llm之openai库快速入门
llm之openai库快速入门
基于openai 1.3.7
新版本和老版本对应的函数关系:https://github.com/openai/openai-python/discussions/742
models.list
列举出可用模型
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
models = client.models.list()
model_list = [model.id for model in models.data]
print(model_list)
chat.completions
openai第一个api请求
api文档:https://platform.openai.com/docs/api-reference/chat/create
1、配置代理
import os
os.environ['HTTP_PROXY']="http://127.0.0.1:7890"
os.environ['HTTPS_PROXY']="http://127.0.0.1:7890"
2、配置api-key
import os
os.environ["OPENAI_API_KEY"] = ''#填写自己的api_key
3、发送请求
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."},
{"role": "user", "content": "Compose a poem that explains the concept of recursion in programming."}
]
)
print(completion.choices[0].message)
Chat Completions API主要参数介绍
使用 Chat Completions API 实现对话任务
主要请求参数说明:
-
model(string,必填)要使用的模型ID。有关哪些模型适用于Chat API的详细信息
-
messages(array,必填)迄今为止描述对话的消息列表
role(string,必填)
发送此消息的角色。
system、user或assistant之一(一般用 user 发送用户问题,system 发送给模型提示信息)-
content(string,必填)消息的内容
-
name(string,选填)此消息的发送者姓名。可以包含 a-z、A-Z、0-9 和下划线,最大长度为 64 个字符
-
stream(boolean,选填,是否按流的方式发送内容)当它设置为 true 时,API 会以 SSE( Server Side Event )方式返回内容。SSE 本质上是一个长链接,会持续不断地输出内容直到完成响应。如果不是做实时聊天,默认false即可。
-
max_tokens(integer,选填)在聊天补全中生成的最大 tokens 数。
输入token和生成的token的总长度受模型上下文长度的限制。
-
temperature(number,选填,默认是 1)采样温度,在 0和 2 之间。
较高的值,如0.8会使输出更随机,而较低的值,如0.2会使其更加集中和确定性。
通常建议修改这个(
temperature)或者top_p,但两者不能同时存在,二选一。 -
response_format只能是text或者json_object,并且使用 JSON 模式时,您还必须通过系统或用户消息指示模型需要生成 JSON格式的输出。如果没有这个,模型可能会生成无休止的空白流,直到生成达到令牌限制,从而导致长时间运行且看似“卡住”的请求。eg: { “type”: “json_object” }
examples:
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
response_format={ "type": "json_object" },
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
)
print(response.choices[0].message.content)
动态构造messages消息列表
1、请求第1个对话
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
messages=[
{
"role": "user",
"content": "Hello!"
}
]
data = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = messages
)
new_message = data.choices[0].message
print(new_message)
输出
ChatCompletionMessage(content='Hi there! How can I assist you today?', role='assistant', function_call=None, tool_calls=None)
2、记录第一段对话的响应:
new_message_dict = {"role": new_message.role, "content": new_message.content}
print(type(new_message_dict))
print(new_message_dict)
输出
<class 'dict'>
{'role': 'assistant', 'content': 'Hi there! How can I assist you today?'}
3、添加响应到messages列表中
# 将消息追加到 messages 列表中
messages.append(new_message_dict)
print(messages)
输出
[{'role': 'user', 'content': 'Hello!'}, {'role': 'assistant', 'content': 'Hi there! How can I assist you today?'}]
4、构造新一轮对话messages
# 新一轮对话
new_chat = {
"role": "user",
"content": "1.讲一个程序员才听得懂的冷笑话;2.今天是几号?3.明天星期几?"
}
messages.append(new_chat)
from pprint import pprint
pprint(messages)
输出
[{'content': 'Hello!', 'role': 'user'},
{'content': 'Hi there! How can I assist you today?', 'role': 'assistant'},
{'content': '1.讲一个程序员才听得懂的冷笑话;2.今天是几号?3.明天星期几?', 'role': 'user'}]
5、进行新一轮对话
data = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
new_message = data.choices[0].message
# 打印 new_messages
print(new_message)
# 打印 new_messages 内容
print(new_message.content)
输出
ChatCompletionMessage(content='1. "为什么编程语言总是错误?因为它们都只认0和1,其他的数字它们根本不理会!"\n2. 今天是2021年9月30日。\n3. 明天是星期五。', role='assistant', function_call=None, tool_calls=None)
1. "为什么编程语言总是错误?因为它们都只认0和1,其他的数字它们根本不理会!"
