ELK(四)—els基本操作
目录
elasticsearch基本概念
Elasticsearch 是一个分布式搜索引擎,用于全文搜索、分析和可视化大规模数据。以下是 Elasticsearch 中一些基本概念:
- 索引(Index):
- Elasticsearch 中的数据存储单元,类似于传统数据库中的数据库。每个索引包含一组相关的文档。
- 文档(Document):
- 索引中的基本信息单元,可以是 JSON、XML、或其他格式的数据。文档是 Elasticsearch 中可被索引和搜索的基本数据单元。
- 类型(Type)(在7.x版本之前):
- Elasticsearch 6.x及更早版本中,索引可以包含一个或多个类型,每个类型定义了文档的结构。从 Elasticsearch 7.x 开始,不再支持多类型,一个索引只有一个默认类型 “_doc”。
- 映射(Mapping):
- 定义了索引中的文档结构,包括每个字段的类型和属性。映射在创建索引时自动创建,也可以手动定义。
- 节点(Node):
- Elasticsearch 集群中的单个服务器,用于存储数据和执行数据操作。每个节点属于一个集群,并且有唯一的名称。
- 集群(Cluster):
- 由一个或多个节点组成的集合,共同存储数据并提供联合的搜索能力。集群有一个唯一的名称。
- 分片(Shard):
