k8s---pod基础下
k8s的pod与docker重启策略的区别
k8s的重启策略
- always deployment的yaml文件只能是always,pod的yaml三种模式都可以。不论正常退出还是非正常退出都重启。
- OnFailure:正常退出不重启,非正常退出会重启
- Never:正常退出和非正常退出都不重启。容器退出了,pod才会重启
pod可以有多个容器,只要有一个容器退出,整个pod都会重启,所有pod内的容器都会重启。
docker的重启策略:
- docker的默认策略是nerver。
- on-failure:非正常退出时才会重启容器
- always:只要容器退出都重启。
- unless-stopped:只要容器退出就会重启,docker的守护进程启动时已经停止的容器,不再重启。
注意:yaml方式创建Deployment和StatefulSet类型时,restartPolicy只能是Always,kubectl run -个pod可以选择Always,OnFailure,Never三种策略
如何快捷的生成yaml文件
生成模板
[root@master01 ~]# kubectl create deployment nginx1 --image=nginx:1.22 --replicas=3 --dry-run=client
deployment.apps/nginx1 created (dry run)
将模板输出到指定的位置
[root@master01 opt]# kubectl create deployment nginx1 --image=nginx:1.22 --replicas=3 --dry-run=client -o yaml > /opt/test1.yaml模板:

pod的生命周期状态
1.pending 挂起。
pod已被创建,但是尚未被分配到运行的node节点。
原因:节点的资源不够,需要等待其他pod的调度。
2.running
运行中pod已经被分配到了node节点,pod内部的所有容器都已经启动,运行状态正常,稳定。
3.complete / successded
表示容器内部的进程运行完毕,正常退出,没有发生错误。
4.failed:
pod中的容器非正常退出。发生了错误,需要通过查看详情和日志来定位问题。
5.UNknow:
因为某些原因,k8s集群无法获取pod的状态。APIserver出了问题。
6.terminating :
终止中,pod正在被删除,里面的容器正在终止。种植过程中,资源回收,垃圾清理,以及终止过程中需要执行的命令。
7.crashloopbackoff:
pod当中的容器退出,kubelect正在重启
8.imagepullbackoff:正在重试拉取镜像
原因:指定仓库错误
9.errimagepull:
拉取镜像出错
原因:1.网速太慢,超时了 ?2.镜像名写错 ?3.镜像仓库挂了
10.Evicte:pod被驱赶了
原因:node节点的资源不够部署pod。资源不足,kubelect自动选择一个pod驱逐
CrashLoopBackOff: 容器退出,kubelet正在将它重启
InvalidImageName: 无法解析镜像名称
ImageInspectError: 无法校验镜像
ErrImageNeverPull: 策略禁止拉取镜像
ImagePullBackOff: 正在重试拉取
RegistryUnavailable: 连接不到镜像中心
ErrImagePull: 通用的拉取镜像出错
CreateContainerConfigError: 不能创建kubelet使用的容器配置
CreateContainerError: 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError: 启动容器失败
PostStartHookError: 执行hook报错
ContainersNotInitialized: 容器没有初始化完毕
ContainersNotReady: 容器没有准备完毕
ContainerCreating: 容器创建中
PodInitializing:pod 初始化中
DockerDaemonNotReady: docker还没有完全启动
NetworkPluginNotReady: 网络插件还没有完全启动
Evicte: pod被驱赶pod容器使用节点资源限制
在我前面Docker的Cgroup文章中,就提到过,为什么我们对容器进行资源限制。同理:首先K8s中pod使用宿主机的资源默认情况下是无节制的,但是当一个集群搭建成功后并投入生产环境中。如果其中的某一个pod因为不明原因出现了bug,疯狂占用宿主机资源,抢占其他pod的资源。势必会导致整个集群的瘫痪,所以pod资源的限制是非常有必要的
?在资源控制器中我们也可以准确的找到相应的资源控制字段:
?
