Spark中使用scala完成数据抽取任务 -- 总结
如题

任务二:离线数据处理,校赛题目需要使用spark框架将mysql数据库中ds_db01数据库的user_info表的内容抽取到Hive库的user_info表中,并且添加一个字段设置字段的格式 第二个任务和第一个的内容几乎一样。
在该任务中主要需要完成以下几个阶段:
- 构建maven工程
- 编写程序
连接mysql数据库
读取MySQL数据库中的数据
在hive中新建数据库
编写程序将读取到的数据处理之后导入到hive - 将程序打成jar包 通过scp命令传到集群中
- 在集群中使用spark --submit命令执行jar包
构建maven项目
使用idea新建一个空项目,在pom.xml文件中引入相对应的依赖
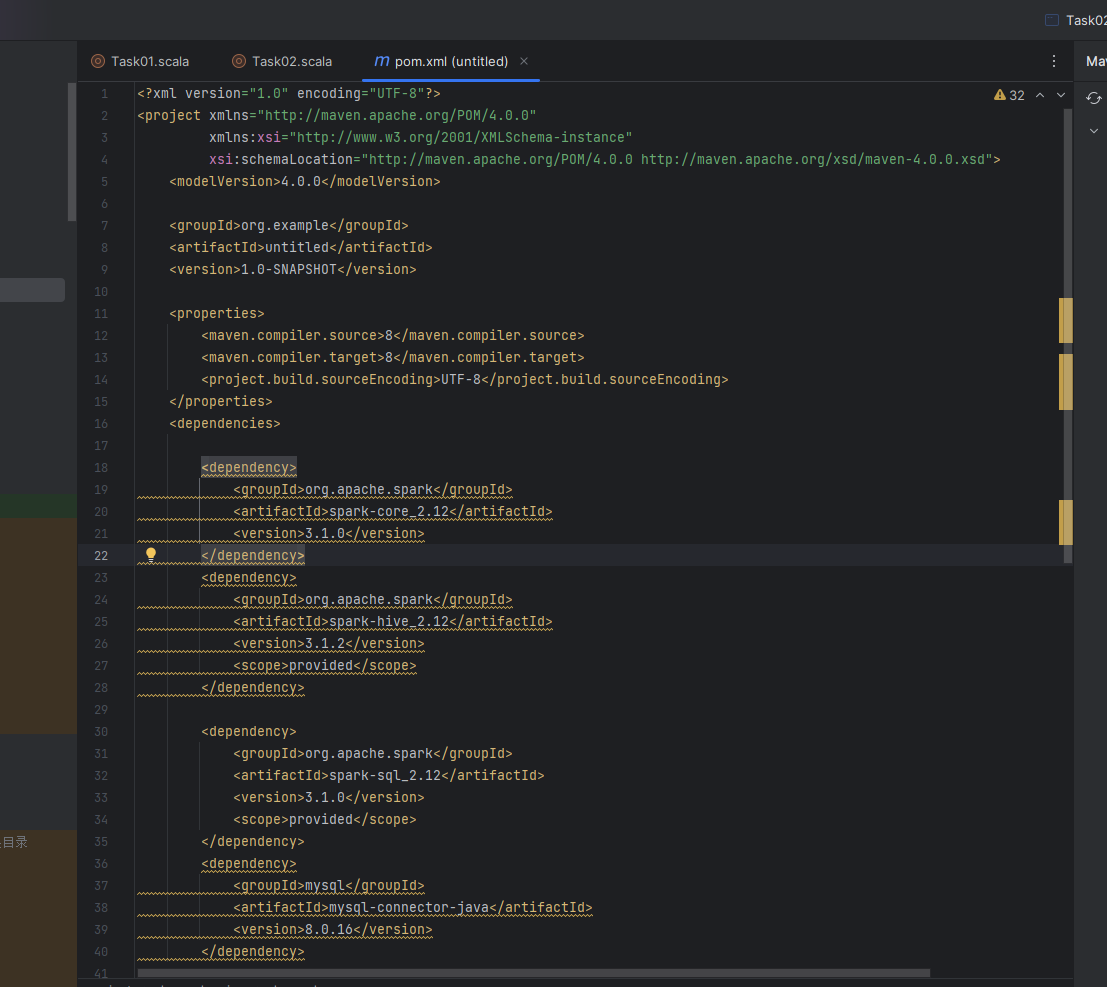
踩坑点(1):
maven中的依赖主要是关于spark的依赖,这些依赖在引入的时候需要注意引入的版本需要与集群中的scala版本相对应
maven仓库链接 : 点击这里

这里就说明了可以使用的Scala版本,注意对应自己集群中的版本选择依赖
踩坑点(2):
该任务需要程序连接本地的mysql服务,所以需要引入java连接mysql数据库的第三方依赖(idea设置-项目结构-添加依赖选择下载好的mysql-connector-java.jar就可以):
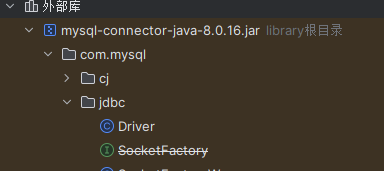
但是在idea中使用maven构建工具打包jar包的时候会出现第三方依赖打不进jar包的情况,这是因为maven工程中需要引入一个插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.xxg.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
