MySQL之四大引擎、账号管理以及建库认识
目录
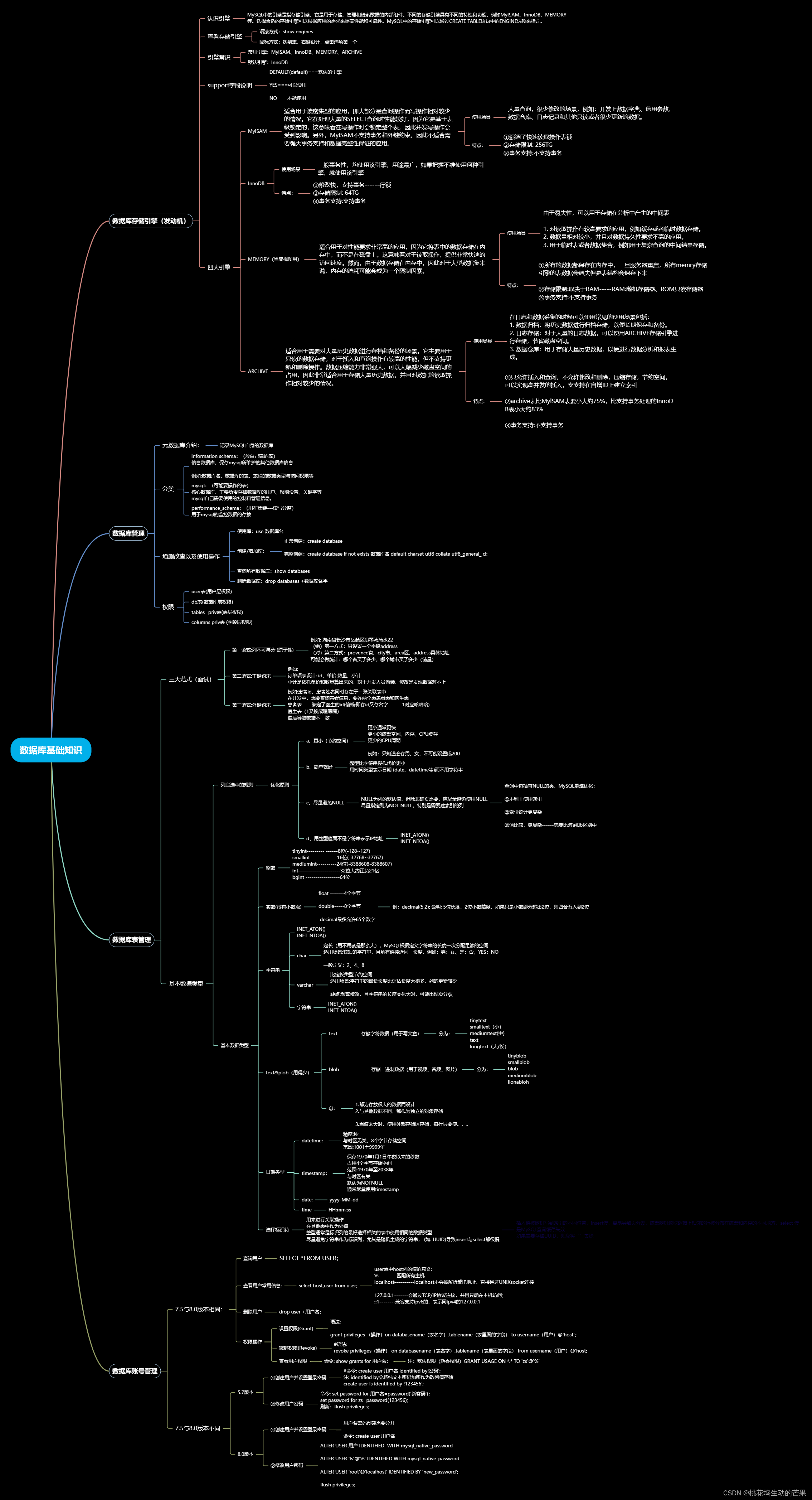
一、数据库存储引擎(发动机)
1.1、认识引擎
MySQL中的引擎是指存储引擎,它是用于存储、管理和检索数据的内部组件。不同的存储引擎具有不同的特性和功能,例如MyISAM、InnoDB、MEMORY等。选择合适的存储引擎可以根据应用的需求来提高性能和可靠性。MySQL中的存储引擎可以通过CREATE TABLE语句中的ENGINE选项来指定。
1.2、查看存储引擎
语法方式:show engines
鼠标方式:找到表,右键设计,点击选项第一个
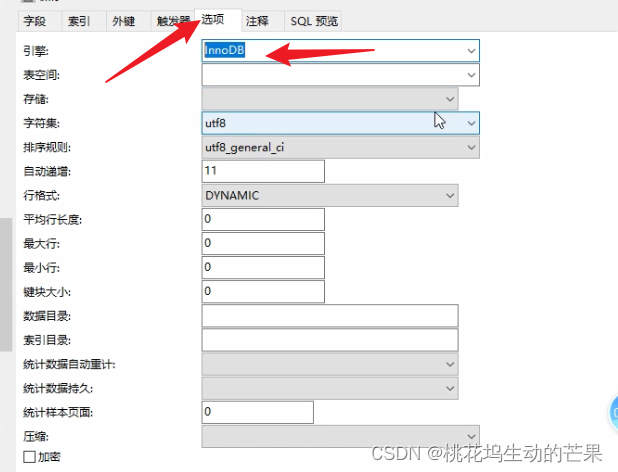
1.3、引擎常识
常用引擎:MyISAM、InnoDB、MEMORY、ARCHIVE
默认引擎:InnoDB

1.4、support字段说明?