- 索引可以被分割成多个分片,每个分片是一个独立的索引。分片允许数据水平扩展,提高并发性能。
- 副本(Replica):
- 每个分片可以有零个或多个副本。副本是分片的精确拷贝,用于提高高可用性和故障恢复。
- 查询(Query):
- 用于搜索 Elasticsearch 中文档的条件。可以通过查询DSL(Domain Specific Language)来构建各种类型的查询。
- 聚合(Aggregation):
- 用于分析和统计数据的机制,可以计算平均值、总和、最小值等。
- 索引别名(Index Alias):
- 为索引提供一个可读的名称,可以用于简化索引操作和在查询中引用多个索引。
- 分析器(Analyzer):
- 用于在索引和查询阶段处理文本数据的组件,包括分词、小写化、去停用词等。
- 倒排索引(Inverted Index):
- Elasticsearch 使用倒排索引来加速搜索,它记录了每个词项出现在哪些文档中。
这些是 Elasticsearch 中一些基本的概念,了解它们有助于更好地理解和使用 Elasticsearch 进行数据存储和检索。
RESTful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
创建非结构化索引
在Lucene中,创建索引是需要定义字段名称以及字段的类型的,在Elasticsearch中提供了非结构化的索引,就是不需要创建索引结构,即可写入数据到索引中,实际上在Elasticsearch底层会进行结构化操作,此操作对用户是透明的。
