邢波(Eric Poe Xing)团队开发的 LLM360 让大模型实现真正的透明
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
在开源模型领域,开源大语言模型展现出了蓬勃的生命力,不仅数量激增,性能也日益优秀。甚至图灵奖获得者 Yann LeCun 也对此感叹:开源人工智能模型正在超越专有模型的道路上迈进。
专有模型在技术性能和创新能力方面展现出非凡的力量,但其闭源的本质成为大语言模型(LLMs)发展的障碍。一些开源模型虽然为从业者和研究者提供了多样化的选择,但大多数仅公开了最终的模型权重或推理代码,导致越来越多的技术报告局限于顶层设计和表面统计。这种封闭式策略不仅限制了开源模型的发展,还在很大程度上阻碍了整个 LLMs 研究领域的进步。
这表明这些 AI 大模型需要更全面、深入地共享信息,包括训练数据、算法细节、实现挑战以及性能评估的具体细节。
为此,Cerebras、Petuum 和 MBZUAI 等的研究者们共同提出了 LLM360。这是一项全面开源的 LLM 倡议,旨在向社区提供与 LLM 训练相关的一切内容,包括训练代码和数据、模型检查点以及中间结果等。LLM360 的目标是使 LLM 训练过程透明化,使每个人都能够复现,从而推动开放和协作式的人工智能研究的发展。

论文地址:https://arxiv.org/abs/2312.06550

博客:https://www.llm360.ai/blog/introducing-llm360-fully-transparent-open-source-llms.html
二、主要内容
研究人员设计了 LLM360 的架构,着重关注其设计原则以及完全开源的理念。他们详细描述了 LLM360 框架的组成部分,包括数据集、代码和配置、模型检查点以及指标等具体细节。LLM360 为当前和未来的开源模型树立了透明度的典范。
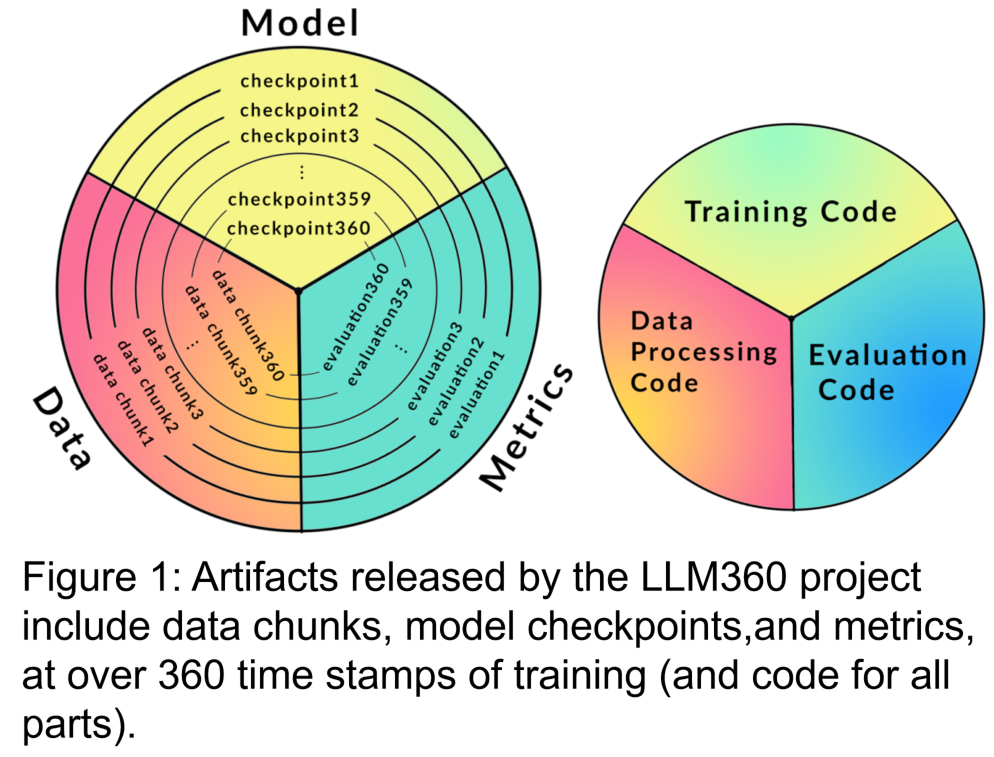
研究者在 LLM360 的开源框架下发布了两个从头开始预训练的大型语言模型:AMBER 和 CRYSTALCODER。AMBER 是基于 1.3T token 进行预训练的 7B 英语语言模型,而 CRYSTALCODER 则是基于 1.4T token 预训练的 7B 英语和代码语言模型。

在本文中,研究者们总结了这两个模型的开发细节、初步评估结果、观察结果以及从中汲取的经验和教训。值得注意的是,在发布时,AMBER 和 CRYSTALCODER 在训练过程中分别保存了 360 个和 143 个模型检查点。
LLM360 的开源理念涵盖了模型权重、训练代码以及创建 LLM 所涉及的微妙细节。这种方法旨在解决 LLMs 领域面临的几个挑战:
- 数据来源和对训练数据的理解,以减少偏见。
- 由于不公开完整的训练配置,导致无法重现,同时也阻碍了对报告结果的验证。
- 由于只发布最终模型权重,导致开放式合作受阻,限制了对新能力或训练数据对 LLM 行为影响的研究。
展望未来,LLM360 承诺发布更大、更强大的模型,同时保持开源原则。该倡议为持续的研究合作和方法发展铺平了道路,旨在解决更好的训练数据混合、过滤技术和优化策略。文章最后承诺了 LLM360 愿景的承诺,即推动 LLMs 预训练领域的复杂性和开放性,同时承认了对负责任使用、风险管理和社区参与的需求。
三、总结
文章要点总结:
所有细节全开源,这种项目就是 🐂🍺
LLM360 是一个全面开源的 LLM 倡议,旨在向社区提供与 LLM 训练相关的一切,包括训练数据、代码和配置、模型检查点以及性能指标等。推动开放和协作式的人工智能研究的发展。
LLM360 的框架包括训练数据集和数据处理代码、训练代码、超参数与配置、模型检查点以及性能指标。透明化 LLM 模型的训练过程,有助于复现和深入研究。
LLM360 发布了两个从头开始预训练的大型语言模型:AMBER 和 CRYSTALCODER。AMBER 是基于1.3T tokens 进行预训练的 7B 英语语言模型,CRYSTALCODER 是基于 1.4T token 预训练的 7B 英语和代码语言模型。
AMBER 和 CRYSTALCODER 在多个基准数据集上评估,结果显示它们在语言任务和代码任务之间取得了很好的平衡,性能相对较强。
LLM360 提供了 ANALYSIS360 项目,用于对模型行为进行多方面分析。研究者对 LLM 中的记忆化进行了初步研究,并发布了所有检查点和数据,以便进行全面分析。
LLM360 的目标是透明化 LLM 的训练过程,使每个人都能复现和深入研究。提供训练数据、代码和配置、模型检查点以及性能指标等信息,促进了开放和协作式的人工智能研究的发展。
AMBER 和 CRYSTALCODER 是 LLM360 倡议的两个开源模型,它们在预训练过程中保存了大量的模型检查点,并在多个基准数据集上展现了良好的性能,推动了 LLMs 研究的进步。
📚? 参考链接:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!