基于Jedis来探讨池化技术
为什么需要池化技术
系统运行时必然是需要数据库连接、线程等一些重量级对象,频繁的创建这种对象对性能有着不小的开销,所以为了减少没必要的创建和开销,我们就用到了池化技术。
通过创建一个资源池来保存这些资源便于后续的复用,从而提升系统性能。
池化技术实现的三种方式
一般来说使用池化技术的客户端有以下三种形式:
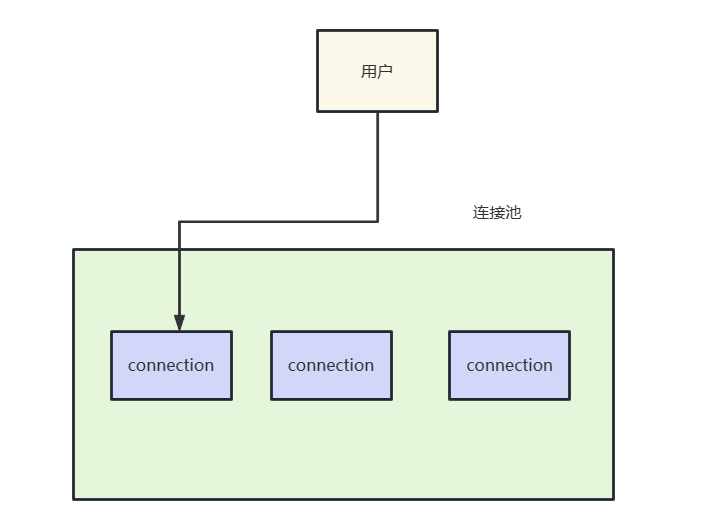
xxxPool和xxxConnection
这种池化方式的实现即我们从xxxPool获取到xxxConnection对象,我们在使用xxxConnection对象之后必须手动调用某些API将资源归还,否则可能会导致内存泄漏之类的问题。并且xxxConnection对象一般都是非线程安全的,多线程操作这类对象很可能导致一些意外情况发生。
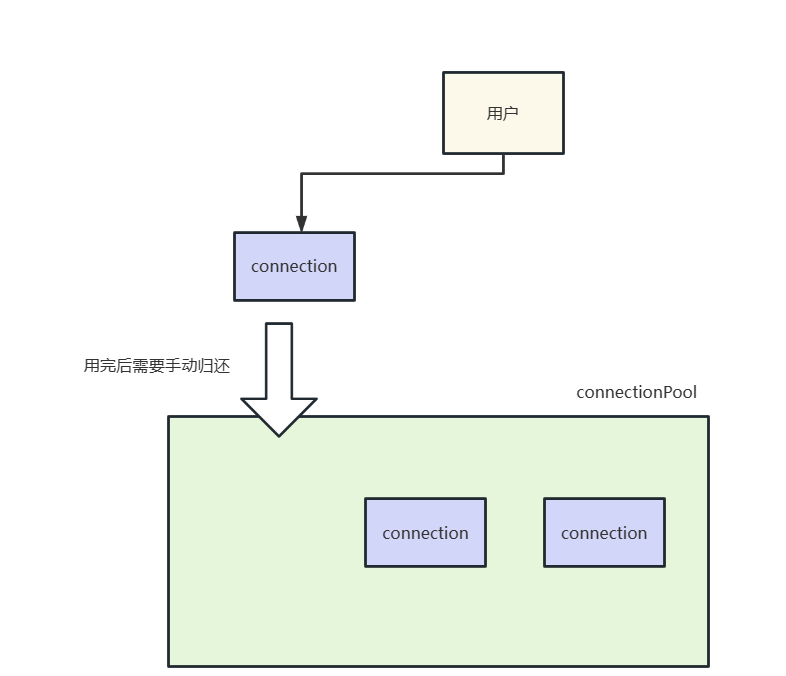
xxxClient和xxxPool
xxxClient这种形式用法一般都是从xxxPool获取这个对象,我们使用完成后无需手动将资源归还,xxxClient会自动完成这种操作,一般来说这种对象都是线程安全的。
xxxConnection对象
xxxConnection就是一个单独的连接对象,是一个完全的单一连接对象,不仅性能一般,还需要手动获取和释放,使用不当极可能导致线程安全问题。
Jedis使用不当导致的线程安全问题
前置步骤
在完成这个实验之前我们必须完成对实验环境的搭建,首先肯定是下载并启动redis服务端,由于笔者使用的是Windows系统,所以这里就简单的下载了一个Windows环境下的redis。下载地址为:
https://github.com/tporadowski/redis/releases
首先自然是在spring boot项目中引入jedis的依赖:
<!--jedis依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
完成这些步骤之后,我们编写一个简单的测试用例测试一下连通性
public class JedisTest {
private static Logger logger = LoggerFactory.getLogger(JedisTest.class);
/**
* 测试ping
*/
@Test
public void testPing() {
Jedis jedis = null;
try {
jedis = new Jedis("127.0.0.1");
String result = jedis.ping();
Assert.isTrue("PONG".equals(result),"unable to connect redis");
} finally {
jedis.close();
}
}
}
从输出结果来看,环境准备完成了,接下来就可以开始实验了。
问题重现
为了方便实验,我们首先基于redis客户端往redis中设置两个值,分别是是(a,1)和(b,2)
try (Jedis jedis = new Jedis("127.0.0.1", 6379)) {
Assert.isTrue("OK".equals(jedis.set("a", "1")), "set a=1 return ok");
Assert.isTrue("OK".equals(jedis.set("b", "2")), "set b=2 return ok");
}
然后我们再编写下面这样一段代码,可以看到两个线程都是用同一个redis客户端获取对象,线程1获取a的值,如果不为1,则输出一段警告。线程不断获取b的值,如果b的value不为2则也输出一段警告。
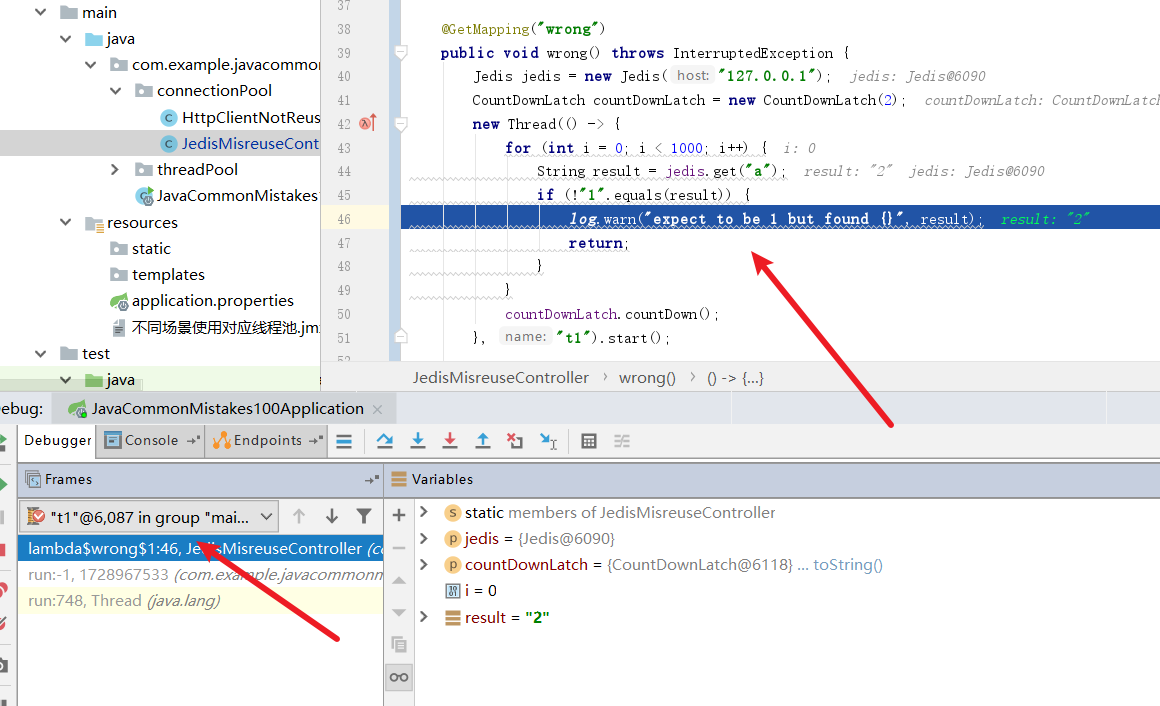
@GetMapping("wrong")
public void wrong() throws InterruptedException {
Jedis jedis = new Jedis("127.0.0.1");
CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("a");
if (!"1".equals(result)) {
log.warn("expect to be 1 but found {}", result);
return;
}
}
countDownLatch.countDown();
