一种基于外观-运动语义表示一致性的视频异常检测框架 论文阅读
A VIDEO ANOMALY DETECTION FRAMEWORK BASED ON APPEARANCE-MOTION SEMANTICS REPRESENTATION CONSISTENCY 论文阅读
论文标题:A VIDEO ANOMALY DETECTION FRAMEWORK BASED ON APPEARANCE-MOTION SEMANTICS REPRESENTATION CONSISTENCY
文章信息:

发表于:ICASSP 2023(CCF B)
原文链接:https://arxiv.org/abs/2204.04151
源码:无
ABSTRACT
视频异常检测是一项重要但具有挑战性的任务。目前流行的方法主要研究正常模式和异常模式之间的重构差异,而忽略了行为模式的外观和运动信息之间的语义一致性,使得结果高度依赖于帧序列的局部上下文,缺乏对行为语义的理解。
为了解决这个问题,我们提出了一个外观-运动语义表示一致性框架,该框架利用正常数据和异常数据之间的外观和运动语义表示的一致性差距。
设计了双流结构来对正常样本的外观和运动信息表示进行编码,并提出了一种新的一致性损失来增强特征语义的一致性,从而可以识别出一致性较低的异常。
此外,异常的低一致性特征可以用来降低预测帧的质量,这使得异常更容易被发现。实验结果证明了该方法的有效性。
1. INTRODUCTION
视频异常检测(VAD)是指识别不符合预期行为的事件[1],在公共安全场景中具有重要的实际价值。尽管在[2, 3]中投入了大量努力,由于异常的罕见性和模糊性,VAD仍然是一项极具挑战性的任务[1]。收集平衡的正常和异常样本,并使用监督二分类模型解决这个任务是不可行的。因此,VAD的典型解决方案通常被制定为一个无监督学习问题,目标是仅使用正常数据训练模型以挖掘正常模式。不符合该模型的事件被视为异常。现有的主流VAD方法几乎都遵循重建或未来帧预测模式。基于重建的方法[4, 5, 6, 7]通常在正常数据上训练自动编码器(AEs),并期望异常数据在测试时产生较大的重建误差,使得异常数据可从正常数据中检测出来。基于预测的方法[3]使用视频帧的时间特征来预测基于给定先前帧序列的下一帧,然后使用预测误差进行异常测量。然而,这样的方法高度依赖于帧序列的局部上下文,并且一些研究[6, 8]表明,仅在正常数据上训练的AE有时能够很好地重建异常,导致性能较差。因此,一些研究人员[9, 10, 11]尝试利用活动的运动信息,其中包含许多表示行为属性的语义,以实现VAD的良好性能。然而,这些方法仅在测试阶段结合外观和运动的信息来检测异常,而在训练阶段并未在相同的空间中联合建模这两种类型的信息[9, 10, 11, 12, 13],这使得难以捕捉VAD的两种模态之间的关联。最近,提出了这些最先进的(SOTA)方法[8, 14]来模拟两种模态的关系,并且可以在大多数情况下检测异常,但由于关系建模方法的不稳定性,结果仍然远远低于期望。例如,Cai等人[14]使用内存网络存储两种模态的关系,以便不合适大小的内存模块容易限制网络的性能。此外,Liu等人[8]在流重建和帧预测的组合中使用混合框架,但结果高度依赖于先前阶段流重建的质量,这使得难以训练一个稳定的模型。