlyCharges', 'TotalCharges', # 设置列名为Tenure, MonthlyCharges, TotalCharges
'gender_Female','gender_Male', # 设置列名为gender_Female, gender_Male
'SeniorCitizen_0','SeniorCitizen_1', # 设置列名为SeniorCitizen_0, SeniorCitizen_1
'Partner_No','Partner_Yes', # 设置列名为Partner_No, Partner_Yes
'Dependents_No','Dependents_Yes', # 设置列名为Dependents_No, Dependents_Yes
'PhoneService_No','PhoneService_Yes', # 设置列名为PhoneService_No, PhoneService_Yes
'MultipleLines_No','MultipleLines_No phone service','MultipleLines_Yes', # 设置列名为MultipleLines_No, MultipleLines_No phone service, MultipleLines_Yes
'InternetService_DSL','InternetService_Fiber','InternetService_No', # 设置列名为InternetService_DSL, InternetService_Fiber, InternetService_No
'OnlineSecurity_No','OnlineSecurity_NoInternetService','OnlineSecurity_Yes', # 设置列名为OnlineSecurity_No, OnlineSecurity_NoInternetService, OnlineSecurity_Yes
'OnlineBackup_No','OnlineBackup_NoInternetService','OnlineBackup_Yes', # 设置列名为OnlineBackup_No, OnlineBackup_NoInternetService, OnlineBackup_Yes
'DeviceProtection_No','DeviceProtection_NoInternetService','DeviceProtection_Yes', # 设置列名为DeviceProtection_No, DeviceProtection_NoInternetService, DeviceProtection_Yes
'TechSupport_No', 'TechSupport_NoInternetService','TechSupport_Yes', # 设置列名为TechSupport_No, TechSupport_NoInternetService, TechSupport_Yes
'StreamingTV_No', 'StreamingTV_NoInternetService','StreamingTV_Yes', # 设置列名为StreamingTV_No, StreamingTV_NoInternetService, StreamingTV_Yes
'StreamingMovies_No','StreamingMovies_NoInternetService','StreamingMovies_Yes', # 设置列名为StreamingMovies_No, StreamingMovies_NoInternetService, StreamingMovies_Yes
'Contract_Month-to-month','Contract_One year', 'Contract_Two year', # 设置列名为Contract_Month-to-month, Contract_One year, Contract_Two year
'PaperlessBilling_No','PaperlessBilling_Yes', # 设置列名为PaperlessBilling_No, PaperlessBilling_Yes