}, "t1").start();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("b");
if (!"2".equals(result)) {
log.warn("expect to be 2 but found {}", result);
return;
}
}
countDownLatch.countDown();
}, "t2").start();
countDownLatch.await();
}
我们将项目进行启动测试并测试该接口,可以看到该接口报错了。
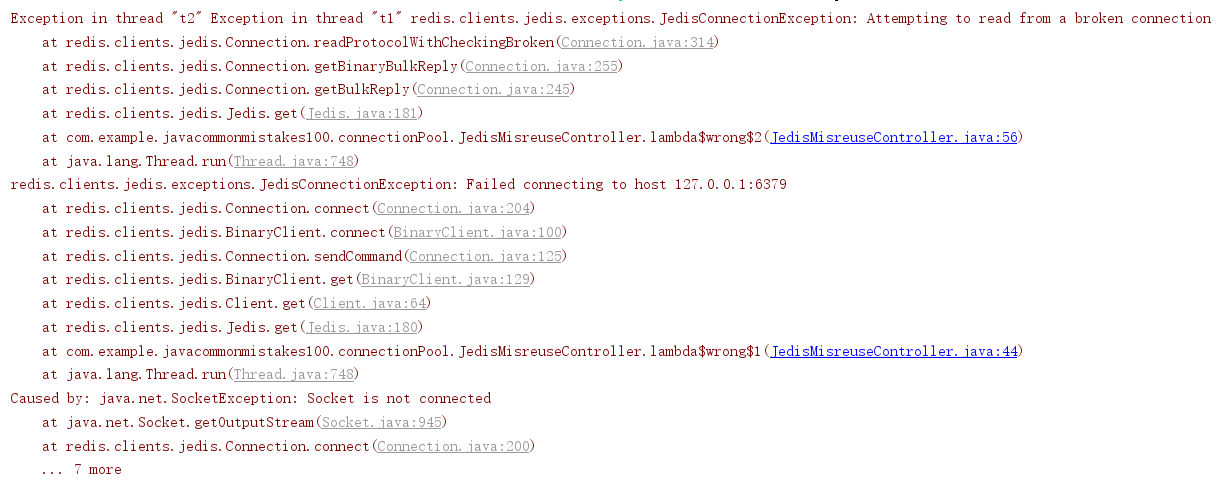
经过笔者不断点击调试,获取到的a的值变为2,出现了线程安全问题。

阅读源码了解究竟
我们的问题发生在get所以我们不妨从get方法中查看究竟。
从源码中可以看到get方法获取值是通过一个client对象的get方法获取的,我们不妨步入看看具体逻辑。
@Override
public String get(final String key) {
checkIsInMultiOrPipeline();
client.get(key);
return client.getBulkReply();
}
可以看到client的get方法还是通过一个get方法完成value的获取,我们再步入看看
@Override
public void get(final String key) {
get(SafeEncoder.encode(key));
}
再次步入后,我们来到了BinaryClient类的get方法,它的逻辑是发送一个get的命令,以key作为参数来完成值的获取的,我们不妨在步入看看细节。
public void get(final byte[] key) {
sendCommand(GET, key);
}
最终,我们来到了Connection对象了,可以看到在多线程情况下,多个线程获取的值会写到同一个outputStream中,这就是造成我们线程安全的原因所在。
//Connection共用一个outputStream对象
private RedisOutputStream outputStream;
public void sendCommand(final ProtocolCommand cmd, final byte[]... args) {
try {
//建立连接
connect();
//向服务端发送cmd命令,参数为args,将结果写入outputStream中
Protocol.sendCommand(outputStream, cmd, args);
} catch (JedisConnectionException ex) {
broken = true;
throw ex;
}
}
除了这一处之外,还有一个地方,我们回到get方法,可以看到return语句后面跟着一个getBulkReply方法,我们步入看看。
@Override
public String get(final String key) {
checkIsInMultiOrPipeline();
client.get(key);
return client.getBulkReply();
}
可以看到redis的结果是从getBinaryBulkReply中获取,再通过SafeEncoder.encode转码返回给客户端的,所以我不妨看看getBinaryBulkReply是如何完成值的获取的。
public String getBulkReply() {
final byte[] result = getBinaryBulkReply();
if (null != result) {
return SafeEncoder.encode(result);
} else {
return null;
}
}
重点来了,可以看到结果是通过flush将结果写入某个地方,然后再通过readProtocolWithCheckingBroken返回的,我们再次步入看看flush做了什么。
public byte[] getBinaryBulkReply() {
flush();
return (byte[]) readProtocolWithCheckingBroken();
}
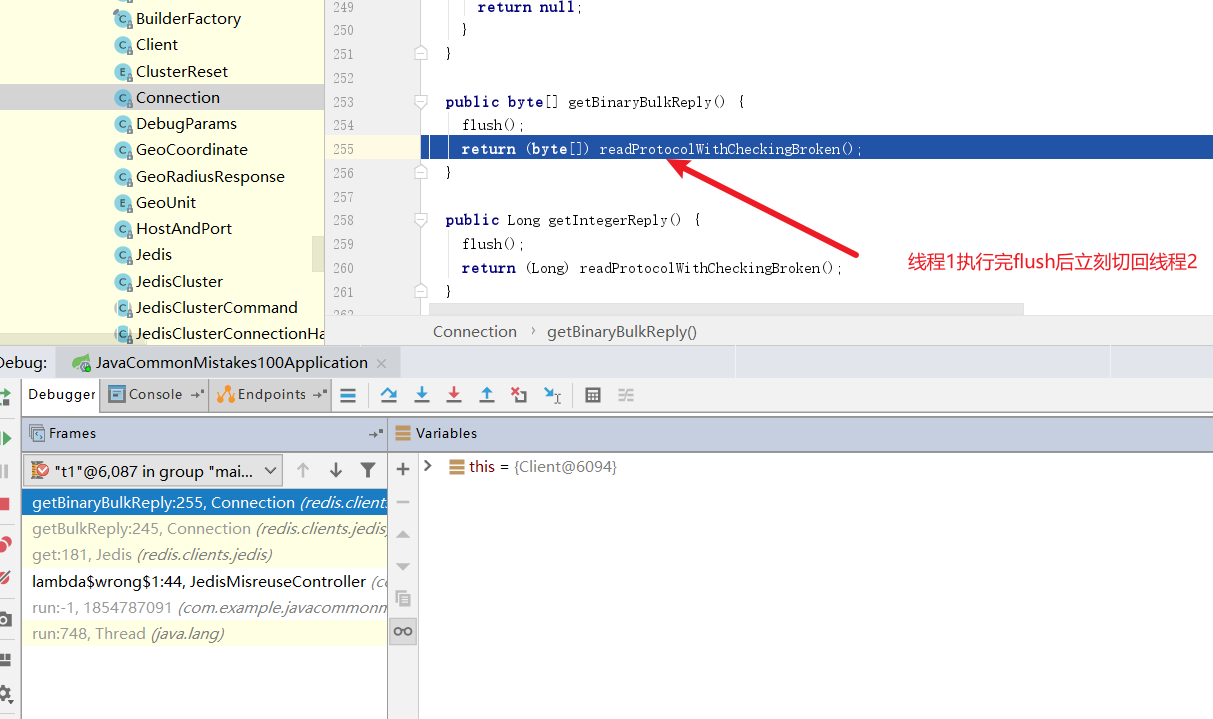
可以看到这个flush方法就是将上文的outputStream的值刷到缓冲区中,试想一下,我们线程1执行完flush就被挂起,然后线程2执行flush的话,线程1是不是就可以拿到线程2的结果呢?
