MySQL 时间日期函数,流程控制函数,加密解密函数以及聚合查询函数
注:本文仅作为查找函数和部分理解使用,希望能给大家带来帮助
以下函数均可以使用
SELECT NOW()等函数 FROM DUAL;来测试 //其中dual是一个准们用来测试的测试表
1.时间日期函数
1.1 获取时间的函数
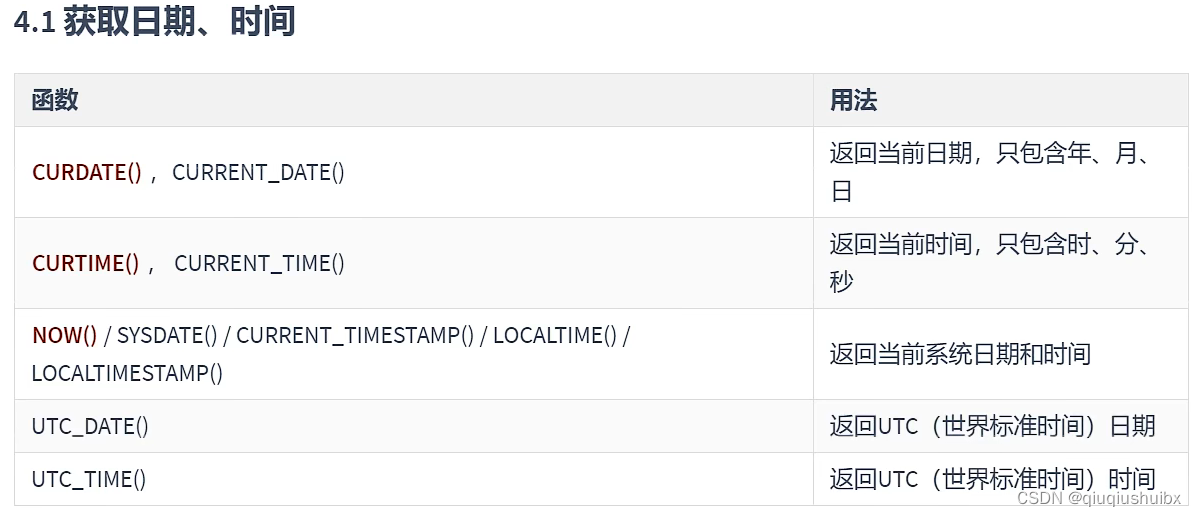
重点记忆前三个红色标注的函数,
第一个函数返回值如2024-01-02的形式