kubectl explain deployment.spec.template.spec.containers.resources
kubectl explain statefulset.spec.template.spec.containers.resources
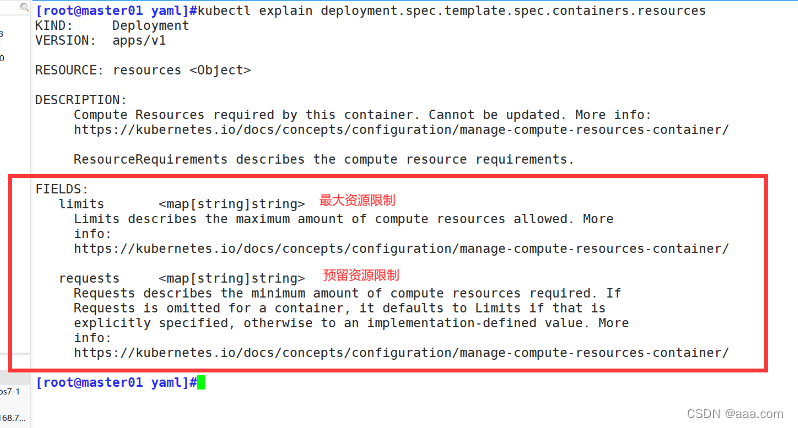
pod容器资源的限制
1.request:pod内容器需要的资源
2.limit:最高能占用系统多少资源
limit需要多少,最多也只能占用这么多pod容器的对cpu的限制:
pod容器对cpu有两种方法限制
?pod对于cpu限制的参数有两种表达形式:
第一种是指定个数的表达形式,例如:1 ,2, 0.5 ,0.2 ,0.3 指定cpu的个数(该个数可以为整数,也可以为小数点后一位的小数)
第二种是以毫核为单位的表达形式:100m ?500m ? 1000m ? 2000m (这里1000m等价于一个cpu,该方式来自于cpu时间分片原理得来)?
?
memory的表达形式?
pod对内存参数的要求十分严谨。对硬件有过研究的朋友,应该会了解到,我们常常提到的GB,MB,TB其实是于实际字节总数是有误差的(原因是GB是以10为底数计量,而真正的换算是以2为底数计量。导致了总量的误差。)而真正没有此误差的单位是Ki ?Mi ?Gi ?Ti?
所以k8s中pod资源限制为了对pod的内存限制更为精准,采用的单位是 Ki ?Mi ?Gi ?Ti?
?
实例运用
需求:创建一个deployment资源,镜像使用centos:7。副本数一个。容器资源预留256MB,cpu0.5个。最多1GB,1个cpu
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: centos
name: centos
spec:
replicas: 1
selector:
matchLabels:
app: centos
template:
metadata:
labels:
app: centos
spec:
containers:
- image: centos:7
name: centos
command: ["/bin/bash","-c","sleep 3600"]
#容器的持久化命令
resources:
requests:
memory: "256Mi"
cpu: "0.5"
limits:
memory: "1Gi"
cpu: "1"
wq
kubectl describe pod centos

下面进行压力测试
yum -y install epel-release
yum -y install stress
stress --vm 1 --vm-bytes 512M
压力测试
[root@centos-847ddb86c-dhn44 /]# stress --vm 1 --vm-bytes 1G