DEFAULT(default)===默认的引擎
YES===可以使用
NO===不能使用
1.5、四大引擎
- MyISAM
适合用于读密集型的应用,即大部分是查询操作而写操作相对较少的情况。它在处理大量的SELECT查询时性能较好,因为它是基于表级锁定的,这意味着在写操作时会锁定整个表,因此并发写操作会受到影响。另外,MyISAM不支持事务和外键约束,因此不适合需要强大事务支持和数据完整性保证的应用。
使用场景:大量查询,很少修改的场景,例如:开发上数据字典、信用参数、数据仓库、日志记录和其他只读或者很少更新的数据。
特点:
①强调了快速读取操作表锁
②存储限制: 256TG
③事务支持:不支持事务
- InnoDB
使用场景:
一般事务性,均使用该引擎,用途最广,如果把握不准使用何种引擎,就使用该引擎
特点:
①修改快,支持事务------行锁
②存储限制: 64TG
③事务支持:支持事务
- MEMORY(当成视图用)
适合用于对性能要求非常高的应用,因为它将表中的数据存储在内存中,而不是在磁盘上。这意味着对于读取操作,提供非常快速的访问速度。然而,由于数据存储在内存中,因此对于大型数据集来说,内存的消耗可能会成为一个限制因素。
使用场景:由于易失性,可以用于存储在分析中产生的中间表
1. 对读取操作有较高要求的应用,例如缓存或者临时数据存储。
2. 数据量相对较小,并且对数据持久性要求不高的应用。
3. 用于临时表或者数据集合,例如用于复杂查询的中间结果存储。
特点
①所有的数据都保存在内存中,一旦服务器重启,所有memry存储引擎的表数据会消失但是表结构会保存下来②存储限制:取决于RAM-----RAM:随机存储器、ROM只读存储器
③事务支持:不支持事务
- ARCHIVE
适合用于需要对大量历史数据进行存档和备份的场景。它主要用于只读的数据存储,对于插入和查询操作有较高的性能,但不支持更新和删除操作。数据压缩能力非常强大,可以大幅减少磁盘空间的占用,因此非常适合用于存储大量历史数据,并且对数据的读取操作相对较少的情况。
使用场景:在日志和数据采集的时候可以使用?