'PaymentMethod_BankTransfer','PaymentMethod_CreditCard','PaymentMethod_ElectronicCheck','PaymentMethod_MailedCheck'] # 设置列名为PaymentMethod_BankTransfer, PaymentMethod_CreditCard, PaymentMethod_ElectronicCheck, PaymentMethod_MailedCheck
# 重命名列后的X_train数据的前几行
X_train.head()
| Tenure | MonthlyCharges | TotalCharges | gender_Female | gender_Male | SeniorCitizen_0 | SeniorCitizen_1 | Partner_No | Partner_Yes | Dependents_No | ... | StreamingMovies_Yes | Contract_Month-to-month | Contract_One year | Contract_Two year | PaperlessBilling_No | PaperlessBilling_Yes | PaymentMethod_BankTransfer | PaymentMethod_CreditCard | PaymentMethod_ElectronicCheck | PaymentMethod_MailedCheck | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1956 | 42 | 60.15 | 2421.60 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3135 | 14 | 76.45 | 1117.55 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 5058 | 44 | 54.30 | 2390.45 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | ... | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 4647 | 32 | 74.75 | 2282.95 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 118 | 41 | 20.65 | 835.15 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
5 rows × 46 columns
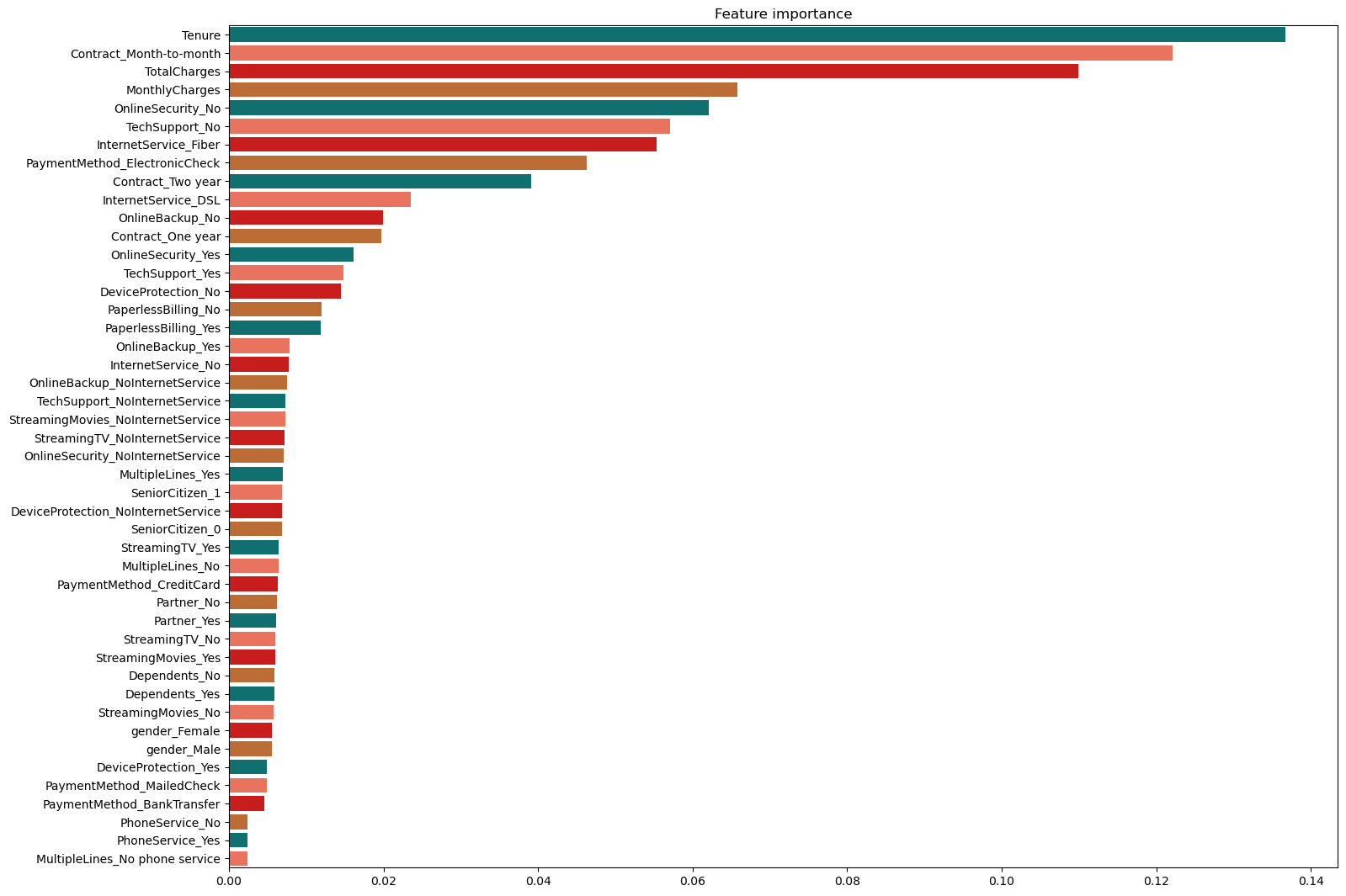
4.4 特征重要性
# 导入所需的库
from sklearn.ensemble import RandomForestClassifier
# 创建一个随机森林分类器对象
# 设置最大深度为8,叶子节点最小样本数为3,分割节点最小样本数为3,估计器数量为5000,随机种子为13
clf = RandomForestClassifier(max_depth=8, min_samples_leaf=3, min_samples_split=3, n_estimators=5000, random_state=13)
# 使用训练数据对分类器进行训练
clf = clf.fit(X_train, y_train)
# 计算特征重要性
fimp = pd.Series(data=clf.feature_importances_, index=X_train.columns).sort_values(ascending=False)
# 创建一个图像对象,设置图像大小为17x13
plt.figure(figsize=(17,13))
# 设置图像标题为"Feature importance"
plt.title("Feature importance")
# 创建一个水平方向的条形图,y轴为特征名称,x轴为特征重要性值,使用预定义的调色板palette
ax = sns.barplot(y=fimp.index, x=fimp.values, palette=palette, orient='h')
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!