RTMO: 超越YOLO-pose的高性能、单阶段、多人姿态估计
论文地址:https://arxiv.org/pdf/2312.07526v1.pdf
github:https://github.com/open-mmlab/mmpose/tree/dev-1.x/projects/rtmo
1. 动机
实时多人姿态估计面临着速度与精度平衡的问题。two-stage的方法中,top-down是先检测再估计pose,人一多的时候就会变慢,bottom-up的方法则需要grouping等操作,效果也不理想;已有的one-stage方法虽然速度很快,但精度往往不高。
因此,作者提出了一个one-stage、高性能的多人姿态估计方法——RTMO,其通过双1-D heatmap表示关键点,无缝集成到了YOLO框架中,在保持高推理速度的前提下,提升了one-stage多人姿态估计的性能。
2. 方法
作者主要是将YOLO目标检测框架和坐标分类方法(如RTMPose、SimCC,以及DFL所用的那样)结合了起来,不过和他们不同的是,RTMPose、SimCC是将整个输入图像分成若干个bins,这导致大量bin的浪费且效率低下,DFL在anchor附近设置bin,这会导致召回比较低;而作者提出在bbox内进行bin的分配,这样一来,就可以实现动态分配,既能覆盖每个实例,又能根据每个实例的大小分配bin,同时也避免了在没有实例的地方分配bin造成浪费。
2.1 概述
提出的RTMO框架如下图所示:
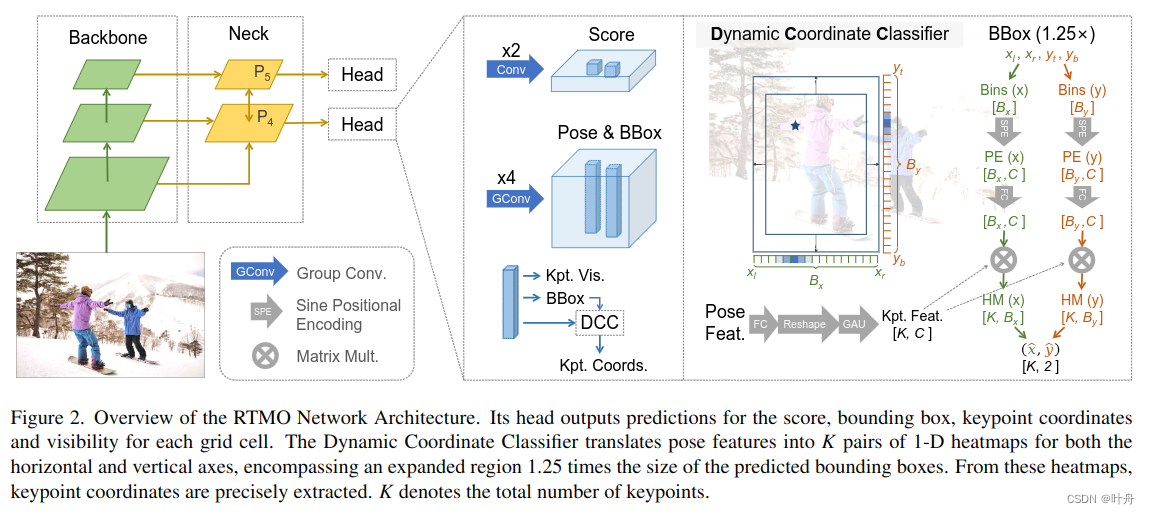
?网络框架描述如下:
输入图像经过backbone(CSPDarknet)后,最后三层feature map经过Hybrid Encoder得到16、32倍下采样的空间feature mapP4、P5,送入Heads;每个Head生成一个得分feature、一个坐标姿态feature,其中坐标姿态feature用于预测bbox、关键点坐标、关键点可见性。
****强行插入一段*****:
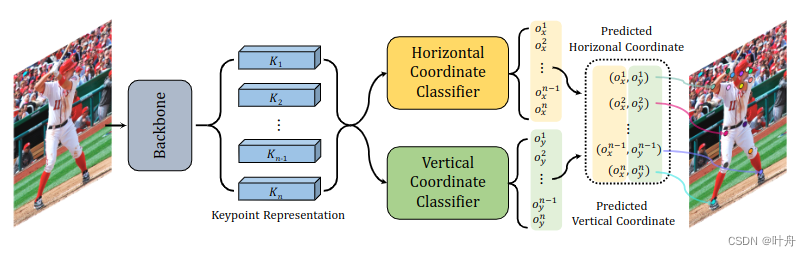
关于坐标分类,没做过的小伙伴可能有点懵,我们可以从SimCC这篇文章中的方法一窥其貌。在SimCC中,将全图沿着X、Y轴分成多个bins,每个bin的宽度是小于一个像素的,也就可以在feature map中得到亚像素级别的坐标,从而缓解量化误差。SimCC网络结构长这样:
2.2 本文关键技术
2.2.1?Dynamic Coordinate Classifier
以前的方法直接从姿态特征回归关键点的位移,这会导致性能低下。本文提出了动态坐标分类器DCC,见图2中的DCC部分,动态地为两个1-D heatmap中的bin分类范围和形式表示,其先将bbox扩展1.25倍,然后再水平、垂直方向均匀划分bin,对于x轴(水平方向),bin的坐标表示如下:
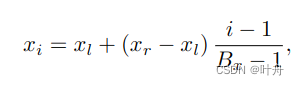
其中,xl, xr表示bbox的左右边界,共Bx个bin;y轴与之类似。
由于采用了动态的bin分配策略,所以每个bbox中的bin坐标是局部的,为了对应到全局坐标,作者使用sine进行了位置编码(positional encoding):
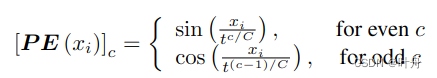
其中,t表示强度,c是索引,C是总维度。?
