word2vec,BERT,GPT相关概念
词嵌入(Word Embeddings)
词嵌入通常是针对单个词元(如单词、字符或子词)的。然而,OpenAI 使用的是预训练的 Transformer 模型(如 GPT 和 BERT),这些模型不仅可以为单个词元生成嵌入,还可以为整个句子生成嵌入。
One-Hot Encoding
独热编码生成的向量是稀疏的,它们之间的距离相等,无法捕捉单词之间的语义关系。独热编码是固定的,无法在训练过程中进行调整。
Embedding Layer
嵌入层生成的向量是密集的,它们可以捕捉单词之间的语义关系。具有相似含义的单词在向量空间中距离较近。嵌入层的权重(即嵌入矩阵)可以在训练过程中进行调整,以便更好地捕捉词汇之间的语义关系。
自监督模型的 Word2Vec:Skip-gram & CBOW
跳元模型(Skip-gram model)
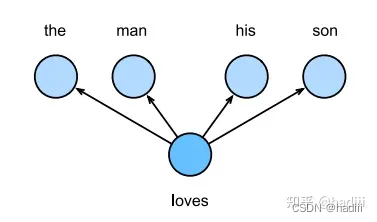
跳元模型是一种常用的词嵌入模型,它的基本假设是一个词可以用来生成其周围的单词。例如,文本序列 “the”, “man”, “loves”, “his”, “son”,选择 “loves” 作为中心词,并将上下文窗口设置为2,跳元模型会考虑生成上下文词 “the”, “man”, “his”, “son” 的条件概率:
P
(
"
t
h
e
"
,
"
m
a
n
"
,
"
h
i
s
"
,
"
s
o
n
"
∣
"
l
o
v
e
s
"
)
P("the", "man", "his", "son" | "loves")
P("the","man","his","son"∣"loves")
我们通常假设上下文词是在给定中心词的情况下独立生成的,这被称为条件独立性。因此,上述条件概率可以被重写为:
P
(
"
t
h
e
"
∣
"
l
o
v
e
s
"
)
?
P
(
"
m
a
n
"
∣
"
l
o
v
e
s
"
)
?
P
(
"
h
i
s
"
∣
"
l
o
v
e
s
"
)
?
P
(
"
s
o
n
"
∣
"
l
o
v
e
s
"
)
P("the" | "loves") · P("man" | "loves") · P("his" | "loves") · P("son" | "loves")
P("the"∣"loves")?P("man"∣"loves")?P("his"∣"loves")?P("son"∣"loves")
这是跳元模型的基本工作原理。
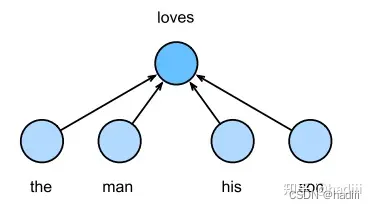
连续词袋模型(Continuous Bag of Words, CBOW)
连续词袋模型的主要假设是,中心词是基于其在文本序列中的周围上下文词生成的。例如,文本序列 “the”, “man”, “loves”, “his”, “son”,选择 “loves” 作为中心词,并将上下文窗口设置为2,连续词袋模型会考虑基于上下文词 “the”, “man”, “his”, “son” 生成中心词 “loves” 的条件概率:
P
(
"
l
o
v
e
s
"
∣
"
t
h
e
"
,
"
m
a
n
"
,
"
h
i
s
"
,
"
s
o
n
"
)
P("loves" | "the", "man", "his", "son")
P("loves"∣"the","man","his","son")
BERT:来自 Transformers 的双向编码器表示
动机
通过使用 Transformer 的双向自注意力机制,BERT 能够同时考虑一个单词在其上下文中的左侧和右侧的信息,从而更好地理解其含义。此外,通过预训练-微调的方式,BERT 能够在大规模未标注数据上学习到丰富的语言知识,然后将这些知识迁移到具体的 NLP 任务上,从而在许多任务上取得了显著的性能提升。
预训练任务之一:掩码语言模型(MLM)
