IDEA使用HDFS的JavaApi
注:以下代码操作是利用junit在java测试文件夹中实现。
1. 准备工作
1.1 创建测试类
创建测试类,并定义基本变量
public class HDFSJAVAAPI {
// 定义后续会用到的基本变量
public final String HDFS_PATH = "hdfs://hadoop00/";
Configuration conf = null;
FileSystem fs = null;
}
1.2 定义资源初始化方法
注释
@Before的作用是在后续每次测试方法之前先执行此方法,进行资源初始化。
@Before
// 用于初始化HDFS配置,执行打开资源的操作
public void Init() throws Exception {
System.out.println("打开资源初始化完成!");
// 如果是无参构造函数,那么将加载默认的配置文件
conf = new Configuration();
//获取FileSystem实例
//对于文件的操作都会在 hdfs://user/root/ 文件夹下进行
fileSystem = FileSystem.get(URI.create(HDFS_PATH), conf, "root");
}
1)关于Configuration
Hadoop使用org.apache.hadoop.conf.Configuration处理配置信息。这个类是作业的配置信息类,任何作用的配置信息必须通过Configuration传递,因为通过Configuration可以实现在多个mapper和多个reducer任务之间共享信息。
Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现(如 etc/hadoop/core-site.xml)。
2)关于FileSystem
FileSystem是一个通用的文件系统API,这里使用的文件系统是HDFS,获取FileSystem实例有下面这几个静态方法。
public static FileSystem get(Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf, String )
- 第一个方法返回的是默认文件系统(在
core-site.xml中指定的,如果没有指定,则使用默认的本地文件系统)。 - 第二个方法通过给定的URI方案和权限来确定要使用的文件系统,如果给定URI中没有指定方案,则默认返回文件系统。
- 第三个方法作为给定用户来访问文件系统,对安全来说至关重要。
1.3 定义资源关闭方法
注释@After的作用是每次测试完成一个方法后都执行此操作,将资源关闭。
@After
// 用于关闭资源
public void Shot() throws Exception {
// 将对象都置空
fs = null;
conf = null;
System.out.println("资源已关闭!");
}
2. 利用Java操作HDFS
2.1 创建目录
@Test
public void mkdir() throws Exception {
fs.mkdirs(new Path("HDFSAPI/test"));
}
执行结果:

1)FileSystem实例提供了创建目录的方法:
public boolean mkdirs(Path f) throws IOException
这个方法可以一次性创建所有必要但还没有的父目录,就像java.io.File类的mkdirs()方法。如果目录(以及所有父目录)都已经创建成功,则返回true。
注:因为指定了用户root所以新键的文件夹默认放在/user/root/下
2.2 上传本地文件到HDFS
public void copyFromLocalFile() throws Exception {
Path src = new Path("D:\\天\\Documents\\文本文件\\登岳阳楼.txt");
Path dst = new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/");
fs.copyFromLocalFile(src, dst);
}
执行结果:

2.3 读取文件
@Test
public void readFile() {
FSDataInputStream in = null;
try {
in = fs.open(new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/登岳阳楼.txt"));
IOUtils.copyBytes(in, System.out, 4096, false);
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(in);
}
}
执行结果:

1)FSDataInputStream对象:
FileSystem对象中的open()方法返回的是FSDataInputStream对象,而不是标准的java.io类对象。这个类是继承了java.io.DataInputStream的一个特殊类,并支持随机访问,由此可以从流的任意位置读取数据。
package org.apache.hadoop.fs;
public class FSDataInputStream extends DataInputStream implements Seekable, PositionedReadable{
}
Seekabel接口支持在文件中找到指定位置,并提供一个查询当前位置相对于文件起始位置偏移量(getPos())的查询方法:
public interface Seekable {
void seek(long pos) throws IOException;
long getPos() throws IOException;
}
调用seek()来定位大于文件长度的位置会引发IOException异常。与java.io.InputStream的skip()不同,seek()可以移到文件中的任意一个绝对位置,skip()则只能相对于当前位置定位到一个新位置。
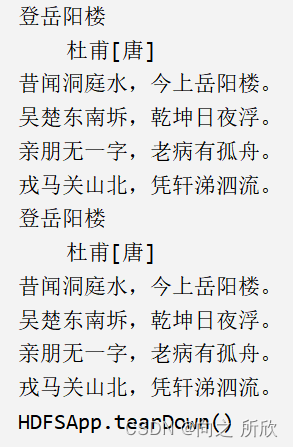
// 使用seek()方法,将HDFS中的一个文件在标准输出上显示两次
@Test
public void readFileTwice() {
FSDataInputStream in = null;
try {
in = fs.open(new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/登岳阳楼.txt"));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); //回到文件的开头
IOUtils.copyBytes(in, System.out, 4096, false);
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(in);
}
}
执行结果:
2.4 重命名文件
@Test
public void rename() throws Exception {
Path oldPath = new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/登岳阳楼.txt");
Path newPath = new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/ClimbingTheYueyangTower.txt");
System.out.println(fs.rename(oldPath, newPath));
}
执行结果:

