机器学习——分类评价指标
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、评价指标
????????对于模型的评价往往会使用损失函数和评价指标,两者的本质是一致的。一般情况下,损失函数应用于训练过程,而评价指标应用于测试过程。对于回归问题,往往使用均方误差等指标评价模型,也使用回归损失函数作为评价指标。而分类问题的评价指标一般会选择准确率、ROC曲线和AUC等,其评价指标如下:
| 术语 | sklearn函数 |
| 混淆矩阵 | confusion_matrix |
| 准确率 | accuracy_score |
| 召回率 | reacall_score |
| f1_score | f1_score |
| ROC曲线 | roc_curve |
| AUC | roc_auc_score |
| 分类评估报告 | classification_report |
2、混淆矩阵
????????在机器学习领域,混淆矩阵(confusion matrix)是衡量分类模型准确度的方法中最基本、最直观、计算最简单的方法。混淆矩阵又称为可能性表格或错误矩阵,用来呈现算法性能的可视化效果,通常应用于监督学习。混淆矩阵由n行n列组成,其每一列表预测值,每一行代表实际的类别。例如,一个人得病了,但检查结果说他没病,那么他“假没病”,也叫假阴性(FN);一个人得病了,医生判断他有病,那么他是“真有病”,也叫阳性(TP);一个人没得病,医生检查结果却说他有病,那么他是“假有病”,也叫假阳性(FP);一个人没得病,医生检查结果也说他没病,那么他是“真没病”,也叫真阴性(TN)4种结局就是2X2=4的混淆矩阵,如表所示。
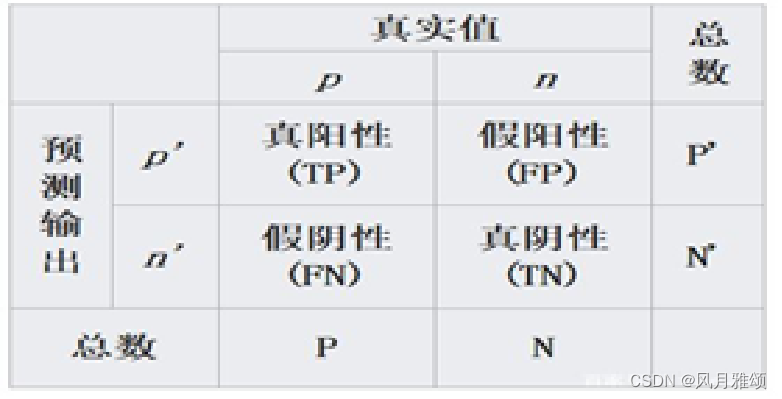
????????FN、TP、FP、TN共包含4个字母P、N、T、F,英文分别是 Positive、Negative、True、False。True和 False 代表预测本身的结果是正确还是不正确,Positive 和 Negative则是代表预测的方向是正向还是负向。
????????每一行之和表示该类别的真实样本数量,每一列之和表示被预测为该类别的样本数量。预测性分类模型肯定是越准越好。因此混淆矩阵中TP与 TN的数值越大越好,而FP与FN的数值越小越好。
混淆矩阵具有如下特性:
- 样本全集=TPUFPUFNUTN。
- 任何一个样本属于且只属于4个集合中的一个,即它们没有交集。
2.1 混淆矩阵示例
????????某系统用来对猫(cat)、狗(dog)、免子(rabbit)进行分类。现共有27只动物,包括8只猫、6条狗和13只兔子。混淆矩阵如表所示。

????????在这个混淆矩阵中,实际有8只猫,但是系统将其中3只猫预测成了狗;实际有6条狗,其中有一条狗被预测成了免子,两条狗被预测成了猫;实际有13只兔子,其中有2只兔子被预测成了狗。
????????sklearn,metrics模块提供了confusion_matrix函数,格式如下:
sklearn.metrics.confusion_matrix(y_true, y_pred,labels)【参数说明】
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
示例:
from sklearn.metrics import confusion_matrix
y_true = [2,0,2,2,0,1]
y_pred = [0,0,2,2,0,2]
print('confusion_matrix\n', confusion_matrix(y_true, y_pred))
y_true = ['cat', 'ant', 'cat', 'cat', 'ant', 'bird']
y_pred = ['ant', 'ant', 'cat', 'cat', 'ant', 'cat']
print('confusion_matrix\n', confusion_matrix(y_true, y_pred, labels = ['ant','bird', 'cat']))【运行结果】
 真实值中,共0,1,2三个特征。
真实值中,共0,1,2三个特征。
2.2 准确率
准确率(accuracy)是最常用的分类性能指标。准确率是预测正确的样本数与总样本数的比值。其计算公式:
sklearn.metrics模块提供了accuracy_score函数,格式如下:
sklearn.metrics.accuracy_score(y_true, y_pred, normalize)【参数说明】
- y_true:真实目标值
- y_pred:估计器预测目标值
- normalize:是否正则化。默认为True,返回正确分类的比例;False返回正确分类的样本数。
示例:
import numpy as np
from sklearn.metrics import accuracy_score
y_true = [0,1,2,3]
y_pred = [0,2,1,3]
print(accuracy_score(y_true, y_pred))
print(accuracy_score(y_true, y_pred, normalize = False))2.3 精确率
????????精确率(precision)又称为查准率。精确率只针对预测正确的正样本而不是所有预测正确的样本,是正确预测的正样本数与预测正样本总数的比值,其计算公式如下:
sklearn.metrics模块提供了precision_score函数,格式如下:
sklearn.metrics.precision_score(y_true, y_pred)示例:
import numpy as np
from sklearn.metrics import precision_score
y_true = [1,0,1,1]
y_pred = [0,1,1,0]
p = precision_score(y_true, y_pred)
print(p)2.4 召回率
????????召回率(recall)是有关覆盖面的度量,它反映有多少正例被分为正例,又称查全率。查准率和召回率是一对矛盾的度量。查准率高时,召回率往往偏低;而召回率高时,查准率往往偏低。