常见的使用场景包括:
1. 数据归档:将历史数据进行归档存储,以便长期保存和备份。
2. 日志存储:对于大量的日志数据,可以使用ARCHIVE存储引擎进行存储,节省磁盘空间。
3. 数据仓库:用于存储大量历史数据,以便进行数据分析和报表生成。
特点:
①只允许插入和查询,不允许修改和删除,压缩存储,节约空间,可以实现高并发的插入,支支持在自增ID上建立索引②archive表比MylSAM表要小大约75%,比支持事务处理的InnoDB表小大约83%
③事务支持:不支持事务
二、数据库管理
2.1、元数据库介绍:
记录MySQL自身的数据库
2.2、分类:
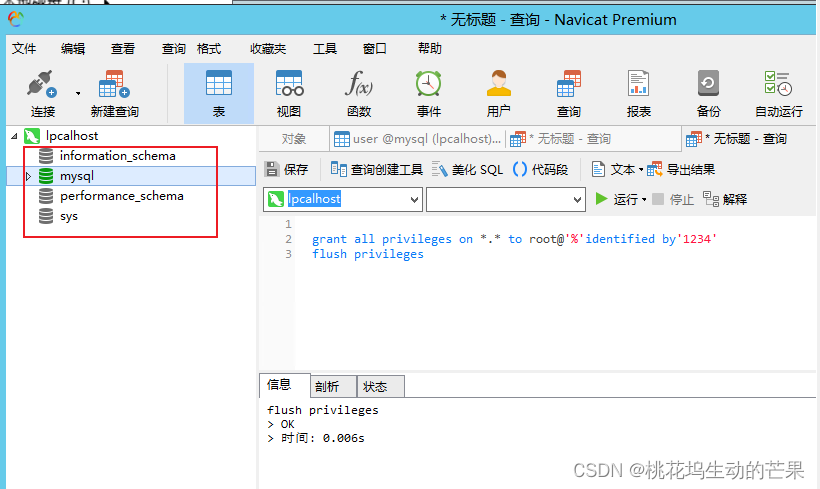
默认数据库:3个
information schema:(放自己建的库)
信息数据库,保存mysql所维护的其他数据库信息
例如:数据库名,数据库的表,表栏的数据类型与访问权限等
mysql:(可能要操作的表)
核心数据库,主要负责存储数据库的用户、权限设置、关键字等
mysql自己需要使用的控制和管理信息。
performance_schema:(用在集群---读写分离)
用于mysql的监控数据的存放
2.3、增删改查以及使用操作
使用库:use 数据库名
创建/增加库:
正常创建:create database
完整创建:create database if not exists 数据库名 default charset utf8 collate utf8_general_ ci;
utf8_general_ ci:设置字符编码以及不区分大小写
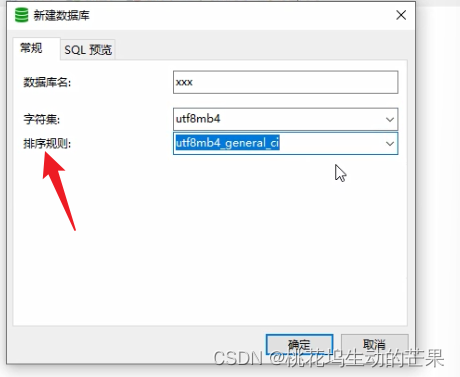
鼠标创建:右键

查询所有数据库:show databases
删除数据库:drop databases +数据库名字
2.4、权限
先看用户用那些权限

1、user表(用户层权限)
2、db表(数据库层权限)
3、tables _priv表(表层权限)
4、columns priv表 (字段层权限)?
三、数据库表管理
3.1、三大范式(面试)
第一范式:列不可再分 (原子性)
例如: 湖南省长沙市岳麓区浪琴湾清水2
(错)第一方式:只设置一个字段address
(对)第二方式:provence省、city市、area区、address具体地址可能会做统计:哪个省买了多少,哪个城市买了多少(销量)
第二范式:主键约束
例如:
订单项表设计: id、单价 数量、小计
小计是依托单价和数量算出来的,对于开发人员偷懒,修改是发现数据对不上
第三范式:外键约束
例如:患者id、患者姓名同时存在于一张关联表中
在开发中,想要查询患者信息,要连两个表患者表和医生表
患者表-----绑定了医生的id(偷懒:即存id又存名字-------1对应哈哈哈)?
医生表(1又换成嘿嘿嘿)
最后导致数据不一致
3.2、基本数据类型
1、列段选中的规则------优化原则
a、更小(节约空间)
更小通常更快
更小的磁盘空间、内存、CPU缓存
更少的CPU周期
例如:只知道会存男、女,不可能设置成200
b、简单就好
整型比字符串操作代价更小
用时间类型表示日期 (date、datetime等)而不用字符串
c、尽量避免NULL
NULL为列的默认值,但除非确实需要,应尽量避免使用NULL
尽量指定列为NOT NULL,特别是需要建索引的列
查询中包括有NULL的类,MySQL更难优化:
①不利于使用索引
②索引统计更复杂
③值比较,更复杂------想要比对a和b区别中
d、用整型值而不是字符串表示IP地址
INET_ATON()
INET_NTOA()
3.3、基本数据类型
整数
tinyint--------- ------8位(-128~127)
smallint--------- ----16位(-32768~32767)
mediumint----------24位(-8388608-8388607)
int---------------------32位大约正负21亿
bgint -----------------64位
实数(带有小数点)
float -------4个字节
double-----8个字节
?decimal最多允许65个数字
?