2. 今天是2021年9月30日。
3. 明天是星期五。
多种身份聊天对话system, user,assistant
目前role参数支持3类身份: system, user assistant
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
# 构造聊天记录
messages=[
{"role": "system", "content": "你是一个乐于助人的体育界专家。"},
{"role": "user", "content": "2008年奥运会是在哪里举行的?"},
]
data = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
message = data.choices[0].message.content
print(message)
输出
2008年夏季奥运会在中国的北京市举行。
添加 GPT 返回结果到聊天记录
# 添加 GPT 返回结果到聊天记录
messages.append({"role": "assistant", "content": message})
print(messages)
输出:
[{'role': 'system', 'content': '你是一个乐于助人的体育界专家。'}, {'role': 'user', 'content': '2008年奥运会是在哪里举行的?'}, {'role': 'assistant', 'content': '2008年夏季奥运会在中国的北京市举行。'}]
第二轮对话
# 第二轮对话
messages.append({"role": "user", "content": "1.金牌最多的是哪个国家?2.奖牌最多的是哪个国家?"})
messages
data = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
message = data.choices[0].message.content
print(message)
输出:
1. 2008年奥运会中,金牌最多的国家是中国,共获得51枚金牌。
2. 奖牌最多的国家也是中国,共获得100枚奖牌(51枚金牌、21枚银牌和28枚铜牌)。
当没有上下文信息,直接提问时,gpt的返回结果有所差异,如下:
data = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{'role': 'user', 'content': '1.金牌最多的是哪个国家?2.奖牌最多的是哪个国家?'}]
)
print(data.choices[0].message.content)
输出结果如下:
1. 截止到2021年,金牌最多的国家是美国。
2. 截止到2021年,奖牌最多的国家是美国。
embeddings
第一个参考案例
参考:https://platform.openai.com/docs/guides/embeddings/use-cases
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
res = client.embeddings.create(input="abc", model="text-embedding-ada-002")
print(res.data[0].embedding)
输出:
[0.0026003902312368155, -0.011285446584224701, -0.009404539130628109,
..................................................................
..................................................................
..................................................................
..................................................................
..................................................................
-0.0012118066661059856, 0.01559880655258894, -0.028086336329579353, -0.023320427164435387, -0.0020134905353188515, -0.005978599656373262, -0.022203195840120316, -0.010083362460136414, -0.01566951721906662]
应用到csv文件上,批量embedding
加载数据集:
input_datapath = "data/fine_food_reviews_1k.csv"
df = pd.read_csv(input_datapath, index_col=0)
df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]
df = df.dropna()
