ShardingSphere数据分片之读写分离
1、概述
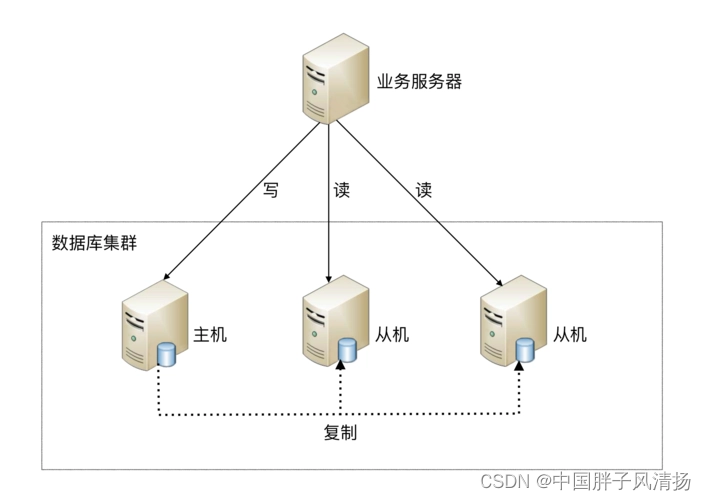
读写分离是一种常见的数据库架构,它将数据库分为主从库,一个主库(Master)用于写数据,多个从库(Slave)进行轮询读取数据的过程。主从库之间通过某种通讯机制进行数据的同步。
所以,数据的读写分离是在数据库的主从复制基础上建立起来的。
数据库的主从复制可以参考之前的文章:Mysql8.0实现主从复制。
读写分离的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。这样可以有效地减轻主数据库的压力,提高数据库的并发性能和稳定性。
2、优缺点
优点:
- 减轻数据库压力:通过将读操作和写操作分开到不同的数据库服务器上,可以有效地减轻主数据库的压力,提高数据库的并发性能和稳定性。
- 提高性能:只读服务器没有写操作,可以大大减轻磁盘IO等性能问题,提高查询效率。同时,读服务器可以采用负载均衡,实现读操作的可伸缩性。
- 易于扩展:读写分离可以很容易地扩展到更多的数据库服务器上,以满足不断增长的业务需求。
缺点:
- 数据实时性差:数据不是实时同步到只读服务器上的,当数据写入主服务器后,要在下次同步后才能查询到。这可能导致数据不一致的问题。
- 数据量大时同步效率差:单表数据量过大时插入和更新因索引、磁盘IO等问题,性能会变的很差。这可能影响到只读服务器的性能和稳定性。
- 连接多个数据库:至少要连接到两个数据库,实际的读写操作是在程序代码中完成的,容易引起混乱。这增加了开发和维护的复杂性。
3、SpringBoot整合实现
使用SpringBoot对ShardingSphere的基本整合可以浏览之前的文章:
ShardingSphere数据分片之分表操作。
因为是SpringBoot整合ShardingSphere,所以我们只需要配置Yaml文件便可以轻松的实现数据库的读写分离。
3.1、引入依赖
CSDN上很多博客都使用的是sharding-jdbc-spring-boot-starter依赖,但是这个依赖是很久以前的了,在需求日益增长的现在,还是要紧跟时代比较好,所以我就用了离现在不是很久的依赖。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
3.2、配置YAML文件
这里结合了读写分离 + 分表的操作,所以YAML文件的配置就比较多。
spring:
shardingsphere:
props:
sql-show: true # 展示shardingSphere对SQL的处理
datasource: # 配置真实的数据源
master: # 主数据库
username: root
password: 123456
url: jdbc:mysql://wangwu_mysql:3306/mysql_test?serverTimezone=Asia/Shanghai # zhoujn.e3.luyouxia.net:11580
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
slave: # 从数据库
username: root
password: 123456
url: jdbc:mysql://zhangsan_mysql:3306/mysql_test?serverTimezone=Asia/Shanghai
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
names: master
rules: # 配置路由规则
readwrite-splitting: # 配置读写分离
data-sources: # 读写分离数据库配置
read-write-datasource: # 自定义读写分离数据库配置名称
type: Static # 静态配置,配置的选项来自同一个YAML文件的datasource参数
props:
write-data-source-name: master # 写库的配置
read-data-source-names: slave # 读库的配置,多个从库之间使用逗号进行隔开
load-balancer-name: round-robin # 多个读库之间采用的访问策略
load-balancers: # 访问策略的配置
round-robin: # 自
定义策略名称
type: ROUND_ROBIN # 明确的策略
sharding: # 数据分片配置
sharding-algorithms: # 数据分片算法配置
table-inline:
type: INLINE
props:
algorithm-expression: test_$->{id % 2}
tables: # 表的分片配置
logic_table_name:
actual-data-nodes: read-write-datasource.test_${0..1}
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: table-inline
mode:
type: Memory
repository:
type: JDBC
load-balancers.type从库访问策略可以是以下的值:
| 参数名称 | 描述 |
|---|---|
| ROUND_ROBIN | 轮询负载均衡器。按照顺序依次将请求分配给每个分片,当所有分片都处理完后再从头开始分配。 |
| LEAST_ACTIVE | 最少活跃调用负载均衡器。选择当前活跃请求数最少的分片作为目标分片。 |
| LEAST_CONNECTION | 最少连接负载均衡器。选择当前连接数最少的分片作为目标分片。 |
| RANDOM | 随机负载均衡器。随机选择一个分片作为目标分片。 |
| LEAST_RESPONSE_TIME | 最少响应时间负载均衡器。选择当前响应时间最少的分片作为目标分片。 |
注意点:
在使用读写分离时,actual-data-nodes参数所对应的真是表的名称不再是Master或者Slave,而是rules.readwrite-splitting.data-sources下自定义是读写分离数据库的名称。
否则读写分离不会成功。
其他的分库分表参数请浏览:ShardingSphere数据分片之分表操作。
3.3、代码层面
整合了ShardingSphere后代码层面还是和日常的编写方式一样就可以了。
3.3.1、controller
@RestController
@RequiredArgsConstructor
public class shardingController {
private final TestServiceImpl testService;
@GetMapping(value = "/add")
public String addData(){
for(int i = 1; i <= 10; i++){
// 此处的操作一定是在Master库中执行的
testService.save(new Test().setTestName("data_" + i).setId(i));
}
return "插入完成";
}
@GetMapping(value = "/list")
public List<Test> list(){
// 此处的操作一定是在Slave库中执行
return testService.list();
}
}
3.3.2、service
@Service
public class TestServiceImpl extends ServiceImpl<TestMapper, Test> implements IService<Test> {
}
3.3.3、mapper
@Mapper
public interface TestMapper extends BaseMapper<Test> {
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!