第二个如 15:20:21
第三个则是两者追加 如: 2024-01-02?15:20:21
1.2 年月日时分秒季度星期等函数?
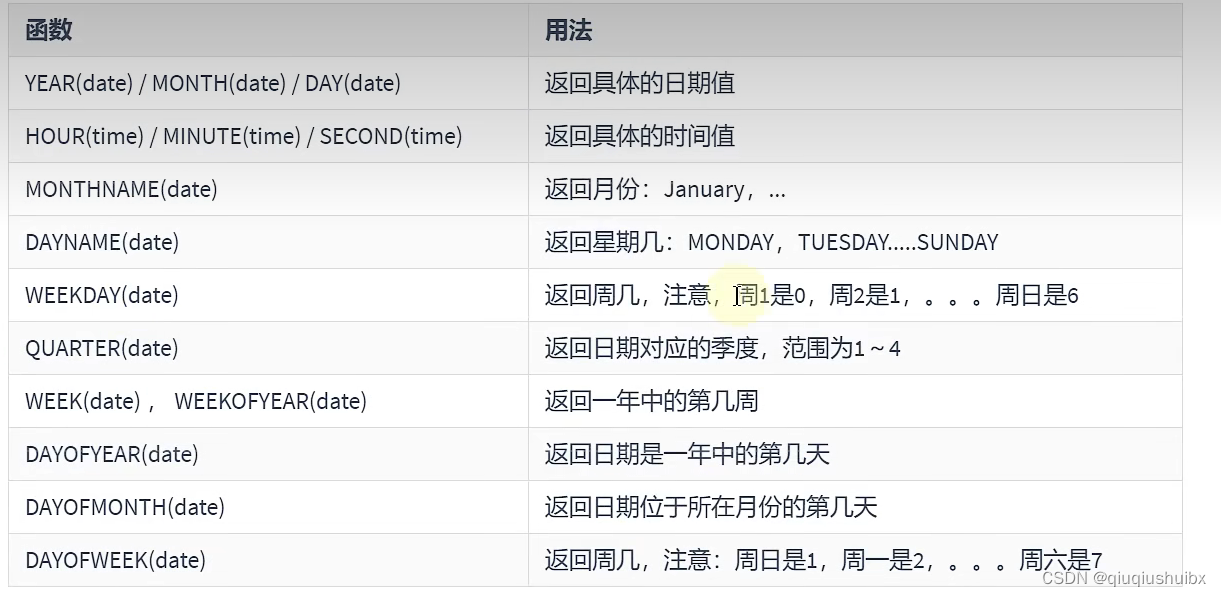
注:注意DAYOFWEEK 和 WEEKDAY的区别
1.3 日期与时间戳之间的转换函数(重点)

1.4 日期的操作函数以及操作表
?
相当于取date的某个单独的字段?
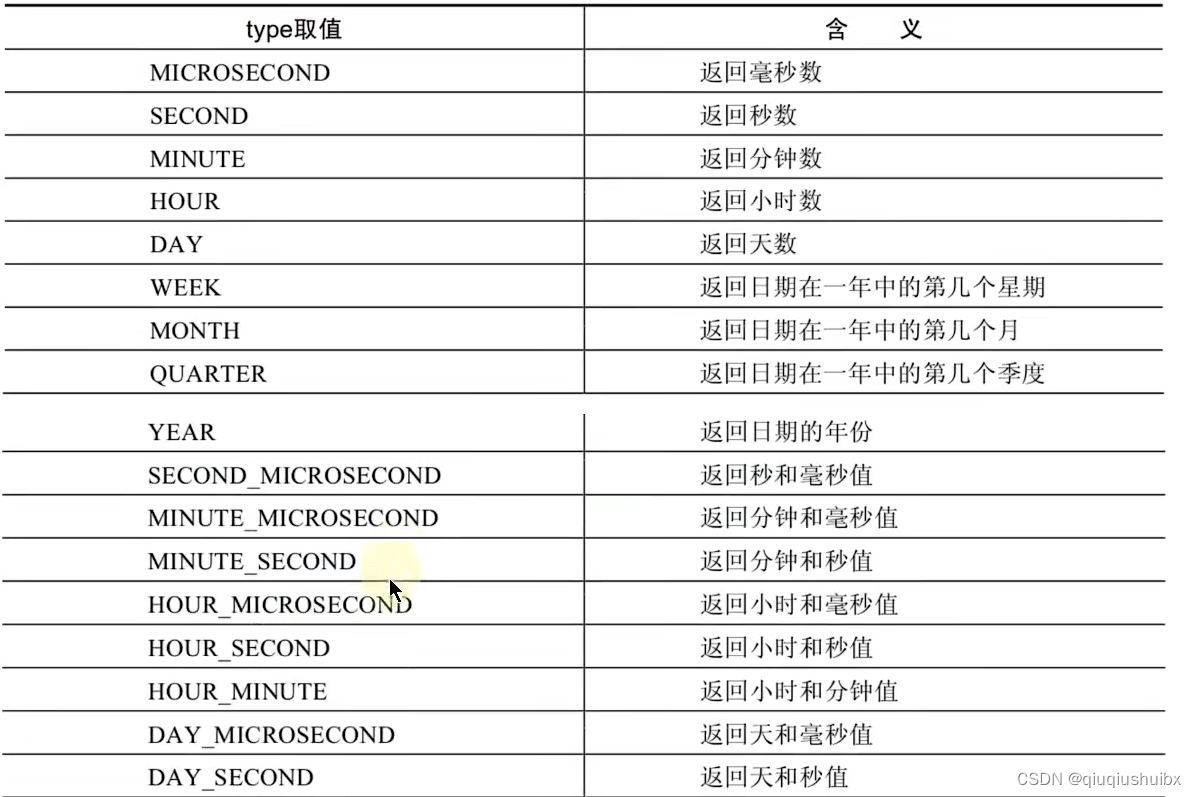
 ?