使用该插件再次打包jar包,就不会出现打不进的情况
maven工程完整代码:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.xxg.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
编写程序
编写的程序中需要用到上文引入的那些依赖
程序的逻辑主要是
(1)与spark建立连接、启动相关配置
(2)启动hive的动态分区
(3)连接mysql
(4)取出mysql中所需字段并处理
(5)将处理结果存入Hive中
与spark建立连接
val conf = new SparkConf().setAppName("子任务1:数据抽取").setMaster("local")
val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
spark.sparkContext.setLogLevel("OFF")
这段代码的目的是创建一个Spark配置对象,设置应用程序的名称为"子任务1:数据抽取",并设置Spark的主节点为"local"。然后,它使用这个配置来创建一个SparkSession对象,并启用Hive支持。最后,它设置SparkContext的日志级别为"OFF"。
启动动态分区
//启用动态分区
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
这段代码是用于配置Apache Spark中的Hive动态分区模式。
在Hive中,动态分区可以在执行查询时动态地创建多个分区。这对于处理大量数据非常有用,因为它可以减少手动分区的需要。
连接mysql
val url = "jdbc:mysql://192.168.96.33/ds_db01"
//连接mysql
val jdbcDF = spark.read.format("jdbc").options(
Map("driver" -> "com.mysql.cj.jdbc.Driver",
"url" -> url,
"password" -> "123456",
"dbtable" -> "sku_info"
)).load()
注意:url需要以"jdbc:mysql://"开头,因为程序是使用jdbc这个第三方依赖访问mysql的。
在spark.read连接的时候也需要使用format()指定数据库驱动是jdbc,option的参数是map类型,
他需要指定依赖包的类名、密码和使用的数据表。
取出mysql中所需字段并处理
jdbcDF.createTempView("ods") // 创建临时表
val dataframe = spark.sql(
"""
select * from ods;
""".stripMargin
)
dataframe.show()
val data = dataframe.withColumn("etl_date", date_format(date_sub(current_date(), 1), "yyyyMMdd"))
data.show()
jdbcDF.createTempView(“ods”):这行代码创建了一个名为"ods"的临时视图。jdbcDF是一个DataFrame,它包含了从JDBC数据源中读取的数据(这里是mysql中的ds_db01库中的sku_info表)。createTempView方法将该DataFrame注册为一个临时表,以便在后续的SQL查询中使用。
