zookeeper经典应用场景之分布式锁
1. 什么是分布式锁
????????在单体的应用开发场景中涉及并发同步的时候,大家往往采用Synchronized(同步)或者其他同一个JVM内Lock机制来解决多线程间的同步问题。在分布式集群工作的开发场景中,就需要一种更加高级的锁机制来处理跨机器的进程之间的数据同步问题,这种跨机器的锁就是分布式锁。
2. 分布式锁的主流方案
- 基于数据库的分布式锁:这种方案使用数据库的事务和锁机制来实现分布式锁。虽然在某些场景下可以实现简单的分布式锁,但由于数据库操作的性能相对较低,并且可能面临锁表的风险,所以一般不是首选方案。
- 基于Redis的分布式锁:Redis分布式锁是一种常见且成熟的方案,适用于高并发、性能要求高且可靠性问题可以通过其他方案弥补的场景。Redis提供了高效的内存存储和原子操作,可以快速获取和释放锁。它在大规模的分布式系统中得到广泛应用。
- 基于ZooKeeper的分布式锁:这种方案适用于对高可靠性和一致性要求较高,而并发量不是太高的场景。由于ZooKeeper的选举机制和强一致性保证,它可以处理更复杂的分布式锁场景,但相对于Redis而言,性能可能较低。
2.1 基于数据库实现分布式锁设计思路
? ? ? ? 我们可以利用数据库的唯一索引来实现,唯一索引天然具有排他性。设计思路如下图所示:
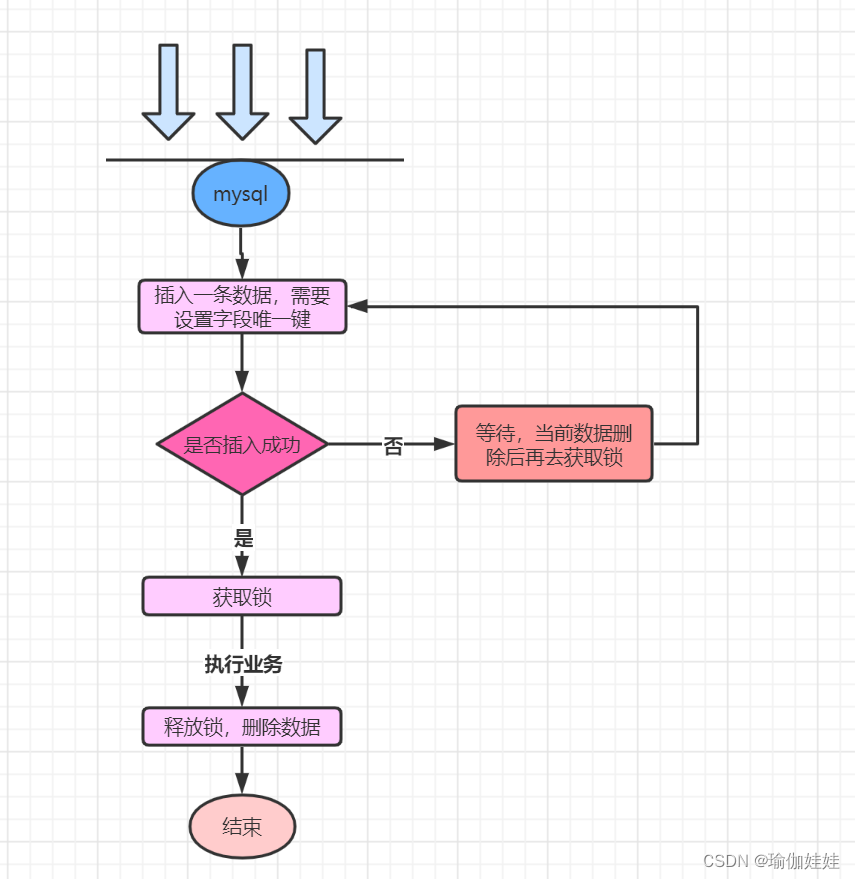
这种基于数据库的分布式锁会有什么问题呢? 很明显,容易出现死锁的问题。基于数据库设计分布式锁,在当下不是首选方案,不在过多赘述,大家明白其中设计思想即可。
2.2 基于redis实现分布式锁设计思路
? ? ? ? 基于redis设计的分布式锁设计是利用了其SETNX的特性,其是set If not exist的简写。意思就是当 key 不存在时,设置 key 的值,存在时,什么都不做。以下是一个基于redis设计分布式锁的一个基础方案。

????????上述方案,从技术的角度看:setnx 占锁成功,但业务代码出现异常或者服务器宕机,没有执行删除锁的逻辑,就会造成死锁。
? ? ? ? 上述是基本方案,之所以称之为基本方案,因为里面还是会有很多问题,比如没有来得及释放锁导致死锁;等待抢锁的线程太多,当当前锁释放后,等待的线程全都去抢占改锁出现的羊群效应;总之值得优化的地方还很多,本文中不在过多赘述,大家体会其中的设计思想,后续会出redis设计分布式锁的详细文章。
2.3 基于zookeeper实现分布式锁
2.3.1 青铜方案
使用临时 znode 来表示获取锁的请求,创建 znode成功的用户拿到锁。

????????想一想,上述设计存在什么问题?