# 将 "Summary" 和 "Text" 字段组合成新的字段 "combined"
df["combined"] = (
"Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
)
df.head(2)

# 模型类型
# 建议使用官方推荐的第二代嵌入模型:text-embedding-ada-002
embedding_model = "text-embedding-ada-002"
# text-embedding-ada-002 模型对应的分词器(TOKENIZER)
embedding_encoding = "cl100k_base"
# text-embedding-ada-002 模型支持的输入最大 Token 数是8191,向量维度 1536
# 在我们的 DEMO 中过滤 Token 超过 8000 的文本
max_tokens = 8000
# 设置要筛选的评论数量为1000
top_n = 1000
# 对DataFrame进行排序,基于"Time"列,然后选取最后的2000条评论。
# 这个假设是,我们认为最近的评论可能更相关,因此我们将对它们进行初始筛选。
df = df.sort_values("Time").tail(top_n * 2)
# 丢弃"Time"列,因为我们在这个分析中不再需要它。
df.drop("Time", axis=1, inplace=True)
# 从'embedding_encoding'获取编码
encoding = tiktoken.get_encoding(embedding_encoding)
# 计算每条评论的token数量。我们通过使用encoding.encode方法获取每条评论的token数,然后把结果存储在新的'n_tokens'列中。
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
# 如果评论的token数量超过最大允许的token数量,我们将忽略(删除)该评论。
# 我们使用.tail方法获取token数量在允许范围内的最后top_n(1000)条评论。
df = df[df.n_tokens <= max_tokens].tail(top_n)
# 打印出剩余评论的数量。
df["n_tokens"].tolist()[:10]
输出:
[52, 178, 78, 111, 78, 96, 98, 44, 96, 77]
对csv文件中的combined列进行embedding
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)
ast.literal_eval将字符串转换为list
import pandas as pd
import ast
df = pd.read_csv('output/embedded_1k_reviews.csv')
# 将字符串转换为向量
df_embedded["embedding_vec"] = df_embedded["embedding"].apply(ast.literal_eval).apply(np.array)
tiktoken库使用
tiktoken是OpenAI开发的一种BPE分词器。
给定一段文本字符串(例如,"tiktoken is great!")和一种编码方式(例如,"cl100k_base"),分词器可以将文本字符串切分成一系列的token(例如,["t", "ik", "token", " is", " great", "!"])。
将文本字符串切分成token非常有用,因为GPT模型看到的文本就是以token的形式呈现的。知道一段文本字符串中有多少个token可以告诉你(a)这个字符串是否对于文本模型来说太长了而无法处理,以及(b)一个OpenAI API调用的费用是多少(因为使用量是按照token计价的)。
编码方式规定了如何将文本转换成token。不同的模型使用不同的编码方式。
tiktoken支持OpenAI模型使用的三种编码方式:
| 编码名称 | OpenAI模型 |
|---|---|
cl100k_base | gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
p50k_base | Codex模型, text-davinci-002, text-davinci-003 |
r50k_base (或 gpt2) | 像 davinci 这样的GPT-3模型 |
你可以使用 tiktoken.encoding_for_model() 获取一个模型的编码方式,如下所示:
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')
在英语中,token的长度通常在一个字符到一个单词之间变化(例如,"t" 或 " great"),尽管在某些语言中,token可以比一个字符短或比一个单词长。空格通常与单词的开头一起分组(例如," is" 而不是 "is " 或 " "+"is")。你可以快速在 OpenAI分词器 检查一段字符串如何被分词。
使用tiktoken计算token
import tiktoken