protected void flush() {
try {
outputStream.flush();
} catch (IOException ex) {
broken = true;
throw new JedisConnectionException(ex);
}
}
基于debug剖析原因
为了印证上文中说到的线程1调用flush后线程2再次flush将导致线程1取到线程2的猜想,我们不妨通过debug的方式来重现这个问题。
我们不妨在jedis的get方法上使用thread模式打个断点。
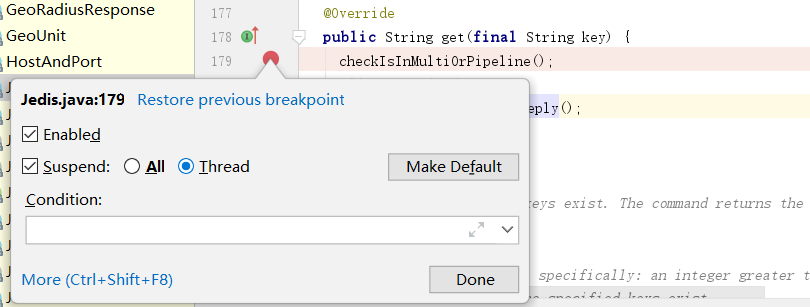
然后启动项目开始debug,首先将线程1执行到flush后切换到线程2
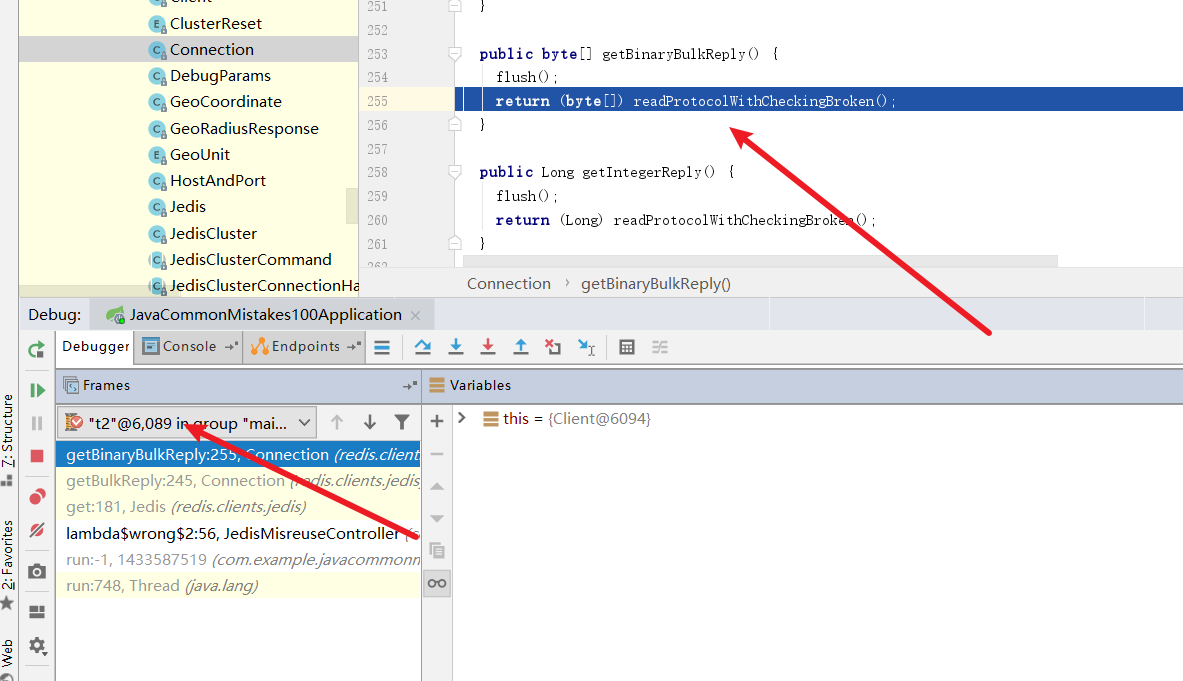
然后让线程2也执行完flush,并将readProtocolWithCheckingBroken走完,让结果存到inputStream中。
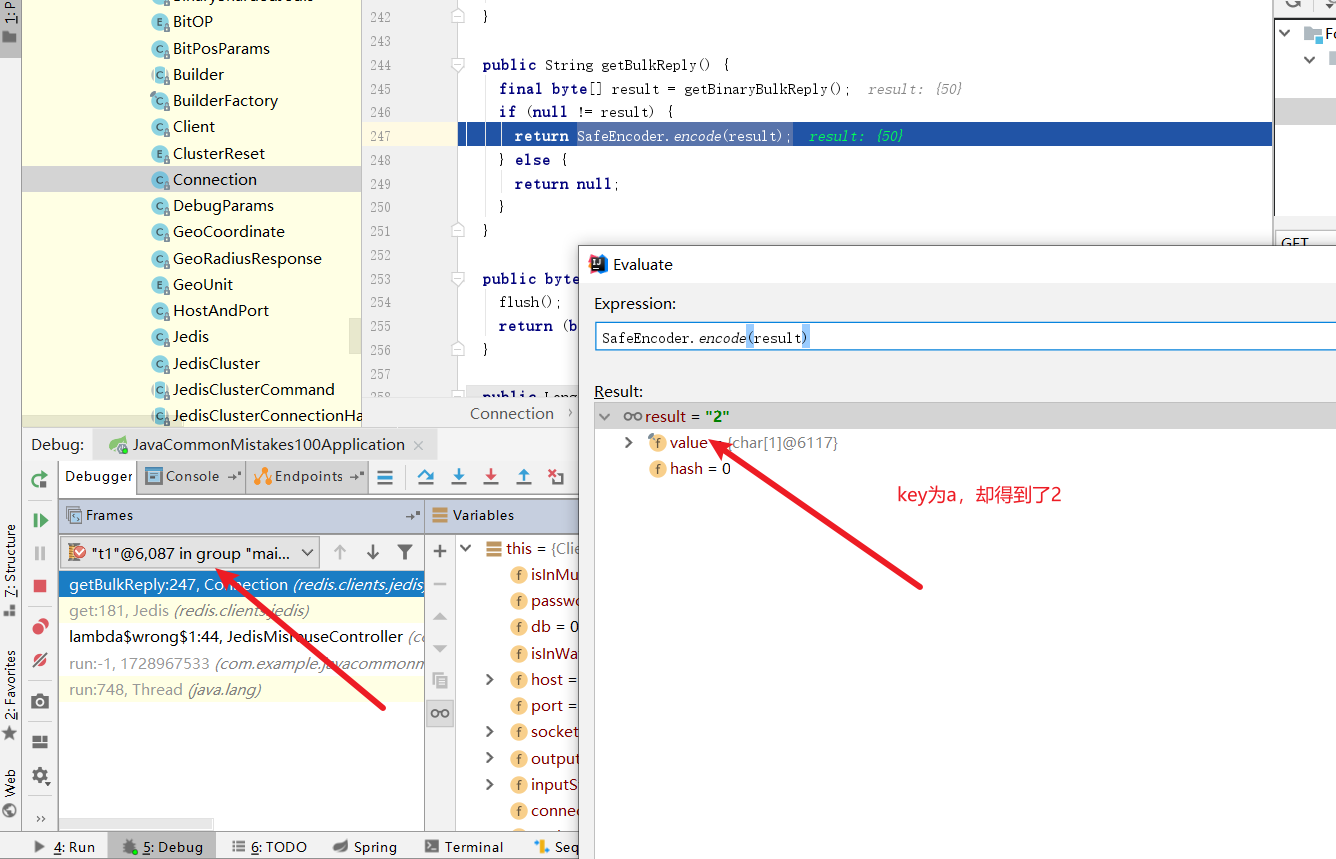
最后我们将线程切回线程1,可以看到key为a却得到了2,线程安全问题重现。
最终代码输出了警告
解决方案
从源码中我们可以看出每一个jedis都相当于一个connection对象,它是属于我们说的第一种连接池,从pool中获取xxxConnection的情况,获取后需要我们手动归还。连接池声明代码如下:
private static JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);
因为jedisPool中获取的都是jedis对象,我们想了解一下为什么无论连接池还是单jedis对象都能通过close方法关闭或者归还对象,我们查看了一下close方法:
可以看到源码中又做了判断,如果是线程池中的对象,则调用returnBrokenResource或returnResource归还,如果是我们自己创建的Jedis对象,则调用close关闭资源。
@Override
public void close() {
//如果是线程池中的对象,则调用returnBrokenResource或returnResource归还
if (dataSource != null) {
JedisPoolAbstract pool = this.dataSource;
this.dataSource = null;
if (client.isBroken()) {
pool.returnBrokenResource(this);
} else {
pool.returnResource(this);
}
} else {
//如果是我们自己创建的Jedis对象,则调用close
super.close();
}
}
为了保证项目关闭之后连接池能够正确关闭,我们可以使用PostConstruct确保在bean完成依赖注入之后,添加一个销毁jedisPool 的钩子方法。
@PostConstruct
public void init() {
Runtime.getRuntime().addShutdownHook(new Thread(()->{
jedisPool.close();
}));
}
然后就可以修改我们的接口了,这样一来每一个线程使用的都是从连接池中获取的对象,因为Jedis继承了Closeable,所以我们可以用JDK的try语法完成close逻辑。就不会有线程安全问题了。
