U-Net: Convolutional Networks for Biomedical Image Segmentation(CVPR2015)

hh
源代码
Abstract
人们普遍认为,深度网络的成功训练需要成千上万个带注释的训练样本。在这篇论文中,我们提出了一个网络和训练策略,该策略依赖于数据增强的强大使用,以更有效地利用可用的注释样本。该体系结构包括捕获上下文的收缩路径和支持精确定位的对称扩展路径。我们表明,这样的网络可以从很少的图像中进行端到端训练,并且在ISBI挑战中优于先前的最佳方法(滑动窗口卷积网络),以分割电子显微镜堆栈中的神经元结构。
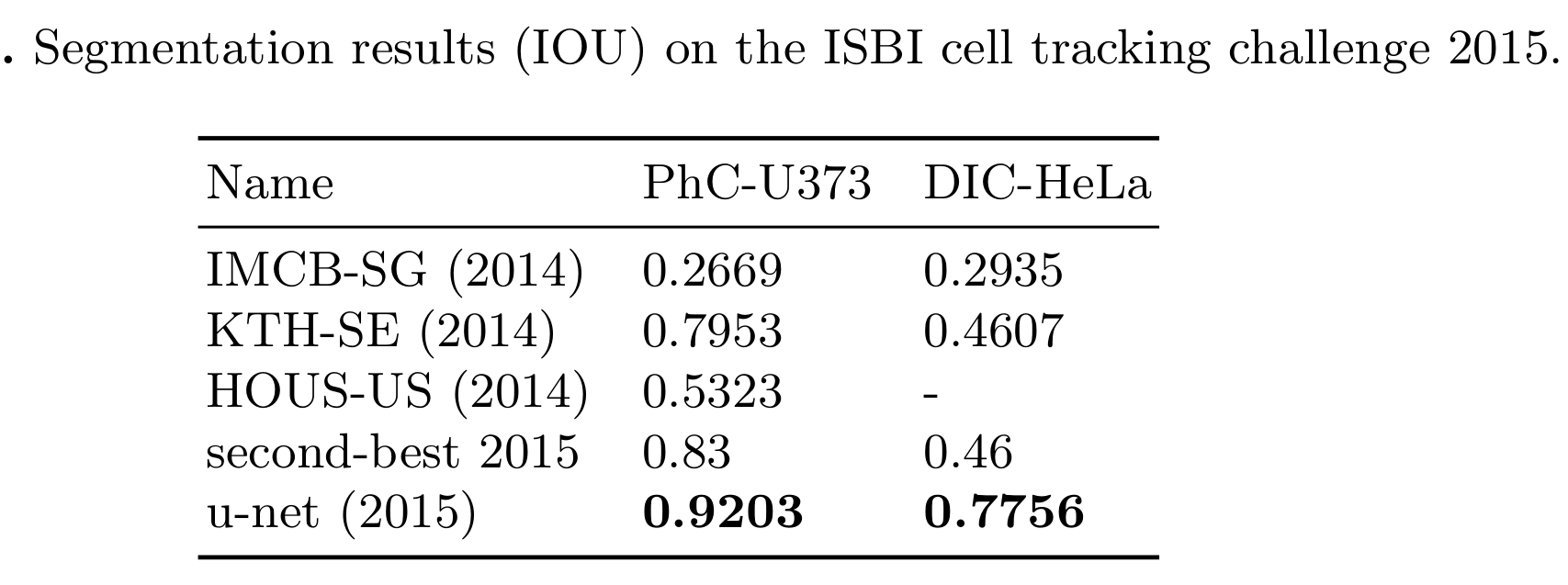
使用在透射光显微镜图像(相位对比和DIC)上训练的相同网络,我们在这些类别中以很大的优势赢得了2015年ISBI细胞跟踪挑战赛。此外,网络速度很快。在最新的GPU上,512x512图像的分割需要不到一秒的时间。
Introduction
在本文中,我们构建了一个更优雅的架构,即所谓的“全卷积网络”[9]。我们修改和扩展了这种架构,使其适用于很少的训练图像,并产生更精确的分割;参见图1。[9]中的主要思想是通过连续的层来补充通常的收缩网络,其中池化算子被上采样算子取代。因此,这些层增加了输出的分辨率。为了定位,从收缩路径的高分辨率特征与上采样输出相结合。然后,连续的卷积层可以根据这些信息学习组装更精确的输出。
我们架构中的一个重要修改是,在上采样部分,我们也有大量的特征通道,这允许网络将上下文信息传播到更高分辨率的层。因此,扩张路径或多或少与收缩路径对称,并产生u形架构。网络没有任何完全连接的层,只使用每个卷积的有效部分,即分割映射只包含像素,在输入图像中可以获得完整的上下文。该策略允许通过重叠贴图策略对任意大的图像进行无缝分割(见图2)。为了预测图像边界区域的像素,通过镜像输入图像来推断缺失的上下文。这种平铺策略对于将网络应用于大型图像非常重要,因为否则分辨率将受到GPU内存的限制。
为了实现输出分割映射的无缝平铺(参见图2),选择输入平铺大小是很重要的,这样所有2x2最大池化操作都应用于具有均匀x和y大小的层
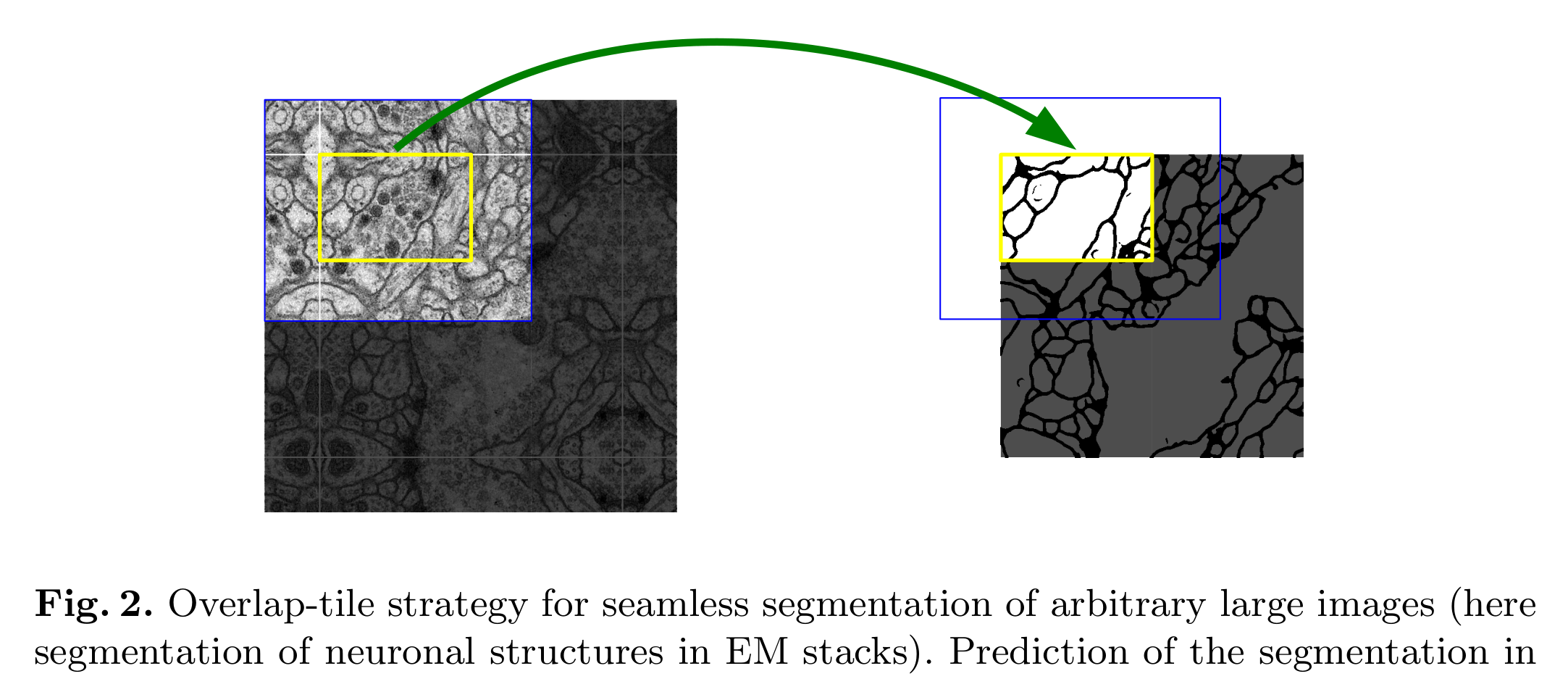
任意大图像无缝分割的重叠贴图策略(这里是EM堆栈中的神经元结构分割)。对黄色区域的分割进行预测,需要蓝色区域内的图像数据作为输入。通过镜像推断缺失的输入数据