stress: info: [89] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: FAIL: [89] (415) <-- worker 90 got signal 9
stress: WARN: [89] (417) now reaping child worker processes
stress: FAIL: [89] (451) failed run completed in 1s
超过限制直接杀死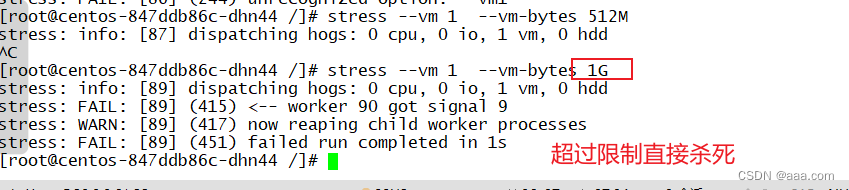
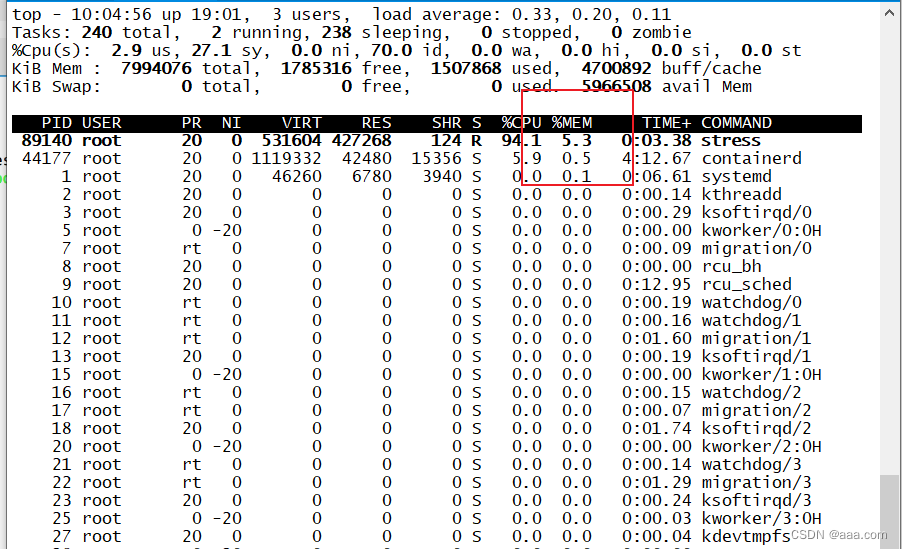
由此可见:
在创建pod时,一定要给容器做资源限制!!!
k8s当中怎么设置拉取镜像的策略
?首先在资源式声明中存在着imagePullPolicy的字段,它的value决定着k8s创建容器时拉取镜像的方式策略。【此字段所在位置也说明了在声明式yaml中,imagePullPolicy是包含containers中】
kubectl explain pod.spec.containers.imagePullPolicy

如图所示,这三种便是k8s拉取镜像的三种策略:
IfNotPresent
只有当镜像在本地不存在时才会拉取。(先对本地进行排查,本地有该镜像直接使用,本地没有该镜像则选择在仓库中拉取)
如果本地镜像有,就不再拉取,本地没有才会去镜像仓库拉取
Always
总是从仓库拉取镜像,无论本地是否存在镜像(即使本地中存在我们所指定的相关镜像,该策略也会先从仓库中拉取进行应用)
不论镜像是否存在,创建时(重启)都会重新拉取镜像
Never
Kubelet 不会尝试获取镜像。如果镜像已经以某种方式存在本地, kubelet 会尝试启动容器;否则,会启动失败。(如果本地不存在,并不会在仓库中拉取,直接报错)
仅仅使用本地镜像,本地没有也不会主动拉取
k8s设置镜像拉取策略命令:
imagePullPolicy: Always / Nerver / IfNotPresent实验演示:


总结:
都是本地部署:never
如果涉及到外部部署:默认策略(事前要把docker镜像导入目标主机,否则会去官网去拉)
Always:一般不用
pod的容器健康检查
1.?探针的概念及其作用?
?探针是由 kubelet 对容器执行的定期诊断(pod中探针又分为三类):
?存活探针(livenessProbe)探测容器是否运行正常。如果探测失败则kubelet杀掉容器(不是Pod),容器会根据重启策略决定是否重启
就绪探针(readinessProbe)探测Pod是否能够进入READY状态,并做好接收请求的准备。如果探测失败Pod则会进入NOTREADY状态(READY为0/1)并且从所关联的service资源的端点(endpoints)中踢出,service将不会再把访问请求转发给这个Pod
启动探针(startupProbe)探测容器内的应用是否启动成功,在启动探针探测成功之前,其它类型的探针都会暂时处于禁用状态?
?