@GetMapping("right")
public void right() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(() -> {
try (Jedis jedis=jedisPool.getResource()) {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("a");
if (!"1".equals(result)) {
log.warn("expect to be 1 but found {}", result);
return;
}
}
countDownLatch.countDown();
}
}, "t1").start();
new Thread(() -> {
try (Jedis jedis=jedisPool.getResource()) {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("b");
if (!"2".equals(result)) {
log.warn("expect to be 2 but found {}", result);
return;
}
}
countDownLatch.countDown();
}
}, "t2").start();
countDownLatch.await();
}
小结
从本例子中可以看到笔者使用池化技术时的几个注意点:
- 根据源码推测池化技术的设计方式和使用方法。
- 基于多线程模式debug排查和印证,并使用池化技术解决问题。
- 时刻保持对池化资源的归还和关闭工作。
使用和不使用池化技术性能之间的差距
问题简介
上文我们提到了池化技术的重要性,接下来我们就基于apache客户端来了解一下不同的池化技术运用方式之间的差距。
前置步骤
为了更好的完成实验,我们可以必须在服务器中安装一个轻量级压测工具wrk,读者可以参考笔者写的这篇文章:
为了更好查看池化技术之间网络交互过程,我们同样还需要安装一下Wireshark,读者可以参考这篇文章:
完成好这些步骤之后,我们就可以开始进行实践了,首先打开我们的spring boot项目(端口号设置为45678),引入httpclient的依赖:
<!--httpclient依赖-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
错误的池化使用示例
先来看看错误的示例,可以看到笔者的使用方式可以说是非常低级的,每次请求进来都去创建一个连接池,然后从连接池中获取一个连接调用test接口。
@GetMapping("wrong2")
public String wrong2() {
//每次请求进来都创建一个连接池
try (
CloseableHttpClient client = HttpClients.custom()
//连接池的连接数为1
.setMaxConnTotal(1)
.setConnectionManager(new PoolingHttpClientConnectionManager())
.evictIdleConnections(60, TimeUnit.SECONDS)
.build();
//使用连接池中的连接调用同一个项目下的test方法
CloseableHttpResponse response = client.execute(new HttpGet("http://127.0.0.1:45678/httpclientnotreuse/test"))) {