?
1.5 时间与秒钟转换函数?

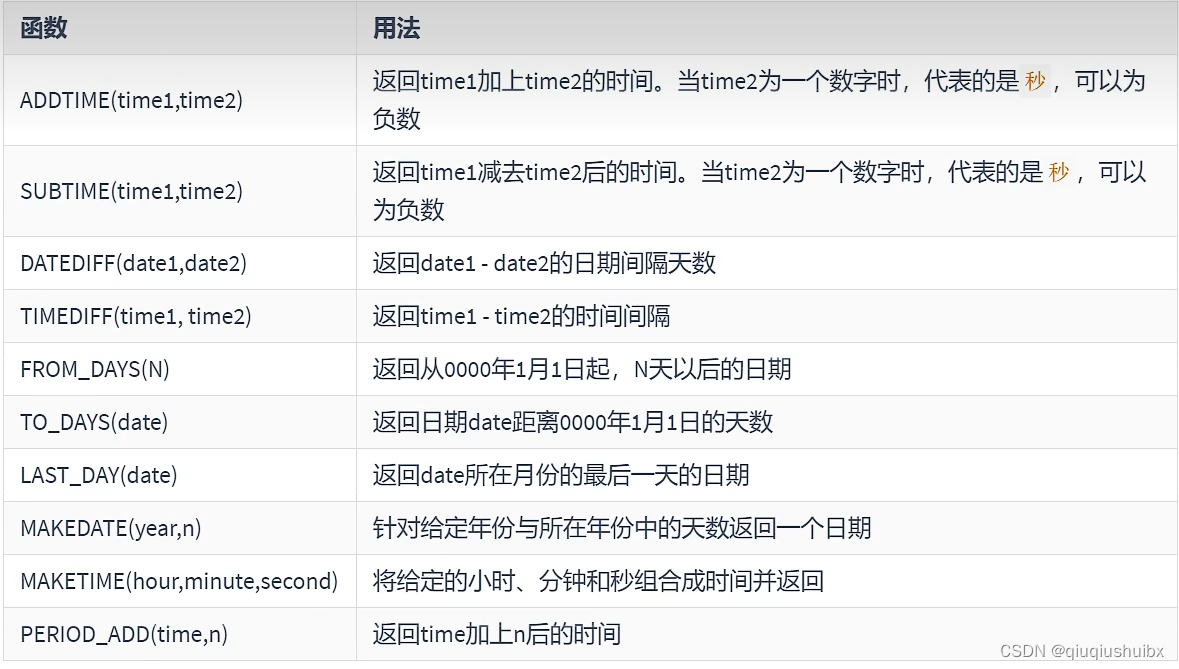
1.6 计算时间与日期函数
加减时间?
