一文掌握Ascend C孪生调试
1? What,什么是孪生调试
Ascend C提供孪生调试方法,即CPU域模拟NPU域的行为,相同的算子代码可以在CPU域调试精度,NPU域调试性能。孪生调试的整体方案如下:开发者通过调用Ascend C类库编写Ascend C算子kernel侧源码,kernel侧源码通过通用的GCC编译器进行编译,编译生成通用的CPU域的二进制,可以通过gdb通用调试工具等调试手段进行调试;kernel侧源码通过毕昇编译器进行编译,编译生成NPU域的二进制文件,可以通过msprof工具进行性能数据采集等方式进行调试。
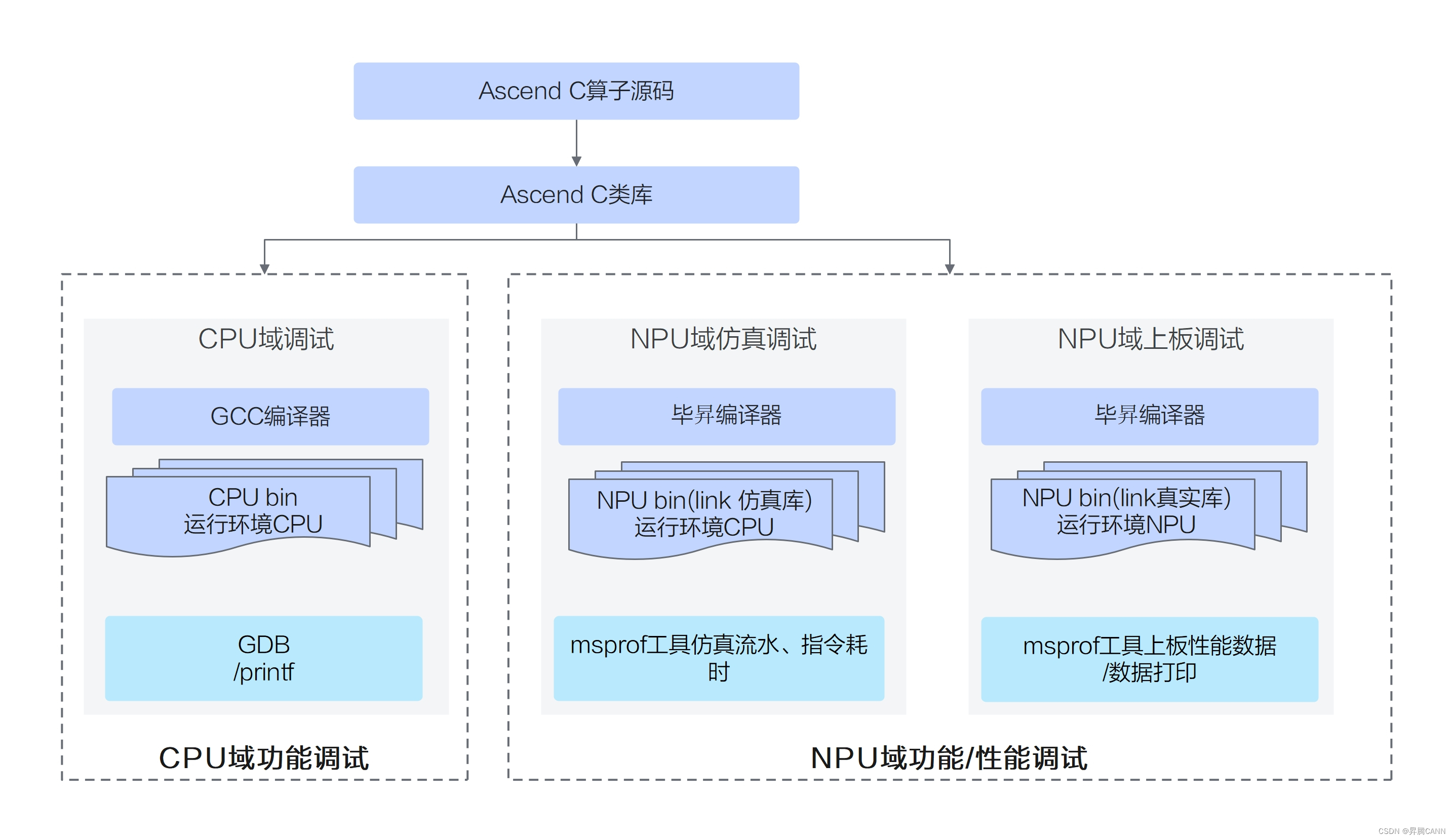
针对NPU域的调试来讲,根据依赖和调用动态库的不同,分为NPU域仿真调试和NPU域上板调试。NPU域仿真调试,依赖和调用的是model仿真器指定的库文件,运行model仿真不需要使用真实的NPU环境;上板调试,依赖和调用的是真实NPU环境上的库文件,进行上板调试需要真实的NPU环境。
CPU域调试用于定位逻辑错误、内存错误等功能问题; NPU域调试不仅可以通过数据打印的方式定位功能问题,也可以用于定位性能问题、算子同步问题。
本文将从功能调试的角度出发,介绍CPU域和NPU域的调试方法,并通过具体的调试样例来帮助大家快速掌握;性能调试的方法将在后续的文章中介绍。
2? HOW,如何进行调试
2.1? CPU域
本节介绍CPU域调试的两种方法:gdb调试、使用printf打印命令打印。
2.1.1? gdb调试
gdb调试相信大家并不陌生,首先我们先来回顾几个常用的调试命令,更多内容可以前往https://sourceware.org/gdb/深入学习。
| 命令 | 功能 |
| step | 执行下一行语句,?如语句为函数调用,?进入函数中 |
| next | 执行下一行语句,?如语句为函数调用,?不进入函数中 |
| continue | 从当前位置继续运行程序 |
| run | 从头开始运行程序 |
| quit | 退出程序 |
| | 输出变量值、调用函数、通过表达式改变变量值 |
| list | 查看当前位置代码 |
| backtrace | 查看各级堆栈的函数调用及参数 |
| break?N | 在第N行上设置断点 |
| display | 每次停下来时,显示设置的变量var的值 |
这里稍微复杂一点的是,因为我们程序是多核执行程序,cpu调测将其转为多进程调试,每个核都会拉起独立的子进程,故gdb需要转换成子进程调试的方式。下面介绍子进程调试的方法。
- 调试单独一个子进程
在gdb启动后,首先设置跟踪子进程,之后再打断点,就会停留在子进程中,设置的命令为:
set follow-fork-mode child