?注意:启动探针只是在容器启动后按照配置满足一次后就不再进行后续的探测了。存活探针和就绪探针会一直探测到Pod生命周期结束为止
kubectl explain pod.spec.containers
probe的检测方法
1.exec探针:在容器内部执行命令,如果命令的返回码是0,表示成功。
适用于需要在容器内自定义命令来检查容器的健康情况
2.httpGet:
对指定IP+port的容器发送一个httpGet的请求。响应状态码大于等于200,小于400都是成功。
x=[200,400)? ?(这里用数学集合的方式表示,更容易理解)
适用于检查容器能否响应http的请求,web容器(nginx,tomcat)
3.tcpSocket
端口:对指定端口上的容器的IP地址进行tcp检查(三次握手),端口打开,认为探测成功。
检查特点容器的端口监听状态。
exec:查看容器指定的配置文件有没有生成
httpGet,tcpSocket:主要是对外部容器的检测
探针字段
initialDelaySeconds: 3
表示容器启动之后多少秒来进行探测,时间不要设置的太短,可能会导致无效探测。?
periodSeconds: 2
表示探针探测的间隔时间。每隔多少秒进行一次检查。应用的延迟敏感度,这个应用非常重要,>核心组件
failureThreshold: 2
表示如果探测失败,失败几次之后把容器标记为不健康
successThreshold: 1
只要成功一次就标记为就绪,健康,ready
timeoutSecond:
表示每次探测的超时时间,在多少秒内必须完成探测
用exec方式探测
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: centos
name: centos
spec:
replicas: 1
selector:
matchLabels:
app: centos
template:
metadata:
labels:
app: centos
spec:
containers:
- image: centos:7
name: centos
command: ["/bin/bash","-c","touch /opt/123.txt ; sleep 3600"]