(增)创建空索引
PUT /elk
{
"settings":{
"index":{
"number_of_shards":"2",
"number_of_replicas":"0"
}
}
}
这里我选择postman进行测试。
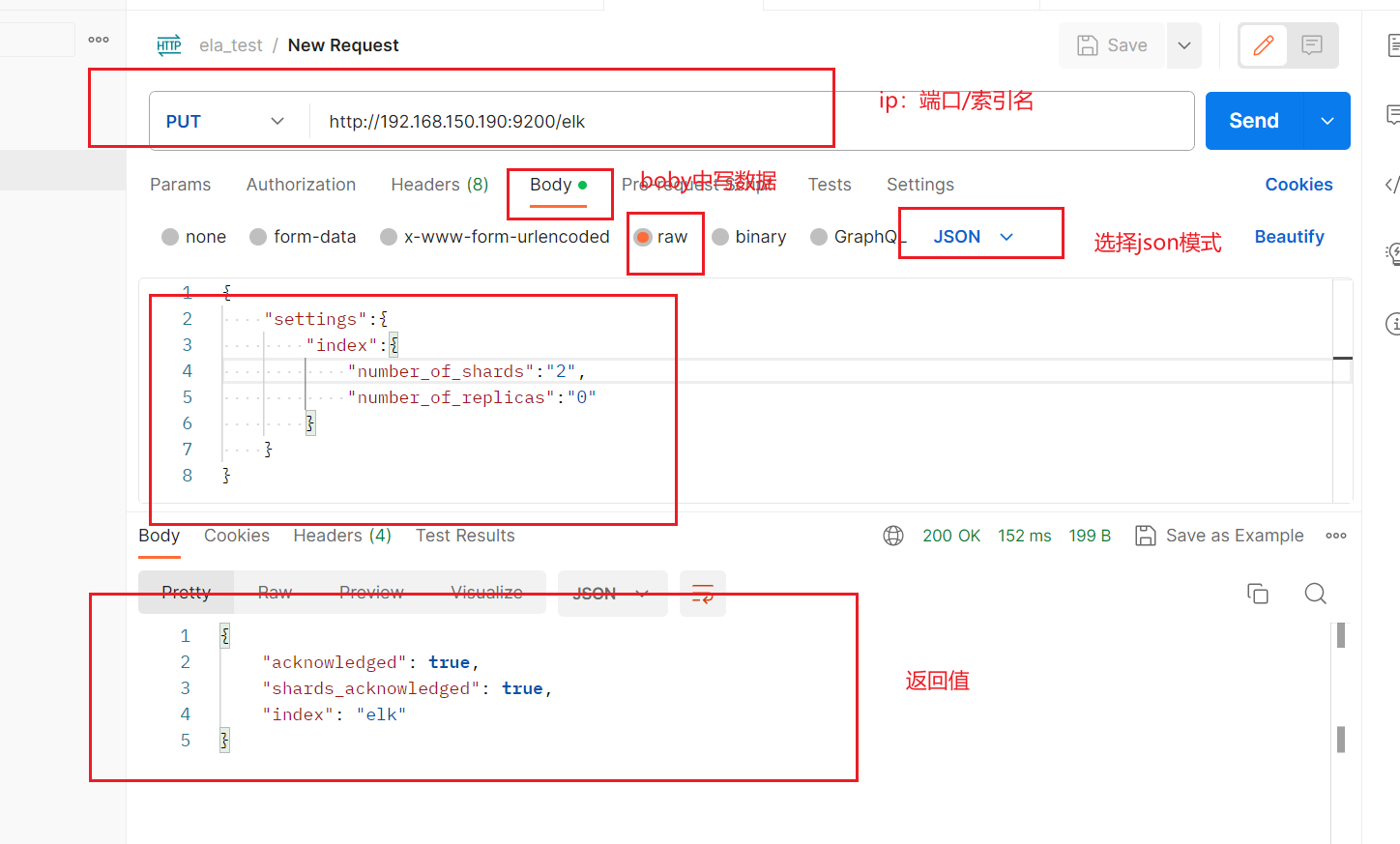
去elasticsearch-head看是否索引创建是否成功。
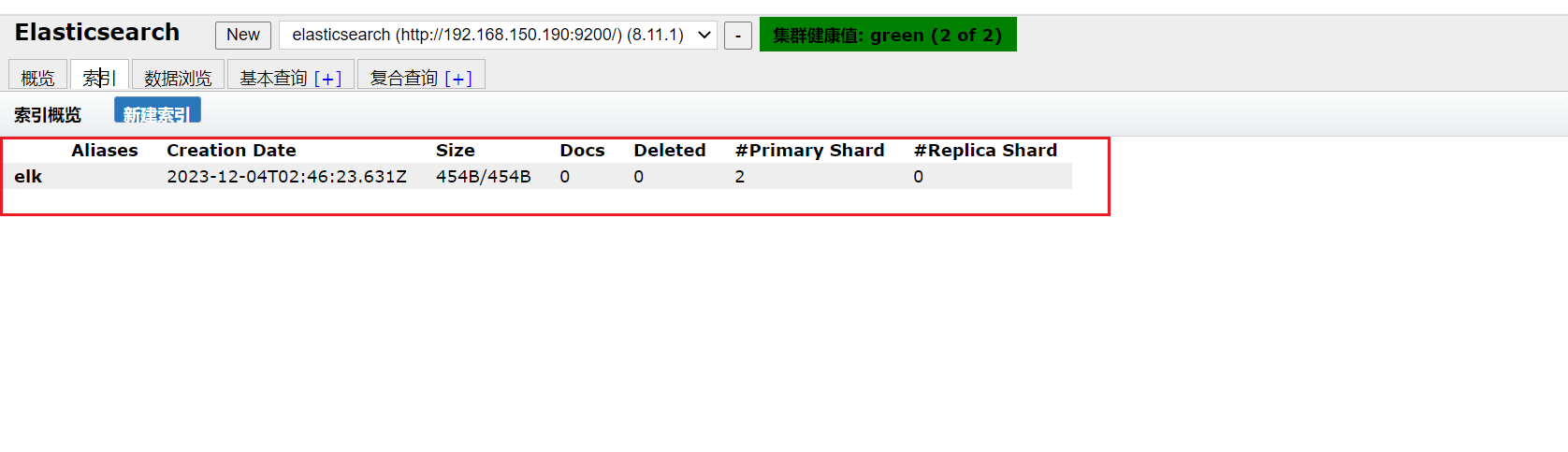
可以看到索引已经创建成功了。
(删)删除索引
DELETE /elk
{
"acknowledged": true
}
在postman中进行删除操作

检查是否删除成功
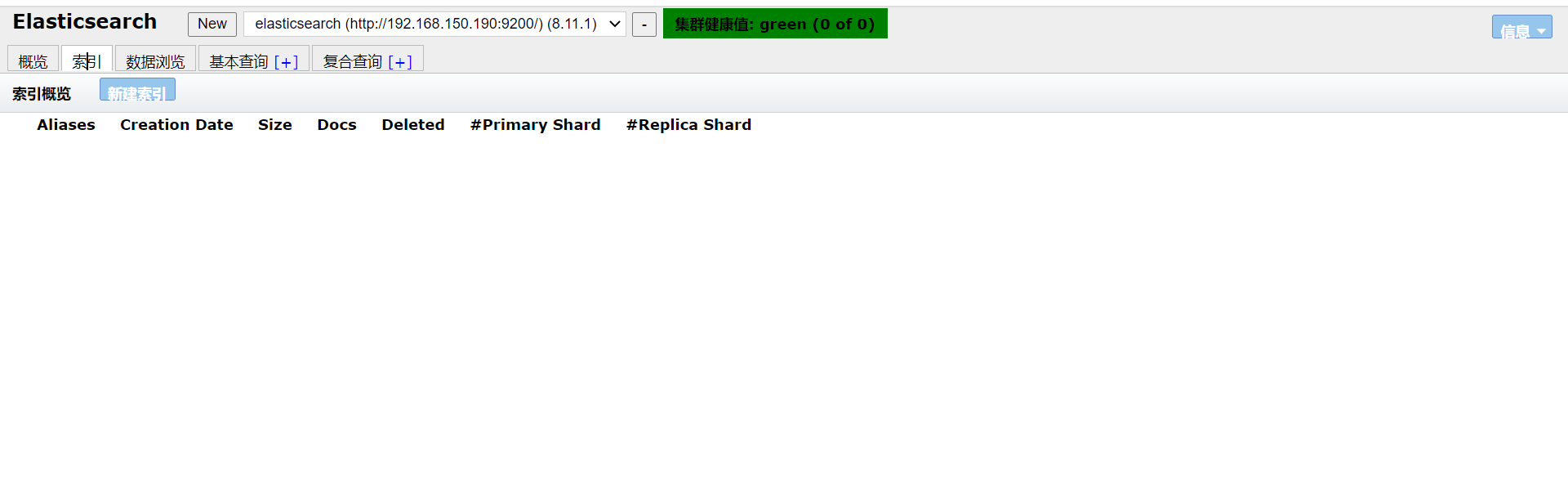
可以看到已经删除成功了
(改)插入数据
上面我们已经学会了如何创建好删除索引,现在我们进行数据的添加操作。
URL规则:
POST /{索引}/{类型}/{id}
插入如下数据。
{
"id":1001,
"name":"王五",
"age":18,
"sex":"男"
}

postman中显示插入成功了。
浏览器上是否也是插入成功呢?
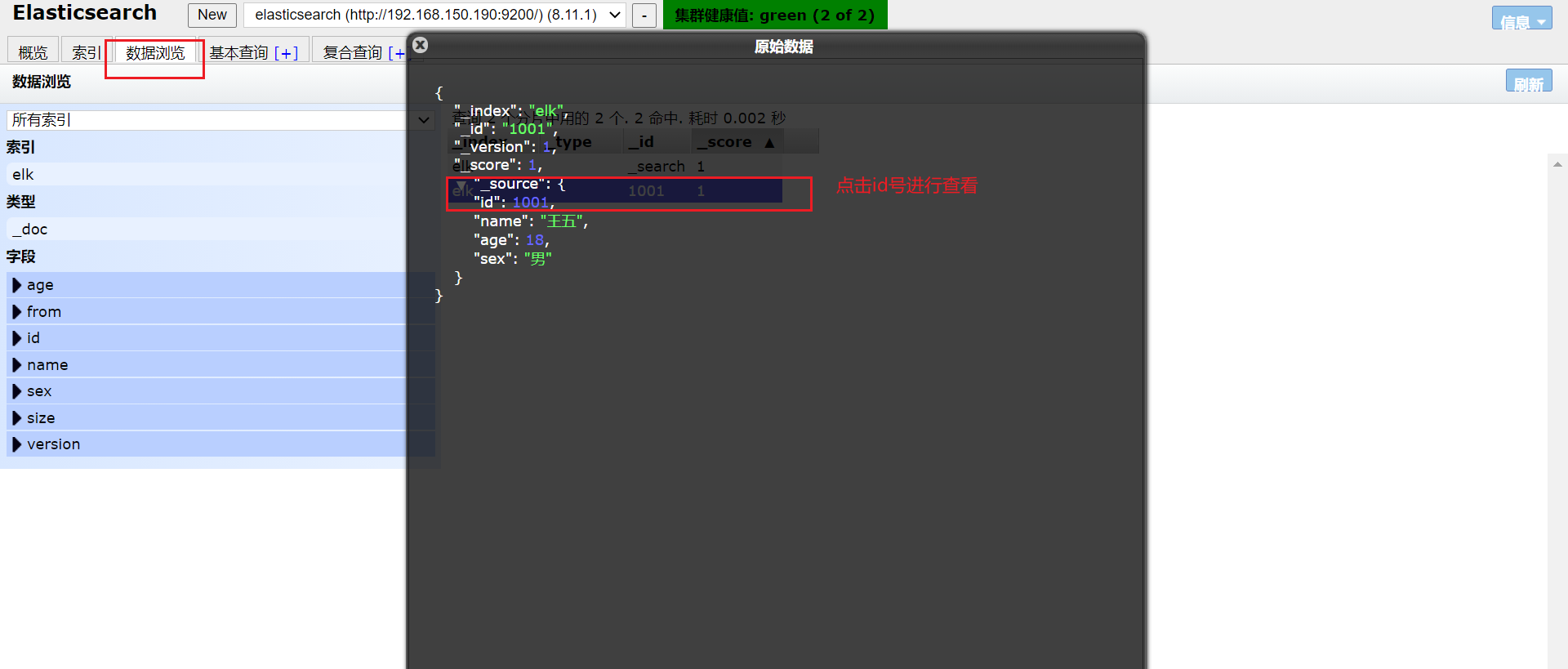
