Python爬虫实战(基础篇)—9获取某个城市天气(附完整代码)
2023-12-14 14:37:08
文章目录
专栏导读
🔥🔥本文已收录于《Python基础篇爬虫》
🉑🉑本专栏专门
针对于有爬虫基础准备的一套基础教学,轻松掌握Python爬虫,欢迎各位同学订阅,专栏订阅地址:点我直达
🤞🤞此外如果您已工作,如需利用Python解决办公中常见的问题,欢
迎订阅《Python办公自动化》专栏,订阅地址:点我直达
的
🔺🔺此外《Python30天从入门到熟练》专栏已上线,欢迎大家订阅,订阅地址:点我直达
背景
-
由于我有一个习惯就是每天都必须查看每日天气情况,但是我手机是那种老版的小灵通,不像现在的智能手机能够显示每日的天气情况,所以我需要写一个爬虫查看当前城市(或者其他城市)的天气如何,这样我就可以知道每日天气情况,我也不会不开心了!
1、网址(请求URL)
-
主页:URL:https://www.tianqishi.com/
-
带城市:URL:https://www.tianqishi.com/
2、查看请求方法、参数
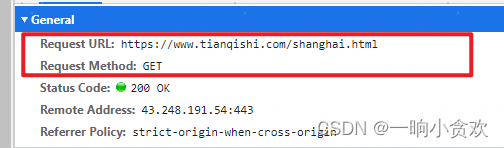
-
请求方法:GET
-
请求参数:无
3、请求初步测试
代码
import requests
url = 'https://www.tianqishi.com/shanghai.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,headers=headers)
print(res_data.text)
请求成功
4、数据清洗(lxml+xpath)
-
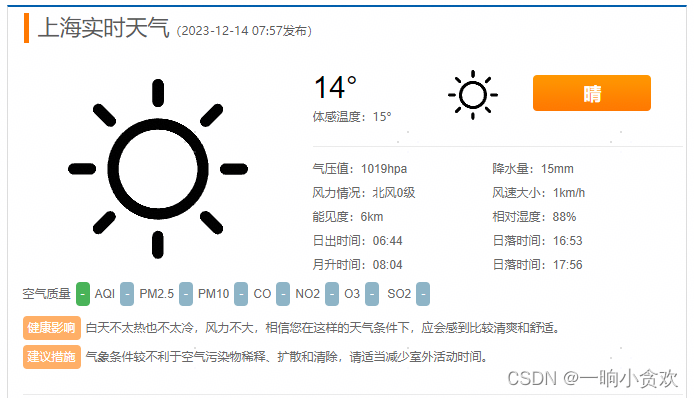
将上述的详细信息,进行元素分析,利用 lxml+xpath,进行数据清洗,lxml 没有安装的小伙伴可以安装一下
-
安装:pip install lxml
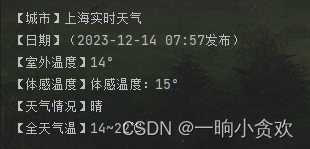
【城市实时天气】+【日期】lxml+xpath 代码
- 【城市实时天气】
在h3标签里,class属性为:class=“city-title ico”
【日期】在h3标签里,class属性为:class=“city-title ico”里面的span 标签里

city = tree.xpath('//h3[@class="city-title ico"]')[0].text
date = tree.xpath('//h3[@class="city-title ico"]//span')[0].text
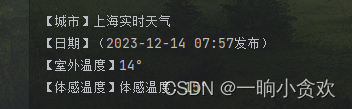
【室外温度】+【体感温度】lxml+xpath 代码

ot = tree.xpath('//div[@class="ltlTemperature"]//b')[0].text # 室外温度
st = tree.xpath('//div[@class="ltlTemperature"]//span')[0].text # 体感温度
【天晴情况】+【全天气温】lxml+xpath 代码

t_type = tree.xpath('(//div[@class="box pcity"])[3]//li//a[@target="_blank"]')[0].text.split(':')[1].split(',')[0]
all_day_t = tree.xpath('(//div[@class="box pcity"])[3]//li//a[@target="_blank"]')[0].text.split(':')[1].split(',')[1]
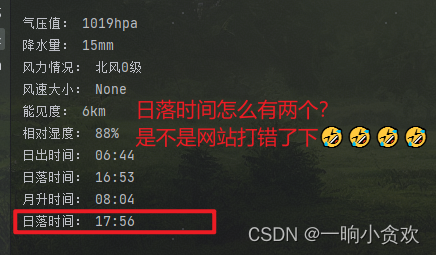
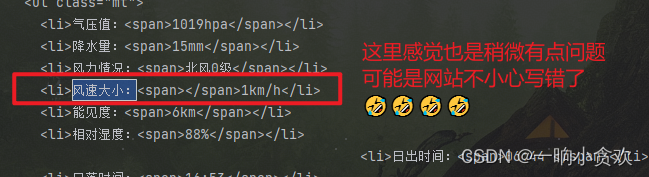
【气压值】【降水量】【风力情况】【风速大小】【能见度】【相对湿度】【日出时间】【日落时间】【月升时间】【日落时间】lxml+xpath 代码

datas = tree.xpath('//ul[@class="mt"]//li')
values = tree.xpath('//ul[@class="mt"]//li//span')
for i in range(len(datas)):
print(datas[i].text,values[i].text)
【空气质量】【健康影响】【建议措施】lxml+xpath 代码
he = tree.xpath('(//div[@class="air-quality pd0"])[1]//font')
suggest = tree.xpath('(//div[@class="air-quality pd0"])[2]//font')