但是这种方式只会停留在遇到断点的第一个子进程中,其余子进程和主进程会继续执行直到退出。涉及到核间同步的算子无法使用这种方法进行调试。
如下是调试一个单独子进程的调试命令样例:
gdb --args add_custom_cpu
set follow-fork-mode child
break add_custom.cpp:45
run
list
backtrace
print i
break add_custom.cpp:56
continue
display xLocal
quit
- 调试多个子进程
如果涉及到核间同步,那么需要能同时调试多个子进程。
在gdb启动后,首先设置调试模式为只调试一个进程,挂起其他进程。设置的命令如下:
(gdb) set detach-on-fork off
查看当前调试模式的命令为:
??????(gdb) show detach-on-fork
中断gdb程序的方式要使用捕捉事件的方式,即gdb程序监控fork这一事件并中断。这样在每一次起子进程时就可以中断gdb程序。设置的命令为:
(gdb) catch fork
当执行r后,可以查看当前的进程信息:
(gdb) info inferiors
??Num ?Description
* 1 ???process 19613
可以看到,当第一次执行fork的时候,程序断在了主进程fork的位置,子进程还未生成。
执行c后,再次查看info inferiors,可以看到此时第一个子进程已经启动。
(gdb) info inferiors
??Num ?Description
* 1 ???process 19613
??2 ???process 19626
这个时候可以使用切换到第二个进程,也就是第一个子进程,再打上断点进行调试,此时主进程是暂停状态:
(gdb) inferior 2
[Switching to inferior 2 [process 19626] ($HOME/demo)]
(gdb) info inferiors
??Num ?Description
??1 ???process 19613
* 2 ???process 19626
请注意,inferior后跟的数字是进程的序号,而不是进程号。
如果遇到同步阻塞,可以切换回主进程继续生成子进程,然后再切换到新的子进程进行调试,等到同步条件完成后,再切回第一个子进程继续执行。
2.1.2? printf打印命令
printf则更为简单,直接使用printf打印命令printf(...)来观察数值的输出。需要注意的是:NPU模式下目前不支持打印语句,所以需要添加内置宏__CCE_KT_TEST__予以区分。样例代码如下:
printf("xLocal size: %d\n", xLocal.GetSize());
printf("tileLength: %d\n", tileLength);
2.2? NPU域????????