可以看到数据已经成功插入了。
(改)数据更新
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新。
{
"id":1001,
"name":"王老五",
"age":55,
"sex":"男"
}
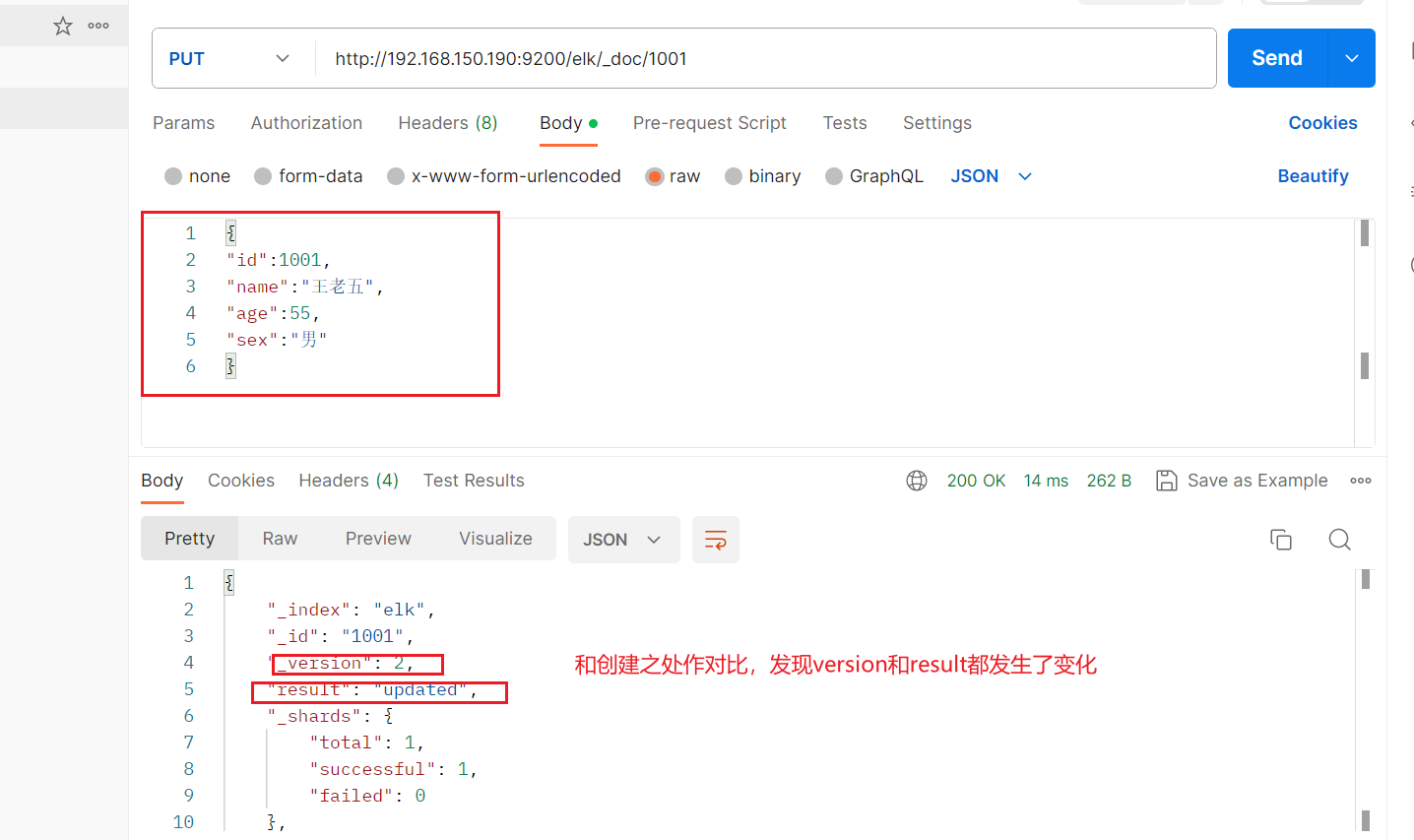
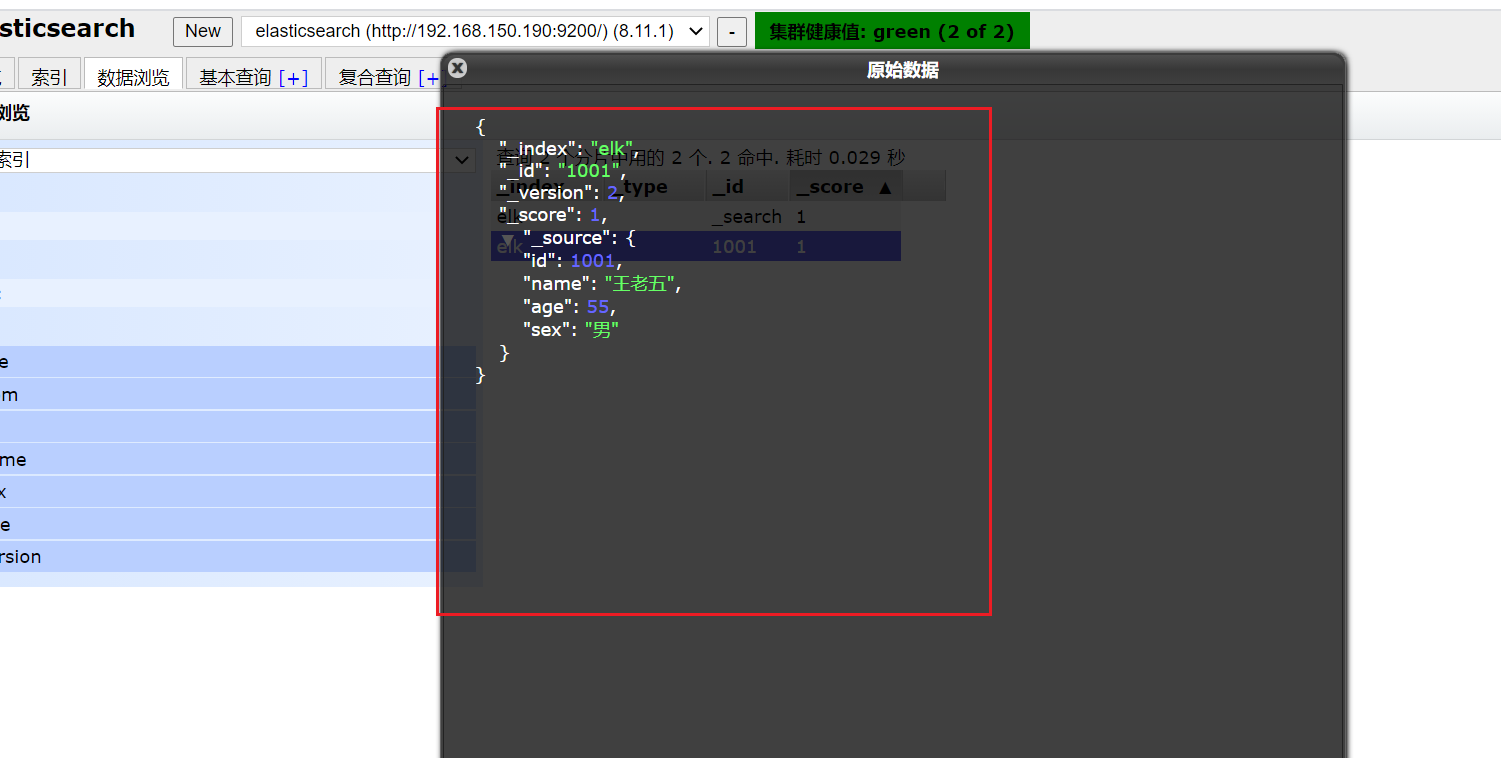
服务器中的数据也成功更新了。
问题与探究问题与探究问题与探究
可以看到数据已经被覆盖了。问题来了,可以局部更新吗? – 可以的。前面不是说,文档数据不能更新吗?
其实是这样的:在内部,依然会查询到这个文档数据,然后进行覆盖操作,步骤如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
#注意:这里多了_update标识
POST /haoke/_update/1001
{
"doc":{
"age":66
}
}
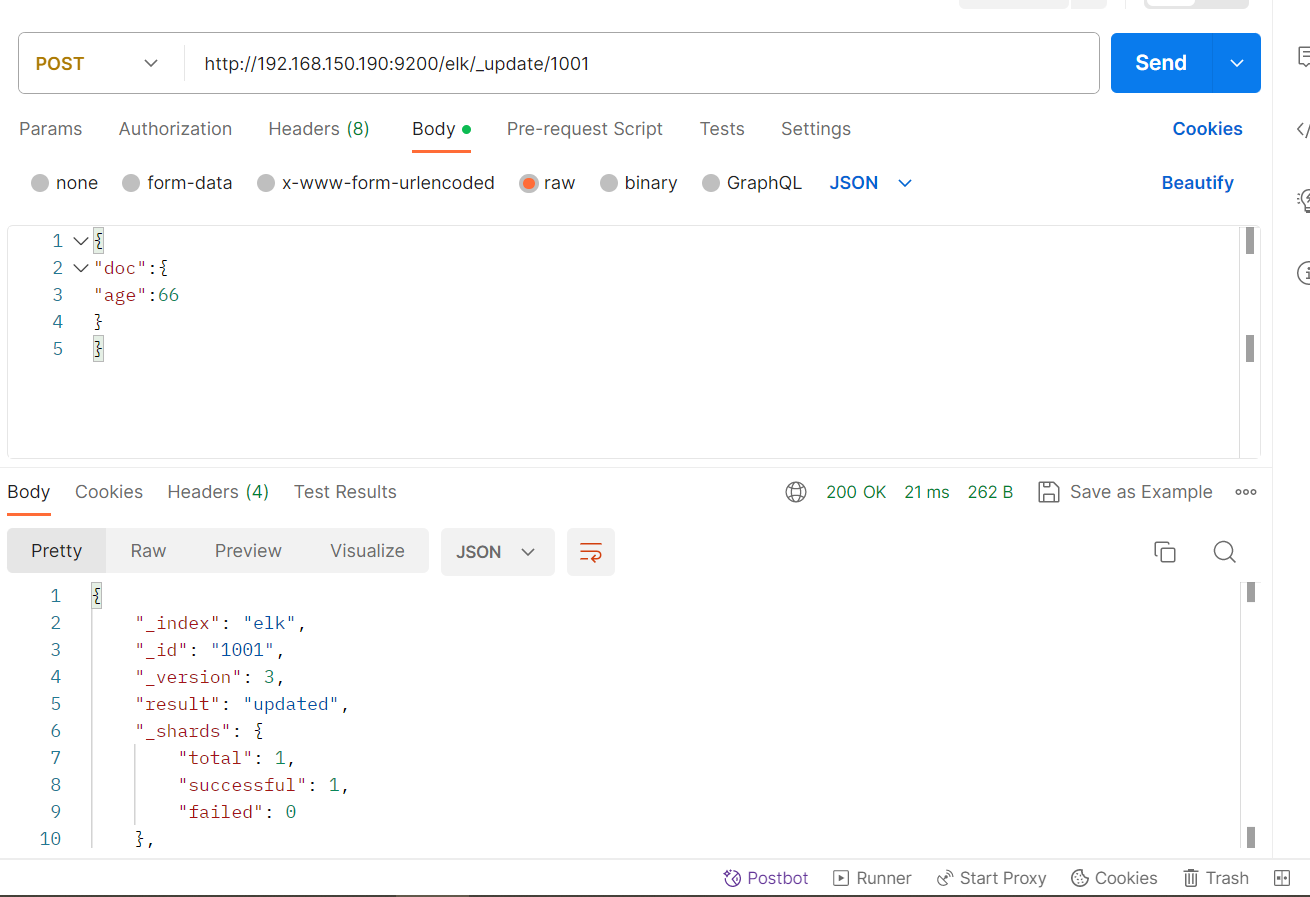
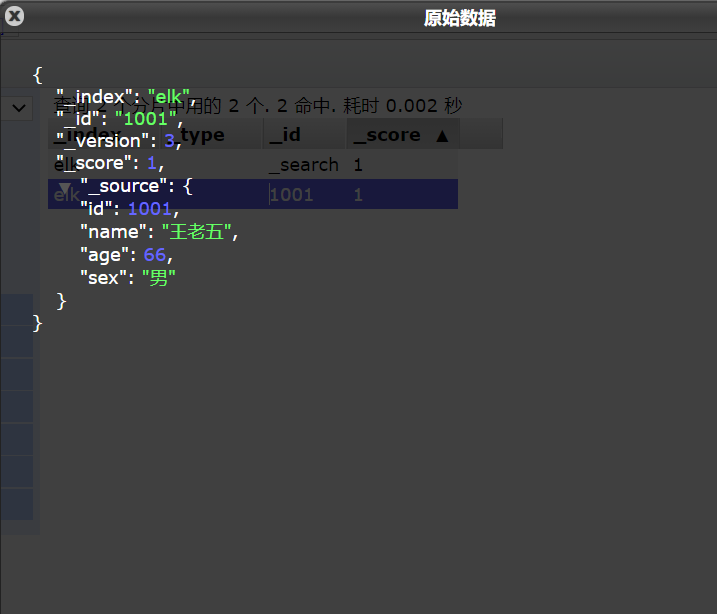
可以看到数据已经成功更新了。
我们需要id存在,否则会报错,也就是404
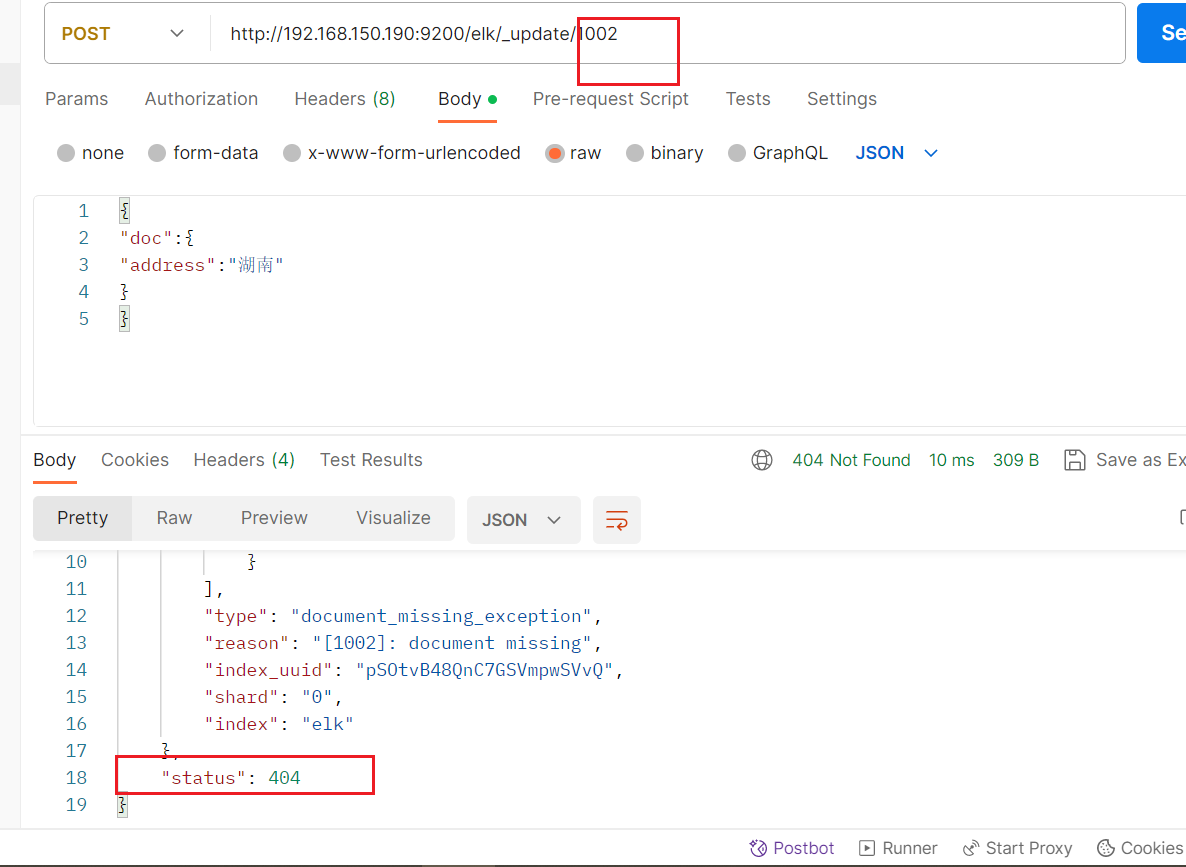