1)FileSystem实例提供了重命名文件的方法:
public boolean rename(oldPath f1, newPath f2)
2.5 创建文件
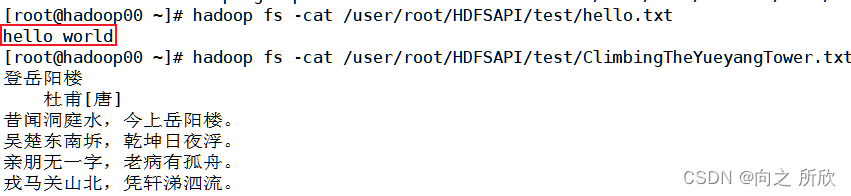
@Test
public void create() throws Exception {
//FSDataOutputStream类是Hadoop对于写操作提供的一个类,这个类重载了很多write方法用于写入不同类型的数据
//像FSDataIntputStream类一样,要获得FSDataOutputStream类的对象,就必须通过FileSystem类来和HDFS建立连接,然后
//通过路径返回FSDataOutputStream实例(对象)。
FSDataOutputStream output = fs.create(new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/hello.txt"));
output.write("hello world".getBytes());
output.flush();
output.close();
}
执行结果:
1)FSDataOutputStream对象
FileSystem实例的create()方法返回FSDataOutputStream对象,与FSDataInputStream类相似,它也有一个查询文件当前位置的方法:
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable {
public long getPos() throws IOException {
}
}
但与FSDataInputStream类不同的是,FSDataOutputStream类不允许在文件中定位。这是因为HDFS只允许一个已打开的文件顺序写入,或在现有文件的末尾追加数据。
2.6 查询文件系统
查看某个目录下的所有文件
@Test
public void listFile() throws Exception {
//FileStatus对象封装了文件系统中文件和目录的元数据,包括文件的长度、块大小、备份数、修改时间、所有者以及权限等信息。
//FileStatus对象一般由FileSystem的getFileStatus()方法获得,调用该方法的时候要把文件的Path传递进去。
FileStatus[] listStatus = fs.listStatus(new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test"));
for (FileStatus fileStatus : listStatus) {
String isDir = fileStatus.isDirectory()?"文件夹":"文件"; // 文件 / 文件夹
String permission = fileStatus.getPermission().toString();// 权限
short replication = fileStatus.getReplication(); // 副本系数
long len = fileStatus.getLen(); //长度
String path = fileStatus.getPath().toString(); // 路径
System.out.println(isDir + "\t" +permission + "\t" + replication + "\t" + len + "\t" + path);
}
}
执行结果:

1)列出文件:
查找一个文件或目录的信息很实用,但通常还需要能够列出目录中的内容。这就是FileSystem的listStatus()方法的功能:
public FileStatus[] listStatus(Path f) throws IOException
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException
public FileStatus[] listStatus(Path[] files) throws IOException
public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOException
2.7 查看文件块信息
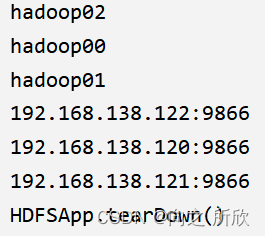
@Test
public void getFileBlockLocation() throws Exception {
FileStatus fileStatus = fileSystem.getFileStatus(new Path("hdfs://hadoop00:9000/user/root/HDFSAPI/test/ClimbingTheYueyangTower.txt"));
BlockLocation[] blocks = fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for (BlockLocation block : blocks) {
for (String host : block.getHosts()) {
System.out.println(host);
}
for (String name : block.getNames()) {
System.out.println(name);
}
}
}
注:这里获取元数据中的主机名和主机地址。
执行结果:
1)文件元数据:FileStatus
FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者以及权限信息。
FeilSystem的getFileStatus()方法用于获取文件或目录的FileStatus对象。
参考资料:
- 《Hadoop权威指南–大数据分析与存储》 第四版
- 《Hadoop应用开发基础》
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!