探索Scrapy-spider:构建高效网络爬虫
Spider简介
Scrapy中的Spider是用于定义和执行数据抓取逻辑的核心组件。Spider负责从指定的网站抓取数据,并定义了如何跟踪链接、解析内容以及提取数据的规则。它允许您定制化地指定要抓取的网站、页面和所需的信息。Spider的作用是按照预定的规则爬取网页,从中提取所需的数据,并将数据传递给Scrapy引擎进行处理。
以下是一个简单的Scrapy Spider示例代码:
import scrapy
class MySpider(scrapy.Spider):
name = 'example_spider'
start_urls = ['http://example.com']
def parse(self, response):
# 在这里编写处理响应的逻辑
# 可以使用XPath或CSS选择器提取数据
title = response.css('title::text').get()
body = response.css('body::text').get()
# 可以将提取到的数据通过yield传递给Pipeline进行处理
yield {
'title': title,
'body': body
}
在这个示例中:
MySpider是一个继承自scrapy.Spider的Spider类。name属性定义了Spider的名称。start_urls属性包含了Spider开始抓取的初始URL列表。parse方法是用于处理网页响应的默认方法。在这里,使用了CSS选择器从网页中提取了标题和正文内容,并通过yield语句将提取到的数据作为字典传递给Pipeline进行处理。
Spider传参方式
在Scrapy中,Spider之间或Spider内部的不同方法之间可以通过多种方式进行参数传递和通信:
-
构造函数参数传递:
- 在Spider的构造函数中定义自定义参数,并在初始化Spider时传递这些参数。这些参数可以在Spider的各个方法中使用。
import scrapy class MySpider(scrapy.Spider): name = 'example' def __init__(self, category=None, *args, **kwargs): super(MySpider, self).__init__(*args, **kwargs) self.category = category def start_requests(self): # 使用传递的参数构建初始请求 # self.category 可在这里使用 # ... -
Request对象传递参数:
- 在发送请求时,可以使用
meta参数将信息传递给下一个回调函数。这可以通过Request对象的meta属性进行。
import scrapy class MySpider(scrapy.Spider): name = 'example' def start_requests(self): url = 'http://example.com' custom_data = {'key': 'value'} yield scrapy.Request(url, callback=self.parse, meta={'custom_data': custom_data}) def parse(self, response): custom_data = response.meta.get('custom_data') # 使用传递的参数 # ... - 在发送请求时,可以使用
-
Spider属性传递:
- Spider对象的属性可以在不同的方法之间共享数据。
import scrapy class MySpider(scrapy.Spider): name = 'example' def start_requests(self): self.shared_data = 'some value' yield scrapy.Request('http://example.com', callback=self.parse) def parse(self, response): # 可以在这里使用 self.shared_data # ...
这些方法允许在Scrapy Spider之间或Spider内的不同方法之间传递参数和共享信息,使得数据和信息在爬取过程中得以灵活传递和使用。
需要注意的是scrapy是多线程异步运作,如果场景内对参数的顺序要求较高的话建议使用meta传参,而不要使用self全局传参,尤其是需要将爬取到的数据暂存在变量时要尤其注意这点
spider的钩子函数
Scrapy中的钩子函数(也称为回调函数)是Spider中用于定义爬取逻辑的关键部分。它们在不同的阶段执行,允许定制化处理请求、响应和提取数据的方式。以下是Scrapy中常用的钩子函数及其作用:
1. start_requests(self)
- 作用: 生成Spider的初始请求。
- 说明: 这个方法生成Spider开始抓取的初始请求。默认情况下,它从
start_urls属性中获取URL并生成请求。我们可以在这里手动创建并返回一个或多个Request对象,也可以使用yield关键字返回请求。
2. parse(self, response)
- 作用: 解析并处理页面响应。
- 说明: 默认的解析方法。当请求返回成功时,Scrapy将调用这个方法。我们可以在这里编写用于处理网页响应的逻辑,包括提取数据、跟进链接等。通常,我们能够使用XPath或CSS选择器从response对象中提取所需的数据。
3. parse_start_url(self, response)
- 作用: 解析Spider的起始URL的响应。
- 说明: 当Spider的起始URL返回成功时,Scrapy会调用这个方法。如果定义了
start_urls属性,则对每个起始URL的响应将会由这个方法处理。它允许你对起始页面的响应进行特定处理。
4. __init__()
- 作用: Spider对象初始化。
- 说明: 这是Spider对象的构造函数,在Spider实例化时调用。你可以在这里进行一些初始化设置或预处理工作。
5. closed(reason)
- 作用: 当Spider关闭时调用。
- 说明: 当Spider停止运行时,无论是因为抓取完成、异常退出或手动停止,都会调用这个方法。你可以在这里进行一些清理工作或输出总结信息。
另外,如果使用parse_start_url去生成url队列那么就无需使用
start_urls = [‘http://example.com’].