当id存在,我们可以往数据添加原先没有的数据。
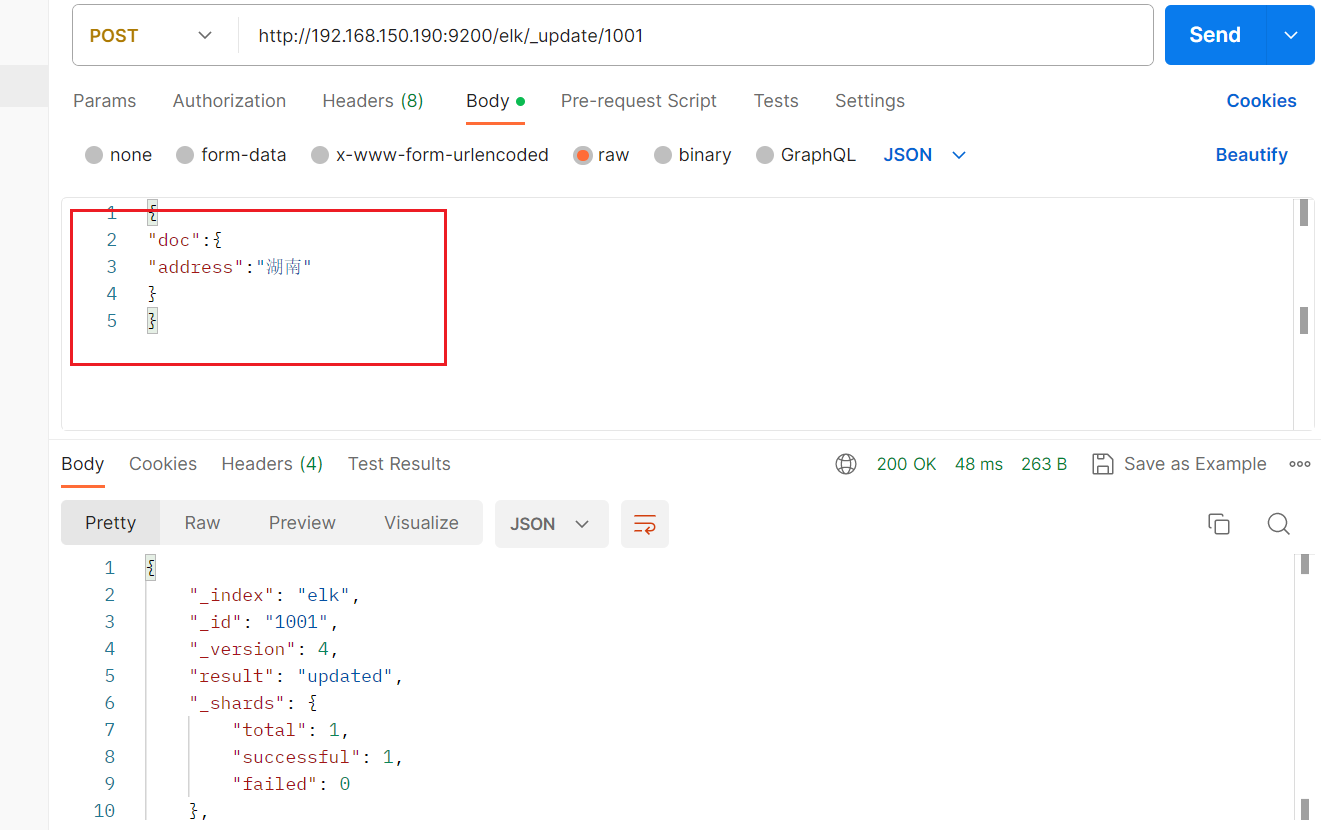
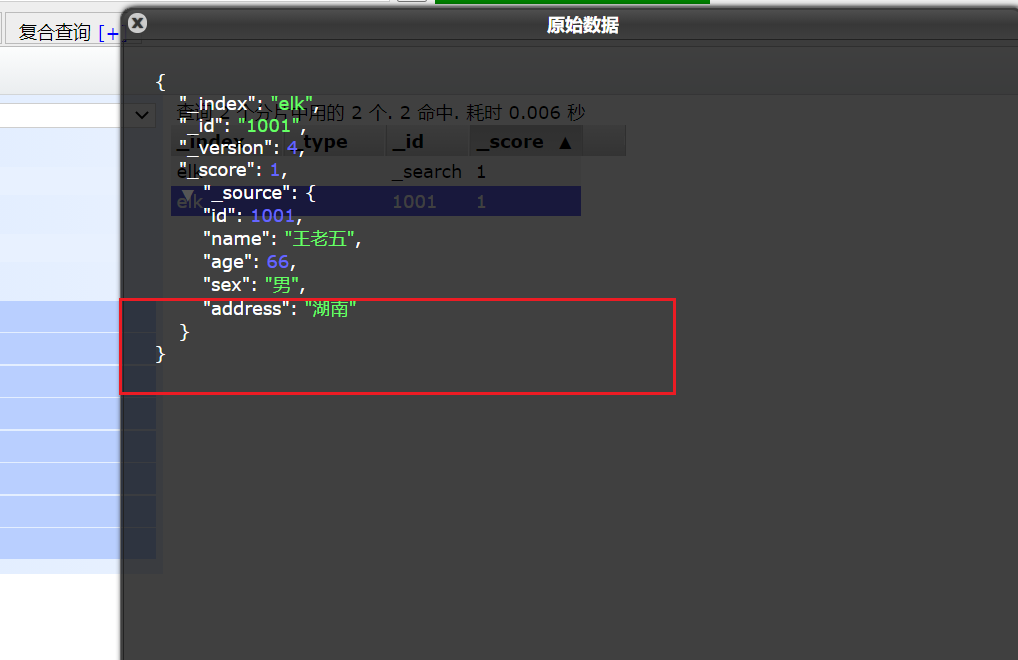
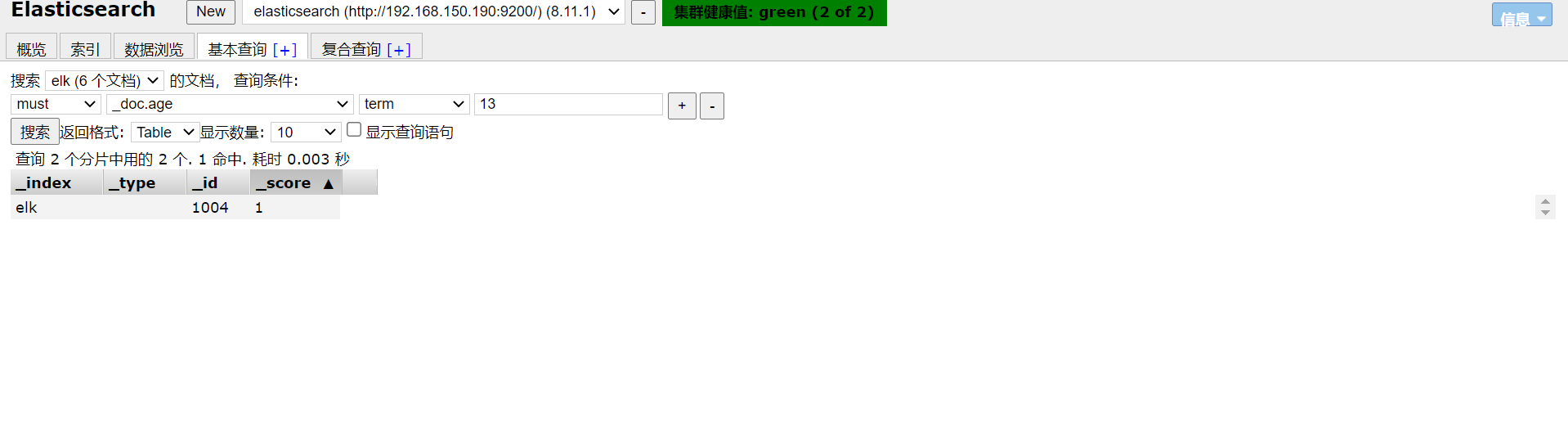
(查)搜索数据(id)
GET /elk/_doc/id
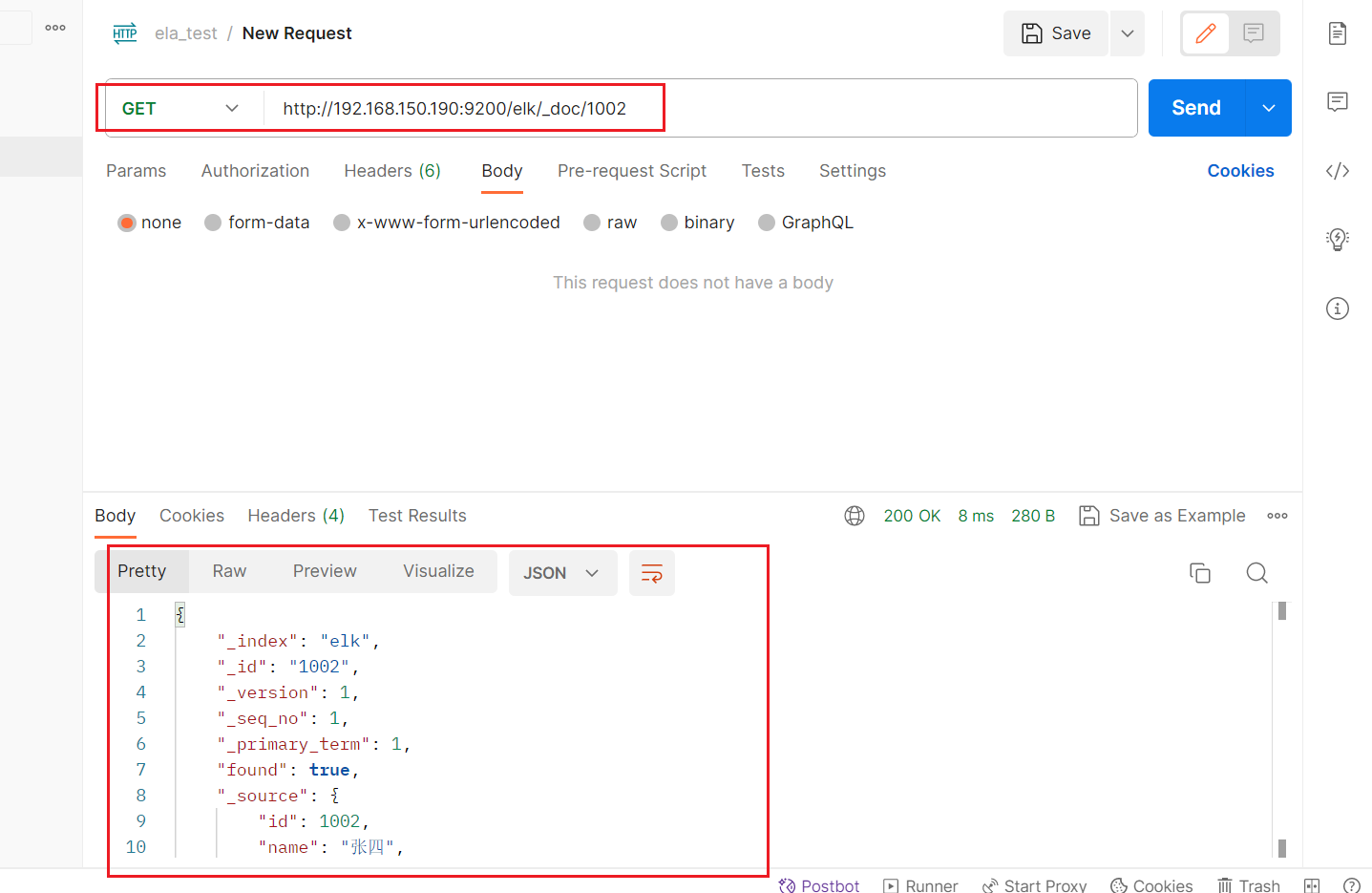
我们也可以直接在elasticsearch中进行搜索
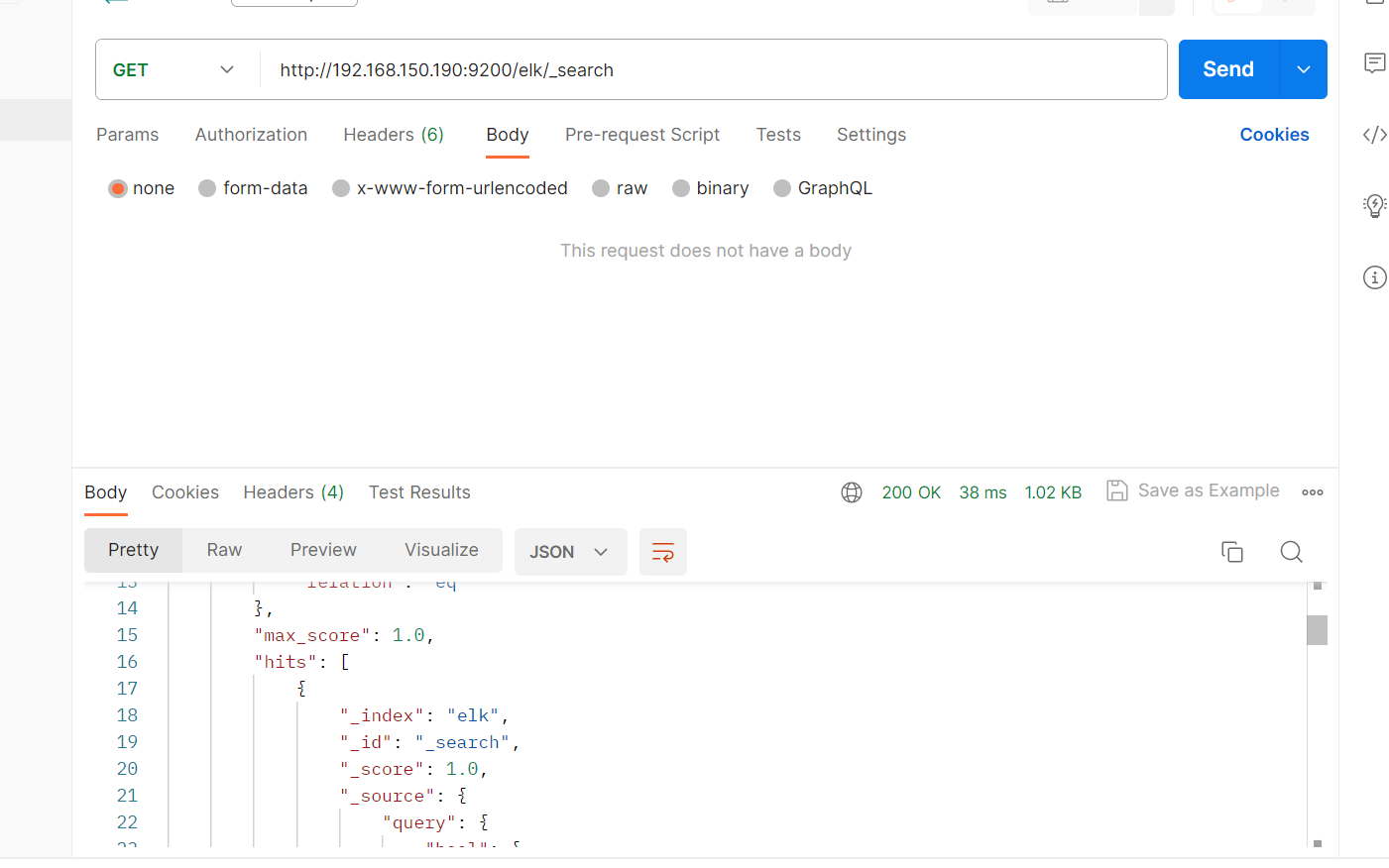
(查)搜索数据(全部)
GET /elk/_search
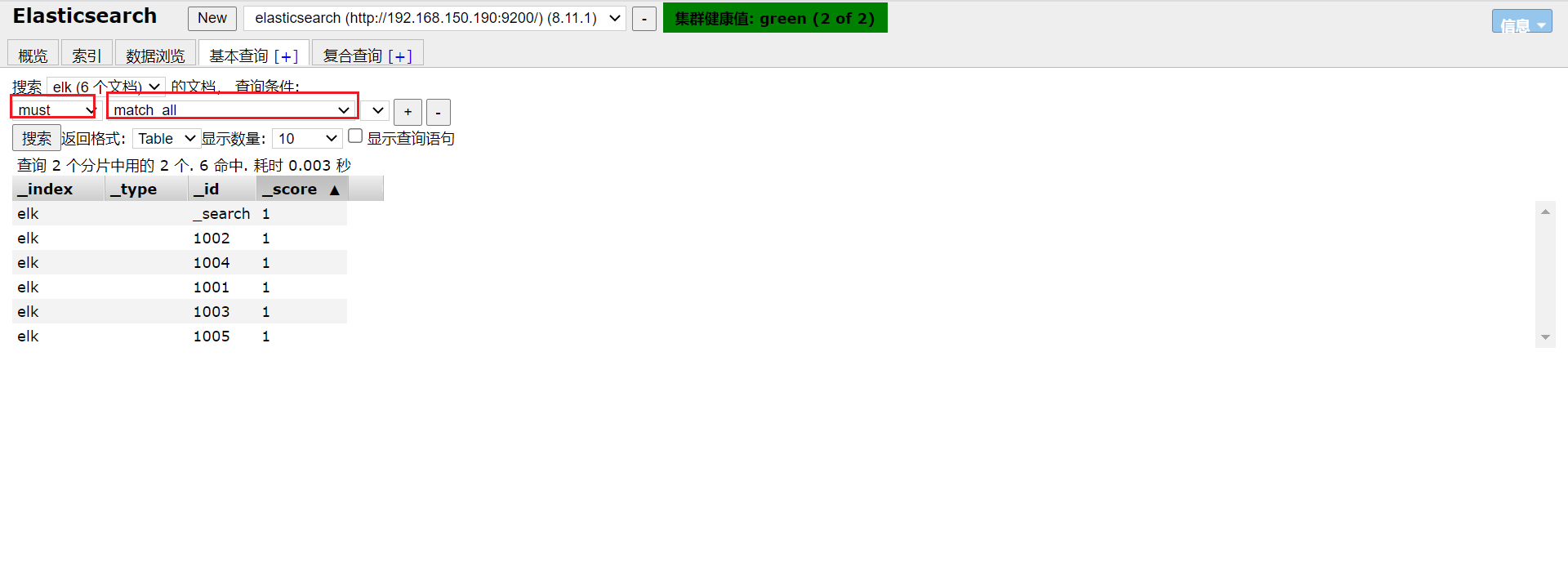
同样的,查询全部也可以直接在elasticsearch-head中的基本查询中进行搜索。
(查)关键字搜索数据
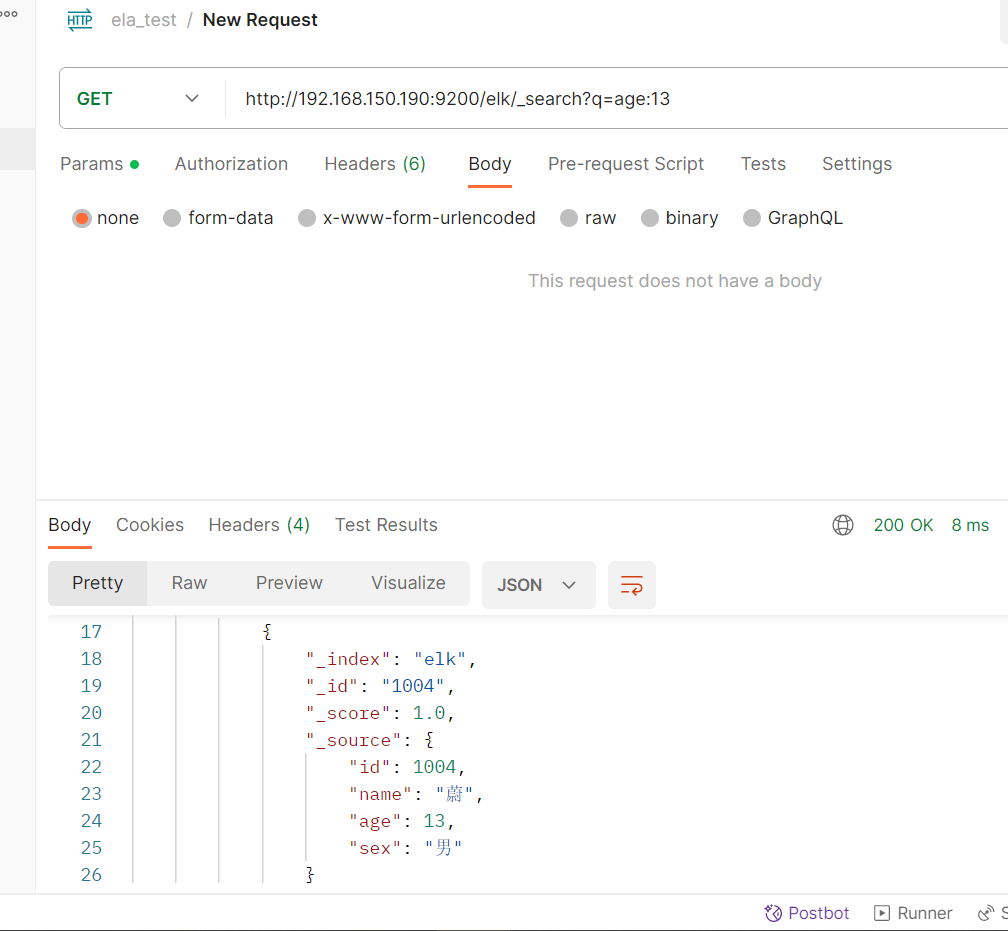
#格式
GET /elk/_search?q=字段名:对应值
#查询年龄等于13的用户
GET /elk/_search?q=age:20
#查询年龄等于13的用户
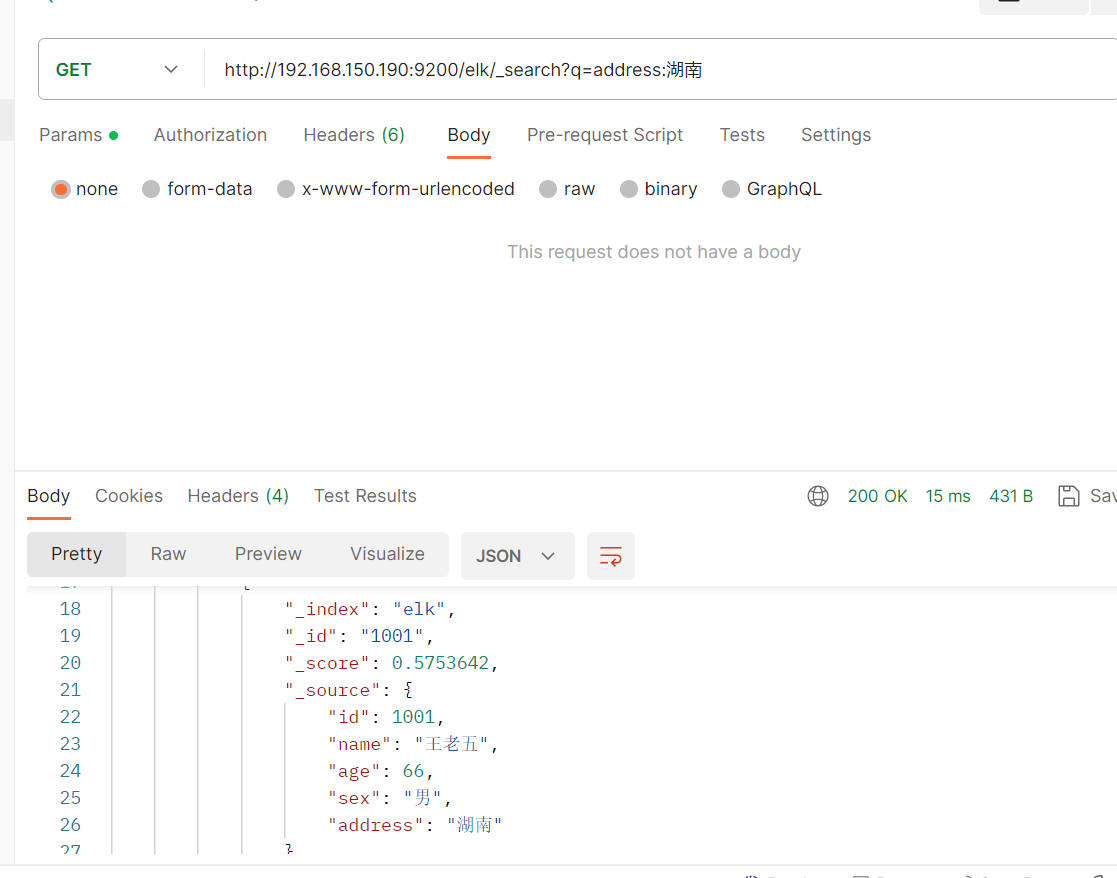
GET /elk/_search?q=address:湖南
(查)DSL搜索