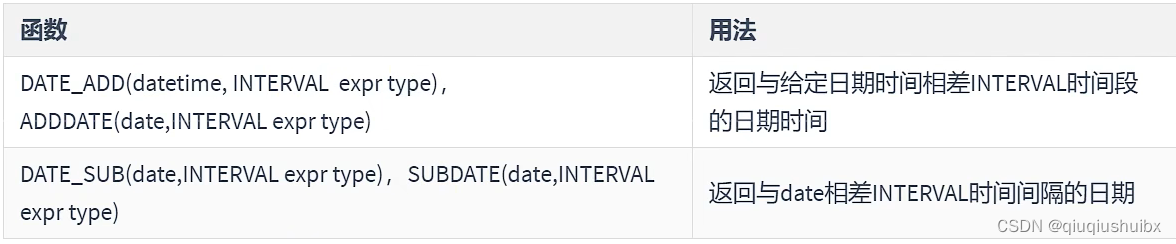
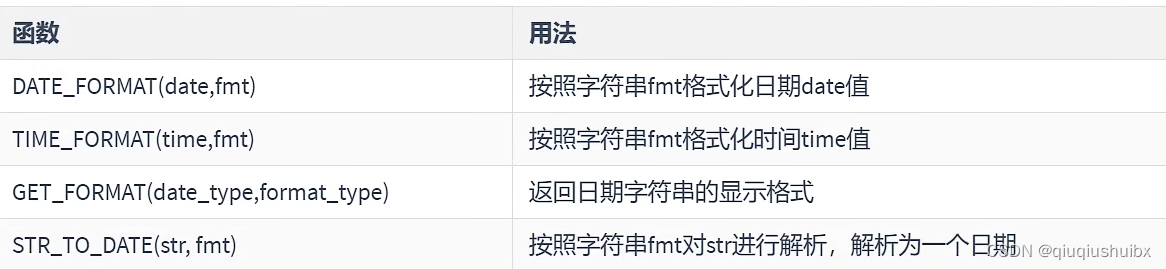
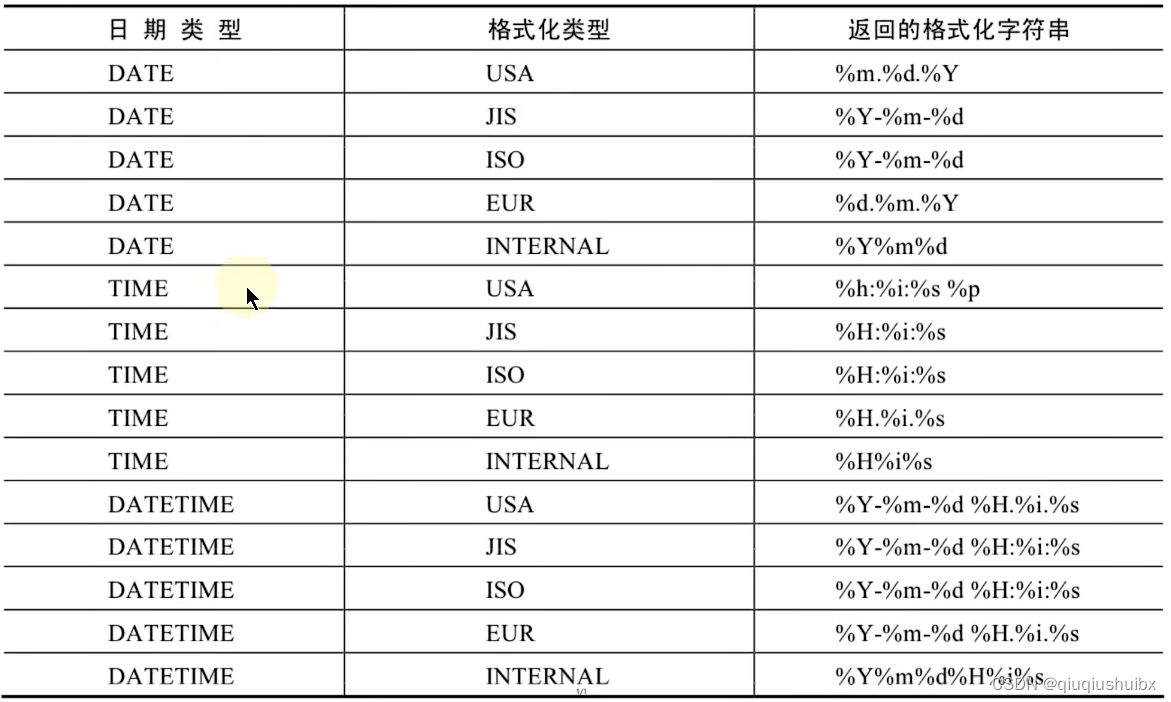
1.7 日期时间的格式化和解析
?
