贪心思想的经典题目
一、区间问题
区间问题,往往需要我们明确几个区间开始位置和结束位置之间的关系,例如几个区间是否有重合的部分等等,这个时候最好的方法就是画图😎!
判断区间是否重叠
LeetCode 252:给定一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间?intervals[i] = [starti, endi]?,请你判断一个人是否能够参加这里面的全部会议。
示例:
输入:intervals = [[0,30],[15,20],[5,10]]
解释:存在重叠区间,一个人在同一时刻只能参加一个会议。
 ?
?
分析:这题判断区间是否重合,用人话来说就是判断你正在参加的这个会议还没结束,你是否又需要去开另一个会议?也就是将会议区间按开始时间排好之后,当前会议的结束时间是否大于下一个会议的开始时间。
-
如果是。那么你这个会还没结束又要去参加别的,存在重叠区间。
-
如果不是。不存在重叠区间。
public boolean canAttendMeetings(int[][] intervals) {
// 将区间按照会议开始实现升序排序
Arrays.sort(intervals, (v1, v2) -> v1[0] - v2[0]);
// 遍历会议,如果下一个会议在前一个会议结束之前就开始了,返回 false。
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] < intervals[i - 1][1]) {
return false;
}
}
return true;
}合并区间?
LeetCode 56:以数组intervals表示若干个区间的集合,其中单个区间为intervals[i] = [starti, endi]。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。?
示例:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
 ?
?
分析:很显然这题首先也是要找出重叠的区间,方法和上面一题一样:先按起始位置排序,然后从第二个区间开始,比较当前区间的起始位置和上一个区间的结束位置。
-
重叠,就合并。观察上图,合并的本质就是当前区间的起始位置和上一个区间的结束位置取最大值。合并后装入一个结果数组中。
-
不重叠。直接放到结果数组中。
public int[][] merge(int[][] intervals) {
//按起始位置排序
Arrays.sort(intervals, (v1, v2) -> v1[0] - v2[0]);
//新的结果返回数组
int[][] res = new int[intervals.length][2];
int idx = -1 ;
for(int[] interval :intervals){
// 如果结果数组是空的,或者当前区间的起始位置 > 结果数组中最后区间(上一个区间)的终止位置,
// 则两个区间不重叠,不用合并,直接将当前区间加入结果数组。
if(idx == -1 || interval[0] > res[idx][1]){
res[++idx]=interval;
}else{
//合并的本质就是把两个区间的结束位置取一个最大值
res[idx][1] = Math.max(res[idx][1],interval[1]);
}
}
return Arrays.copyOf(res,idx + 1);
}?
插入区间?
LeetCode 57:给你一个无重叠的,按照区间起始端点排序的区间列表。在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
示例 2:
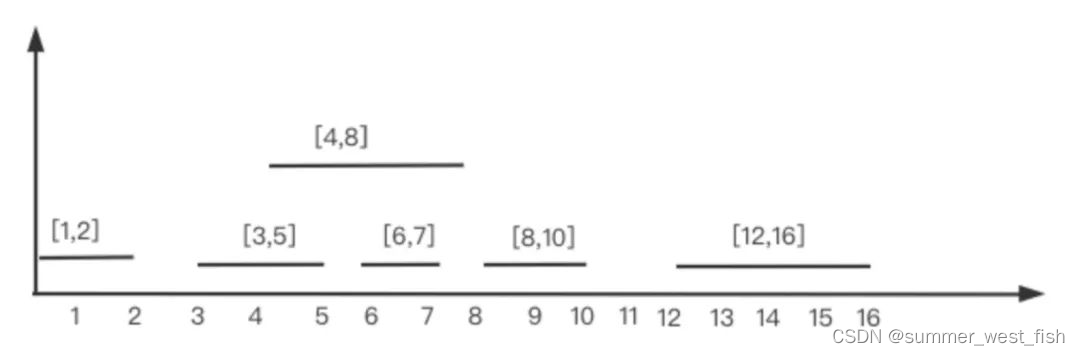
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
 ?
?
分析:本题就是上一题的再拓展,本题中的区间已经按照起始端点升序排列,因此我们直接遍历区间列表,寻找新区间的插入位置即可。具体步骤如下:
-
首先将新区间左边且相离的区间加入结果集(遍历时,如果当前区间的结束位置小于新区间的开始位置,说明当前区间在新区间的左边且相离)
-
接着判断当前区间是否与新区间重叠,重叠的话就进行合并,直到遍历到当前区间在新区间的右边且相离,将最终合并后的新区间加入结果集;
-
最后将新区间右边且相离的区间加入结果集。
相当于把原数组分成两个部分:比新区间小的且不重合的、重合的、比新区大的且不重合的?
public int[][] insert(int[][] intervals, int[] newInterval) {
int[][] res = new int[intervals.length + 1][2];
int idx = 0;
// 遍历区间列表:
// 首先将新区间左边且相离的区间加入结果集
int i = 0;
while (i < intervals.length && intervals[i][1] < newInterval[0]) {
res[idx++] = intervals[i++];
}
// 判断当前区间是否与新区间重叠,重叠的话就进行合并,直到遍历到当前区间在新区间的右边且相离,
// 将最终合并后的新区间加入结果集
while (i < intervals.length && intervals[i][0] <= newInterval[1]) {
newInterval[0] = Math.min(intervals[i][0], newInterval[0]);
newInterval[1] = Math.max(intervals[i][1], newInterval[1]);
i++;
}
res[idx++] = newInterval;
// 最后将新区间右边且相离的区间加入结果集
while (i < intervals.length) {
res[idx++] = intervals[i++];
}
return Arrays.copyOf(res, idx);
}二、字符串分割
LeetCode 736:字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。?