Elasticsearch的DSL(Domain-Specific Language)是一种查询语言,用于在Elasticsearch中执行搜索操作。DSL允许用户以结构化的方式构建复杂的查询,以满足不同的搜索需求。DSL查询通常以JSON格式表示,并包含各种查询和过滤条件。
以下是一些常见的DSL查询语法和查询类型的详细解释:
-
Match Query:
Match查询用于执行全文本搜索,它会在指定的字段中查找包含特定词语的文档。{ "query": { "match": { "field_name": "search_term" } } }匹配年龄为20的数据
POST /elk/_search #请求体 { "query" : { "match" : { "age" : 23 } } }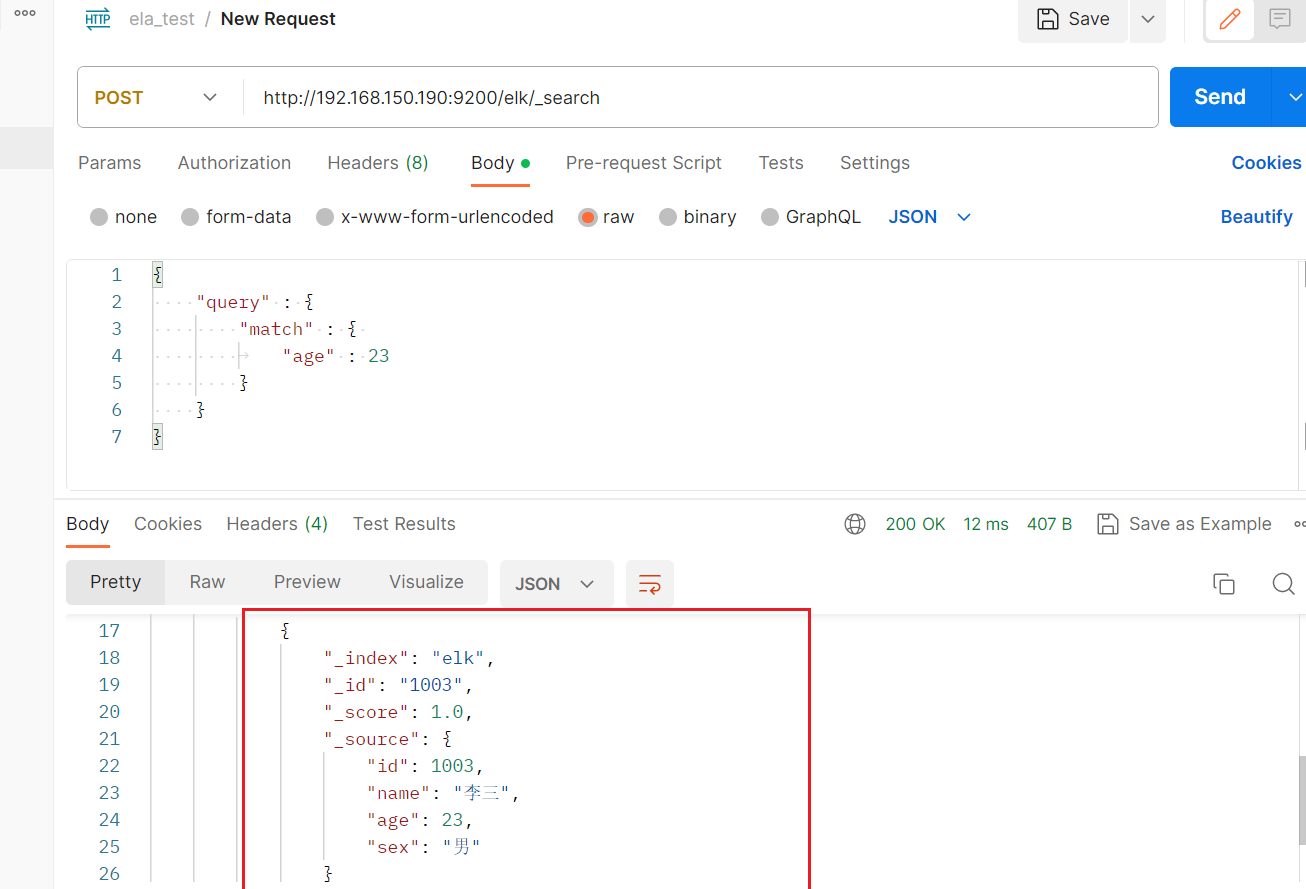
匹配多个姓名数据
POST /elk/_search #请求数据 { "query" : { "match" : { "name" : "张四 李三 王老五" } } }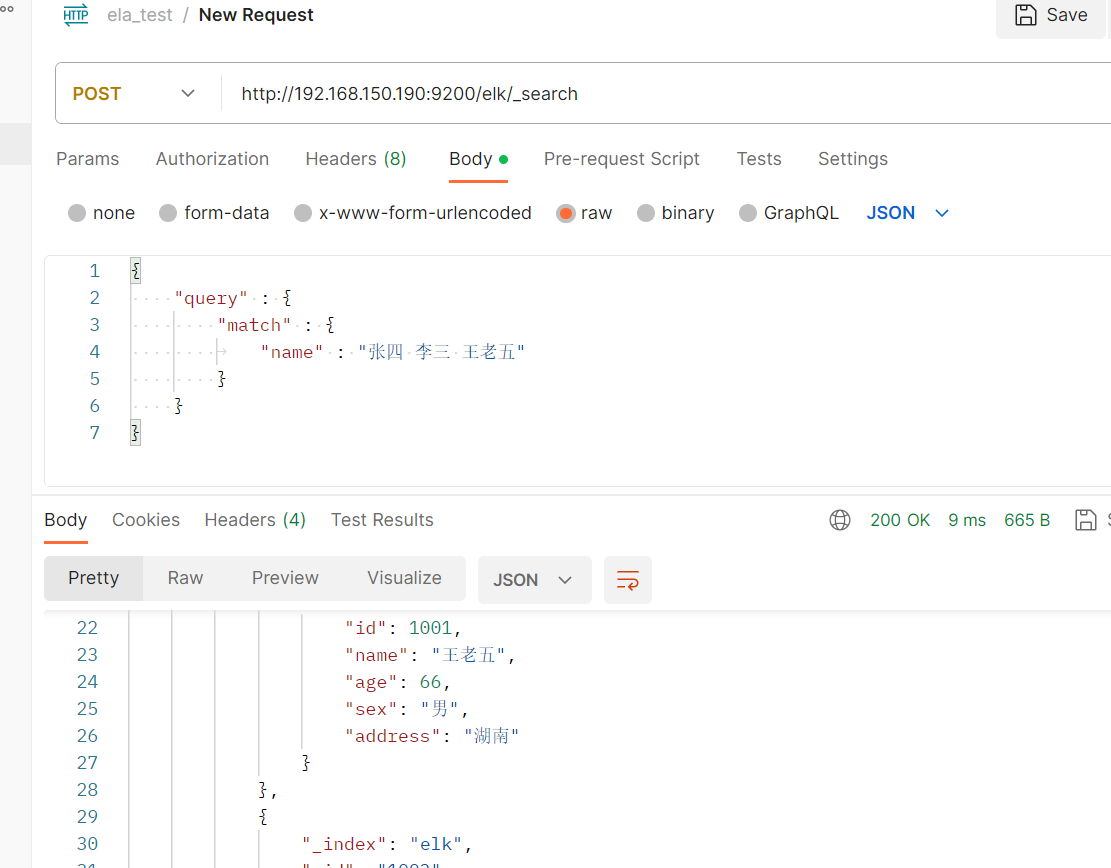
高亮显示
POST /elk/_search #请求数据 { "query": { "match": { "name": "王老五" } }, "highlight": { "fields": { "name": {} } } }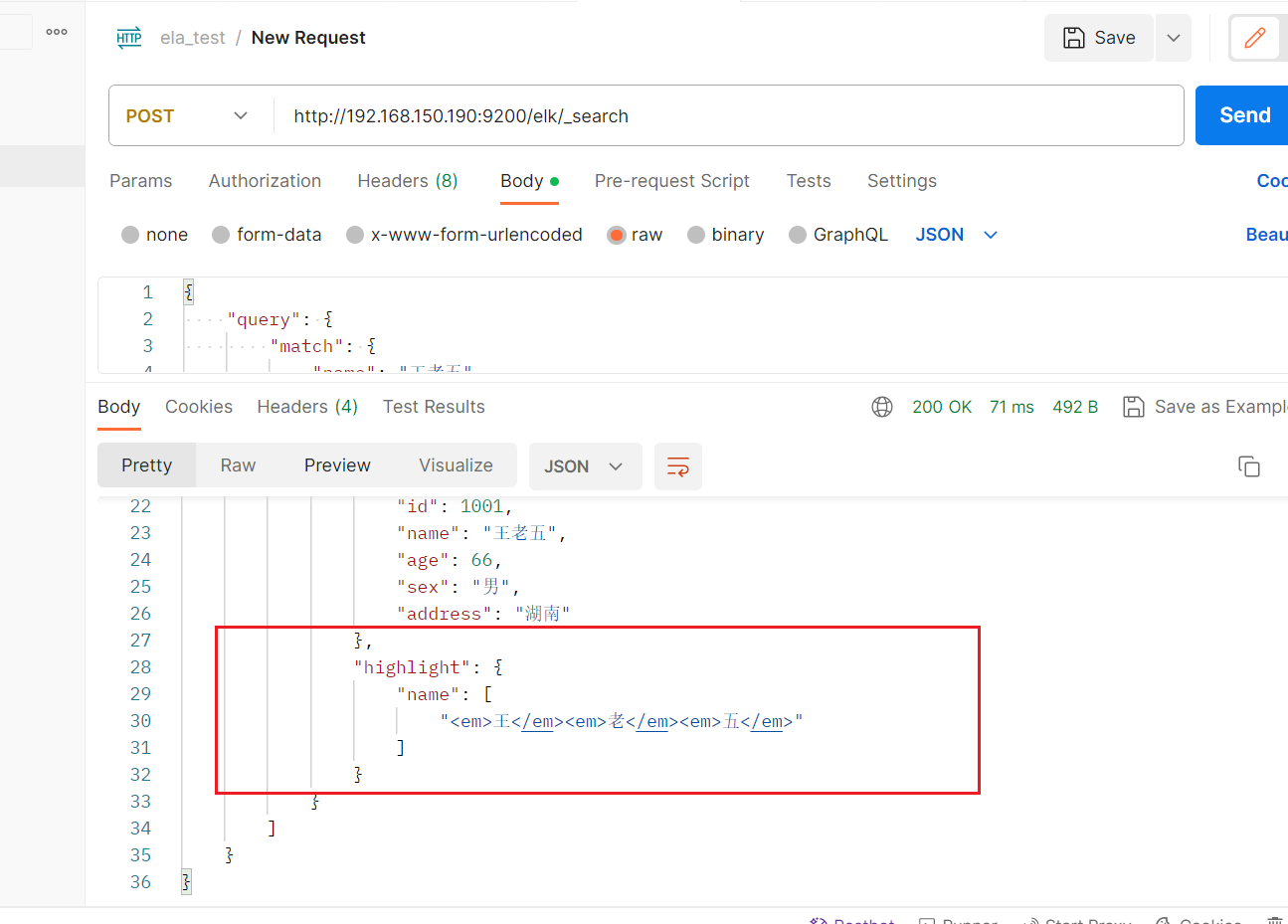