return EntityUtils.toString(response.getEntity());
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
@GetMapping("/test")
public String test() {
return "OK";
}
编写完成之后,我们不妨在服务器中将项目启动,并使用wrk进行压测。
如下所示,我们使用一个线程和一个连接对接口压测10s。
wrk -t1 -c1 -d10s --latency http://localhost:45678/httpclientnotreuse/wrong2
压测结果如下,可以看到qps为414.01。
Running 10s test @ http://localhost:45678/httpclientnotreuse/wrong2
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.49ms 1.23ms 12.12ms 89.16%
Req/Sec 415.93 88.45 620.00 70.00%
Latency Distribution
50% 2.06ms
75% 2.96ms
90% 3.80ms
99% 7.65ms
4144 requests in 10.01s, 466.15KB read
Requests/sec: 414.01
Transfer/sec: 46.57KB
然后我们再通过服务器进行抓包了解一下压测通信过程详情。
如下命令所示,笔者使用tcpdump对45678端口(即我们的web项目端口)进行抓包,并将结果写到wrong2.pcap文件中。
tcpdump -i any tcp and port 45678 -w wrong2.pcap
开启抓包命令之后,我们再打开一个终端对接口进行压测,完成后将pcap文件下载到本地用Wireshark打开。
如下所示,我们在Wireshark过滤一栏键入下面的指令。
tcp.port == 45678 && http
并将源端口号应用为列以便观察数据。
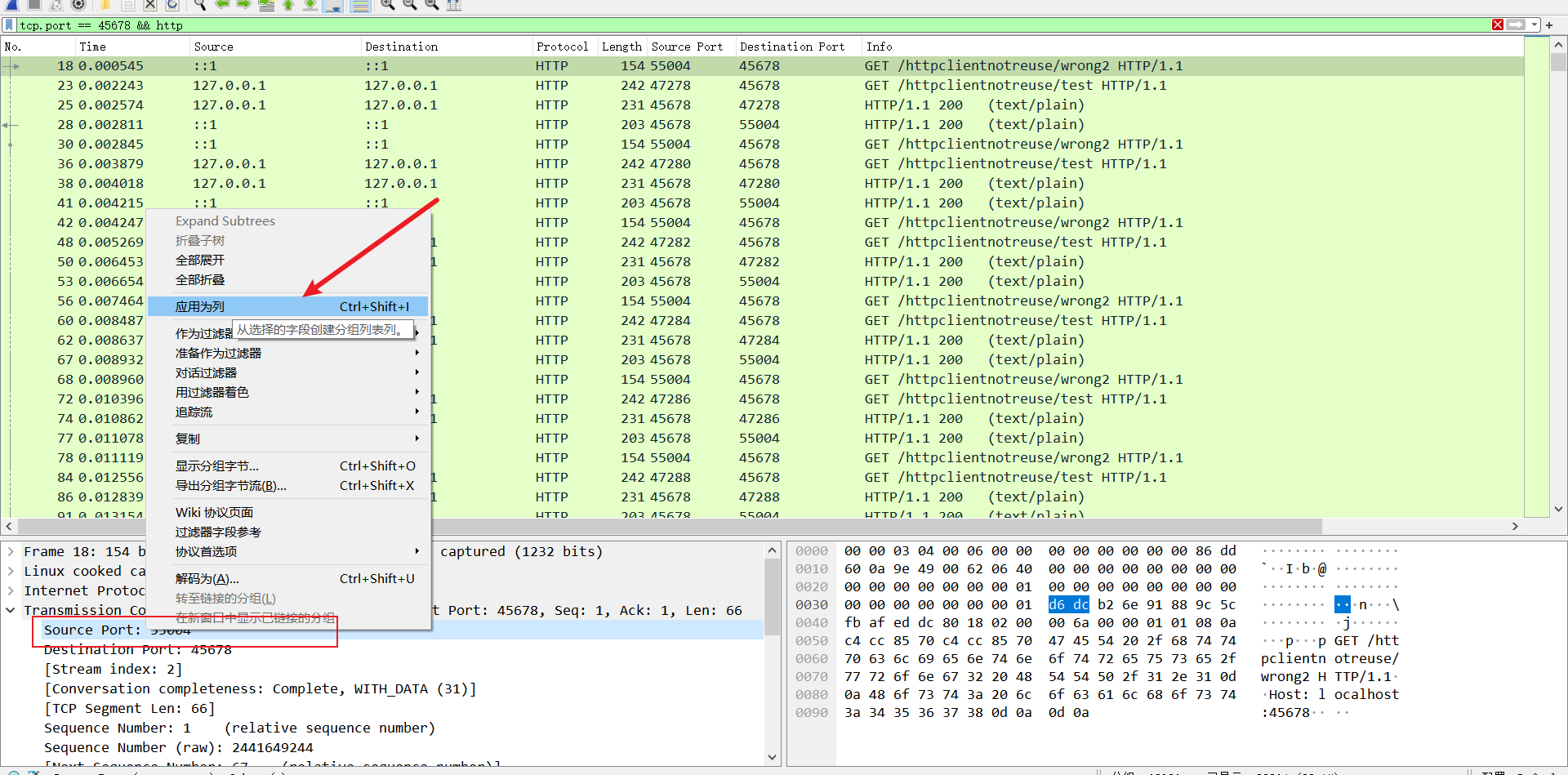
可以看到每一个请求test接口的源端口号都不一样,很明显,每次发起请求时都是发起test请求时,都进行了TCP三次握手再请求的过程。
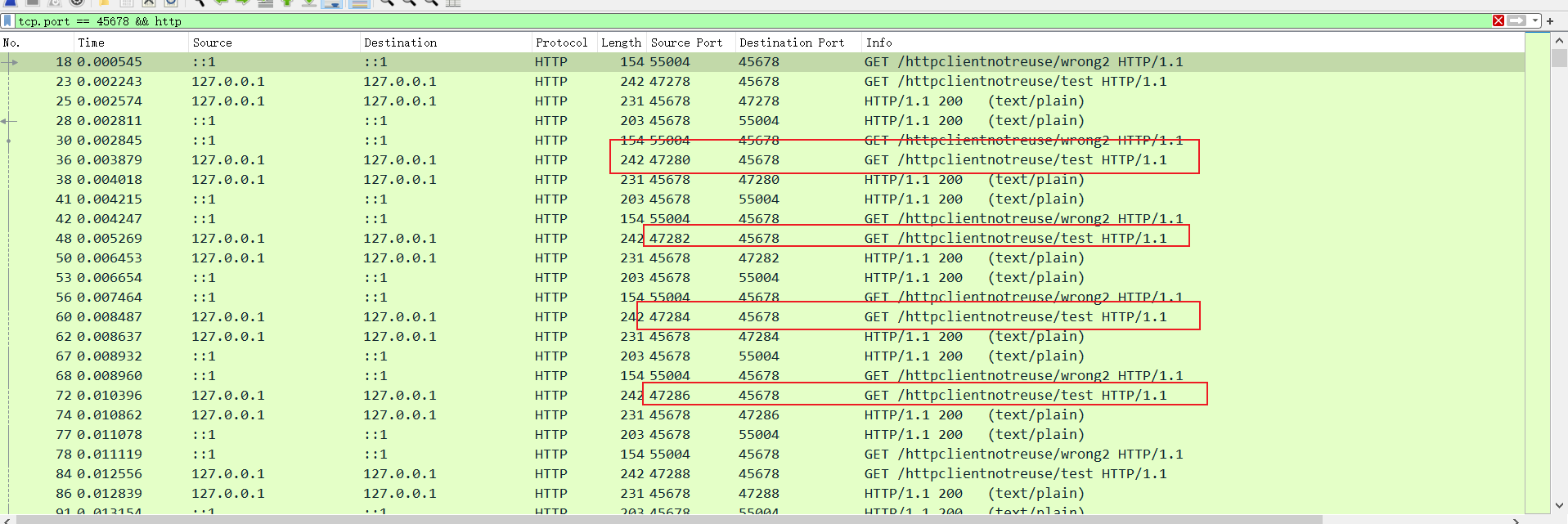
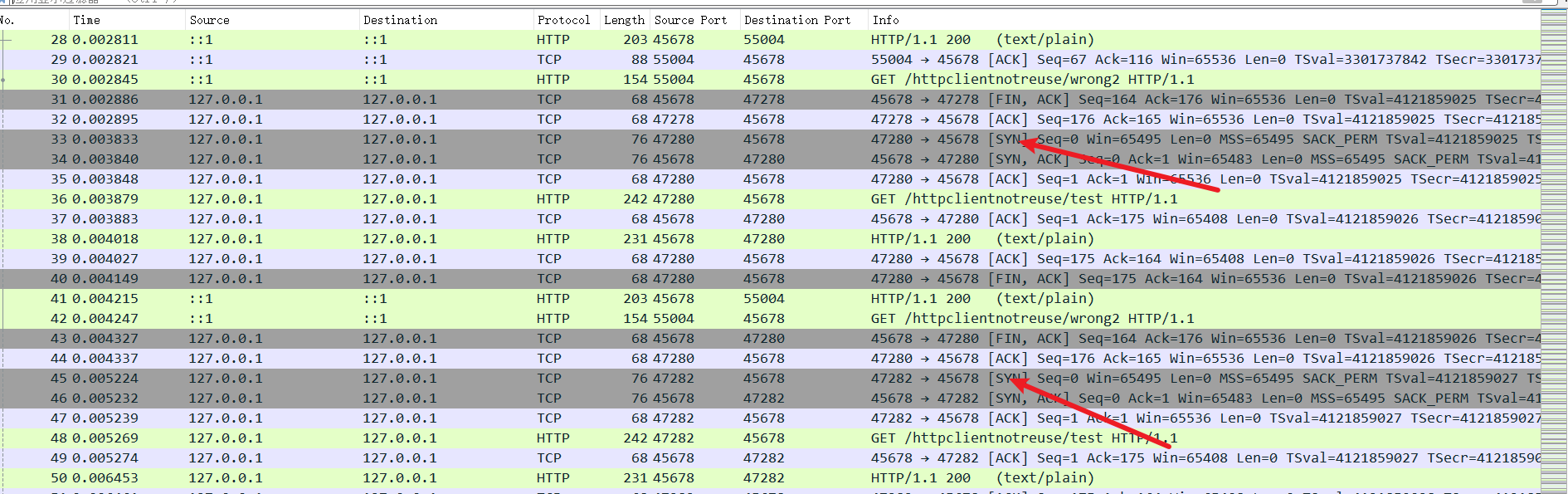
我们不妨将过滤条件删除,可以看到,抓包记录中大量的SYN包,很明显大量的HTTP请求都是先进行TCP三次握手了。
正确的池化使用示例
接下来我们再来看看正确池化的效果。首先我们会在类中声明一个全局静态连接池
private static CloseableHttpClient client = null;
static {
client = HttpClients.custom()
.setMaxConnTotal(1)
.setConnectionManager(new PoolingHttpClientConnectionManager())
.evictIdleConnections(60, TimeUnit.SECONDS)
.build();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}));
