从txt文档里筛选出每行重复数据字符,并保存到新的txt文档
2024-01-09 16:45:16
从txt文档里筛选出每行重复数据字符,并保存到新的txt文档
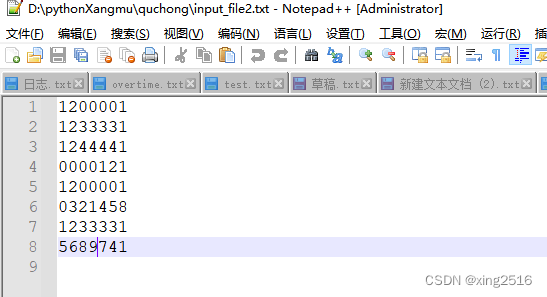
input_file = r'D:\pythonXangmu\quchong\input_file2.txt' #原始文档
#output_file = 'output.txt'#重复内容记录文档
output_file = r'D:\pythonXangmu\quchong\output2.txt'#绝对路径,解决报错找不到文件或文件夹
with open(input_file, 'r', encoding='utf-8') as file:
content = file.readlines()
print('content',content)
unique_lines = set()#存储唯一的行数据,是集合
duplicate_lines = []#存储重复的行,是列表
#筛选出每行重复的(多行中找)
for line in content:
if line in unique_lines:
duplicate_lines.append(line)
else:
unique_lines.add(line)
#筛选出行内 重复的数据 (单行中找重复)
result = []
for line in unique_lines:
current_char = None#表示当前的字符为空
count = 0#记录连续重复字符的数量
consecutive_duplicates = ""#用于存储连续重复的字符
for char in line:
if char == current_char:
count += 1
consecutive_duplicates += char
else:
if count > 1:
result.append(line) # 将整行添加到result列表中
current_char = char#将current_char更新为当前字符char,以便继续跟踪下一个字符
count = 1#将count重置为1,表示当前字符是一个新的字符序列的开始
consecutive_duplicates = char
print('unique_lines',unique_lines)
print("筛选出含重复字符",result)
with open(output_file, 'w', encoding='utf-8') as file:
for line in result:
file.write(line)#写入新文档
# for line2 in result:
# line2 =line2
# print('line2',line2)
#print('unique_lines',unique_lines)
#print('duplicate_lines',duplicate_lines)
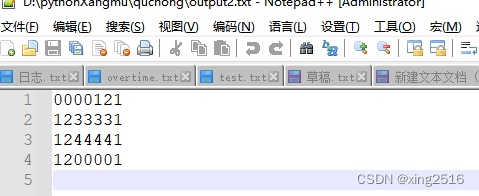
筛选后的txt文档
文章来源:https://blog.csdn.net/xing2516/article/details/135482523
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!