如图2中的DCC部分所示,bin经过sine 位置编码后又利用一个FC层来细化其对任务的适应性,然后与经过FC+Reshape+GAU(Gated Attention Unit)后的关键点feature相乘,再经过softmax得到heatmap:

2.2.2??MLE for Coordinate Classification
作者提出了用极大似然估计作为坐标分类的损失函数。在分类任务中,one-hot目标、交叉熵损失比较常用,还有Label平滑以及KLD,都能提升性能。高斯均值及方差可以视为标注坐标和预定义参数,则目标分布定义为:
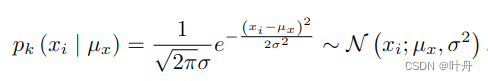
比较重要的一点是,作者注意到上述目标分布在数学上与带有真值xi的标注ux的似然函数相等,这种对称性的出现是因为高斯分布相对于它的平均值是对称的。将xi的预测概率作为先验,则第k个关键点的似然定义为:
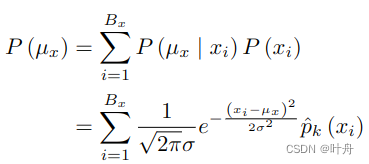
最大化上述似然即可建模标注的分布。
在实际使用中,作者使用了拉普拉斯分布和负对数似然损失:
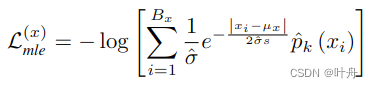
总的MLE损失为:
![]()
