2023年12月19日工程中学到的知识整理
(T▽T)免责声明:仅仅是个人学习总结,如有错误烦请告知
1. Pandas中的query函数
函数功能:筛选数据
df.query("等式或者不等式")
# for example
df.query("A==5")
df.query("A>=10")
2.lambda表达式
what:lambda是一个函数,可以接受参数输入
funca = lambda x: x+1
funca(2)
out:3
funcb = lambda x:x+1 if x==1 else 0
funcb(1)
out:2
funcb(2)
out:0
# pandas使用lambda表达式
pd_1 = pd.DataFrame([round(np.random.random(),2) for _ in range(5)])
#数据长这样
0
0 0.95
1 0.62
2 0.04
3 0.61
4 0.77
#接下来转换
pd_2 = pd_1[0].apply(lambda x: '{:.0%}'.format(x))
out:
0 95%
1 62%
2 4%
3 61%
4 77%
3.pandas中的apply函数
函数功能:对dataframe进行函数处理
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
"""
func 代表的是传入的函数或 lambda 表达式;
axis 参数可提供的有两个,该参数默认为0/列
0 或者 index ,表示函数处理的是每一列;
1 或 columns ,表示处理的是每一行;
raw ;bool 类型,默认为 False;
False ,表示把每一行或列作为 Series 传入函数中;
True,表示接受的是 ndarray 数据类型;
"""
>>> df =pd.DataFrame([[4,9]]*3,columns = ['A','B'])
>>> df
A B
0 4 9
1 4 9
2 4 9
?
?
>>> df.apply(np.sqrt)
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
>>> df.apply(np.mean)
A 4.0
B 9.0
4. pandas中的groupby
函数功能:将数据按照某一列进行划分
具体的在这个博客里面总结过:click here
- 按多列分组:
df.groupby({column1, column2])
df = pd.DataFrame([['a', 'man', 120, 90],
['b', 'woman', 130, 100],
['a', 'man', 110, 108],
['a', 'woman', 120, 118]], columns=['level', 'gender', 'math', 'chinese'])
print(df)
level gender math chinese
0 a man 120 90
1 b woman 130 100
2 a man 110 108
3 a woman 120 118
group = df.groupby(['gender', 'level'])
# 先按照'gender'列的值来分组。每组内,再按'level'列来分组。也返回一个groupby对象
for key, value in group:
print(key)
print(value)
print("")
('man', 'a')
level gender math chinese
0 a man 120 90
2 a man 110 108
('woman', 'a')
level gender math chinese
3 a woman 120 118
('woman', 'b')
level gender math chinese
1 b woman 130 100
5.pandas中的to_dict
函数功能:将datadrame转换成字典的形式
{ }表示字典数据类型,字典中的数据是以 {key : value} 的形式显示,是键名和键值一一对应形成的
6.pandas中的set_index
函数功能:指定某一个列作为索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
"""
keys:列标签或列标签/数组列表,需要设置为索引的列
drop:默认为True,删除用作新索引的列
append:是否将列附加到现有索引,默认为False。
inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。
"""
import pandas as pd
import numpy as np
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[50, 43, 34, 40, 25, 25, 45, 32]})
Country Income Age
0 China 10000 50
1 China 10000 43
2 India 5000 34
3 India 5002 40
4 America 40000 25
5 Japan 50000 25
6 China 8000 45
7 India 5000 32
print(df.set_index('Country'))
Income Age
Country
China 10000 50
China 10000 43
India 5000 34
India 5002 40
America 40000 25
Japan 50000 25
China 8000 45
India 5000 32
6.1 pandas.DataFrame.reset_index
函数功能:重置索引(重置成默认索引)
df = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
输出:df
class max_speed
falcon bird 389.0
parrot bird 24.0
lion mammal 80.5
monkey mammal NaN
# 重置索引时,将旧索引添加为列,并使用新的顺序索引:
df.reset_index()
index class max_speed
0 falcon bird 389.0
1 parrot bird 24.0
2 lion mammal 80.5
3 monkey mammal NaN
7.Python 字典(Dictionary) get()
函数功能:返回指定key的value
get(...)
D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.
>>> dict = {'1':'one','2':'two','3':'three'}
>>> dict.get('2',0)
'two'
>>> dict.get('4',0)
0
>>> dict.get('4','false')
'false'
8.pandas.Index.map
函数功能:映射
Index.map(mapper, na_action=None)[source]
# for example
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,100),
"weight":np.random.randint(40,90,100),
"smoker":[boolean[x] for x in np.random.randint(0,2,100)],
"gender":[gender[x] for x in np.random.randint(0,2,100)],
"age":np.random.randint(15,90,100),
"color":[color[x] for x in np.random.randint(0,len(color),100) ]
}
)
print(data.head(5))