# 使用`tiktoken.get_encoding()`按名称加载编码。第一次运行时,它将需要互联网连接进行下载。后续运行不需要互联网连接。
encoding1 = tiktoken.get_encoding("cl100k_base")
# 使用`tiktoken.encoding_for_model()`函数可以自动加载给定模型名称的正确编码。
encoding2 = tiktoken.encoding_for_model("gpt-3.5-turbo")
# encoding1和encoding2是等价的,因为gpt-3.5-turbo使用的编码名称是cl100k_base
print(encoding1.encode("tiktoken is great!"))
print(encoding2.encode("tiktoken is great!"))
输出:
定义函数计算返回文本字符串中的Token数量
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""返回文本字符串中的Token数量"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")
输出:
6
decode返回原文:
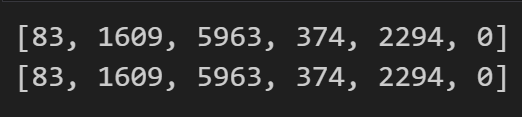
encoding1.decode([83, 1609, 5963, 374, 2294, 0])
输出:
'tiktoken is great!'
注意:尽管**.decode()**可以应用于单个token,但对于不在 utf-8 边界上的token来说,解码可能会有损失或错误。
对于单个token,.decode_single_token_bytes() 安全地将单个整数token转换为其表示的字节。
[encoding1.decode_single_token_bytes(token) for token in [83, 1609, 5963, 374, 2294, 0]]
tools和tool_choice的使用
参考:
https://platform.openai.com/docs/api-reference/chat/create
https://platform.openai.com/docs/guides/function-calling
1、通过http请求openai的api使用tools和tool_choice
import json
import requests
import os
from tenacity import retry, wait_random_exponential, stop_after_attempt
GPT_MODEL = "gpt-3.5-turbo"
# 使用了retry库,指定在请求失败时的重试策略。
# 这里设定的是指数等待(wait_random_exponential),时间间隔的最大值为40秒,并且最多重试3次(stop_after_attempt(3))。
# 定义一个函数chat_completion_request,主要用于发送 聊天补全 请求到OpenAI服务器
@retry(wait=wait_random_exponential(multiplier=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, tools=None, tool_choice='auto', model=GPT_MODEL):
# 设定请求的header信息,包括 API_KEY
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + os.getenv("OPENAI_API_KEY"),
}
# 设定请求的JSON数据,包括GPT 模型名和要进行补全的消息
json_data = {"model": model, "messages": messages}
# 如果传入了functions,将其加入到json_data中
if tools is not None:
json_data.update({"tools": tools})
# 如果传入了function_call,将其加入到json_data中
if tool_choice != 'auto':
json_data.update({"tool_choice": tool_choice})
# 尝试发送POST请求到OpenAI服务器的chat/completions接口
try:
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json=json_data,
)
# 返回服务器的响应
return response
# 如果发送请求或处理响应时出现异常,打印异常信息并返回
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
定义tools:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
发起请求:
# 定义一个空列表messages,用于存储聊天的内容
messages = []
# 使用append方法向messages列表添加一条系统角色的消息
messages.append({