在这个任务中,BERT 的输入文本中的一部分单词被随机地替换为特殊的 [MASK] 标记。模型的目标是预测被遮蔽的单词。这种方法允许 BERT 在训练过程中学习到双向的上下文信息,因为它需要同时考虑被遮蔽单词左侧和右侧的上下文来预测其原始单词。MLM 任务的一个关键优势是,与传统的从左到右或从右到左的预训练方法相比,它可以更好地捕捉到双向上下文信息。
预训练任务之二:下一句预测(NSP)
在这个任务中,BERT 需要预测两个给定句子是否是连续的。具体来说,模型接收一对句子作为输入,并需要判断第二个句子是否紧跟在第一个句子之后。这个任务的目的是帮助 BERT 学习句子之间的关系,从而更好地理解句子级别的上下文。
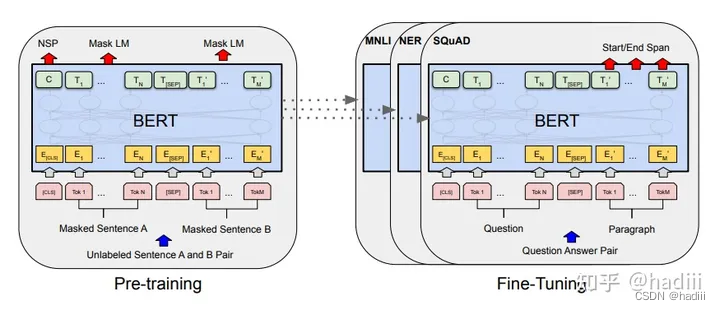
架构
BERT 模型采用了多层的 Transformer 编码器。每一层都包含一个自注意力机制和一个前馈神经网络。这些层被堆叠在一起,形成了 BERT 的深度网络结构。
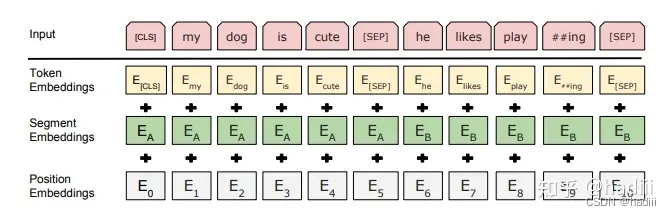
BERT 的嵌入主要包括三种类型:词嵌入、段落嵌入和位置嵌入。
- 词嵌入:在 BERT 中,每个单词首先被转换为一个固定大小的向量,这个向量捕获了单词的语义信息。BERT 使用了 WordPiece 嵌入,这是一种子词嵌入方法,可以有效处理未知词和长尾词。
- 段落嵌入:BERT 可以处理一对句子的输入。为了区分这两个句子,BERT 引入了段落嵌入。每个句子都有一个对应的段落嵌入,这个嵌入是添加到每个单词的词嵌入上的。
- 位置嵌入:由于 Transformer 模型并不考虑单词的顺序,BERT 引入了位置嵌入来捕获单词在句子中的位置信息。
GPT:Generative Pre-trained Transformer
动机
GPT 由 OpenAI 在 2018 年提出,它也是建立在 Transformer 的基础上,但 GPT 采用的是 Transformer 的解码器结构。GPT 的关键思想是使用大量的文本数据进行无监督预训练,然后在特定任务上进行微调。GPT 在预训练阶段使用的是语言模型任务,即给定一个文本序列的前 N 个单词,预测第 N+1 个单词。这种方式使得模型能够学习到丰富的语言特征。
词表压缩:BytePairEncoding (BPE)
BPE 算法的工作原理是将频繁出现的字节对(在 NLP 中通常是字符对)合并为一个单独的符号。以下是 BPE 算法在 NLP 中的一般步骤:
- 准备阶段:给定一个文本语料库,首先将文本分割为基本单位(例如,字符或字节)。
- 统计频率:统计所有相邻字符对的出现频率。
- 合并最频繁的对:选择最频繁的字符对,将它们合并为一个新的符号。这个新的符号被添加到词汇表中。
- 重复步骤:重复统计频率和合并步骤,直到达到预先设定的词汇表大小,或者没有更多的合并可以执行。
通过这种方式,BPE 能够生成一个固定大小的词汇表,其中包含了单个字符、常见的字符序列以及完整的单词。
BERT 与 GPT 的区别简介
- BERT 使用的是 Transformer 的编码器(Encoder)结构。它是设计为深度双向模型,通过同时考虑左右两侧的上下文来预训练语言表示。
- BERT 采用了掩码语言模型(MLM)和下一句预测(NSP)两种预训练任务。MLM 随机掩盖输入序列中的单词并预测这些单词,而 NSP 预测两个句子是否顺序相邻。
- GPT 使用的是 Transformer 的解码器(Decoder)结构,并且不使用 encoder-decoder 注意力。GPT 是单向的,它预训练一个生成式的语言模型,主要考虑左侧(之前)的上下文。
- GPT 主要采用传统的语言模型预训练任务 (Next Token Prediction,NTP),即根据给定的文本前缀预测下一个单词,只利用了左侧的上下文信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!