height weight smoker gender age color
0 185 89 True 男 27 yellow
1 164 86 True 女 66 black
2 169 72 True 女 63 yellow
3 186 80 False 男 62 yellow
4 166 45 True 女 61 black
# how to Replace “男” with 1 and “女” with 0 in the gender column?
#①使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
#②使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)
height weight smoker gender age color
0 159 46 False 0 85 white
1 174 83 False 1 46 yellow
2 173 49 True 1 36 yellow
3 184 74 False 1 59 black
4 189 70 False 0 72 white
9.自定义函数basic_eda(df)用于查看dataframe的详细信息
def basic_eda(df):
print("-------------------------------TOP 5 RECORDS-----------------------------")
print(df.head(5))
print("-------------------------------INFO--------------------------------------")
print(df.info())
print("-------------------------------Describe----------------------------------")
print(df.describe())
print("-------------------------------Columns-----------------------------------")
print(df.columns)
print("-------------------------------Data Types--------------------------------")
print(df.dtypes)
print("----------------------------Missing Values-------------------------------")
print(df.isnull().sum())
print("----------------------------NULL values----------------------------------")
print(df.isna().sum())
print("--------------------------Shape Of Data---------------------------------")
print(df.shape)
print("============================================================================ \n")
10.dt.xx
- dt.date
- dt.normalize
- dt.year:返回日期的年份
- dt.month
- dt.day
- dt.hour
- dt.week
- dt.quarter:返回日期的季度
- dt.day_name:返回星期几的英文
11.pandas中的sort_values
函数功能:可根据指定列数据也可根据指定行的数据排序
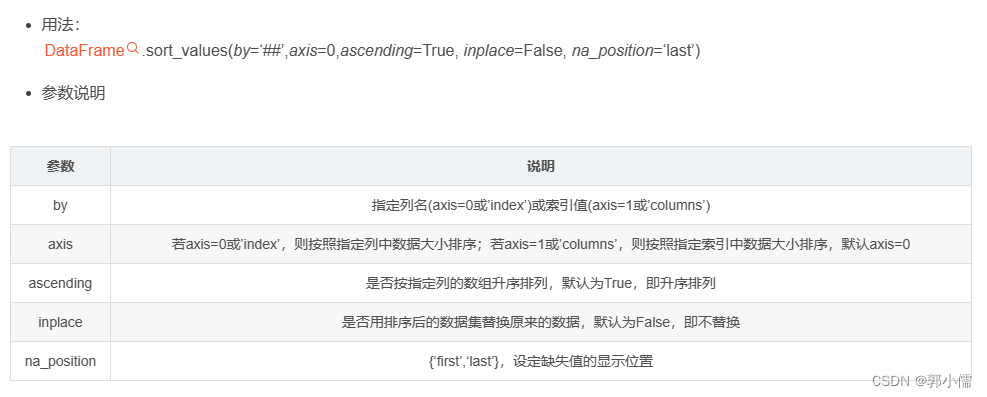
12.TimeseriesGenerator
(1)为什么要使用TimeseriesGenerator?
在训练监督学习(深度学习)模型前,要把time series数据转化成samples的形式
那什么是sample?有一个输入组件
X
X
X和一个输出组件
y
y
y
深度学习模型就是一个映射函数:
y
=
f
(
X
)
y=f(X)
y=f(X)
对于一个单变量的one-step预测:输入组件就是前一个时间步的滞后数据,输出组件就是当前时间步的数据,如下:
X, y
[1, 2, 3], [4]
[2, 3, 4], [5]
[3, 4, 5], [6]
…
TimeseriesGenerator class就可以把手动生成samples的这个过程自动化
(2)怎么使用TimeseriesGenerator
需要两步:定义和使用
a.定义
# 官方文档:
tf.keras.preprocessing.sequence.TimeseriesGenerator(
data,
targets,
length,
sampling_rate=1,
stride=1,
start_index=0,
end_index=None,
shuffle=False,
reverse=False,
batch_size=128
)
# load data 在大多数时间序列预测问题中,输入和输出系列将是同一time series
inputs = ...
outputs = ...
# define generator
generator = TimeseriesGenerator(inputs, outputs, ...)
- length:在每个样本的输入部分中使用的滞后观察的数量(例如 3)
- sampling_rate: s a m p l i n g r a t e = r samplingrate=r samplingrate=r,输入组件: d a t a [ i ] , d a t a [ i ? r ] , d a t a [ i ? 2 r ] , . . . . . . , d a t a [ i ? l e n g t h ] data[i],data[i-r],data[i-2r],......,data[i-length] data[i],data[i?r],data[i?2r],......,data[i?length]
- stride: s t r i d e = s stride=s stride=s,输出组件: d a t a [ i ] , d a t a [ i + s ] , d a t a [ i + 2 s ] . . . . data[i],data[i+s],data[i+2s].... data[i],data[i+s],data[i+2s]....
- start_index:在start_index前的点不使用
- end_index:在end_index后的点不使用
- shuffle:是否打乱数据
- reverse:是否将输出的samples按照时间倒序排列
- batch_size:每次迭代时返回的样本数
b.使用timeseriesgenerator训练模型
使用fit_generator()函数来训练模型model
# define generator
generator = TimeseriesGenerator(...)
# define model
model = ...
# fit model
model.fit_generator(generator, steps_per_epoch=len(generator), ...)
- generator:TimeseriesGenerator类实例化的生成器作为fit_generator的参数(argument)
- steps_per_epoch:一个epoch中使用的samples数量,可以设置为generator长度(len(generator))代表使用generator中的所有samples
同样,可以使用evaluate_generator()函数来评估模型
使用predict_generator()函数对新数据进行预测
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!