示例 1:
输入:s = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释:划分结果为 "ababcbaca"、"defegde"、"hijhklij" 。每个字母最多出现在一个片段中。像 "ababcbacadefegde", "hijhklij" 这样的划分是错误的,因为划分的片>- 段数较少。
示例 2:
输入:s = "eccbbbbdec"
输出:[10]
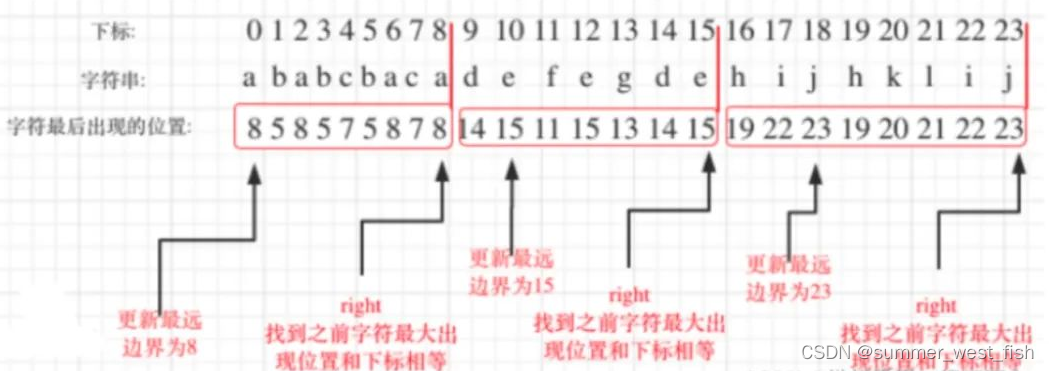
分析:如何把同一个字母的都圈在同一个区间里呢🤔?该遍历过程相当要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。所以可以这么做:
-
首先,统计每一个字符最后出现的位置
-
然后,从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点。?
public List<Integer> partitionLabels(String s) {
//结果数组,用于保存每个子串的长度
List<Integer> list = new ArrayList<>();
//用于保存每个字符在字符串中最后一次出现的索引
int[] edge = new int[26];
char[] chars = s.toCharArray(); //将字符串s转换为字符数组chars。
for(int i = 0 ;i < chars.length;i++){
edge[chars[i] - 'a'] = i;
}
int idx = 0; //当前已经遍历过的字符中最大的索引
int last = -1; //上一个子串的结束索引
for(int i = 0; i < chars.length; i++){
idx = Math.max(idx,edge[chars[i] - 'a']);
if(i == idx){
list.add(i-last);
last = i;
}
}
return list;
}edge[chars[i] - 'a'] = i;是用来更新数组edge中每个字符的最后出现位置索引。
初始化两个变量idx和last,分别表示当前已经遍历过的字符中最大的索引和上一个子串的结束索引😁。初始时,last的值为-1,表示还没有开始枚举子串。
再次遍历字符数组chars,对于每个字符的索引i,更新idx为idx和edge[chars[i] - 'a']中的较大值。这样,idx表示当前已经遍历过的字符中最大的索引(即最远的字符)。
如果当前字符的索引i等于idx,说明当前字符是一个独立的子串,因为它是从上一个子串后面的第一个出现的。此时,将当前子串的长度i - last添加到列表list中,并将last更新为当前索引i😊,以便开始下一个子串的计算。遍历完成后,列表list中保存了每个子串的长度,将其作为结果返回。
?
三、加油站问题?
LeetCode 134:在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
示例 :
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释: 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。因此,3 可为起始索引。
分析:什么时候能汽车跑?只有gas[i] - cost[i] >= 0的时候才能开始跑,这样i才能作为开始位置。
再思考:汽车什么情况下能一直跑🤔?例如从位置i跑到位置i+4,是不是油量curSum有所剩余才能跑?如果跑到i+3,curSum < 0无法跑完全程,说明开始位置选取的不对,i到i+3都无法作为开始位置,需要更新开始位置。
特殊情况:如果全程的总油量减去总消耗小于零,则无论从哪里开始都跑不完全程
public int canCompleteCircuit(int[] gas, int[] cost) {
int curSum = 0;
int totalSum = 0;//总油量
int start = 0;
for(int i = 0 ; i < gas.length;i++){
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if(curSum < 0){
start = i + 1; //更新汽车开始的位置
curSum = 0 ;//归零curSum。重新开始算
}
}
if(totalSum < 0) return -1; //说明从哪里开始开车都不行
return start;
}?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!