????????如果所有的锁请求者都 监听 锁持有者,当代表锁持有者的 znode 被删除以后,所有的锁请求者都会通知到,都会竞争同一个资源,但是只有一个锁请求者能拿到锁。这就是羊群效应。?
2.3.2 白银方案
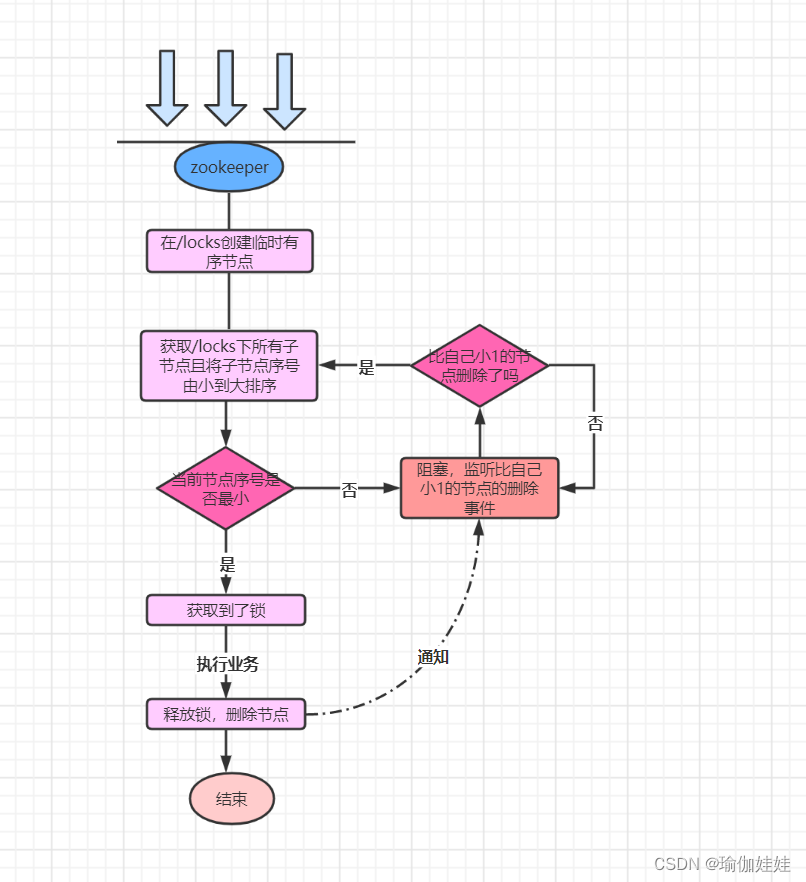
? ? ? ? 我们想一下青铜方案的问题,就是羊群效应,那么在并发编程中是如何处理这种羊群效应的呢?并发编程中,当资源被占用时,其他线程都进入阻塞队列,资源被释放后,阻塞队列中的一个线程出队,进行获取资源。同理,我们想一想,如果等待监听的线程在一个队列里面,遵循先进先出的规则,我们就可以实现一把公平分布式锁的实现?