"role": "system", # 消息的角色是"system"
"content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous." # 消息的内容
})
# 向messages列表添加一条用户角色的消息
messages.append({
"role": "user", # 消息的角色是"user"
"content": "What's the weather like today" # 用户询问今天的天气情况
})
# 使用定义的chat_completion_request函数发起一个请求,传入messages和functions作为参数
chat_response = chat_completion_request(
messages, tools=tools
)
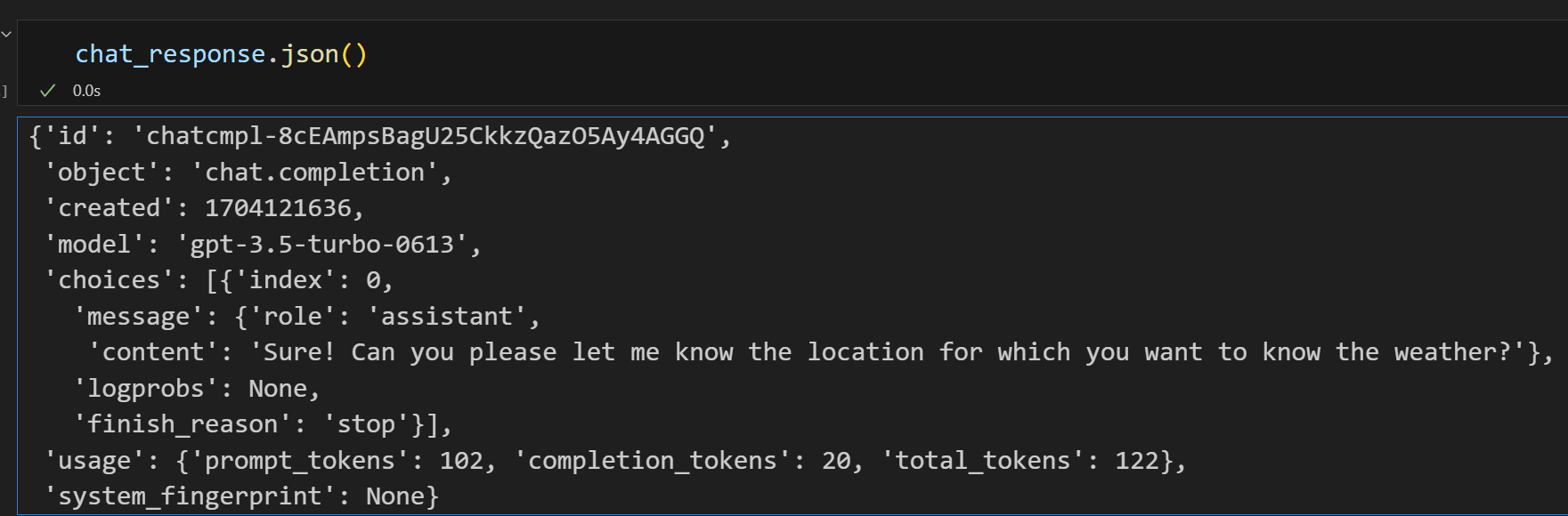
print(chat_response.json())
# 解析返回的JSON数据,获取助手的回复消息
assistant_message = chat_response.json()["choices"][0]["message"]
# 将助手的回复消息添加到messages列表中
messages.append(assistant_message)
响应如下:
.json() 是 requests.Response 对象的一个方法。当响应的内容是 JSON 格式时,这个方法会自动解析 JSON 字符串,并将其转换为 Python 中的字典(或列表,取决于 JSON 的结构)
print(messages)
输出:
[{'role': 'system', 'content': "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."}, {'role': 'user', 'content': "What's the weather like today"}, {'role': 'assistant', 'content': 'Sure! Can you please let me know the location for which you want to know the weather?'}]
# 向messages列表添加一条用户角色的消息,用户告知他们在苏格兰的格拉斯哥
messages.append({
"role": "user", # 消息的角色是"user"
"content": "I'm in Shanghai, China." # 用户的消息内容
})
# 再次使用定义的chat_completion_request函数发起一个请求,传入更新后的messages和functions作为参数
chat_response = chat_completion_request(
messages, tools=tools
)
# 解析返回的JSON数据,获取助手的新的回复消息
assistant_message = chat_response.json()["choices"][0]["message"]
# 将助手的新的回复消息添加到messages列表中
messages.append(assistant_message)
print(assistant_message)
输出:
{'role': 'assistant', 'content': None, 'tool_calls': [{'id': 'call_Zd77AJEn9WnTZohncetOPI7U', 'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{\n "location": "Shanghai, China"\n}'}}]}
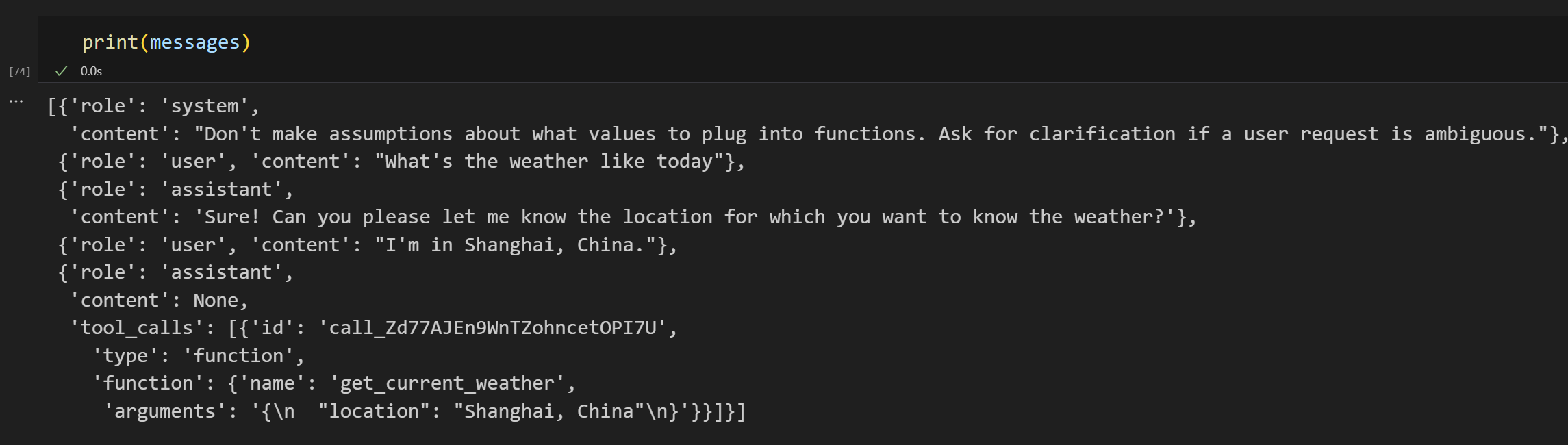
print(messages)
输出:
2、通过openai库的api使用tools和tool_choice
使用openai解析用户提问的参数,并将其传入自定义的函数中,得到执行结果,返回给用户。
from openai import OpenAI
import json
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
# Example dummy function hard coded to return the same weather
# In production, this could be your backend API or an external API
def get_current_weather(location, unit="fahrenheit"):
"""Get the current weather in a given location"""
if "tokyo" in location.lower():
return json.dumps({"location": "Tokyo", "temperature": "10", "unit": unit})
elif "san francisco" in location.lower():