对于我们的任务,可用的训练数据很少,我们通过对可用的训练图像应用弹性变形来使用过度的数据增强。这允许网络学习这种变形的不变性,而不需要在注释的图像语料库中看到这些转换。这在生物医学分割中尤其重要,因为变形曾经是组织中最常见的变化,并且可以有效地模拟真实的变形。Dosovitskiy等人[2]在无监督特征学习的范围内证明了数据增强对学习不变性的价值。
在许多细胞分割任务中的另一个挑战是同一类触摸物体的分离;参见图3。为此,我们建议使用加权损失,其中触摸单元之间的分离背景标签在损失函数中获得较大的权重。
(a)原始图像。(b)叠加与地面真值分割。不同的颜色表示海拉细胞的不同实例。?生成分割蒙版(白色:前景,黑色:背景)。(d)使用逐像素的损失权值来强迫网络学习边界像素。
Network Architecture
网络体系结构如图1所示。它包括一条收缩路径(左侧)和一条扩张路径(右侧)。
收缩路径遵循卷积网络的典型架构。它由两个3x3卷积(未填充卷积)的重复应用组成,每个卷积后面都有一个整流线性单元(ReLU)和一个2x2 max池化操作,步幅为2,用于下采样,在每个降采样步骤中,我们将特征通道的数量加倍。
扩展路径中的每一步都包括特征映射的上采样2x2卷积(“反卷积”),将特征通道的数量减半,与收缩路径中相应裁剪的特征映射进行连接,以及两个3x3卷积,每个卷积都有一个ReLU。由于在每次卷积中边界像素的损失,裁剪是必要的。在最后一层,使用1x1卷积将每个64个分量的特征向量映射到所需的类数,这个网络总共有23个卷积层。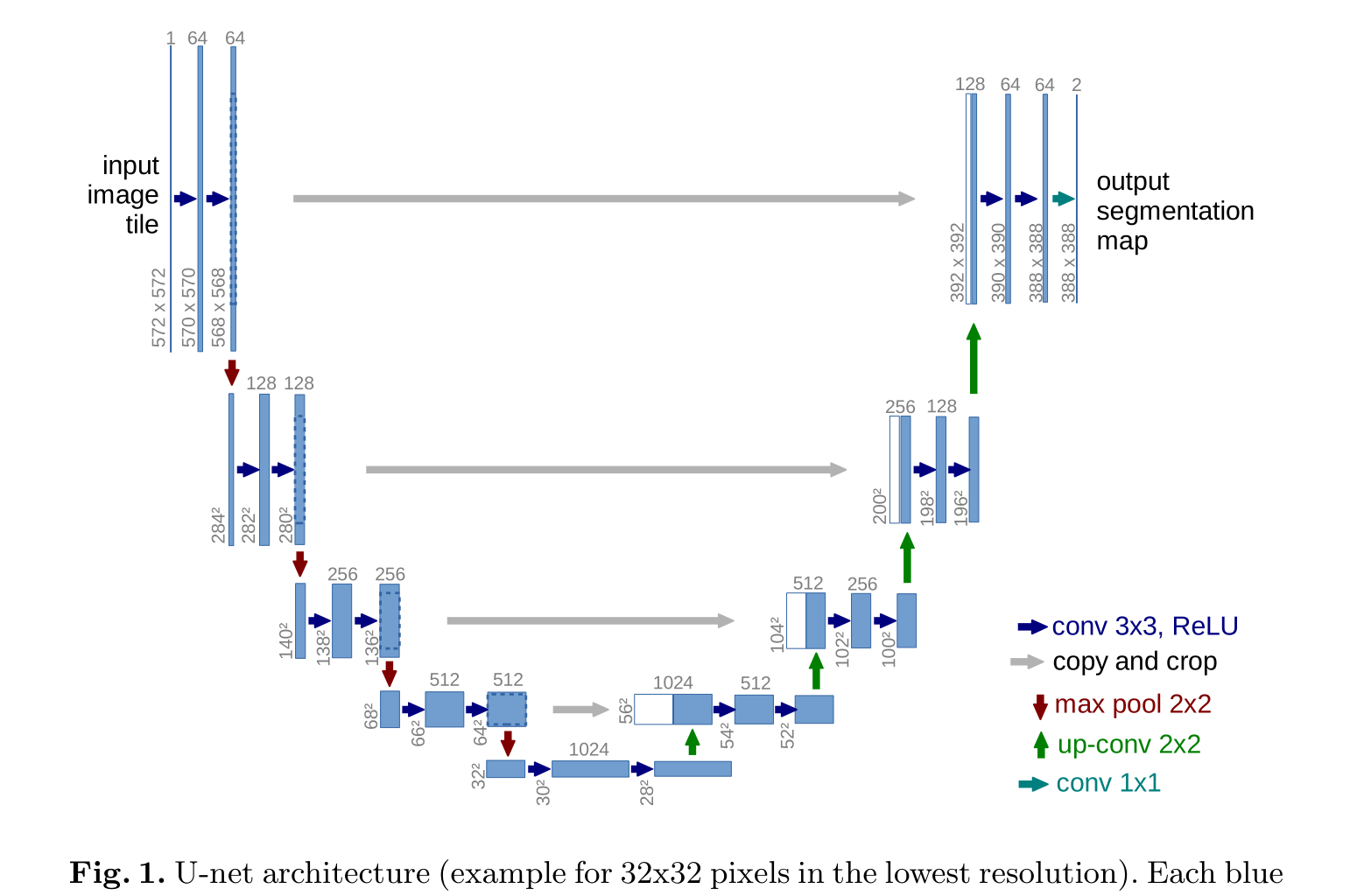
每个蓝框对应一个多通道特征图。通道的数量表示在盒子的顶部。x-y尺寸在框的左下边缘提供。白框表示复制的特征图。箭头表示不同的操作。
Conclusion
UNet的收缩路径(左侧)进行特征提取,并且随着网络层次的加深,感受野也会逐渐扩大,分辨率低、语义强获取的是图像整体性的特征,而浅层网络呢(分辨率高、语义弱)获取的是细粒度特征。
右侧进行反卷积上采样,但因为卷积进行的下采样会导致部分边缘信息的丢失,失去的特征并不能从上采样中找回,因此作者采用了特征拼接操作来弥补,后续FPN貌似是延用了这一思想,通过横向连接将低分辨率语义强的特征和高分辨率语义弱的特征结合起来
torch code
import torch
import torch.nn as nn
import torch.nn.functional as F
class double_conv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,strides=1,padding=1):