val data = dataframe.withColumn(…):这行代码向dataframe中添加一个新列。新列的名称为"etl_date",值是通过对当前日期减去一天,并按照"yyyyMMdd"的格式进行格式化得到的。date_format和date_sub是Spark中用于日期处理的函数。新生成的DataFrame存储在变量data中。
将处理结果存入Hive中
data.write.format("hive").mode("append").partitionBy("etl_date").saveAsTable("ods.sku_info")
spark.sql("show partitions ods.sku_info").show()
这行代码的功能是:
- data.write.format(“hive”):指定输出格式为Hive。
- mode(“append”):如果目标表已经存在,则以追加模式写入数据,而不是覆盖现有数据。
- partitionBy(“etl_date”):按“etl_date”列分区。
- saveAsTable(“ods.sku_info”):将数据保存为名为“ods.sku_info”的Hive表。
- spark.sql(“show partitions ods.sku_info”).show() :执行一个SQL查询来查看“ods.sku_info”表的分区信息
将程序打成jar包
程序编写完成之后,可以使用idea自带的maven构建工具把项目打包成jar包:
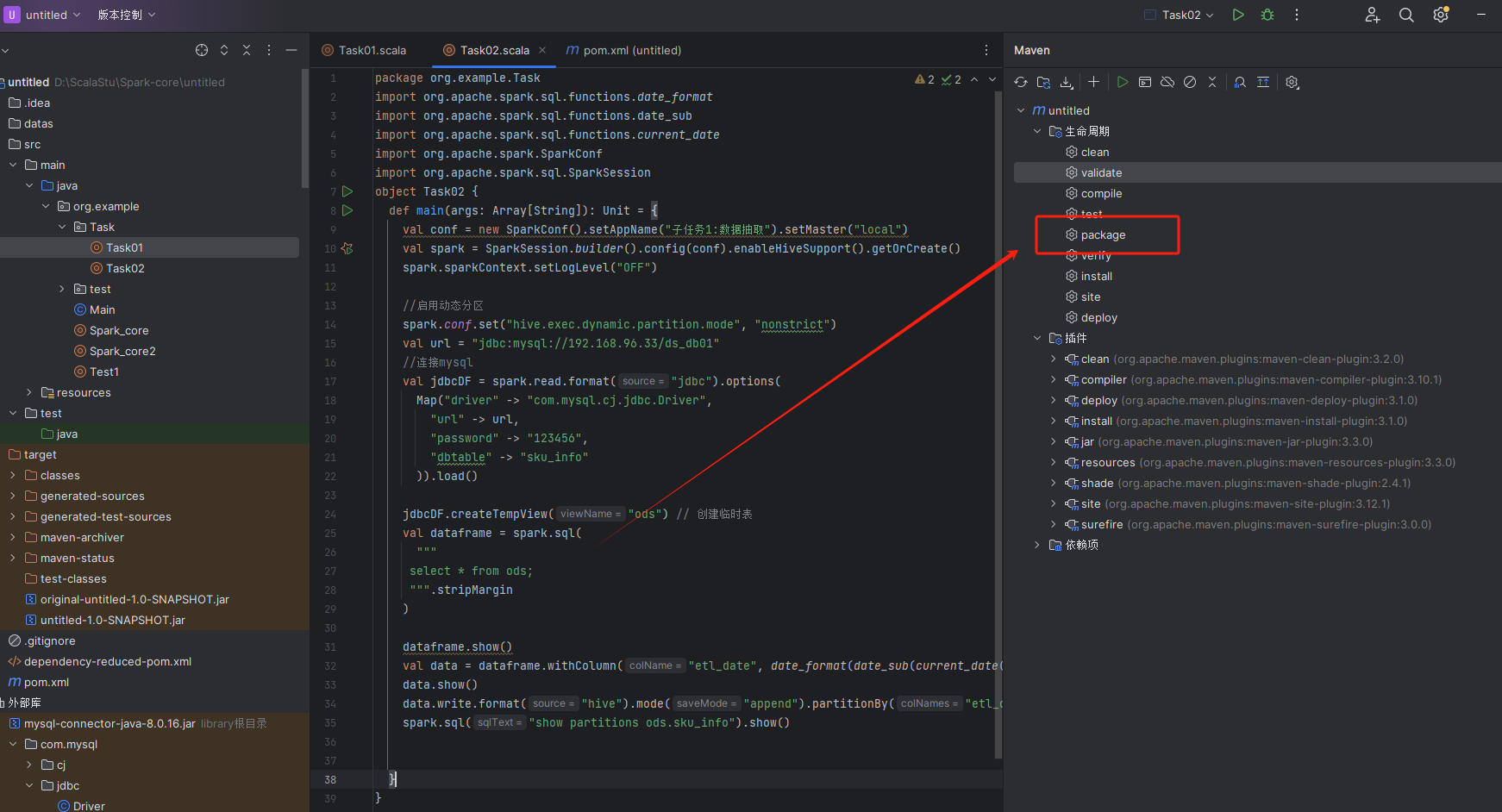
等待编译,由于引入了插件,所以会打出两个jar包,其中没有original的是我们需要的包。