????????zookeeper的临时有序znode就是一个天然的队列,我们可以利用这个特性,使用临时有序znode来表示获取锁的请求,线程创建最小后缀数字 znode 的用户成功拿到锁。设计思路如下:
2.3.1 zookeeper之Curator 可重入分布式锁
? ? ? ? 上述我们讨论了一些利用zookeeper节点特性设计分布式锁的一些方案,但在实际的开发中,如果需要使用到分布式锁,不建议去自己“重复造轮子”,建议直接使用Curator客户端中的各种官方实现的分布式锁,例如其中的InterProcessMutex可重入锁。
2.3.1.1 使用示例
????????以下是利用Curator 的可重入锁实现订单号的生成示例:
public class CuratorLockTest implements Runnable{
private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";
final static CuratorFramework client= CuratorFrameworkFactory.builder()
.connectString(CLUSTER_CONNECT_STR)
.retryPolicy(new ExponentialBackoffRetry(100,1)) // 设置重试策略
.build();
private OrderCodeGenerator orderCodeGenerator = new OrderCodeGenerator();
//可重入互斥锁
final InterProcessMutex lock=new InterProcessMutex(client,"/curator_lock");
public static void main(String[] args) throws InterruptedException {
client.start();
for(int i=0;i<30;i++){
new Thread(new CuratorLockTest()).start();
}
Thread.currentThread().join();
}
@Override
public void run() {
try {
// 加锁
lock.acquire();
//执行业务
String orderCode = orderCodeGenerator.getOrderCode();
System.out.println("生成订单号 "+orderCode);
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
// 释放锁
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
运行结果:

2.3.1.2 源码阅读?
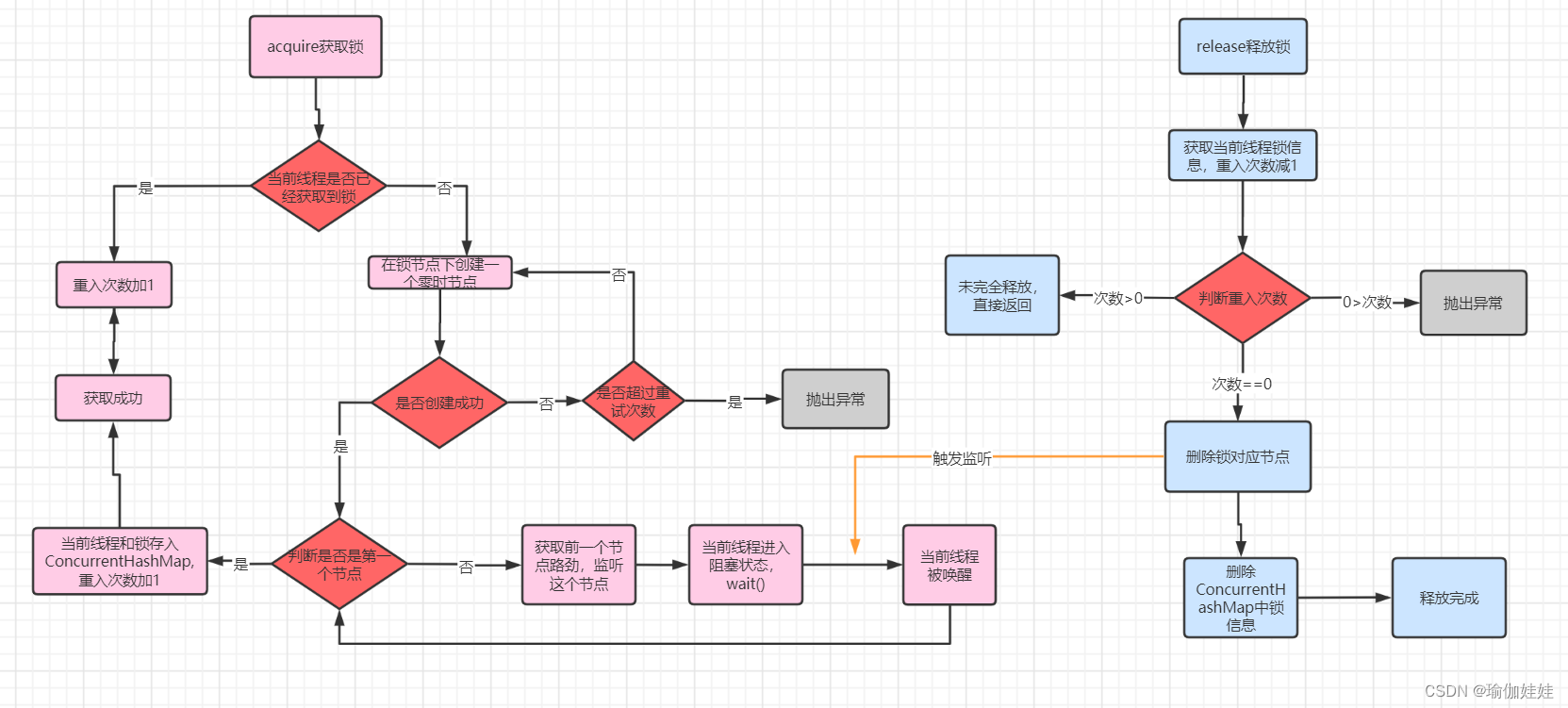
? ? ? ? 接下来,我们一起来看一下Curator是如何实现分布式锁的。分为获取锁和释放锁两部分。
获取锁源码解读:
我们以InterProcessMutex类的的acquire方法作为入口,依次跟踪
//获取锁 public void acquire() throws Exception { if (!this.internalLock(-1L, (TimeUnit)null)) { throw new IOException("Lost connection while trying to acquire lock: " + this.basePath); } }获取锁的主线逻辑:
private boolean internalLock(long time, TimeUnit unit) throws Exception { Thread currentThread = Thread.currentThread(); //获取当前线程的锁信息 InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread); //获取到了锁的信息 if (lockData != null) { //重试次数加1 lockData.lockCount.incrementAndGet(); return true; //没有获取到线程锁信息 } else { //创建临时有序节点 加锁 String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes()); if (lockPath != null) { //将锁数据保存到concurrentMap InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath); this.threadData.put(currentThread, newLockData); return true; } else { return false; } } }创建临时有序节点,加锁逻辑
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception { long startMillis = System.currentTimeMillis(); Long millisToWait = unit != null ? unit.toMillis(time) : null; byte[] localLockNodeBytes = this.revocable.get() != null ? new byte[0] : lockNodeBytes; int retryCount = 0; String ourPath = null; boolean hasTheLock = false; boolean isDone = false; while(!isDone) { isDone = true; try { //创建临时有序节点 ourPath = this.driver.createsTheLock(this.client, this.path, localLockNodeBytes); //加锁逻辑 hasTheLock = this.internalLockLoop(startMillis, millisToWait, ourPath); } catch (KeeperException.NoNodeException var14) { //重试逻辑 if (!this.client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper())) { throw var14; } isDone = false; } } return hasTheLock ? ourPath : null; }加锁逻辑:
