【Python数据采集系列】利用协程并发采集豆瓣TOP250电影信息(源码解析)
2024-01-08 10:35:28
这是Python数据采集系列原创文章,我的第193篇原创文章。
一、引言
前文回顾:
Python语言高级实战-基于协程的方式来实现异步并发编程(附源码和实现效果)
【Python程序开发系列】进程、线程、协程?一文全面梳理多任务并发编程基本概念
Python数据分析实战-爬取豆瓣电影Top250的相关信息并将爬取的信息写入Excel表中(附源码和实现效果)
本期知识点:
? ? ? ? 协程在数据爬虫中的应用非常常见,特别是在需要高效地处理大量网络请求的情况下。我们之前学习过爬虫最重要的模块requests,但它是阻塞式的发起请求,每次请求发起后需阻塞等待其返回响应,不能做其他的事情。使用协程可以实现异步的网络请求和并发的数据处理,从而提高爬虫的效率和性能。
????? ??如果需要实现异步爬虫,就不能用requests,aiohttp就是基于asyncio实现的http框架,可以理解为aiohtpo是requests升级版本,可用于实现异步爬虫,优点就是更快于 requests 的同步爬虫。
????????本文以使用协程实现爬取豆瓣电影Top250并将信息写入Excel表格作为案例。
二、实现过程
完整代码
import asyncio
import aiohttp
import openpyxl
from bs4 import BeautifulSoup
async def fetch_movie_info(session, url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Cookie": "bid=m9sDMeuTWp4; ap_v=0,6.0; _pk_id.100001.4cf6=d6615bd2530852c6.1700447648.; _pk_ses.100001.4cf6=1; __utma=30149280.633232779.1700447649.1700447649.1700447649.1; __utmb=30149280.0.10.1700447649; __utmc=30149280; __utmz=30149280.1700447649.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1435231277.1700447649.1700447649.1700447649.1; __utmb=223695111.0.10.1700447649; __utmc=223695111; __utmz=223695111.1700447649.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _cc_id=748927837a892b664c1f1ab42fbe510a; panoramaId_expiry=1700534054317; panoramaId=18a92c0e9b136f927d0f0871ae33a9fb927a9d987bb8aa39557c58077684bc2c; panoramaIdType=panoDevice; _pbjs_userid_consent_data=3524755945110770; __gads=ID=7617c807b66fd695:T=1700447653:RT=1700448285:S=ALNI_MY0jxMNVX0GooLXe8dtdh74vfdLvQ; __gpi=UID=00000cdbaaf33934:T=1700447653:RT=1700448285:S=ALNI_MYekZkuVr46VHfZjhuhdX2kpLxOkw; cto_bundle=xIP-n181MjZFSVBGdlMlMkJEY3hvY3dycER1QjhISjdGU2dzOWxWZUFSMmNZd25VQ1Y0REdtaXZPdTh2aEJGUCUyQlo3WjVETzVNc2VUSFR3dHFXQVRRZU1ZejdOMXk5RDM4VjV1WkJsRWVXd1dQdjRvRE1JQjhEVkJQUVEyV0M1dlgzVkFBclZDTnJWM1g3MWZERDltRFR1UDZZNXp3JTNEJTNE; cto_bidid=vr7nBV8lMkZGJTJCOGVQWjhWREJUelpJYm1UdFBWaWd5bk9WT1JCdyUyRjlpN1duSWFZd3JPR2dkdmh1Q2tNa3NJa25rQTExSFlPM1p2YzdpT1U2cDE5UUowU3p1VHk3YkhVWWw4aFBmUExiZmtZdWtPS3U4byUzRA; cto_dna_bundle=14GGU181MjZFSVBGdlMlMkJEY3hvY3dycER1QiUyQmxhTVFwSEdNWHZ6OE5MZ2olMkJQbjlyODR2SWtIJTJCUGZmYm40Z3p5b1AxbSUyRkJKVDBVUVlXbGE1ZWRQeVUlMkJmeTR5dyUzRCUzRA",
}
async with session.get(url, headers=headers) as response:
data = await response.text()
return data
async def parse_movie_info(html):
# 在这里编写提取信息的代码,根据豆瓣电影页面的结构
# 提取导演、主演等信息,并返回一个字典
soup = BeautifulSoup(html, 'html.parser')