livenessProbe:
exec:
command: ["/usr/bin/test","-e","/opt/123.txt"]
initialDelaySeconds: 3
#表示容器启动之后多少秒来进行探测,时间不要设置的太短,可能会导致无效探测。
periodSeconds: 2
#表示探针探测的间隔时间。每隔多少秒进行一次检查。应用的延迟敏感度,这个应用非常重要,>核心组件
failureThreshold: 2
#表示如果探测失败,失败几次之后把容器标记为不健康
successThreshold: 1
#只要成功一次就标记为就绪,健康,ready
timeoutSecond:
#表示每次探测的超时时间,在多少秒内必须完成探测
kubectl apply -f test1.yaml
kubectl exec -it centos-797bc57596-jkdfw -- rm -rf /opt/123.txt

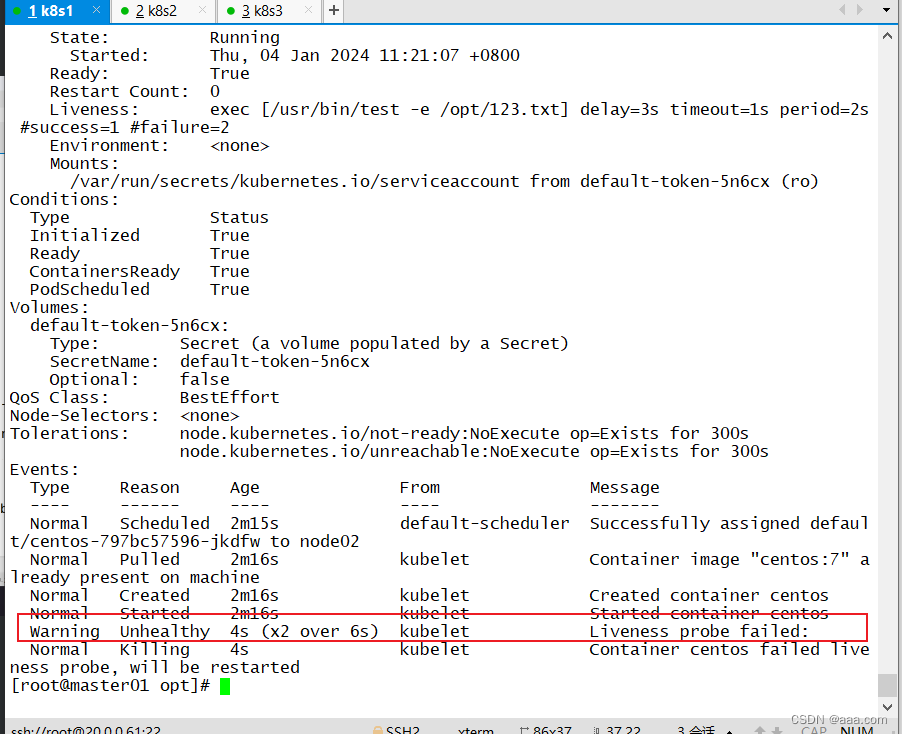
脚本所示,通过exec将返回值写入/opt/123.txt中。若进容器将/opt/123.txt删除,则容器会重启,最多重启三次。(如上图所示)
此时若再将文件创建,容器就可以正常运行
kubectl exec -it centos-797bc57596-jkdfw -- touch /opt/123.txt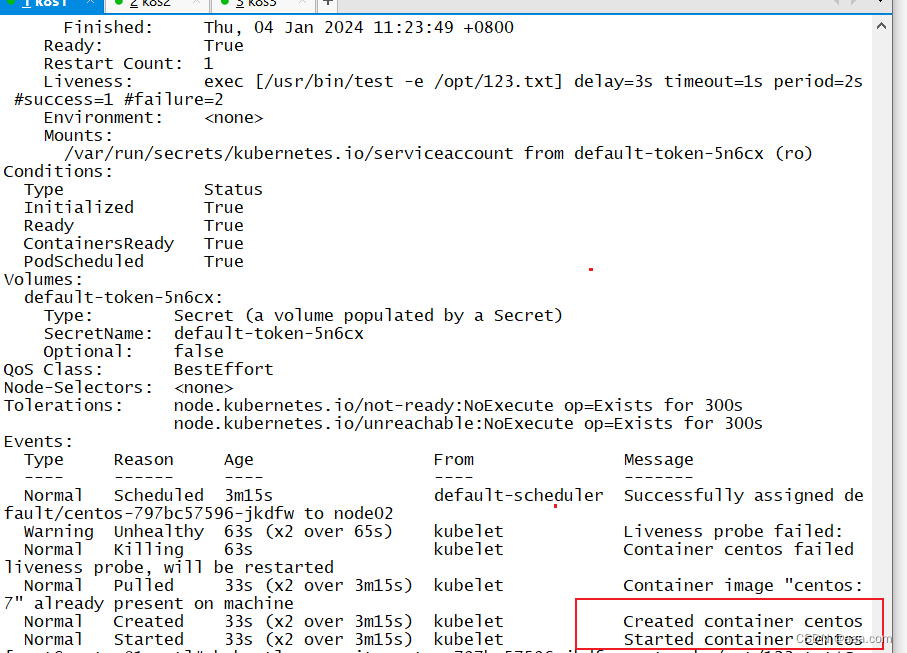
HTTP方法测试
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: tomcat:8.0.52
name: nginx1
livenessProbe:
httpGet:
port: 8080
path: /index.html
initialDelaySeconds: 4
periodSeconds: 2
我们修改回来
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: tomcat:8.0.52
name: nginx1