天气简报 lxml+xpath 代码
tianqijianbao = tree.xpath('//div[@class="jdjianjie"]//p')[0]

5、不同城市测试
-
代码到这已经全部完成,我们可以测试一下,其他城市试一试
-
我们发现只是将【北京】转换成拼音【beijing】
汉字转拼音
-
Python中文字转拼音可以使用xpinyin,直接使用pip安装即可👇
pip install xpinyin -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
汉字转拼音代码测试
from xpinyin import Pinyin
p = Pinyin()
result1 = p.get_pinyin('北京')
print(result1)
输出结果
bei-jing
把中间的【-】去掉
from xpinyin import Pinyin
p = Pinyin()
result1 = p.get_pinyin('北京')
print(result1.replace('-',''))
输出结果
beijing
不同城市测试
成功!

6、完整代码
# -*- coding: UTF-8 -*-
'''
@Project :测试
@File :main.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2023/12/13 13:44
'''
import requests
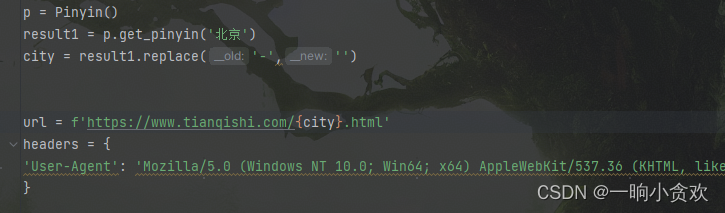
from lxml import etree
from xpinyin import Pinyin
p = Pinyin()
result1 = p.get_pinyin('北京')
city = result1.replace('-','')
url = f'https://www.tianqishi.com/{city}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
res_data = requests.get(url=url,headers=headers)
# print(res_data.text)
tree = etree.HTML(res_data.text)
city = tree.xpath('//h3[@class="city-title ico"]')[0].text
date = tree.xpath('//h3[@class="city-title ico"]//span')[0].text
ot = tree.xpath('//div[@class="ltlTemperature"]//b')[0].text # 室外温度
st = tree.xpath('//div[@class="ltlTemperature"]//span')[0].text # 体感温度
t_type = tree.xpath('(//div[@class="box pcity"])[3]//li//a[@target="_blank"]')[0].text.split(':')[1].split(',')[0]
all_day_t = tree.xpath('(//div[@class="box pcity"])[3]//li//a[@target="_blank"]')[0].text.split(':')[1].split(',')[1]
datas = tree.xpath('//ul[@class="mt"]//li')
values = tree.xpath('//ul[@class="mt"]//li//span')
air_quality = tree.xpath('//div[@class="air-quality"]//span')
he = tree.xpath('(//div[@class="air-quality pd0"])[1]//font')
suggest = tree.xpath('(//div[@class="air-quality pd0"])[2]//font')
tianqijianbao = tree.xpath('//div[@class="jdjianjie"]//p')[0]
print(f"【城市】{city}\n【日期】{date}\n【室外温度】{ot}\n【体感温度】{st}\n【天气情况】{t_type}\n"
f"【全天气温】{all_day_t}")
for i in range(len(datas)):
print(f"【{datas[i].text}】{values[i].text}")
print(f'【空气质量】{air_quality[0].text}\n【AQI】{air_quality[1].text}\n【PM2.5】{air_quality[2].text}\n【PM10】{air_quality[3].text}\n'
f'【CO】{air_quality[4].text}\n【NO2】{air_quality[5].text}\n【O3】{air_quality[6].text}\n【SO2】{air_quality[7].text}')
print(f"【健康影响】{he[0].text}\n【建议措施】{suggest[0].text}")
print(f"【天气简报】{tianqijianbao.text}")
总结
-
今天的代码和上一节课的代码类似,都是简单的GET请求,并且返回的是html页面,我们利用【lxml】+【xpath】提取数据
-
这里需要大家对【xpath】稍微了解一下,并且自己会找元素,只要会找元素基本没什么难度
-
希望大家多多点赞,多多收藏,多多关注
-
本专栏持续更新中。。。点个关注拜托了!!!
文章来源:https://blog.csdn.net/weixin_42636075/article/details/134989194
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!