return json.dumps({"location": "San Francisco", "temperature": "72", "unit": unit})
elif "paris" in location.lower():
return json.dumps({"location": "Paris", "temperature": "22", "unit": unit})
else:
return json.dumps({"location": location, "temperature": "unknown"})
def run_conversation():
# Step 1: send the conversation and available functions to the model
messages = [{"role": "user", "content": "What's the weather like in San Francisco, Tokyo, and Paris?"}]
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=messages,
tools=tools,
tool_choice="auto", # auto is default, but we'll be explicit
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# Step 2: check if the model wanted to call a function
if tool_calls:
# Step 3: call the function
# Note: the JSON response may not always be valid; be sure to handle errors
available_functions = {
"get_current_weather": get_current_weather,
} # only one function in this example, but you can have multiple
messages.append(response_message) # extend conversation with assistant's reply
# Step 4: send the info for each function call and function response to the model
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
location=function_args.get("location"),
unit=function_args.get("unit"),
)
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
) # extend conversation with function response
second_response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=messages,
) # get a new response from the model where it can see the function response
return second_response
print(run_conversation())
3、构建基于sqlite数据库的问答系统
(1) 定义使用http方法请求openai的api: https://api.openai.com/v1/chat/completions
import json
import requests
import os
from tenacity import retry, wait_random_exponential, stop_after_attempt
GPT_MODEL = "gpt-3.5-turbo"
# 使用了retry库,指定在请求失败时的重试策略。
# 这里设定的是指数等待(wait_random_exponential),时间间隔的最大值为40秒,并且最多重试3次(stop_after_attempt(3))。
# 定义一个函数chat_completion_request,主要用于发送 聊天补全 请求到OpenAI服务器
@retry(wait=wait_random_exponential(multiplier=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, tools=None, tool_choice=None, model=GPT_MODEL):
# 设定请求的header信息,包括 API_KEY
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + os.getenv("OPENAI_API_KEY"),
}
# 设定请求的JSON数据,包括GPT 模型名和要进行补全的消息
json_data = {"model": model, "messages": messages}