livenessProbe:
httpGet:
port: 8080
path: /index.jsp
initialDelaySeconds: 4
periodSeconds: 2
成功运行。
下面来对tomcat的页面进行访问:
kubectl get pod -o wide
查看IP
curl 10.244.2.21:8080/index.jsp
tcpSocket检测
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: tomcat:8.0.52
name: nginx1
livenessProbe:
tcpSocket:
port: 8081
initialDelaySeconds: 4
periodSeconds: 2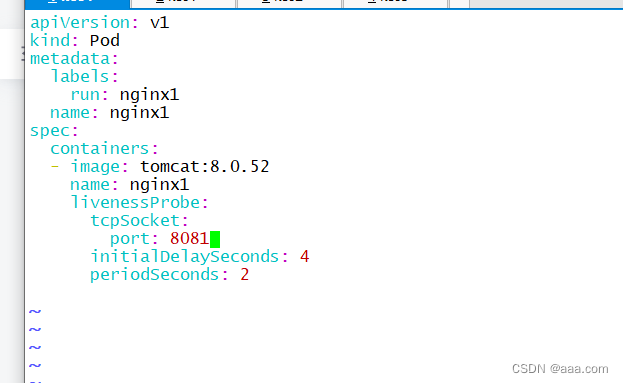

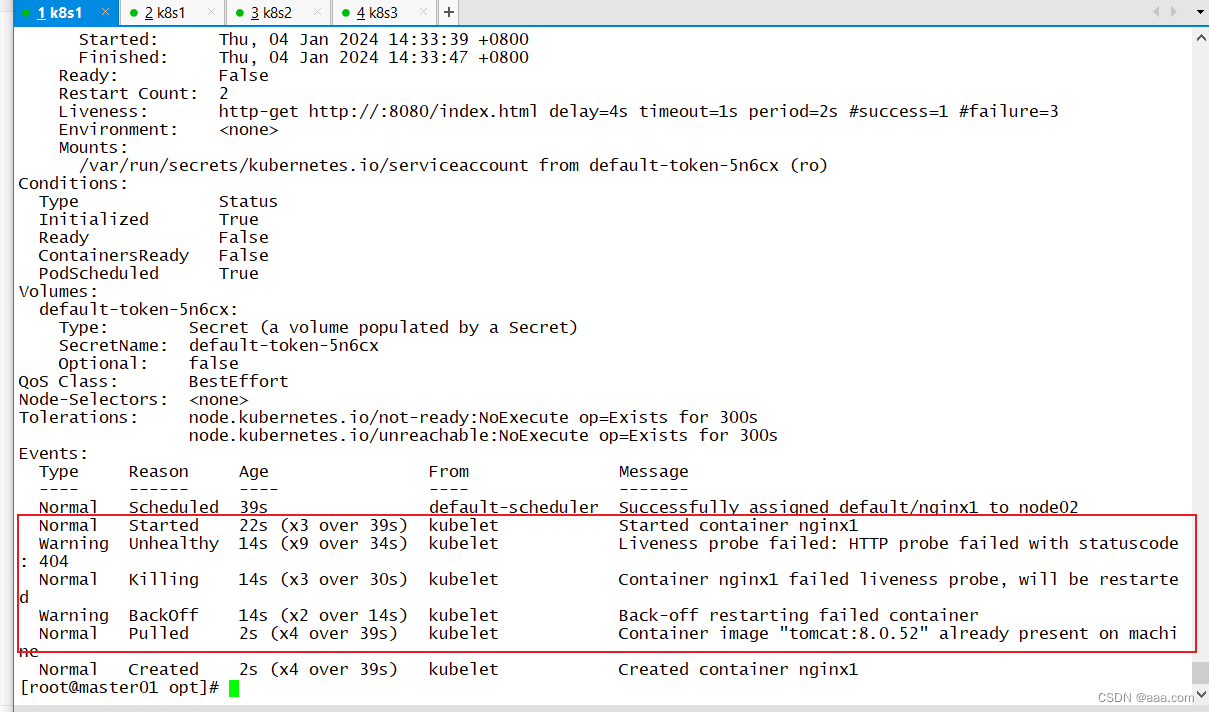
如图所示,我给tomcat一个错误的端口8081,容器无法启动

修改为正确端口:8080
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: tomcat:8.0.52
name: nginx1
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 4
periodSeconds: 2


成功启动运行
强制删除会导致资源残留,不建议经常适用

总结:
总结:
探针的三个方法:
存活探针:检测失败后,会杀死容器然后重启
探针将伴随整个容器的生命周期
exec:相当于执行了一个shell命令,容器里面执行
shell命令执行成功:
返回码是0,表示成功。
只要成功一次就是探测成功
httpGet:对外部容器发起了一次get请求,可以添加path指定访问的资源。返回码在[200,400)范围之内都算成功。
tcpSocket:相当于telnet,指定的容器监听端口是否能打开。是否能和指定的容器监听端口进行通信
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!