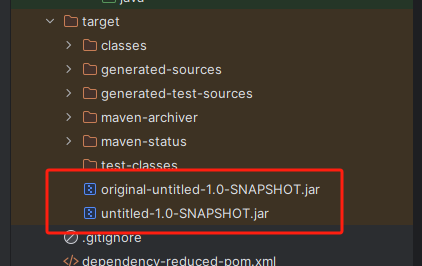
文件传输
使用scp命令或者文件传输工具将该jar包发送到集群中的一台机器上
scp -r unitiled-1.0-SNAPSHOT.jar root@master:/opt/
在集群中使用spark --submit命令执行jar包
spark-submit --class org.example.Task.Task01 --master yarn --deploy-mode client /opt/untitled-1.0-SNAPSHOT.jar
运行这个命令的时候有两个踩坑点
踩坑点(3):
如果不把打包第三方依赖的maven引入。或者程序中没有成功指定jdbc类都会报这样的错,如果出现这样的问题可以检查这两个地方。
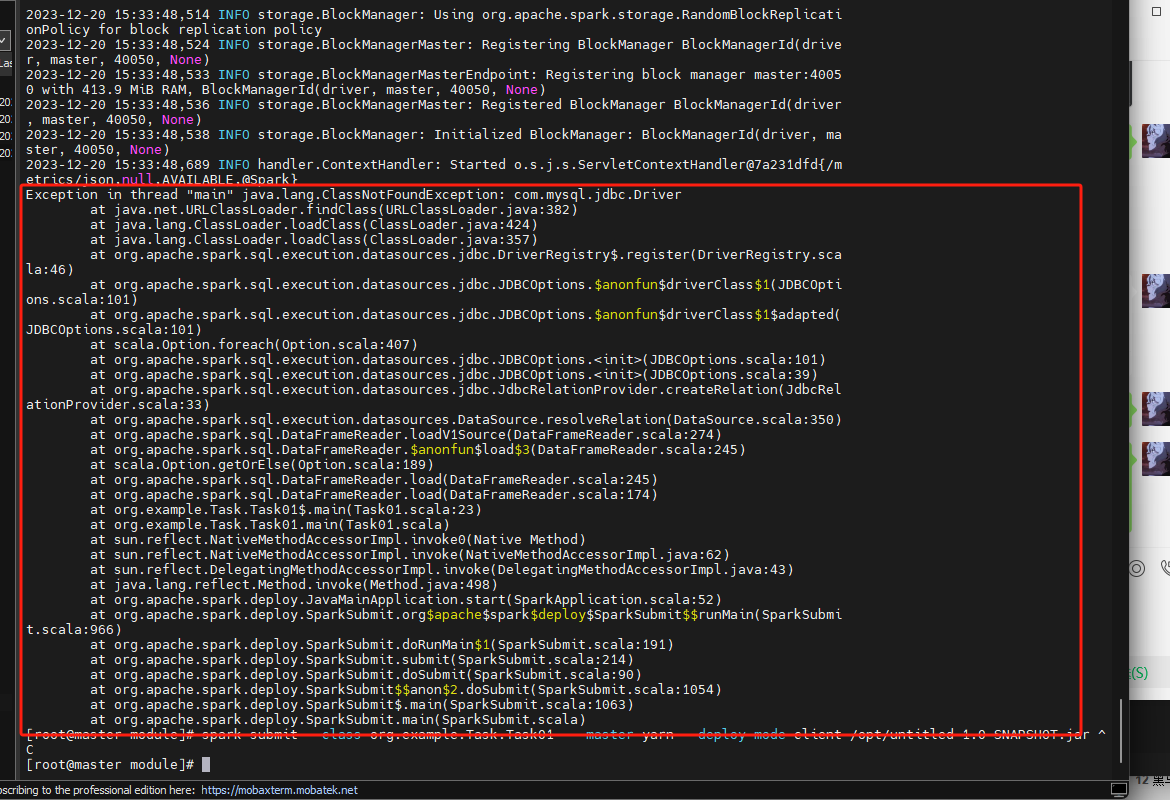
踩坑点(4):
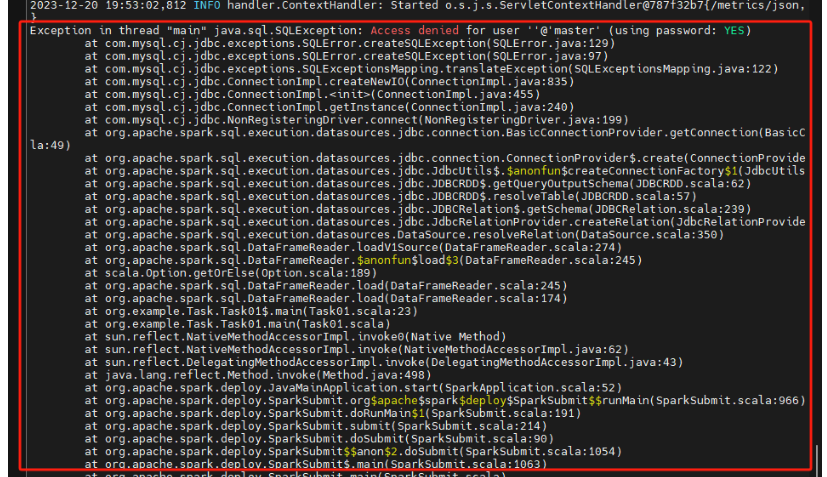
出现这个问题,网上的结局办法为:
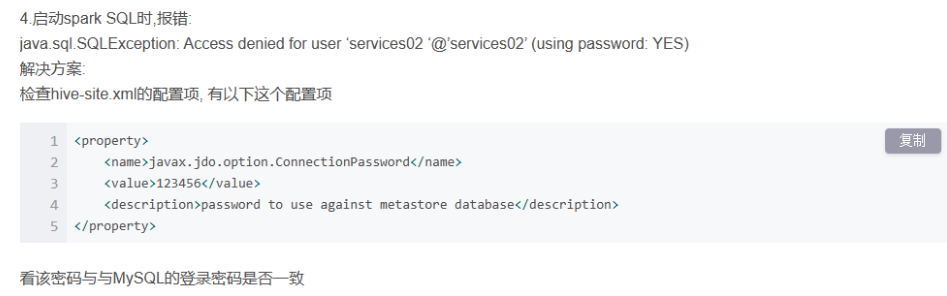
但是我尝试过并没有解决问题,我的解决方案为:
(1)在mysql中创建一个用户名为“”(空)的用户
(2)给这个用户所有的权限
grant all privileges on *.* to ""@"%";
flush privileges;
指令运行成功的结果为:
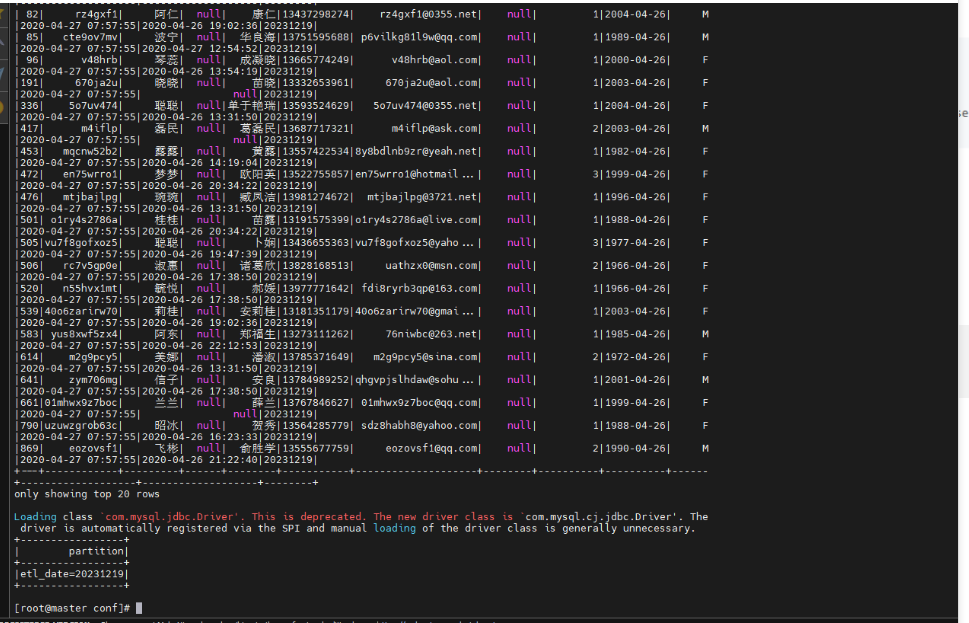
第二个任务和第一个任务完全一样,该个名字就可以。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!