# 如果传入了functions,将其加入到json_data中
if tools is not None:
json_data.update({"tools": tools})
# 如果传入了function_call,将其加入到json_data中
if tool_choice is not None:
json_data.update({"tool_choice": tool_choice})
# 尝试发送POST请求到OpenAI服务器的chat/completions接口
try:
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json=json_data,
)
# 返回服务器的响应
return response
# 如果发送请求或处理响应时出现异常,打印异常信息并返回
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
(2) 定义数据库操作函数
from openai import OpenAI
import json
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
import sqlite3
conn = sqlite3.connect("data/chinook.db")
print("Opened database successfully")
def get_table_names(conn):
"""返回一个包含所有表名的列表"""
table_names = [] # 创建一个空的表名列表
# 执行SQL查询,获取数据库中所有表的名字
tables = conn.execute("SELECT name FROM sqlite_master WHERE type='table';")
# 遍历查询结果,并将每个表名添加到列表中
for table in tables.fetchall():
table_names.append(table[0])
return table_names # 返回表名列表
def get_column_names(conn, table_name):
"""返回一个给定表的所有列名的列表"""
column_names = [] # 创建一个空的列名列表
# 执行SQL查询,获取表的所有列的信息
columns = conn.execute(f"PRAGMA table_info('{table_name}');").fetchall()
# 遍历查询结果,并将每个列名添加到列表中
for col in columns:
column_names.append(col[1])
return column_names # 返回列名列表
def get_database_info(conn):
"""返回一个字典列表,每个字典包含一个表的名字和列信息"""
table_dicts = [] # 创建一个空的字典列表
# 遍历数据库中的所有表
for table_name in get_table_names(conn):
columns_names = get_column_names(conn, table_name) # 获取当前表的所有列名
# 将表名和列名信息作为一个字典添加到列表中
table_dicts.append({"table_name": table_name, "column_names": columns_names})
return table_dicts # 返回字典列表
def ask_database(conn, query):
"""使用 query 来查询 SQLite 数据库的函数。"""
try:
results = str(conn.execute(query).fetchall()) # 执行查询,并将结果转换为字符串
except Exception as e: # 如果查询失败,捕获异常并返回错误信息
results = f"query failed with error: {e}"
return results # 返回查询结果
(3)定义消息和tools
messages = []
# 向消息列表中添加一个系统角色的消息,内容是 "Answer user questions by generating SQL queries against the Chinook Music Database."
messages.append({"role": "system", "content": "Answer user questions by generating SQL queries against the Chinook Music Database."})
# 向消息列表中添加一个用户角色的消息,内容是 "Hi, who are the top 5 artists by number of tracks?"
messages.append({"role": "user", "content": "Hi, who are the top 5 artists by number of tracks?"})
# 获取数据库信息,并存储为字典列表
database_schema_dict = get_database_info(conn)