例:decimal(5.2); 说明: 5位长度,2位小数精度,如果只是小数部分超出2位,则四舍五入到2位
字符串
char
定长(用不用就是那么大),MySQL根据定义字符串的长度一次分配足够的空间
适用场景:较短的字符串,且所有值接近同一长度,例如:男:女、是:否、YES:NO
一般定义:2、4、8
varchar
比定长类型节约空间
适用场景:字符串的最长长度比评估长度大很多,列的更新较少
缺点:频繁修改,且字符串的长度变化大时,可能出现页分裂
?
text&plob(用得少)
text------------存储字符数据(用于写文章)
分为:
tinytext
smalltext(小)
mediumtext(中)
text
longtext(大/长)
blob----------------存储二进制数据(用于视频、音频、图片)
分为:
tinyblob
smallblob
blob
mediumblob
Ilonabloh
总:
1.都为存放很大的数据而设计
2.与其他数据不同,都作为独立的对象存储3.当值太大时,使用外部存储区存储,每行只要使。。。
?
日期类型
datetime:
精度:秒
与时区无关,8个字节存储空间
范围:1001至9999年
timestamp:
保存1970年1月1日午夜以来的秒数
占用4个字节存储空间
范围:1970年至2038年
与时区有关
默认为NOTNULL
通常尽量使用timestamp?
date:yyyy-MM-dd
time:HH:mm:ss
选择标识符
- 用来进行关联操作
- 在其他表中作为外键
- 整型通常是标识列的最好选择
注:区别:虽然查出结果没有区别,但是第二个需要把字符串转成整形,速度慢

- 相关的表中使用相同的数据类型
- 尽量避免字符串作为标识列,尤其是随机生成的字符串, (如: UUID)导致insert与select都很慢
插入值被随机写到索引的不同位置,insert慢,容易导致页分裂,磁盘随机读取逻辑上相邻的行被分布在磁盘和内存的不同地方,select 慢
是MySQL查询缓存失效
如果需要存储UUID,则应将“”去除?
四、数据库账号管理
案例:
项目经理可以看见所有项目表
项目组长可以看见他那个项目的表
普通研发/测试/产品可以用他那个项目的表,同时没有建表删表
7.5与8.0版本相同:
4.1、查询用户:????????
SELECT *FROM USER;
4.2、查看用户常用信息:???
?????select host,user from user;
user表中host列的值的意义:
%---------匹配所有主机
localhost----------localhost不会被解析成IP地址,直接通过UNIXsocket连接127.0.0.1-------会通过TCP/IP协议连接,并且只能在本机访问;
::1--------兼容支持ipv6的,表示同ipv4的127.0.0.1
4.3、删除用户
drop user +用户名;
4.4、权限操作
设置权限(Grant)
语法:
grant privileges (操作)on databasename(表名字).tablename(表里面的字段) to username(用户)@'host';
db是一个库的名字 Zs是一个用户 db_xiaoli表
#给 Zs用户 赋予 数据库db xiaoli中的表t p1 user 查询权限
grant SELECT on db_xiaolit.t p1 user to zs@'%';
#给 Zs用户 赋予 数据库db xiaoli中的表t p1 user 修改权限
grant UPDATE on db_xiaolit p1 user to zs@'%';
#给 Zs用户 赋予 数据库db xiaoli中所有表 查询权限
grant SELECT on db_xiaoli.* to zs@'%';
#给 Zs用户 赋予 数据库db xiaoli中所有表 所有权限
grant ALL on db_xiaoli.* to zs@'%';
撒销权限(Revoke)
#语法:?
revoke privileges(操作) on databasename(表名字).tablename(表里面的字段) from username(用户)@'host;
#啥也不能回收,不会对GRANTALL PRIVILEGES ONdb xiaoli*TO zs @%有
revoke DELETE on db_xiaolit.t p1 user from zs@'%';
#可以回收GRANT SELECT,UPDATE ON 'db xiaoli'.'t_p1'user TO 'zs'@'%'
revoke all on db _xiaoli.t_p1_user from zs@%';
#可以回收
GRANT ALL PRIVILEGES ON db_xiaoli. TO zs @'%';
revoke all on db_xiaolit.* from zs@'%';
#注: revoke只能回收grants列表中更小的
?
查看用户权限
命令: show grants for 用户名;
show grants fro 'zs'@'%';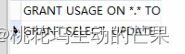
注:默认权限(游客权限)GRANT USAGE ON *.* TO 'zs'@'%'
7.5与8.0版本不同
5.7版本
①创建用户并设置登录密码
#命令: create user 用户名 identified by!密码';
注: identified by会将纯文本密码加密作为散列值存储
create user ls identified by !123456';
②修改用户密码
命令: set password for 用户名=password('新客码');
set password for zs=password(123456);
刷新:flush privileges;
8.0版本
①创建用户并设置登录密码
用户名密码创建需要分开
命令: create user 用户名
create user ls;②修改用户密码
ALTER USER 用户 IDENTIFIED? WITH mysql_native_password
ALTER USER 'Is'@'%' IDENTIFIED WITH mysql_native_password
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
flush privileges;?
五、思维导图总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!