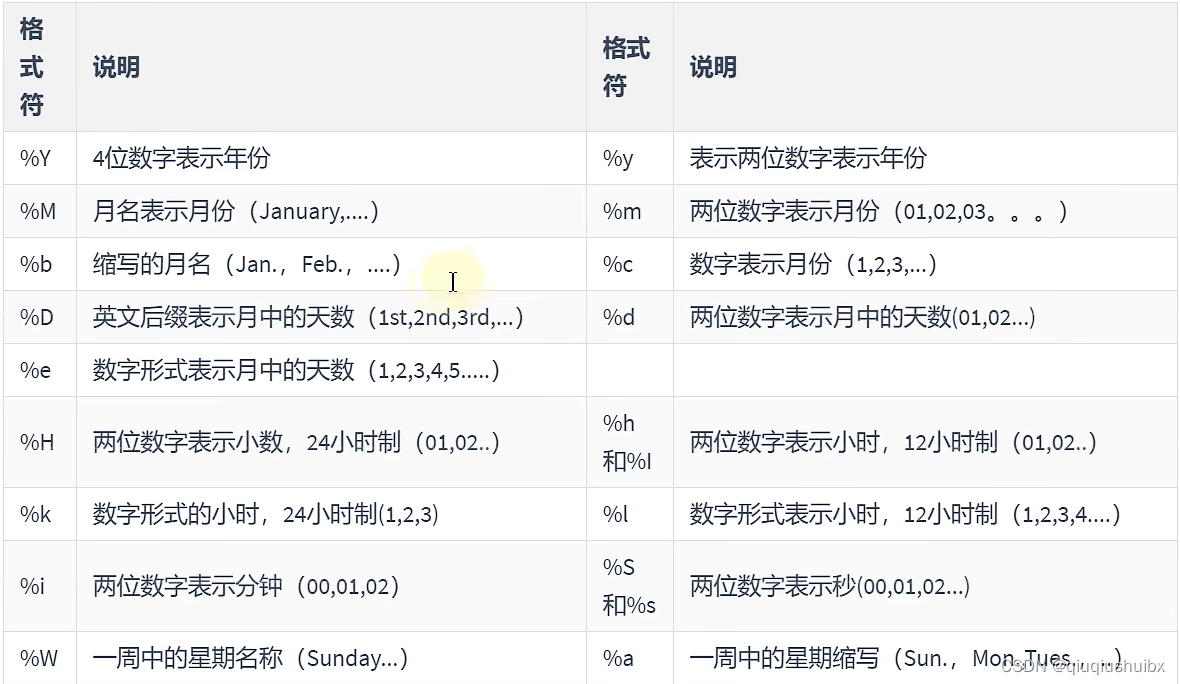
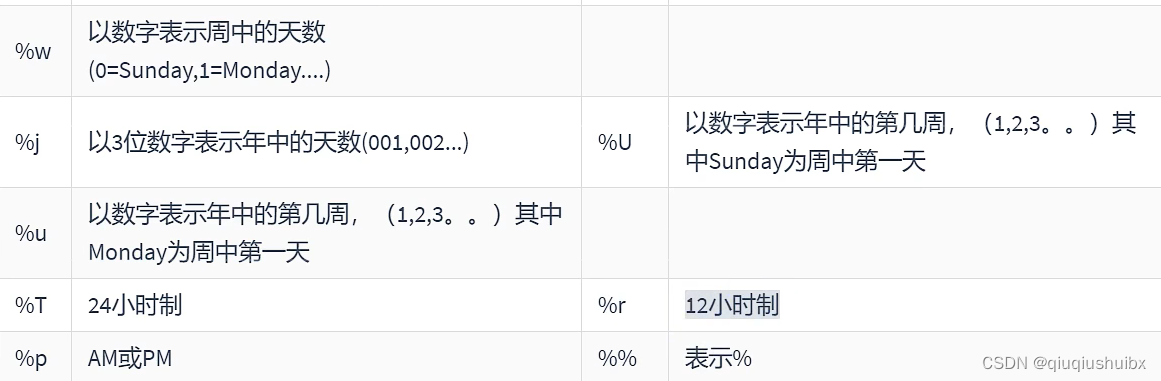
getformat的参数
比如 getformat(DATE,USA);
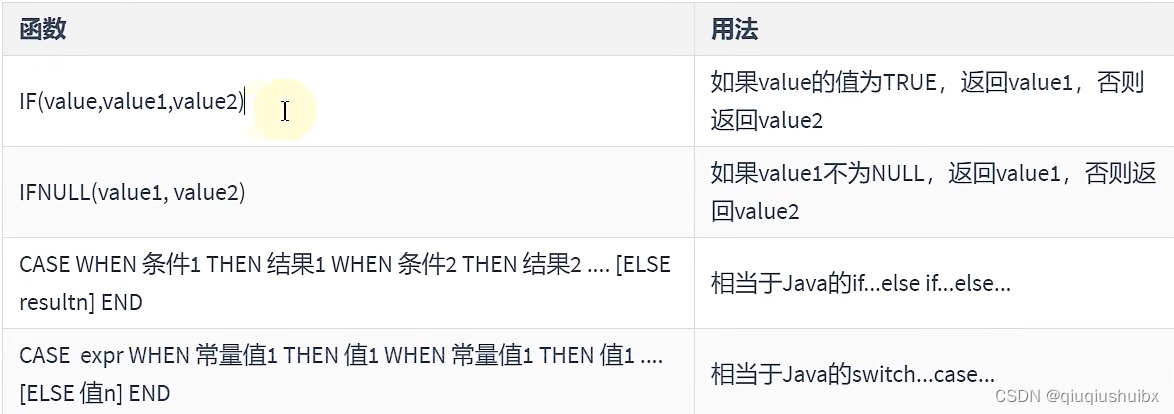
流程控制函数
类似于其他变成语言中的 if else? ?/? switch case
第一个函数类似于三目表达式,是就返回第一个,不是就返回第二个
case when
可以当成if else 还是 switch case 就看case和when之间有没有变量存在,如果有,当做switch case处理,否则当做 if else 处理
小疑问:循环语句???
其实select遍历表就自带循环语句了(暂时这么解释)?
加密解密函数

红色框标记的三个函数在mysql5.7版本可以使用,其实我们在配置8.0环境的时候就会发现不能使用简单的密码了,其实就是因为加密方式使用的是一个sha加密算法
?
聚合查询函数
这里介绍五个常用的聚合函数
这里count(1) 和 count(*) 也可以表示表中的字段条数
注:这里的count(字段)不会计算空字段
小问题:这里count(字段) , count(1) count(*) 哪个的效率更高呢??
取决于使用的存储引擎在MyISAM中使用 count(*) ,count(1),count(字段)的效率是相当的
但是使用InnoDB的话,count(1) 和 count(*) 的效率是高于count(字段)的

group by 的使用?
用于分组使用,一般是配合聚合函数来操作的
eg:将公司按照部门来分组,查询每个部门的最大/平均工资....
注:select中的非聚合函数的参数一定要在group by中出现作为分组项
例:假设我想把每个部门每个工种的最大工资统计出来,假设这里我们有两个部门,每个部门都有5个工种,理应出现十条数据,但是如果我们只按照两个部门分组就只会出现2条数据,这是不合理的.
with rollup
在分完组之后可以加一条记录,算出总和
注:使用with rollup之后就不可以使用 order by 了,两者相互冲突
having
?和where一样作为筛选条件,但是是在分完组之后进行筛选
having 和 where的对比
1.having的使用范围更广,甚至可以将过滤条件通通交给having
2.过滤条件中如果没有聚合函数,使用where的效率要高于having,因为where是先筛选再连接
having 是链接完了再筛选
SQL底层执行原理
首先我们先谈谈SQL的执行逻辑顺序
都是按照如上顺序来操作的,先读取表,连接表,进行where筛选,分组,having筛选,最后是排序,分页等等? 这也就说明了为啥用where先过滤一波效率要更高

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!