# 将数据库信息转换为字符串格式,方便后续使用
database_schema_string = "\n".join(
[
f"Table: {table['table_name']}\nColumns: {', '.join(table['column_names'])}"
for table in database_schema_dict
]
)
tools = [
{
"type": "function",
"function": {
"name": "ask_database",
"description": "Use this function to answer user questions about music. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
SQL query extracting info to answer the user's question.
SQL should be written using this database schema:
{database_schema_string}
The query should be returned in plain text, not in JSON.
""",
}
},
"required": ["query"],
},
},
}
]
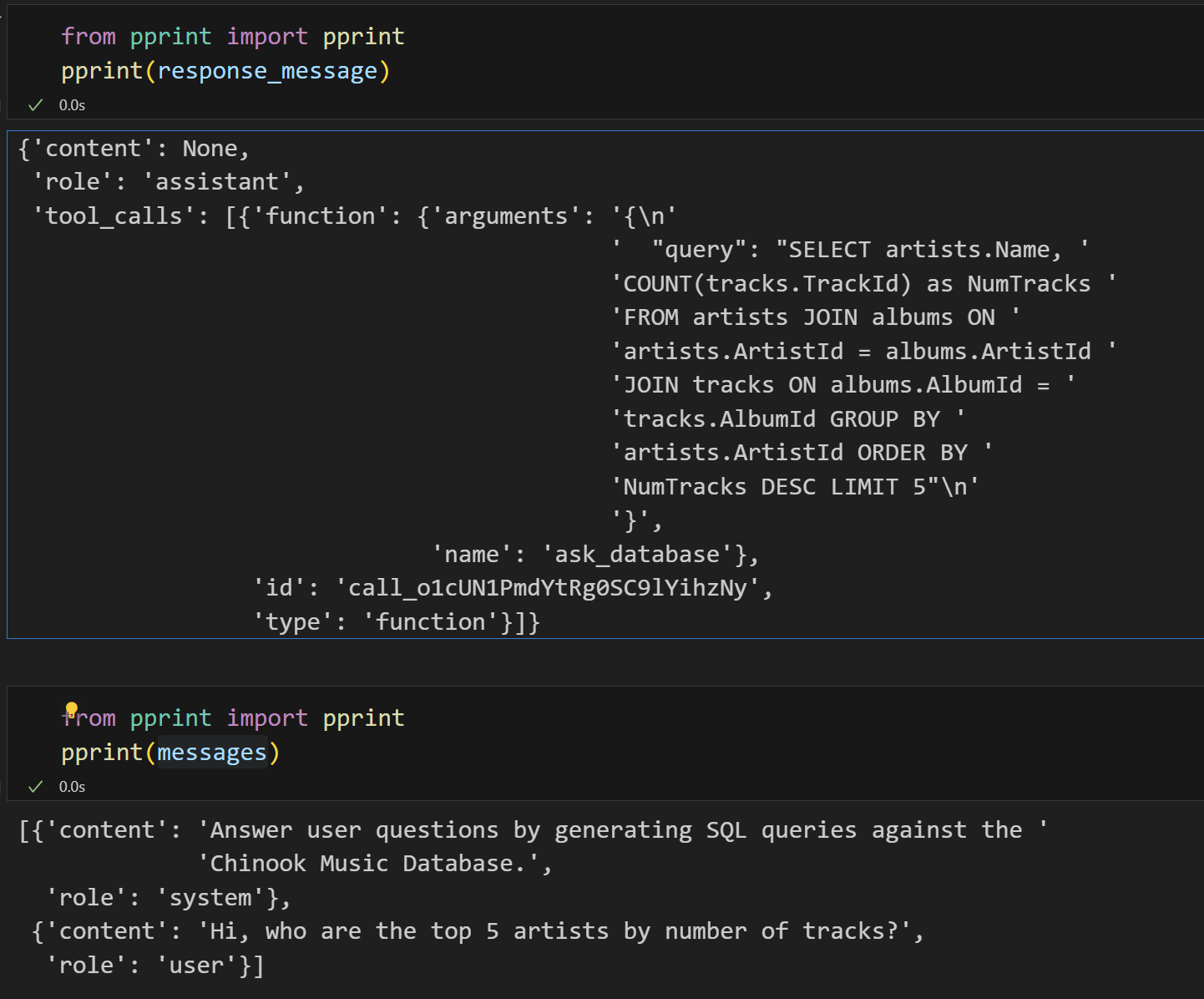
response_message = response.json()["choices"][0]["message"]
tool_calls = response_message["tool_calls"]
打印当前消息列表
(4)提取用户要查询的输入,放入函数执行,将结果返回
# Step 3: call the function
# Note: the JSON response may not always be valid; be sure to handle errors
available_functions = {
"ask_database": ask_database,
} # only one function in this example, but you can have multiple
messages.append(response_message) # extend conversation with assistant's reply
# messages.append(
# "Assistant": "Assistant",
# "name": tool_calls[0].function.name,
# "content": tool_calls[0].function.arguments,
# )
# Step 4: send the info for each function call and function response to the model
for tool_call in tool_calls:
function_name = tool_call["function"]["name"]
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call["function"]["arguments"])
function_response = function_to_call(
conn=conn,
query=function_args.get("query"),
)
messages.append(
{
"tool_call_id": tool_call["id"],
"role": "tool",
"name": function_name,
"content": function_response,
}
) # extend conversation with function response
print(messages)
# second_response = client.chat.completions.create(
# model="gpt-3.5-turbo",
# messages=messages,
# ) # get a new response from the model where it can see the function response
打印当前messages:
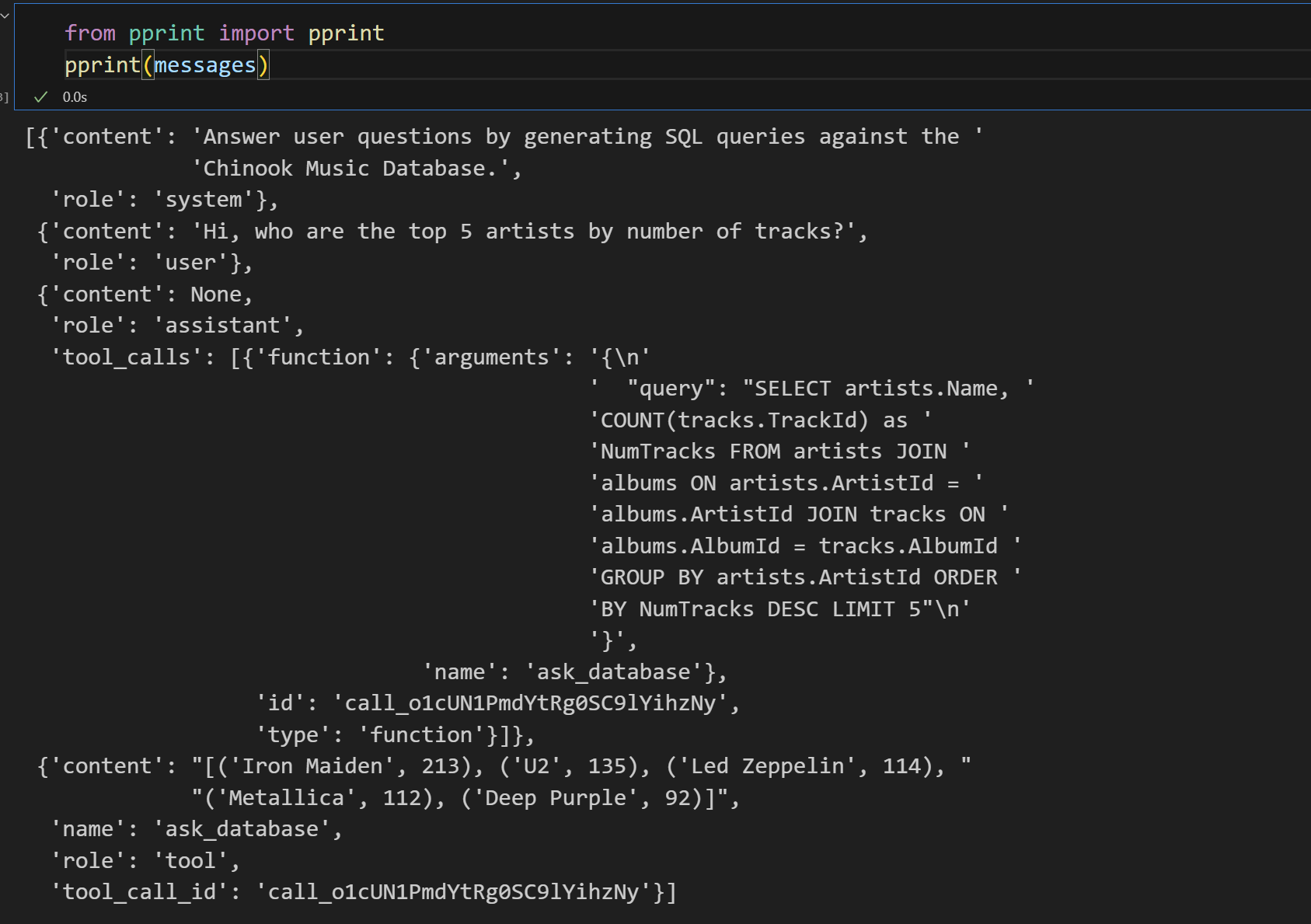
(5) 再次发送请求
second_response = chat_completion_request(
model="gpt-3.5-turbo",
messages=messages,
) # get a new response from the model where it can see the function response
打印second_response结果如下
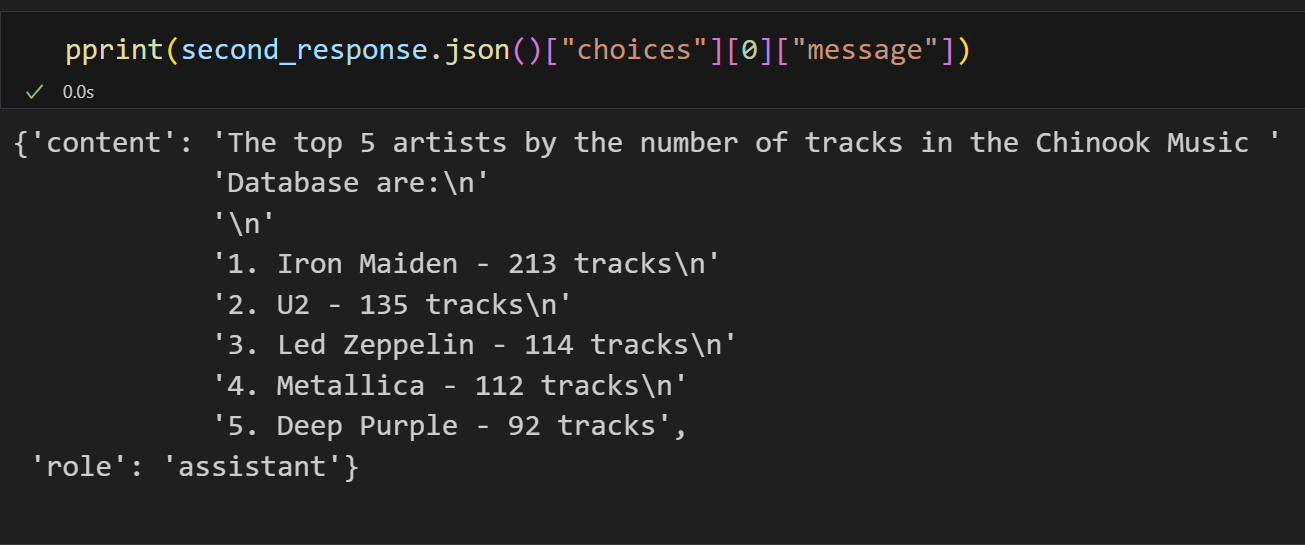
公众号

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!