与 KLD 不同,我们的 MLE 损失允许可学习的方差,表示不确定性。这种不确定性学习框架自动调整各种样本的难度。对于困难样本,模型预测较大方差以简化优化过程,对于简单样本,预测较小方差来提升准确性。而在KLD中,采用可学习方差是有问题的,因为模型会从简化学习的角度出发从而倾向于学习较大方差。
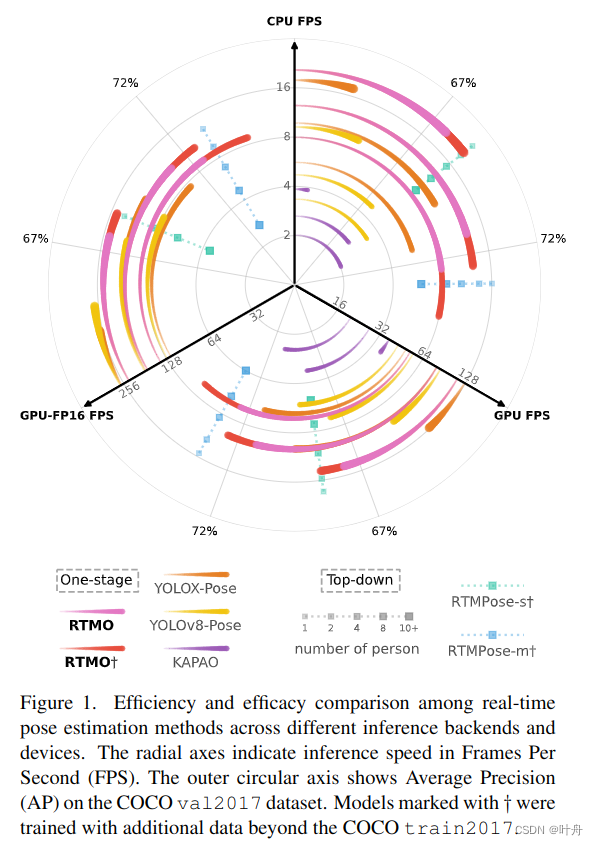
3. 实验结果
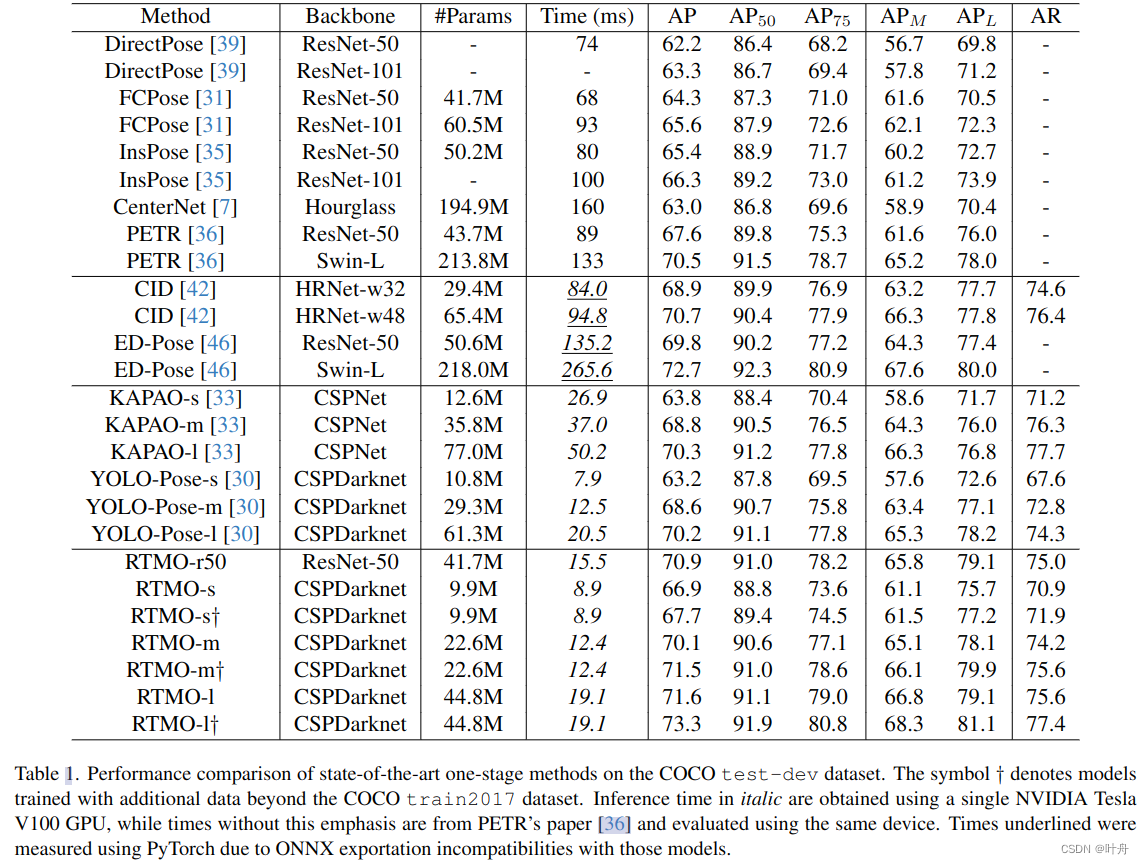

?
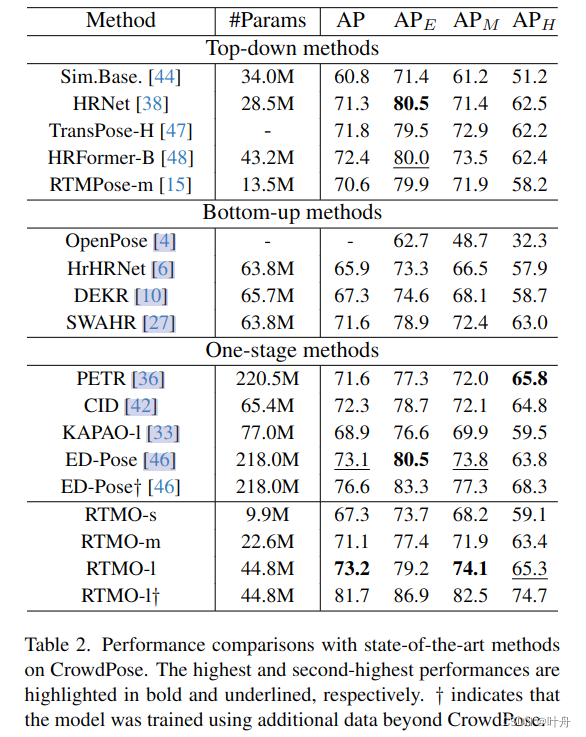
?4. 写在后面
RTMO这项工作对YOLO进行了扩展,将坐标分类的方法集成到了YOLO框架中。不同于YOLO-Pose的直接回归,RTMO将bbox范围内的X、Y轴范围分为多个bin,然后对关键点x/y坐标进行分类得到其坐标;也不同于其他one-stage 多人姿态估计方法,如SimCC直接在全图划分bins或者DFL在anchor附近划分bins,RTMO则在bbox范围内进行划分,这避免了全图密集bins的浪费,也保证了每个实例的覆盖。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!