//加锁逻辑 private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception { boolean haveTheLock = false; boolean doDelete = false; try { if (this.revocable.get() != null) { ((BackgroundPathable)this.client.getData().usingWatcher(this.revocableWatcher)).forPath(ourPath); } //加锁成功 跳出循环 while(this.client.getState() == CuratorFrameworkState.STARTED && !haveTheLock) { //拿到排好序的节点 List<String> children = this.getSortedChildren(); String sequenceNodeName = ourPath.substring(this.basePath.length() + 1); //判断是不是第一个节点 PredicateResults predicateResults = this.driver.getsTheLock(this.client, children, sequenceNodeName, this.maxLeases); //是第一个节点 if (predicateResults.getsTheLock()) { haveTheLock = true; } else { //获取前一个节点 String previousSequencePath = this.basePath + "/" + predicateResults.getPathToWatch(); synchronized(this) { try { //监听前一个节点 ((BackgroundPathable)this.client.getData().usingWatcher(this.watcher)).forPath(previousSequencePath); //等待 if (millisToWait == null) { this.wait(); } else { millisToWait = millisToWait - (System.currentTimeMillis() - startMillis); startMillis = System.currentTimeMillis(); if (millisToWait > 0L) { this.wait(millisToWait); } else { doDelete = true; break; } } } catch (KeeperException.NoNodeException var19) { } } } } } catch (Exception var21) { ThreadUtils.checkInterrupted(var21); doDelete = true; throw var21; } finally { if (doDelete) { //异常 删除节点 this.deleteOurPath(ourPath); } } return haveTheLock; }
释放锁源码阅读:
//释放锁 public void release() throws Exception { Thread currentThread = Thread.currentThread(); //获取当前线程锁信息 InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread); //不是当前锁的线程 if (lockData == null) { throw new IllegalMonitorStateException("You do not own the lock: " + this.basePath); } else { //重入锁减1 int newLockCount = lockData.lockCount.decrementAndGet(); if (newLockCount <= 0) { //小于0 抛异常 if (newLockCount < 0) { throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + this.basePath); } else {//等于零 try { //释放锁 this.internals.releaseLock(lockData.lockPath); } finally { //删除map中线程的锁信息 this.threadData.remove(currentThread); } } } } }?
2.3.1.3 源码阅读总结
3. 总结
优点:ZooKeeper分布式锁(如InterProcessMutex),具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,使用起来也较为简单。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis。在高性能、高并发的应用场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可靠性,因此在并发量不是太高的应用场景中,还是推荐使用ZooKeeper的分布式锁。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!