而且,这些方法建模的关系主要用于恢复像素信息,但仍然缺乏对行为语义的理解。在本文中,我们在通过外观-运动语义表示一种简单而新颖的网络中充分利用正常事件的多模态知识来检测异常,称为AMSRC-Net。具体来说,受到使用多模态的SOTA方法[8, 10, 12, 14]的启发,我们首先通过通用的双流编码器提取正常事件中外观和运动的代表性特征。与以前的工作不同,我们观察两种模态特征之间的一致性,并提出一种新颖的一致性损失,以在特征空间中明确地建模语义一致性。然后,所提出的网络为异常样本生成更低的一致性特征,这通常反映出不规则的行为语义,并可用于检测异常。此外,我们设计了一个简单的流引导融合模块,它利用上述特征语义一致性差异来增强预测质量差异。对三个公共VAD数据集进行的大量实验证明,我们提出的AMSRC-Net的性能优于SOTA方法。
2. PROPOSED METHOD
正如图1所示,我们提出的AMSRC-Net由三部分组成:一个双流编码器、一个解码器和一个流引导融合模块(FGFM)。我们首先将先前的视频帧图像及其光流剪辑输入到双流编码器中,以获得外观和运动的特征表示。然后,我们提出的一致性损失用于进一步增强正常样本中外观和运动信息之间特征语义的一致性。接下来,两个一致的模态特征被输入到流引导融合模块中。最后,将融合后的特征馈入解码器,以预测未来的帧图像。AMSRC-Net的详细网络架构如图2所示,所有组件将在以下小节中详细介绍。
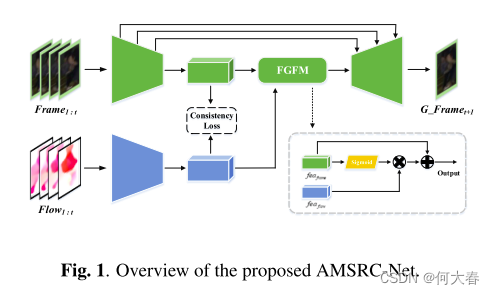
双流编码器和解码器:
双流编码器从输入视频帧图像和相应的光流中提取特征表示。由于一致性约束,提取的特征语义高度相似,代表了监控视频中的前景行为特性。然后,训练解码器以通过采用通过融合来自前一步骤的提取特征而形成的聚合特征来生成下一帧。聚合特征可能缺乏低级信息,如背景、纹理等。为了解决这个问题,我们在帧流编码器和解码器之间添加了一个类似UNetlike的跳过连接结构[15],以保留这些与预测高质量未来帧的行为无关的低级特征。
FGFM:
由于在双流编码器的末端采用了ReLU激活函数,输出特征中许多特征表示具有零值。在训练双流特征的语义一致性时,我们观察到非零特征表示上的两个流特征的分布是高度一致的。相反,异常数据生成的外观-运动特征的较低一致性反映了在非零特征表示上的两个流特征分布的较大差异。为了利用上述特征表示差距来提高VAD性能,我们设计了一个简单的流引导融合模块,以扩大正常和异常样本之间的预测误差差距。给定外观特征
f
e
a
f
r
a
m
e
fea_{frame}
feaframe? 和运动特征
f
e
a
f
l
o
w
fea_{flow}
feaflow?,我们在没有线性投影和残差操作的情况下,使用
f
e
a
f
r
a
m
e
fea_{frame}
feaframe? 和
f
e
a
f
l
o
w
fea_{flow}
feaflow? 的激活之间的Hadamard乘积来生成融合特征
f
e
a
f
u
s
e
d
fea_{fused}
feafused?,该特征用于预测:
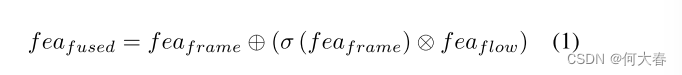