2.2.1? 上板数据打印(DumpTensor、PRINTF)
功能包括DumpTensor、PRINTF两种,其中DumpTensor用于打印指定Tensor的数据,PRINTF主要用于打印标量和字符串信息。
具体的使用方法如下:
1. 设置打开DUMP开关的环境变量
export ACL_DUMP_DATA=1
修改Dump信息配置文件acl.json。单算子调用应用开发场景下,新建acl.json放在应用开发的工程目录下,在调用aclInit接口时传入;Pytorch调用场景下,放在Pytorch脚本执行目录下,由框架自行读取。配置样例如下:其中dump_path表示dump数据文件存储到运行环境的目录,支持配置绝对路径或相对路径;dump_mode表示dump的模式,配置成input/output/all有效模式均可以;dump_op_switch表示单算子dump数据开关,需要配置成on,开启单算子dump模式;dump_debug为预留参数,开发者无需关注,直接配置成off即可。
{
????"dump":{
????????"dump_path":"/dump",
????????"dump_mode": "all",
????????"dump_debug": "off",
????????"dump_op_switch": "on"
?????}
}
2. 增加算子工程编译选项-DASCENDC_DUMP:修改算子工程op_kernel目录下的CMakeLists.txt文件,首行增加编译选项,打开DUMP开关,样例如下:
add_ops_compile_options(ALL OPTIONS -DASCENDC_DUMP)
3.?在算子kernel侧实现代码中需要输出日志信息的地方调用DumpTensor接口或者PRINTF接口打印相关内容
a)?DumpTensor示例,srcLocal表示待打印的Tensor;5表示用户的自定义附加信息,比如当前的代码行号;dataLen表示元素个数。
DumpTensor(srcLocal,5, dataLen);
Dump时,每个block核的dump信息前会增加对应信息头DumpHead(32字节大小),用于记录核号和资源使用信息;每次Dump的Tensor数据前也会添加信息头DumpTensorHead(32字节大小),用于记录Tensor的相关信息。如下图所示,展示了多核打印场景下的打印信息结构。

DumpHead的具体信息如下:
- block_id:当前运行的核号;
- total_block_num:此次dump的核数;
- block_remain_len:当前核剩余可用的dump的空间;
- block_initial_space:当前核初始分配的dump空间;
- magic:内存校验魔术字。
DumpTensorHead的具体信息如下:
- desc:用户自定义附加信息;
- addr:Tensor的地址;
- data_type:Tensor的数据类型;
- position:表示Tensor所在的物理存储位置。
打印结果的样例如下:
DumpHead: block_id=0, total_block_num=16, block_remain_len=1048448, block_initial_space=1048576, magic=5aa5bccd
DumpTensor: desc=5, addr=0, data_type=DT_FLOAT16, position=UB
[40, 82, 60, 11, 24, 55, 52, 60, 31, 86, 53, 61, 47, 54, 34, 62, 84, 29, 48, 95, 16, 0, 20, 77, 3, 55, 69, 73, 75, 40, 35, 13]
DumpHead: block_id=1, total_block_num=16, block_remain_len=1048448, block_initial_space=1048576, magic=5aa5bccd
DumpTensor: desc=5, addr=0, data_type=DT_FLOAT16, position=UB
[58, 84, 22, 54, 41, 93, 1, 45, 50, 9, 72, 81, 23, 96, 86, 45, 36, 9, 36, 34, 78, 7, 2, 29, 47, 26, 13, 24, 27, 55, 90, 5]
...
DumpHead: block_id=7, total_block_num=16, block_remain_len=1048448, block_initial_space=1048576, magic=5aa5bccd
DumpTensor: desc=5, addr=0, data_type=DT_FLOAT16, position=UB
[28, 27, 79, 39, 86, 5, 23, 97, 89, 5, 65, 69, 59, 13, 49, 2, 34, 6, 52, 38, 4, 90, 11, 11, 61, 50, 71, 98, 19, 54, 54, 99]
b)?PRINTF示例如下:
PRINTF("fmt string %d", 0x123);
3? Example,调试样例
下面通过具体的样例来实战一下吧!