}
然后我们的连接池则是直接使用这个连接池发起http请求的。
@GetMapping("right")
public String right() {
try (CloseableHttpResponse response = client.execute(new HttpGet("http://127.0.0.1:45678/httpclientnotreuse/test"))) {
return EntityUtils.toString(response.getEntity());
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
然后我们使用同样的参数对这个接口进行压测
wrk -t1 -c1 -d10s --latency http://localhost:45678/httpclientnotreuse/right
从压测结果来看,qps为3337.56,很明显正确的使用池化技术对性能是有着质的提高。
Running 10s test @ http://localhost:45678/httpclientnotreuse/right
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 764.22us 4.52ms 82.06ms 98.54%
Req/Sec 3.37k 478.07 4.16k 73.00%
Latency Distribution
50% 274.00us
75% 316.00us
90% 379.00us
99% 15.98ms
33637 requests in 10.08s, 3.70MB read
Requests/sec: 3337.56
Transfer/sec: 375.44KB
我们使用同样的方式进行抓包
tcpdump -i any tcp and port 45678 -w right.pcap
从抓包记录来看,很明显发起http请求的接口都是47402,都是复用同一个TCP连接。
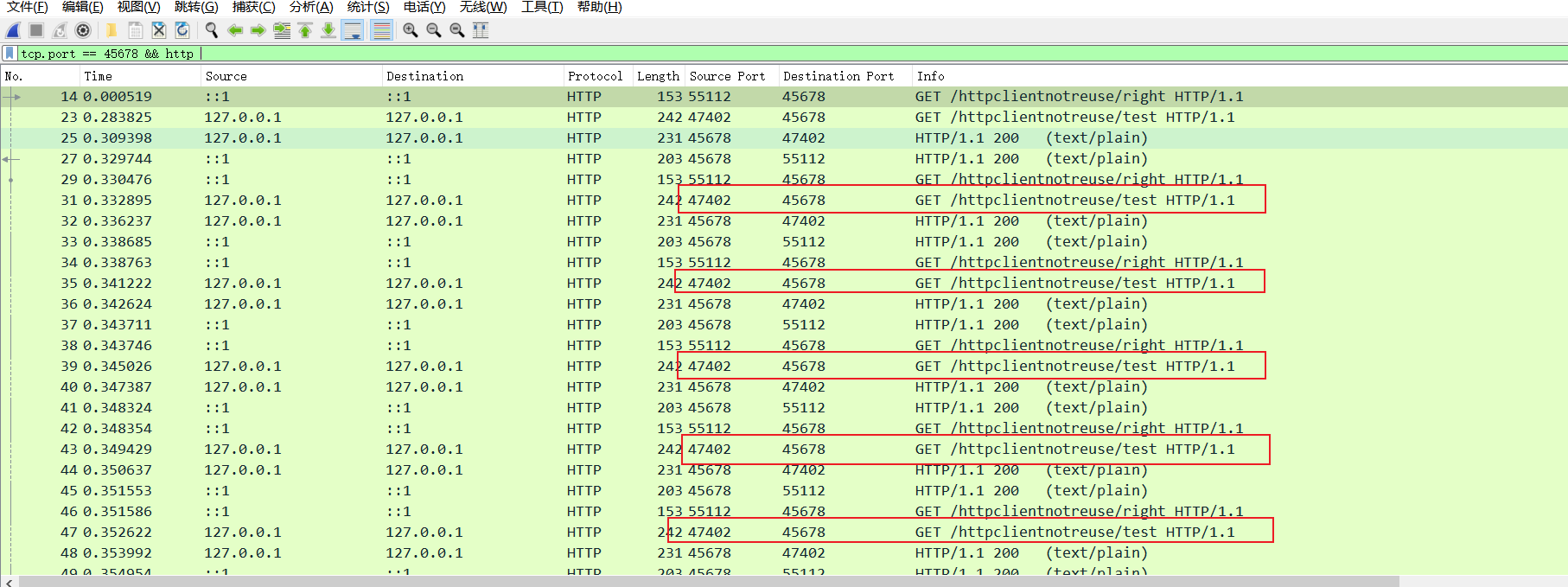
小结池化技术性能压测实验
这里我们通过wrk压测和Wireshark抓包对池化技术使用细节进行了进一步了解,很明显正确的使用池化技术可以复用资源,避免资源没必要的创建和销毁,进而提高服务器每秒处理请求数即QPS。
池化配置问题
最大连接数的配置可能造成的问题
既然聊到池化技术,那么我们就来了解一下池化技术中关于连接池的配置问题。我们使用连接池时都会设置连接池参数的配置,这里面可能会涉及一个比较常用的配置,最大连接数。
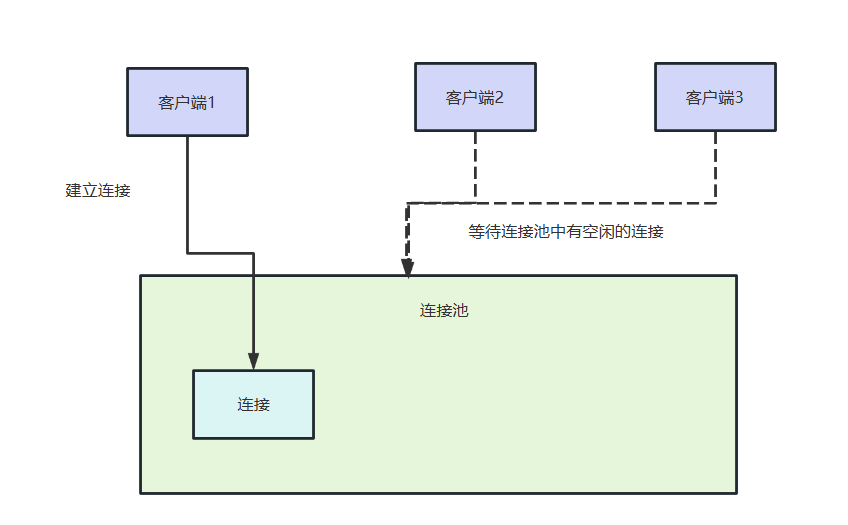
这个参数我们必须谨慎,如果连接参数过小,极可能导致大量客户端等待连接,导致吞吐量下降。
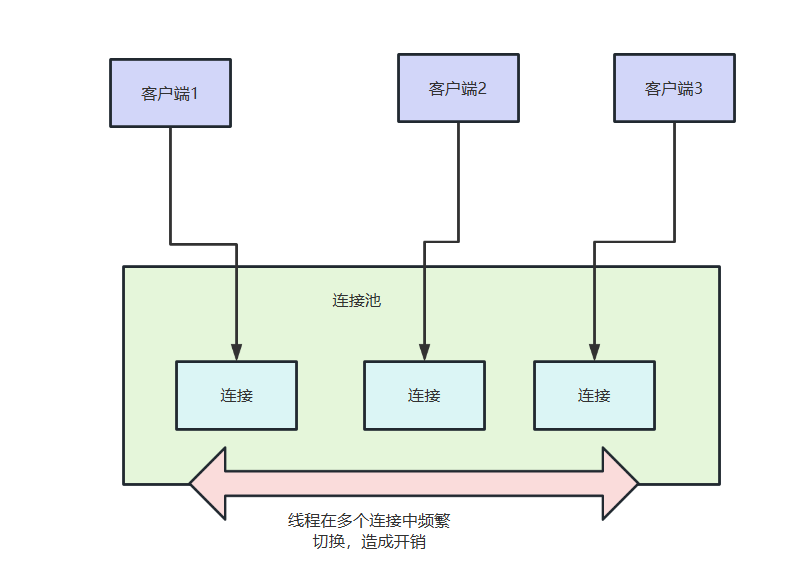
而连接数设置过大又可能会增加服务端维护连接池的开销,以及大量客户端通过这些连接和服务端建立远程交互进而造成大量线程切换的开销。
基于数据库连接池复现问题
我们不妨基于spring boot jpa写一段保存用户信息的功能来模拟一下数据库连接池被打满的情况。
首先我们引入JPA和MySQL的依赖。
<!-- jpa -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- myql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
