个人调用OCR
2024-01-07 17:26:08
一、自己训练模型
二、调用现成API
此处介绍百度智能云API,因为有免费次数。(原来一些网址在百度不是默认显示网址的,而是自己的网站名字)
首页找到OCR?


?每个人每月能用1K次。(有详细的API文档说明,不过跟着我的步骤来也足够)

?
?在创建应用后得到API key和 Secret Key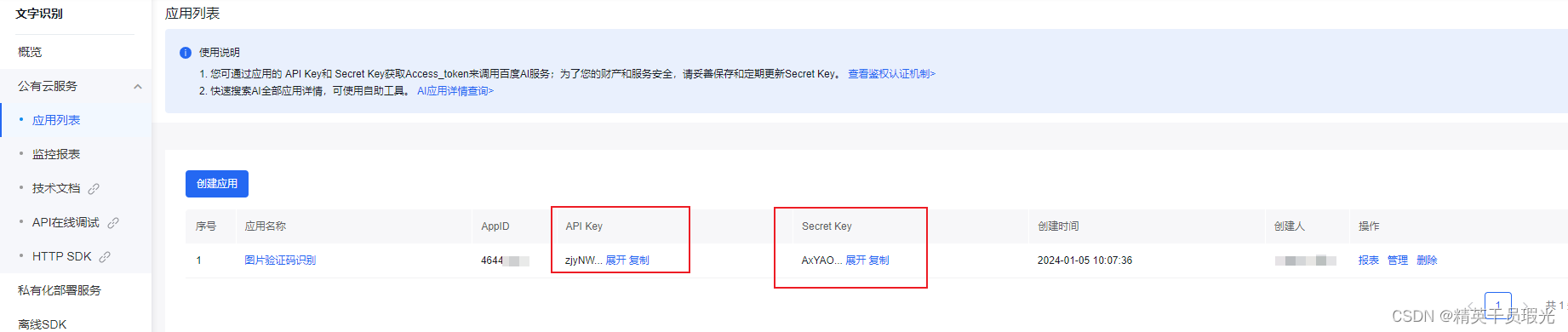
?
?还需要拿到一个access token
#官方代码
import requests
import json
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxxxx&client_secret=xxxxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()
# 更改为个人使用版本
def get_token(self):
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s' \
'&client_secret=%s' % (self.apikey,self.apisecret)
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
if response:
print(response.json())
# 存储token
try:
self.redis1["baidutoken"]=response.json()["access_token"]
except Exception as e:
print("请求报错,无法获取token")全代码
import requests
import base64
# 封装百度类
class Baidu:
def __init__(self):
# apikey
self.apikey = "12345"
# api secretkey
self.apisecret = "12345"
self.redis = {}
# 文字图片识别
def cor(self, filename=r"C:\Users\eqwimg\test.png"):
# 定义请求地址
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 读取图片
f = open(filename, 'rb')
# base64编码
img = base64.b64encode(f.read())
# 定义请求参数
params = {"image": img}
self.get_token()
access_token = self.redis.get("baidutoken")
request_url = request_url + "?access_token=" +access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
# 发起请求
response = requests.post(request_url, data=params, headers=headers)
if response:
print(response.json())
# 获取识别的结果
num = ""
for x in response.json()["words_result"]:
num += x["words"]
return num
# 获取token
def get_token(self):
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s' \
'&client_secret=%s' % (self.apikey,self.apisecret)
response = requests.get(host)
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
if response:
print(response.json())
# 存储token
try:
self.redis["baidutoken"]=response.json()["access_token"]
except Exception as e:
print("请求报错,无法获取token")
def cor():
# 实例化对象
baidu = Baidu()
num = baidu.cor()
times = 0
success = False
while times<3 and not success:#最大识别3次
num = baidu.cor()
if len(num) == 4: #默认是4为识别码
success = True
else:
break
times += 1
if success:
return num
else:
return None
cor()借鉴:
文章来源:https://blog.csdn.net/Zhong____/article/details/135406383
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!