3.1? CPU域调试样例
在进行调试之前我们需要获取一个精度有问题的算子样例
1. 通过如下的样例链接获取正确的样例。(CPU调试当前仅适用于通过内核调用符调用算子的程序调试,所以这里我们获取KernelLaunch的代码样例)
https://gitee.com/ascend/samples/tree/master/operator/AddCustomSample/KernelLaunch
2. 将AddKernelInvocation / add_custom.cpp中的Init函数替换成如下有bug的代码。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
????{
????????xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
????????yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
????????zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
????????pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH);
????????pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH);
????????pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH);
}
3. 参考样例readme,跑一下样例,样例出现如下报错:
[ERROR] result error
下面我们一起开始debug之旅吧。
- 观察日志报错。
观察是否有打屏日志报错,可搜索关键词"failed"。下图的报错示例指示,错误出现在代码中调用Add接口的地方。
add_cpu: /usr/local/Ascend/ascend-toolkit/7.0.RC1.alpha003/x86_64-linux/tikcpp/tikcfw/interface/kernel_operator_vec_binary_intf.h:79:?void AscendC::Add(const AscendC::LocalTensor<T>&, const AscendC::LocalTensor<T>&, const AscendC::LocalTensor<T>&, const int32_t&) [with T = float16::Fp16T; int32_t = int]: Assertion `false && "check vadd instr failed"' failed.
通过上述报错日志,一般只能定位到框架报错的代码行,无法明确具体错误,接下来需要通过gdb调试的方式或者printf打印的方式进一步精确定位。
2. gdb调试。下面的样例展示了拉起Add算子CPU侧运行程序的样例,该样例程序会直接抛出异常,直接gdb运行,查看调用栈信息分析定位即可。其他场景下您可以使用gdb打断点等基本操作进行调试。
????????1) 使用gdb拉起待调试程序,进入gdb界面进行debug。
gdb add_cpu
? ? ? ? 2) 单独调试一个子进程。
(gdb) set follow-fork-mode child
? ? ? ? 3) 运行程序。
(gdb) r
? ? ? ? 4) 通过bt查看程序调用栈。
(gdb) bt
? ? ? ? 5) 查看具体层的堆栈信息,打印具体变量的值。本示例中,查看报错代码的上一层第5层的堆栈,打印了TILE_LENGTH为128,该程序中表示需要处理128个half类型的数,大小为128*sizeof(half)=256字节;同时打印了输入Tensor xLocal的值,其中dataLen表示LocalTensor的size大小为128字节,只能计算128字节的数据。可以看出两者的长度不匹配,由此可以继续检查代码内存分配时传入长度是否有误,从而定位到Init函数中InitBuffer的问题。同理,大家可以自行打印yLocal和zLocal的值。
(gdb) f 5
#5 ?0x0000555555560638 in KernelAdd::Compute (this=0x7fffffffd360, progress=0)
????at /samples-master/operator/AddCustomSample/KernelLaunch/AddKernelImpl/add.cpp:54
54 ?????????????Add(zLocal, xLocal, yLocal, TILE_LENGTH); (gdb) p TILE_LENGTH
$1 = 128
(gdb) p xLocal
$3 = {<AscendC::BaseTensor<float16::Fp16T>> = {<No data fields>}, address_ = {logicPos = 9 '\t', bufferHandle = 0x7fffffffd460 "\003\005\377\377\200", dataLen = 128,
bufferAddr = 0,absAddr = …}
3. printf打印。在调用报错代码行之前的位置增加变量打印。样例代码如下:
__aicore__ inline void Compute(int32_t progress)
????{
????????LocalTensor<half> xLocal = inQueueX.DeQue<half>();
????????LocalTensor<half> yLocal = inQueueY.DeQue<half>();
????????LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
????????#ifdef __CCE_KT_TEST__
????????printf("xLocal size: %d\n", xLocal.GetSize());
printf("tileLength: %d\n", TILE_LENGTH);
#endif
????????Add(zLocal, xLocal, yLocal, TILE_LENGTH);
????????outQueueZ.EnQue<half>(zLocal);
????????inQueueX.FreeTensor(xLocal);
????????inQueueY.FreeTensor(yLocal);
????}
可以看到有如下打屏日志输出,打印了tileLength为128,该程序中表示需要处理128个half类型的数;输入Tensor xLocal的size大小,为64,表示只能计算64个half类型的数。可以看出两者的长度不匹配,由此可以继续检查代码内存分配时传入长度是否有误,从而定位到Init函数中InitBuffer的问题。
xLocal size: 64