建立一张user表
-- wiki.`user` definition
CREATE TABLE `user` (
`id` char(8) NOT NULL DEFAULT '' COMMENT 'id',
`login_name` varchar(50) NOT NULL COMMENT '登陆名',
`name` varchar(50) DEFAULT NULL COMMENT '昵称',
`password` char(32) NOT NULL COMMENT '密码',
`pass_word` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `login_name_unique` (`login_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户';
编写user表对应的实体类
@Entity
@Data
public class User {
@Id
@GeneratedValue(strategy = AUTO)
private Long id;
private String name;
private String loginName;
private String password;
}
编写user表持久层代码,代码很简单,集成JPA类即可,具体的逻辑该类都为我们实现了,我们只需指定泛型即可。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}
服务层代码如下所示,逻辑很简单,创建一个实体类调用持久层UserRepository 保存即可,注意我们为了模拟真实环境的某些复杂业务,这个功能我们加了事务并且还让其休眠500ms。
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public User register() {
User user = new User();
user.setName("new-user-" + System.currentTimeMillis());
user.setLoginName("new-user-" + System.currentTimeMillis());
user.setPassword("123");
userRepository.save(user);
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return user;
}
}
最后是控制层代码。
@Autowired
private UserService userService;
@GetMapping("test")
public Object test() {
return userService.register();
}
因为我们后续会用到jconsole,所以我们会在配置文件中添加下面这段配置,使得我们可以在jconsole的mbean中看到这个信息。
spring.datasource.hikari.register-mbeans=true
为了保证文章完整性,这里也把数据库连接配置贴上:
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.datasource.url=jdbc:mysql://xxxxxxx
spring.datasource.username = xxxxxxx