其中,σ代表Sigmoid函数,⊕和?分别表示矩阵加法和Hadamard乘积。在正常和异常数据的融合特征表示中存在差距,只有正常数据的融合特征被训练用于生成高质量的未来帧。随着训练过程中融合特征表示中差距的增加,预测帧质量的差距也被放大。
Loss Function:
我们遵循先前基于预测的VAD工作[3],使用强度和梯度差异来使预测接近其真实值。强度损失确保了预测和其真实值之间像素的相似性,而梯度损失可以使预测的图像更加清晰。我们通过最小化预测帧
x
~
\widetilde{x}
x
与其真实值
x
x
x之间的
l
2
l_2
l2?距离来实现:

梯度损失定义为:
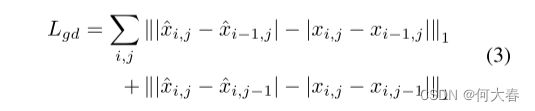
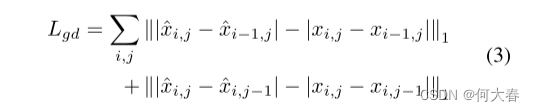
其中i、j表示视频帧的空间索引。
为了建模正常样本的外观和运动语义表示的一致性,我们最小化由双流编码器编码的正常样本的外观和运动特征之间的余弦距离。提出的一致性损失定义如下:
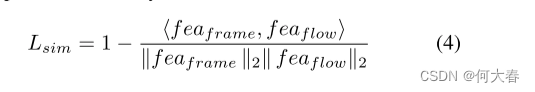
总损失L的形式如下:
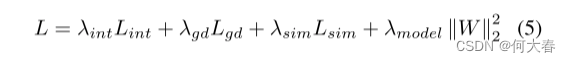
其中,
λ
i
n
t
λ_{int}
λint?、
λ
g
d
λ_{gd}
λgd?、
λ
s
i
m
λ_{sim}
λsim?是平衡超参数,W是模型的参数,
λ
m
o
d
e
l
λ_{model}
λmodel?是控制模型复杂性的正则化超参数。
Anomaly Detection:
在测试阶段,异常评分由两部分组成:
(1) 外观与运动特征的不一致
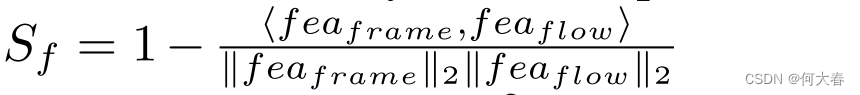
(2) 未来帧预测误差

然后,通过使用加权策略将这两部分融合,得到最终的异常分数,具体如下:

其中,
u
f
u_f
uf?、
δ
f
δ_f
δf?、
u
p
u_p
up?和
δ
p
δ_p
δp?分别表示所有正常训练样本的外观和运动特征之间的不一致性以及预测误差的平均值和标准差,
w
f
w_f
wf?和
w
p
w_p
wp?表示两个分数的权重。
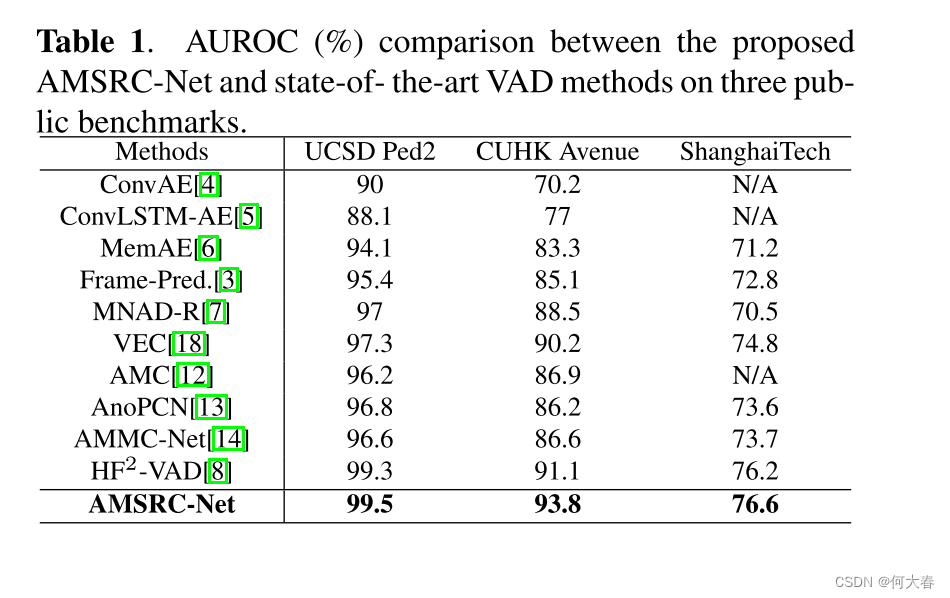
3. EXPERIMENTAL RESULTS
4. CONCLUSION
提出了一个外观-运动语义表示一致性框架,该框架利用正常数据和异常数据之间的外观和运动语义表示的一致性来检测异常。
设计了一个双流编码器来提取正常样本的外观和运动特征,并添加约束来增强其一致性语义,从而可以识别出一致性较低的异常样本。
此外,流引导融合模块可以融合异常的外观和运动特征的一致性较低,从而影响预测帧的质量,使异常产生较大的预测差异。
在三个公共基准上的实验结果表明,我们的方法比最先进的方法性能更好。
阅读总结:
和上一篇一个作者,方法也很类似。上一篇是运动信息替换外观信息用于后续的解码器,这篇是通过一个模块将两个结合起来。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!