-
Term Query:
Term查询用于匹配确切的词语。它通常用于精确匹配,而不进行全文本搜索。{ "query": { "term": { "field_name": "exact_term" } } } -
Bool Query: Bool查询允许将多个查询组合在一起,并使用逻辑运算符(must、must_not、should)来定义查询逻辑。
{ "query": { "bool": { "must": [ { "match": { "field1": "value1" } }, { "term": { "field2": "value2" } } ], "must_not": [ { "range": { "field3": { "gte": "2022-01-01" } } } ], "should": [ { "term": { "field4": "value3" } } ] } } }查询年龄大于18岁的男性用户。
POST /elk/user/_search #请求数据 { "query": { "bool": { "filter": { "range": { "age": { "gt": 18 } } }, "must": { "match": { "sex": "男" } } } } } -
Range Query:
Range查询用于匹配指定范围内的值。{ "query": { "range": { "field_name": { "gte": "min_value", "lte": "max_value" } } } } -
Wildcard Query:
通配符查询允许使用通配符进行模糊匹配。{ "query": { "wildcard": { "field_name": "search*term" } } } -
Nested Query:
Nested查询用于在嵌套文档中执行查询。{ "query": { "nested": { "path": "nested_field", "query": { "match": { "nested_field.property": "value" } } } } }
这些是一些基本的DSL查询示例。在实际应用中,可以将这些查询类型组合使用,以满足特定的搜索需求。此外,Elasticsearch还支持聚合(Aggregation)、排序(Sorting)、分页(Pagination)等高级功能,可以进一步扩展查询的能力。
其他(聚合)
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
POST /elk/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!