5. 其他自定义回调函数
除了以上常用的钩子函数外,我们还可以定义其他自定义的回调函数,用于处理特定页面的响应。例如,可以根据不同类型的页面定义不同的回调函数,以便从中提取数据或执行特定操作。
假如我们对于一条数据的提取需要逐条发送多个请求,我们可以这样写:
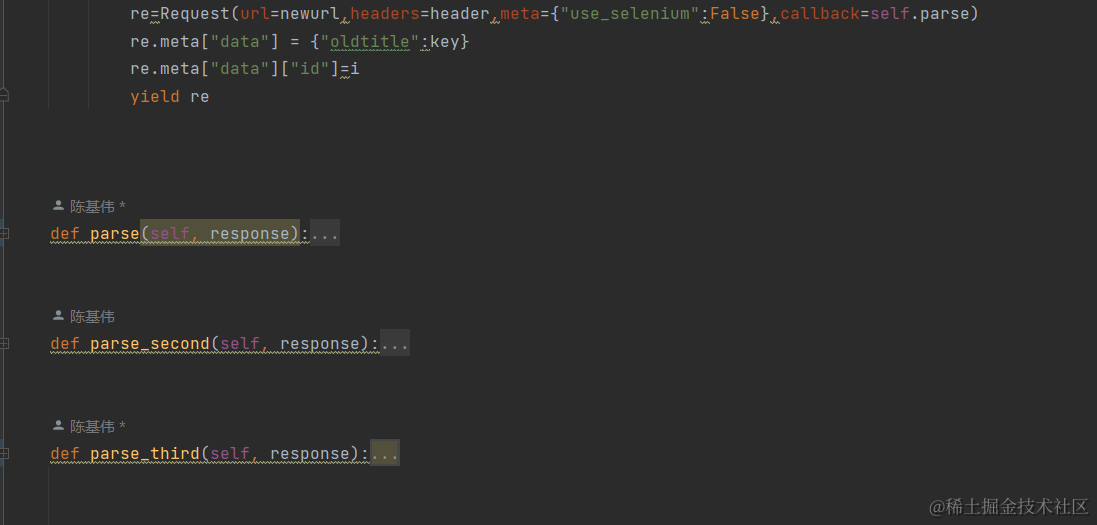
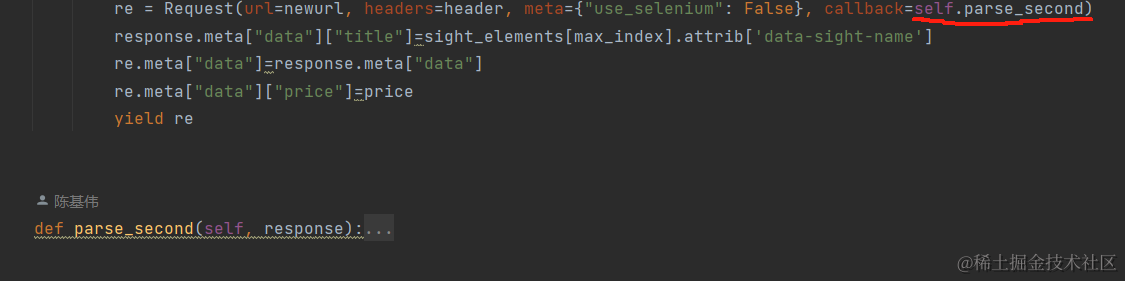
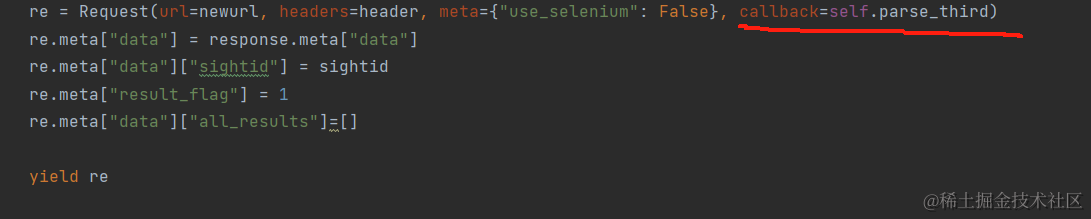
并使用meta存储传递信息。最终的收集完本条数据后返还item去给pip管道处理收集到的信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!