spring.datasource.password = xxxx
spring.datasource.platform=mysql
spring.jpa.open-in-view=false
然后我们会将这个项目打包到服务器上,为了能让本地jconsole监控到该服务信息我们启动时会添加下面几个参数,
java
-Djava.rmi.server.hostname=xxxx #远程服务器ip
-Dcom.sun.management.jmxremote #允许JMX远程调用
-Dcom.sun.management.jmxremote.port=3214 #允许JMX远程调用的端口号,后续我们的jmx就可以通过该ip和该端口和应用建立连接
-Dcom.sun.management.jmxremote.ssl=false # 是否开启ssl
-Dcom.sun.management.jmxremote.authenticate=false # 是否开启ssl
-jar
java-common-mistakes.jar
项目启动后我们可能还需要进行这样一步操作,以笔者为例项目启动时JVM远程调用端口号为3214,但是放行该端口后还是无法连接,查阅网上资料了解到还有别的端口需要放行,所以我们需要键入下面这条命令
netstat -apn |grep java
最终输出这样结果,可以看到除了应用端口和JMX远程调用端口以外,还有34751和36709两个端口,所以我们一并将其放行。

完成后我们就可以使用jconsole进行远程连接了,打开JConsole输入应用的ip+JMX远程调用端口号即可,以笔者为例则是:i
ip:3214
接下来我们就可以在JConsole中看到连接池的信息了,可以看到默认情况下,最大连接数为10:
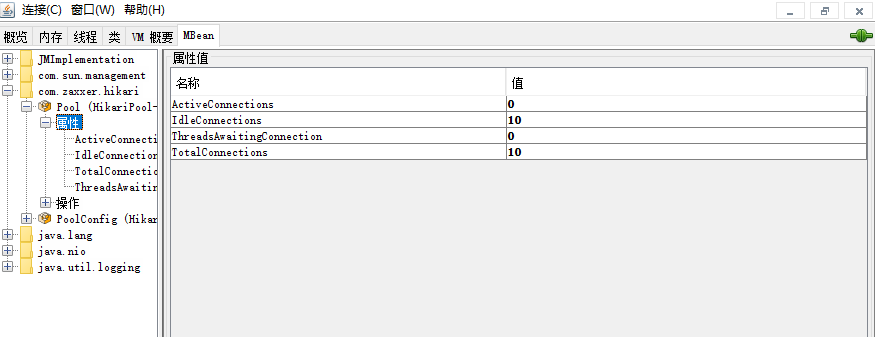
我们不妨基于wrk进行一次压测,因为笔者的服务器为双核,所以使用了20个线程进行压测:
wrk -t20 -c20 -d30s --latency http://localhost:45678/improperdatasourcepoolsize/test
可以看到在现有连接池都被占用,大量连接处于等待状态,导致大量请求报错:
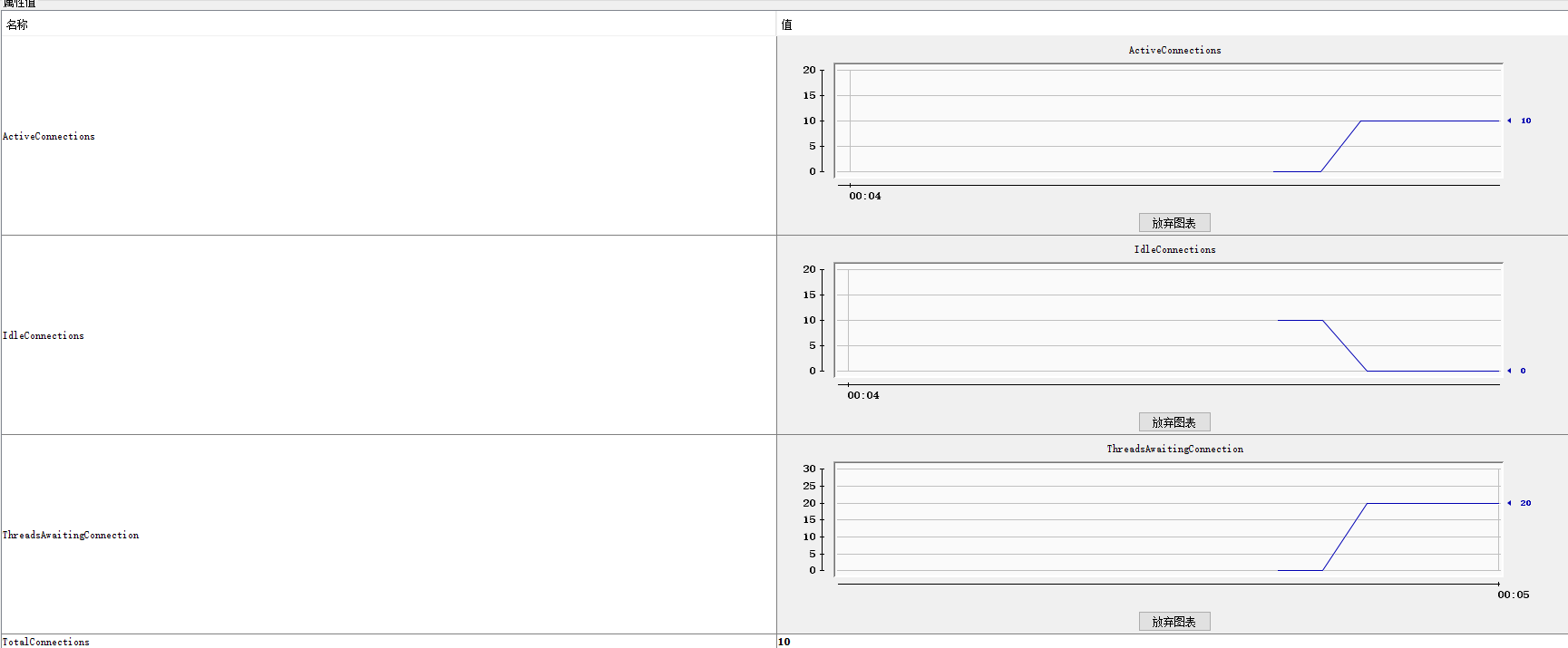
报错内容基本都为超时
unable to obtain isolated JDBC connection] with root cause
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms.
解决思路
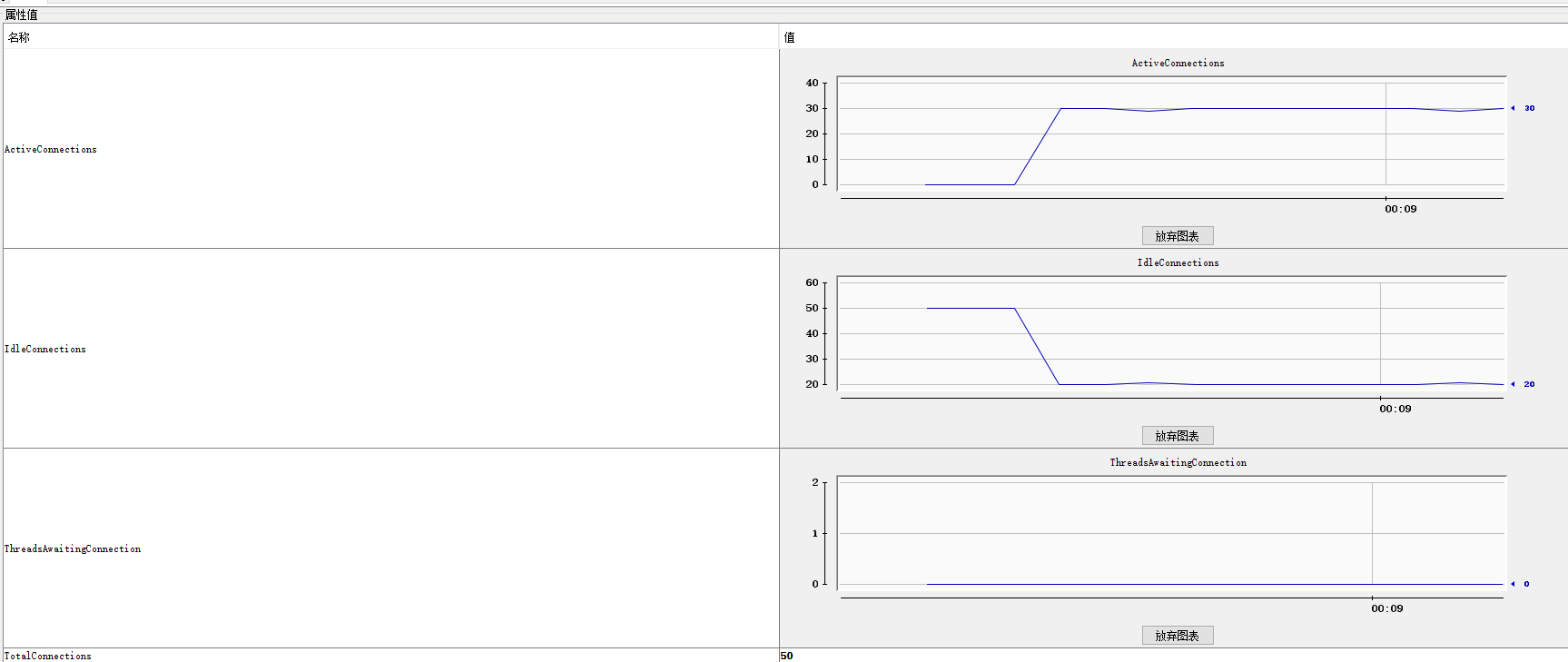
所以我们需要对连接池进行调整,为了直观压测获取服务器最大并发数,我们将连接池最大值调整为50:
spring.datasource.hikari.maximum-pool-size=50
然后再次进行压测,最终我们得到服务器的最大并发数为30,为了保证有一半的冗余,连接池数量调整为并发数*2即60
小结一下,对于连接池参数问题建议做到以下几点:
- 做好配置确保可以实时监控,确保自己的配置是生效的。
- 进行压测确保配置参数符合预期效果。
- 配置连接参数要确保留有一半的余量,并保证我们的监控工具能够在剩余不到一半的情况下发出预警。
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!