召回率是正确预测的正例数与实际正例总数之比,计算公式如下
sklearn.metrics模块提供了recall_score函数,格式如下:
sklearn.metrics.recall _score(y_true, y_pred, average)????????以信息检索为例,刚开始在页面上显示的信息是用户可能最感兴趣的信息,此时查准率高,但只显示了部分数据,所以召回率低;随着用户不断地下拉滚动条显示其余信息,信息与用户兴趣的匹配程度逐渐降低,查准率不断下降,召回率逐渐上升;当下拉到信息底部时,此时的信息是最不符合用户兴趣的,因此查准率最低,但所有的信息都已经展示,召回率最高。
3、F1分数
F1分数(F1 score)用于衡量二分类模型的精确度,是精确率和召回率的调和值,其变化范围为0~1。F1分数的计算公式如下:
sklearn.metrics 模块提供了f1_score函数。格式如下:
sklearn.metrics.f1_score(y_true, predictions, average = 'micro【参数说明】
- y_true:真实目标值
- predictions:估计器预测目标值
示例:
from sklearn import metrics
y_test = [0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2]
y_pred = [0,0,1,1,0,0,0,2,2,0,1,1,1,1,2,1,1,2,2,1,2,2,2,2,2,2,1,1,2,2]
F1 = metrics.f1_score(y_test, y_pred, average = 'micro')
print("F1", F1)4、ROC曲线
????????ROC全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,用于描述混淆矩阵中FPR-TPR两个量之间的相对变化情况。ROC曲线的横轴是FPR,纵轴是TPR。ROC曲线用于描述样本的真实类别和预测概率。

ROC曲线中的4个点如下:
- 点(0,1):即 FPR=0,TPR=1,意味着FN=0且FP=0,所有的样本都正确分类
- 点(1,0):即 FPR=1,TPR=0,最差分类器,避开了所有正确答案。
- 点(0,0):即 FPR=TPR=0,FP=TP=0,分类器把每个样本都预测为负类。
- 点(1,1):即 FPR=TPR=1,分类器把所有样本都预测为正类。
sklearn,metrics 模块提供了roc_curve函数,格式如下:
sklearn.metrics.roc_ curve(y_true, y_score)【参数说明】
- y_true:每个样本的真实类别,必须为0(反例)、1(正例)标记。
- y_score:预测得分,可以是正类的估计概率
示例:
import numpy as np
from sklearn import metrics
y = np.array([1,1,2,2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label = 2)
print(fpr)
print(tpr)
print(thresholds)
from sklearn.metrics import auc
print(metrics.auc(fpr, tpr))5、AUC
????????AUC(Area Under Curve)是指 ROC曲线下的面积,由于ROC曲线一般都处于y=x这条直线的上方,所以AUC 的取值范围为0.5~1。AUC 只能用于评价二分类,直观地评价分类器的好坏,值越大越好。
AUC 对模型性能的判断标准如下:
- AUC=1,是完美分类器。采用这个预测模型时,存在至少一个阈值能得出完美预测。在绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。若对这个分类器(模型)设定合适的阈值,它就才预测价值。
- AUC=0.5,跟随机猜测一样(例如抛硬币),模型没有预测价值。
- AUC<0.5,比随机猜测还差。但是,只要总是反预测而行,就优于随机猜测。
sklearn.metrics模块提供了roc_auc_score函数,格式如下:
sklearn.metrics.roc_auc_score(y_true, y_score)【参数说明】
- y_true:每个样本的真实类别,必须为0(反例)、1(正例)标记。
- y_score:预测得分,可以是正类的估计概率。
示例:
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0,0,1,1])
y_score = np.array([0.1,0.4,0.35,0.8])
print(roc_auc_score(y_true, y_score))6、分类评估报告
????????Sklearn 中的classification_report函数用于显示主要分类指标的文本报告,显示每个类的精确度、召回率、F1值等信息。classification_report函数格式如下:
sklearn.metrics.classification _report(y_true, y_pred, labels, target_names)【参数说明】
- y_true:真实目标值。
- y_pred:估计器预测目标值。
- labels:指定类别对应的数字。
- target_names:目标类别名称。
示例:
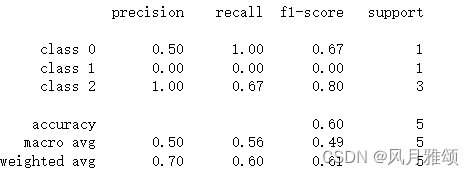
from sklearn.metrics import classification_report
y_true = [0,1,2,2,2]
y_pred = [0,0,2,2,1]
target_names = ['class 0','class 1','class 2']
print(classification_report(y_true, y_pred, target_names = target_names))【运行结果】
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!