tileLength: 128
3.2? NPU域调试样例
在进行调试之前我们需要获取一个精度有问题的算子样例
- 通过如下的样例链接获取正确的样例。(上板数据打印调试当前适用于单算子调用程序(aclnn接口)调试,所以这里我们获取算子工程和aclnn单算子调用的代码样例)
???????samples: CANN Samples - Gitee.com
2. 将AddCustom / op_kernel / add_custom.cpp中的Init函数替换成如下有bug的代码。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileNum)
????{
????????ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
????????this->blockLength = totalLength / GetBlockNum();
????????this->tileNum = tileNum;
????????ASSERT(tileNum != 0 && "tile num can not be zero!");
????????this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
????????xGm.SetGlobalBuffer((__gm__ half*)x + this->blockLength * GetBlockIdx(), this->blockLength);
????????yGm.SetGlobalBuffer((__gm__ half*)y + this->blockLength * GetBlockIdx(), this->blockLength);
????????zGm.SetGlobalBuffer((__gm__ half*)z + this->blockLength * GetBlockIdx(), this->blockLength);
????????pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength);
????????pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength);
????????pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength);
????}
3. 参考样例readme,跑一下算子的编译部署以及aclnn调用样例,aclnn调用样例出现如下报错:
[ERROR] result error
下面我们一起开始debug之旅吧。
在AddCustom / op_kernel / add_custom.cpp中关键的流程中增加数据打印
比如如下的示例代码分别在计算前和计算后增加对zLocalTensor的数据打印,同时打印参与计算的元素个数。
DumpTensor(zLocal, __LINE__, zLocal.GetSize());
????????PRINTF("The data Length involved in calculation is %d.\n", this->tileLength);
????????Add(zLocal, xLocal, yLocal, this->tileLength);
????????DumpTensor(zLocal, __LINE__, zLocal.GetSize());
参考上文的上板数据打印流程进行环境变量、cmake文件等配置,运行aclnn单算子调用样例,可以看到屏幕有如下打印:
DumpTensor: desc=54, addr=512, data_type=DT_FLOAT16, position=UB
[59.1875, 66.625, 53.4375, 52.0625, 80.3125, 10.5234, 21.3594, 43.2188, 1.15039, 50.625, 7.88672, 60.0625, 63.9062, 28.2812, 6.72266, 66.3125, 38.9062, 7.9375, 37.8125, 38.9062, 57.0938, 14.2266, 66.625, 62.3125, 5.17969, 1.63477, 45.2812, 68.1875, 59.9375, 23.8281, 71.8125,
45.1875, 59.2188, 53.875, 77.25, 47.5625, 75, 38.1875, 61.2812, 63.125, 58.5312, 83.6875, 44.5312, 57.125, 2.74609, 32.8438, 27.1094, 20.9219, 70.3125, 62.7188, 20, 6.90625, 30.5312, 91.75, 17.3125, 29.8125, 68.9375, 83.125, 23.4375, 58.8125, 62.6875,
69.9375, 19.9531, 46.25]
The data Length involved in calculation is 128.
DumpTensor: desc=57, addr=512, data_type=DT_FLOAT16, position=UB
[151.75, 158, 48.125, 96.25, 158, 74.125, 101.375, 34, 36.2812, 112.375, 109.125, 95.25, 142.75, 44.75, 176.375, 130.125, 68.3125, 70.3125, 102.375, 92.75, 139.25, 55.4375, 87, 102.75, 177.375, 118.875, 113.375, 25.6562, 101.125, 107.75, 165.5,
72.5, 17.5625, 52.4688, 167.125, 132.75, 171.375, 98.75, 133.375, 107.5, 119.375, 149.25, 161.625, 146.375, 162.25, 88.8125, 119.375, 88.9375, 170.5, 91.625, 72.9375, 131.875, 71.5625, 44.6562, 57.0625, 101.5, 150.125, 71.75, 126.625, 113.688, 139.75,
107.938, 79.5625, 132.875]
观察得到tensor的长度为64,但是设置的计算长度为128 两者不匹配,进一步定位可以确定问题为Init时初始化buffer的长度错误。
通过本篇内容 大家可以了解Ascend?C孪生调试的概念,并可以参照实际样例进行实战练习。更多相关内容请参考:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!