super(double_conv2d_bn,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,
kernel_size=kernel_size,
stride = strides,padding=padding,bias=True)
self.conv2 = nn.Conv2d(out_channels,out_channels,
kernel_size = kernel_size,
stride = strides,padding=padding,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
class deconv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=2,strides=2):
super(deconv2d_bn,self).__init__()
self.conv1 = nn.ConvTranspose2d(in_channels,out_channels,
kernel_size = kernel_size,
stride = strides,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
return out
class Unet(nn.Module):
def __init__(self):
super(Unet,self).__init__()
self.layer1_conv = double_conv2d_bn(1,8)
self.layer2_conv = double_conv2d_bn(8,16)
self.layer3_conv = double_conv2d_bn(16,32)
self.layer4_conv = double_conv2d_bn(32,64)
self.layer5_conv = double_conv2d_bn(64,128)
self.layer6_conv = double_conv2d_bn(128,64)
self.layer7_conv = double_conv2d_bn(64,32)
self.layer8_conv = double_conv2d_bn(32,16)
self.layer9_conv = double_conv2d_bn(16,8)
self.layer10_conv = nn.Conv2d(8,1,kernel_size=3,
stride=1,padding=1,bias=True)
self.deconv1 = deconv2d_bn(128,64)
self.deconv2 = deconv2d_bn(64,32)
self.deconv3 = deconv2d_bn(32,16)
self.deconv4 = deconv2d_bn(16,8)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
conv1 = self.layer1_conv(x)
pool1 = F.max_pool2d(conv1,2)
conv2 = self.layer2_conv(pool1)
pool2 = F.max_pool2d(conv2,2)
conv3 = self.layer3_conv(pool2)
pool3 = F.max_pool2d(conv3,2)
conv4 = self.layer4_conv(pool3)
pool4 = F.max_pool2d(conv4,2)
conv5 = self.layer5_conv(pool4)
convt1 = self.deconv1(conv5)
concat1 = torch.cat([convt1,conv4],dim=1)
conv6 = self.layer6_conv(concat1)
convt2 = self.deconv2(conv6)
concat2 = torch.cat([convt2,conv3],dim=1)
conv7 = self.layer7_conv(concat2)
convt3 = self.deconv3(conv7)
concat3 = torch.cat([convt3,conv2],dim=1)
conv8 = self.layer8_conv(concat3)
convt4 = self.deconv4(conv8)
concat4 = torch.cat([convt4,conv1],dim=1)
conv9 = self.layer9_conv(concat4)
outp = self.layer10_conv(conv9)
outp = self.sigmoid(outp)
return outp
model = Unet()
inp = torch.rand(10,1,224,224)
outp = model(inp)
print(outp.shape)
==> torch.Size([10, 1, 224, 224])
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!