movie_elements = soup.find_all('div', class_='item')
movie_info_list = []
for movie_element in movie_elements:
# title_element = movie_element.find('div', class_='hd')
# title = title_element.find('span', class_='title').text
title = movie_element.find('span', class_='title').text
# print(title)
detail_link = movie_element.find('a')['href']
image_link = movie_element.find('img')['src']
rating = float(movie_element.find('span', class_='rating_num').text)
movie_info = {
'title': title,
'detail_link': detail_link,
'image_link': image_link,
'rating': rating
}
movie_info_list.append(movie_info)
return movie_info_list
async def write_to_excel(movie_info_lists):
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['title', 'detail_link', 'image_link', 'rating'])
for movie_info in movie_info_lists:
ws.append([movie_info['title'], movie_info['detail_link'], movie_info['image_link'], movie_info['rating']])
wb.save('douban_top250.xlsx')
async def main():
base_url = 'https://movie.douban.com/top250?start={}'
movie_info_lists = []
async with aiohttp.ClientSession() as session:
tasks = [fetch_movie_info(session, base_url.format(i)) for i in range(0, 250, 25)]
pages = await asyncio.gather(*tasks)
for page in pages:
movie_info_list = await parse_movie_info(page)
movie_info_lists.extend(movie_info_list)
await write_to_excel(movie_info_lists)
if __name__ == '__main__':
asyncio.run(main())代码解读
- 这里的函数全部都是异步函数,使用async关键字定义,使用await关键字来暂停函数的执行,等待异步操作完成后再继续执行。异步函数只能在其他异步函数中使用await来调用,或者在协程中使用awaitable对象的.await()方法来调用。
- 使用 async with aiohttp.ClientSession() as session 创建了一个异步HTTP客户端会话,使用async with session.get(url, headers=headers) as response语句使用这个会话来发起一个GET请求。response(session.get(url, headers=headers))是一个阻塞操作,所以需要await response.text()。main函数时主协程,fetch_movie_info函数是子协程。
- tasks是一个任务列表,里面每个元素是一个fetch_movie_info任务,即发出fet请求,返回每一页的网页内容,共10页10个任务。asyncio.gather()是asyncio库中的一个函数,用于并发地运行多个协程任务,并等待它们全部完成。由于一个任务返回一个response.text(),asyncio.gather()返回的就是所有任务的response.text(),也就是pages。
- 依次循环遍历pages,解析每一个page,返回所提取的这一页的25个电影信息列表movie_info_list,最终得到movie_info_lists
- 将movie_info_lists写入excel。
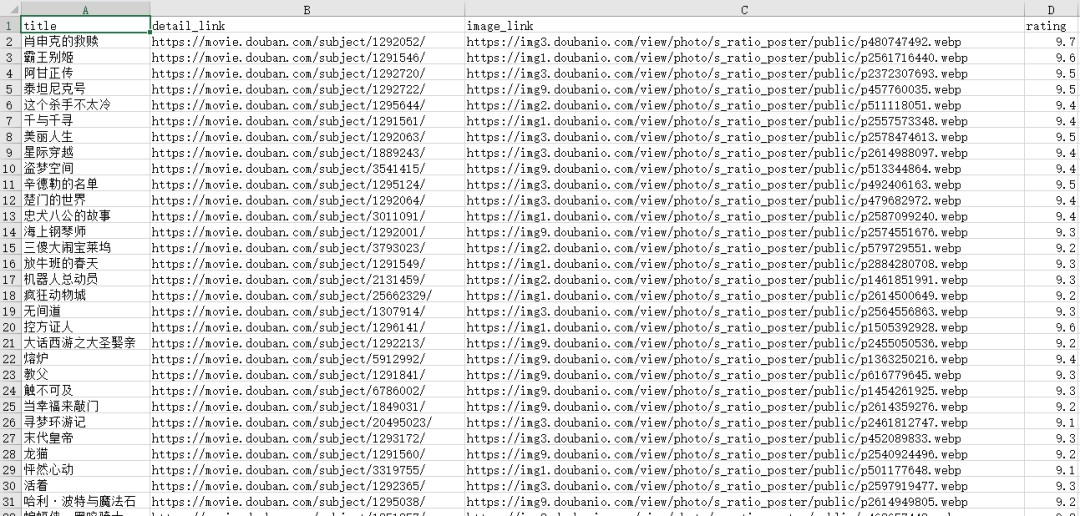
三、结果
douban_top250.xlsx:
本期内容就到这里,我们下期再见!需要数据集和源码的小伙伴可以关注底部公众号添加作者微信!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
文章来源:https://blog.csdn.net/sinat_41858359/article/details/135449063
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!